
简单介绍cgroups以及在K8s中的应用 - CPU

cgroups(control groups,控制组群) 是 Linux 内核的一个功能,用来限制、控制与分离一个进程组的资源(如CPU、内存、磁盘输入输出等)。它是由 Google 的两位工程师进行开发的,自 2008 年 1 月正式发布的 Linux 内核 v2.6.24 开始提供此能力。cgroups到目前为止,有两个大版本, 即 v1 和 v2 。
作者:董卫国,中国移动云能力中心软件研发工程师,专注于云原生领域。
cgroups(control groups,控制组群) 是 Linux 内核的一个功能,用来限制、控制与分离一个进程组的资源(如CPU、内存、磁盘输入输出等)。它是由 Google 的两位工程师进行开发的,自 2008 年 1 月正式发布的 Linux 内核 v2.6.24 开始提供此能力。cgroups到目前为止,有两个大版本, 即 v1 和 v2 。
cgroups可以限制、记录、隔离进程组所使用的物理资源(包括:CPU、memory、IO等),为容器实现虚拟化提供了基本保证,是构建docker、containerd、kubernetes等一系列容器服务的基石。
从单个进程的资源控制到操作系统层面的虚拟化。cgroups提供了以下四大功能
1)资源限制:cgroups可以对进程组使用的资源总额进行限制。如设定应用运行时使用内存的上限,一旦超过这个配额就发出OOM(Out of Memory)。
2)优先级分配:通过分配的CPU时间片数量及硬盘IO带宽大小,实际上就相当于控制了进程运行的优先级。
3)资源统计:cgroups可以统计系统的资源使用量,如CPU使用时长、内存用量等等,这个功能非常适用于计费。
4)进程控制:cgroups可以对进程组执行挂起、恢复等操作。
下面我们对v1和v2版本的使用进行一些简单的验证,并对于cgroups在kubernetes中的一些使用进行介绍,本节我们主要介绍cgroups对CPU使用率的限制能力。
cgroups v1介绍
我们当前的测试环境为centos 7.9 ,内核为 5.4版本,如下所示:

我们可以使用如下命令查询当前的cgroups版本

/sys/fs/cgroup是cgroups的默认挂载目录,对于v1版本,命令的返回值应该是tmpfs
cgroups中最关键的是一个概念就是到子系统(subsystem),每一个subsystem代表一种资源的控制能力,每个subsystem下可以建立cgroups控制组,并写入进程号,以起到对进行限制资源的作用。
目前为止,Linux支持13种subsystem,比如限制CPU的使用时间,限制使用的内存,统计CPU的使用情况,冻结和恢复一组进程等,我们可以通过如下命令查看系统支持的subsystem。
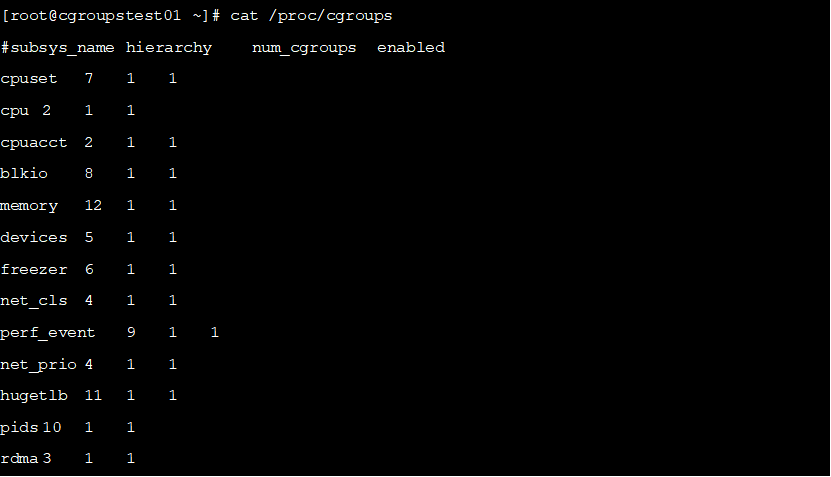
从左到右,字段的含义分别是:
l支持的subsystem的名字,每种subsystem独立地控制一种资源
lsubsystem所关联到的cgroups树的ID,如果多个subsystem关联到同一颗cgroups树,那么他们的这个字段将一样,比如这里的cpu和cpuacct就一样,表示他们绑定到了同一颗树。如果出现下面的情况,这个字段将为0:
²当前subsystem没有和任何cgroups树绑定
²当前subsystem已经和cgroups v2的树绑定
²当前subsystem没有被内核开启
lsubsystem所关联的cgroups树中进程组的个数,也即树上节点的个数。
l1表示开启,0表示没有被开启(可以通过设置内核的启动参数“cgroup_disable”来控制subsystem的开启)。
Linux内核有一个很大的模块叫VFS(Virtual File System)。VFS能够把具体的文件系统细节隐藏起来,给用户态进程提供一个同一个为文件系统API接口。也就是说当我们对这些文件进行一些写操作,就可以按照我们的需求对进程的资源进行定制化的配置,下面我们简单介绍几个cgroups的文件系统API接口。
简单看一下/sys/fs/cgroup/cpu的目录结构和内容。
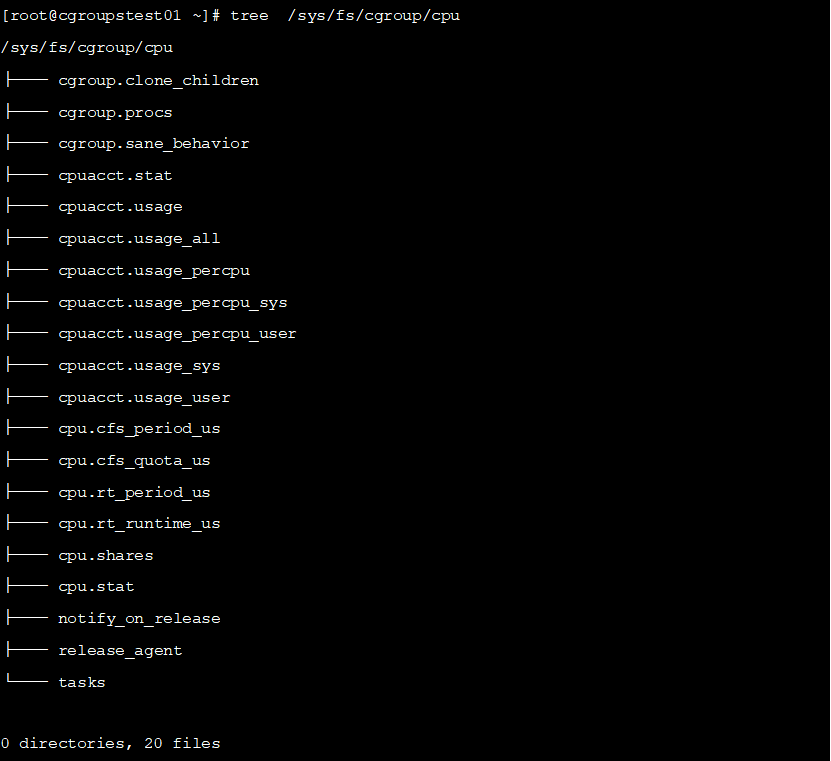
cpu子系统是cgroups用来限制进程如何使用CPU的时间的subsystem,它提供了3种调度办法,并且这3种调度办法都可以在启动容器时进行配置,分别是:
1)share :相对权重的CPU调度
2)cfs :完全公平调度
3)rt :实时调度
以cfs为例简单说明,cfs根据cpu.cfs_quota_us 和 cpu.cfs_period_us 两个文件实现公平调度,这两个文件内容组合使用可以限制进程在长度为 cfs_period_us 的时间内,只能被分配到总量为 cfs_quota_us 的 CPU 时间。
tasks文件是当前 cgroups 包含的pid (Process Identifier,进程号)列表,把某个进程的 pid 添加到这个文件中就等于把进程移到该 cgroups控制组中。
进程的cgroups属组
本小节我们简单介绍下如何查看一个进程属于哪个cgroup组,方便我们后续追踪容器进程的cgroup情况。
每个进程在/proc/[pid]目录下有一个cgroup文件,这个文件内保存了一个进程和cgroup的对应关系。查看当前shell的cgroups

从左到右,字段的含义分别是:
lcgroups树的ID, 和/proc/cgroups文件中的ID一一对应。
l和cgroups树绑定的所有subsystem,多个subsystem之间用逗号隔开。这里name=systemd表示没有和任何subsystem绑定,只是给他起了个名字叫systemd。
l进程在cgroups树中的路径,即进程所属的cgroups,这个路径是相对于挂载点的相对路径。
第三列是相对路径,补全就是/sys/fs/cgroup/systemd/user.slice/user-0.slice/session-672.scope/tasks,我们切换到对应的路径并查看tasks内容,查看内容如下:
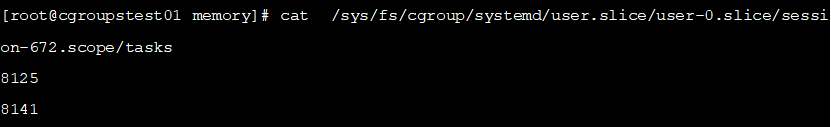
可以看到PID 8125在tasks内。
由于当前没有对进程做资源限制,因此/proc/[pid]/cgroups中cpu/memory等限制均为空。
cgoups资源限制测试
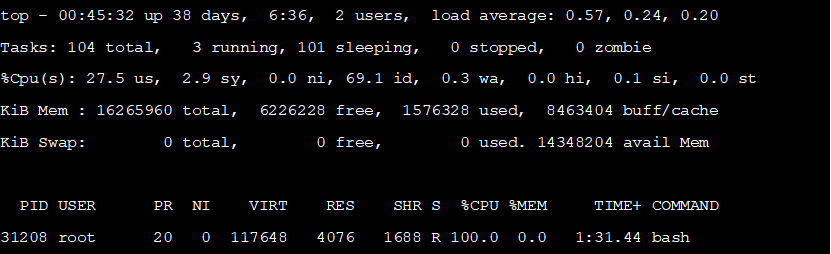
在一台centos系统运行如下一个耗cpu的命令

新打开一个会话,使用top命令容易观察到,有一个bash进程(即当前会话的进程)CPU使用率为100%,如下所示:
创建一个名为test01的cgroups控制组控制这个进程的CPU资源,并将当前会话的进程加入资源组(即写入task文件),如下所示

当前cgroups限制在100000微秒内可以申请使用10000微秒的CPU,也就是使用了一个CPU线程的10%,再次执行shell命令
使用top命令观察cpu占用率如下所示

符合预期。
换一个命令测试,shell命令如下
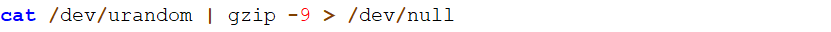
查看当前的CPU消耗如下所示
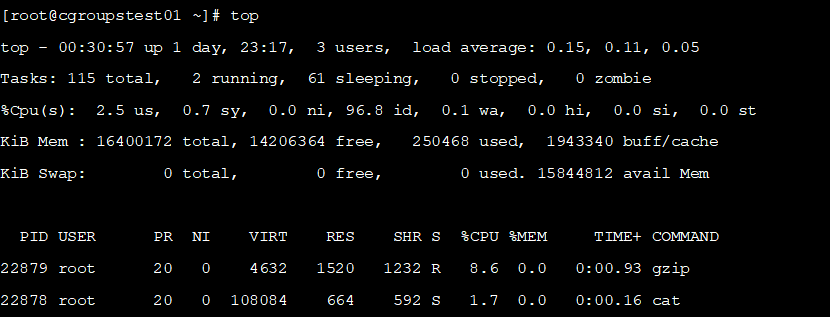
可以看到shell的两个子进程加起来也使用了10%的CPU,查看task文件

可以看到两个子进程已经自动加入了task中。
把当前shell的pid移动到cpu的/sys/fs/cgroup/cpu中,并使用rmdir命令清理,如下所示:

可以看到之前创建的cgroups控制组已经被删除。
Kubernetes中的资源限制
Kubernetes 通过配置 cgroups来限制容器或者pod 能使用的最大资源量。这个配置有两种实现方式, 在 Kubernetes 中称为 cgroup runtime driver:
lcgroupfs
这种比较简单直接,kubelet往 cgroup 文件系统中写 limit 就行了。这也是目前 Kubernetes 的默认方式。
lsystemd
所有 cgroup-writing 操作都必须通过 systemd 的接口,不能手动修改 cgroup 文件。适用于 Kubernetes cgroup v2 模式。
在Kubernetes中启动一个deployment查看效果

Pod变为Running状态后,登录到Pod所在节点执行如下shell命令查看容器cgroupstest的内存限制

容器的资源限制如下所示

执行如下shell查看CPU限制

先看cpu.shares结果大致如下

对于CPU,requests 经过转换之后会写入 cpu.share, 表示这个 cgroups最少可以使用的 CPU。
在Kubernetes中一个CPU线程相当于1024 share,使用如下命令可以查看

CPU 资源的单位m 是 millicores 的缩写,表示千分之一核,一个CPU线程可以分为1000个等份,容易得到如下公式
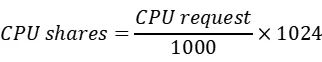
可以看到pod的resource.request中CPU为50m,通过上面的公式转化为share结果为51, cpu share是一个相对值,可以参考下面的解释:

容易知道,cpu.shares是一个相对值,也是一个软限制,在空闲时,CPU占用也很容易超过request申请的值,因此只能作为resource.request,不能作为resource.limits。
而resource.limits 则通过.cfs_quota_us和cpu.cfs_period_us 两个文件来控制,表示cgroups最多可以使用的 CPU。
lcpu.cfs_period_us 此参数可以设定重新分配 cgroup 可用 CPU 资源的时间间隔,单位为微秒
lcpu.cfs_quota_us 此参数可以设定在某一阶段(由 cpu.cfs_period_us 规定)某个 cgroup 中所有任务可运行的时间总量,单位为微秒。一旦 cgroup 中任务用完按配额分得的时间,它们就会被在此阶段的时间提醒限制流量,并在进入下阶段前禁止运行。
如果 cgroups 中任务在每 1 秒内有 0.2 秒,可对单独 CPU 进行存取,可以将 cpu.cfs_quota_us 设定为 200000,cpu.cfs_period_us 设定为 1000000。查看如下结果

由此容易得到测试容器的CPU上限使用率为100m。
通过top命令查看也符合预期
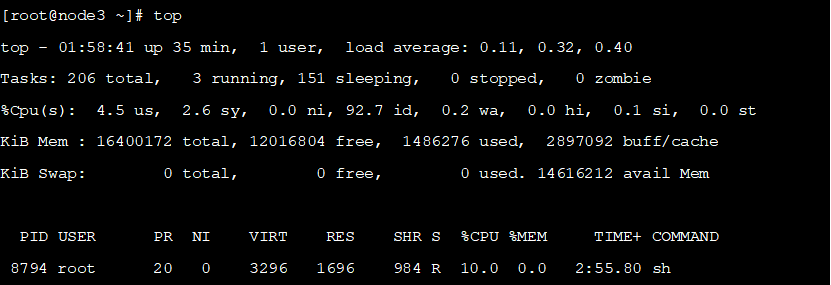
使用如下命令修改pod和容器的资源上限:
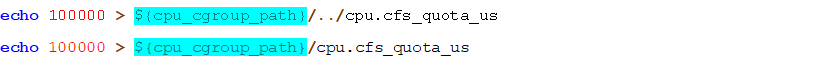
注意在修改cgroups时候,先修改pod的cgroups,再修改容器的,因为在子 cgroups中对相关子系统进行修改时,该子系统的相关属性小于父 cgroups属性的相应值。
查看结果如下:
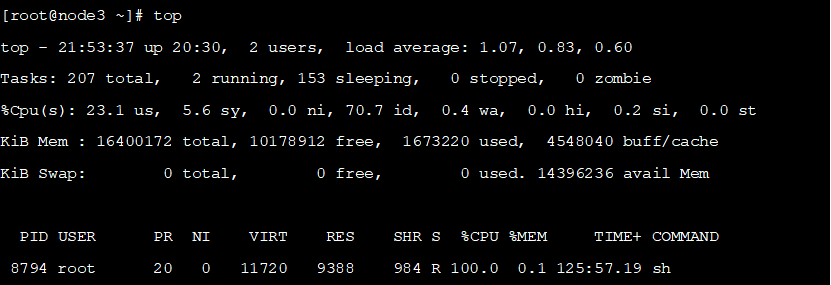
资源使用率提升至100%,符合预期。
前面已经介绍过,Kubernetes spec 里的 requests/limits 是打在 container 上的,并没有打在 pod 上。因此 pod 的 requests/limits 需要由 kubelet 综合统计 pod 的所有 container 的 request/limits 计算得到。CPU 和内存的计算方式如下:

注意,
1)如果其中某个 container 的 CPU 字段只设置了 request 没设置 limit, 则 pod 将只设置 cpu.shares,不设置 cpu.cfs_quota_us。
2)如果所有 container 都没有设置 cpu request/limit(等效于 requests==limits==0), 则将 pod cpu.share 将设置为 Kubernetes 定义的最小值 2。这种 pod 在 node 空闲时最多能使用整个 node 的资源;但 node 资源紧张时,也最先被驱逐。
cgroups v2介绍
cgroups v2 在 Linux Kernel 4.5中被引入,并且考虑到其它已有程序的依赖,V2 会和 V1 并存几年。当前很多的操作系统版本中,默认的cgroups仍是v1版本,下面我们进行切换,并进行测试。
测试使用cgroups v2
Centos7启动cgroups v2
这里笔者基于自己较为熟悉的centos7进行测试,首先升级systemd,我们参考如下命令先升级systemd

升级内核至4.5版本以上,笔者的测试机器升级到了5.4版本,然后重启机器
然后修改 /etc/default/grub 文件,在变量GRUB_CMDLINE_LINUX最后追加如下内容
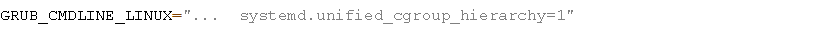
更新引导,重启机器

重启后,检查挂载,发现当前已使用cgroups v2,且cgroups v1已关闭
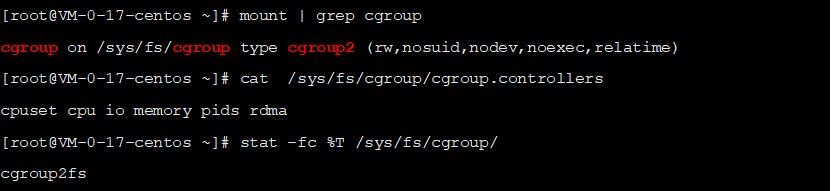
如果挂载情况和v1版本一样,则需要重新检查内核版本,确认切换到正确的高版本内核后,再次重启。
简单了解cgroups关键文件
在cgroups v2版本的根目录下会有三个 cgroups核心文件:
lcgroup.controllers: 该文件列出当前 cgroup支持的所有 controller,如: cpu io memory
lcgroup.procs: 在刚挂载时,root cgroup目录下的 cgroup.procs 文件中会包含系统当前所有的Proc PID(除了僵尸进程)。同样,可以通过将 Proc PID 写入 cgroup.procs 来将 Proc 加入到 cgroup
lcgroup.subtree_control: 用于控制该 cgroup下 controller开关,只有列在 cgroup.controllers 中的 controller 才可以被开启,默认情况下所有的 controller都是关闭的。
查看cgroups v2支持的哪些资源限制,如下所示:

可以看到当前版本支持cpuset、cpu、io、memory、pids、rdma等几种资源,除了rdma其他几种都是常见的资源限制,这里面没有了cgroups v1中的net_cls。
尝试新建一个名为test的cgroups组,然后查看目录,如下所示

可以看到,当前cgroups可以支持cpuset cpu io memory pids的资源限制。
cgroup.subtree_control:这个文件内容应是cgroup.controllers的子集。其作用是限制在当前cgroups目录层级下创建的子目录中的cgroup.controllers内容。就是说,子层级的cgroups资源限制范围被上一级的cgroup.subtree_control文件内容所限制。
所以,如果我们想创建一个可以支持cpuset cpu io memory pids全部五种资源限制能力的cgroups组的话,应该做如下操作:
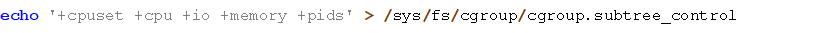
执行之后再次检查,如下所示

此时我们创建的test cgroups组就有cpu,cpuset,io,memory,pids五种常见的资源限制能力了。另外要注意,被限制进程只能添加到叶子结点的组中,不能添加到中间结点的组内。
CPU资源隔离
新版cgroups简化了cpu配额的配置方法。用一个文件就可以进行配置了:cpu.max。该文件支持2个值,格式为:$MAX $PERIOD。这个含义是,在 $PERIOD所表示的时间周期内,有 $MAX是分给本cgroups的。也就是配置了本cgroups的CPU占用在单核上不超过50%。
执行如下命令设置资源限制
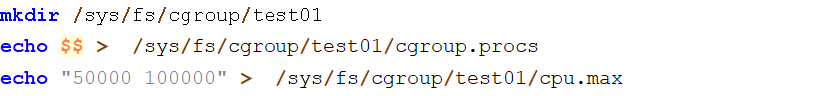
执行脚本如下命令进行测试:
打开一个会话,用top命令查看结果
可以看到CPU使用率被限制在了50%。
CPU还有一个软性的限制,叫做 cpu.weight ,相当于v1版本cgroups中的cpu.shares。还有一个相关的值为 cpu.weight.nice ,这个值随cpu.weight的变化为变化,cgroups v2官方文档里说这个值的取值范围是[-20, 19],从nice名字和取值范围看,大概相当于linux中的nice命令(一个调整进程优先级的命令)的作用。
Kubernetes中的资源限制
启用cgroups v2
Kubernetes 自 v1.25 起 cgroup2 特性正式 stable,根据官方文档,我们可以知道,cgroup2 相比 cgroups v1 有以下优势:
lAPI 中单个统一的层次结构设计
l更安全的子树委派给容器
l更新的功能特性, 例如压力阻塞信息(Pressure Stall Information,PSI)
l跨多个资源的增强资源分配管理和隔离
l统一核算不同类型的内存分配(网络内存、内核内存等)
l考虑非即时资源变化,例如页面缓存回写
推荐在使用 Kubernetes v1.25及以上版本时, 使用支持 cgroups v2 的linux 和 CRI. 并启用 Kubernetes 的cgroups v2 功能.
首先在kubelet 使用 systemd cgroup 驱动。kubeadm 支持在执行 kubeadm init 时,传递一个 KubeletConfiguration 结构体。KubeletConfiguration 包含 cgroupDriver 字段,可用于控制 kubelet 的 cgroup 驱动。如下所示

也可以自行在kubelet的config配置中修改参数:cgroupDriver: systemd
containerd 使用 systemd cgroup 驱动,编辑 /etc/containerd/config.toml:
修改或增加如下内容
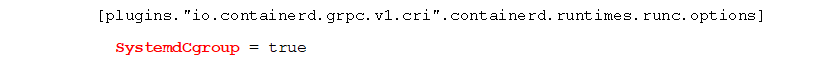
cgroups v2 使用一个与 cgroups v1 不同的 API,因此如果有任何应用直接访问 cgroups文件系统, 则需要将这些应用更新为支持 cgroups v2 的版本。例如:
l一些第三方监控和安全代理可能依赖于 cgroups文件系统。你要将这些代理更新到支持 cgroups v2 的版本。
l如果以独立的 DaemonSet 的形式运行 cAdvisor 以监控 Pod 和容器, 需将其更新到 v0.43.0 或更高版本。
l如果你使用 JDK,推荐使用 JDK 11.0.16 及更高版本或 JDK 15 及更高版本, 以便完全支持 cgroups v2。
测试效果
在Kubernetes中启动一个deployment查看效果
登录到节点上执行如下命令
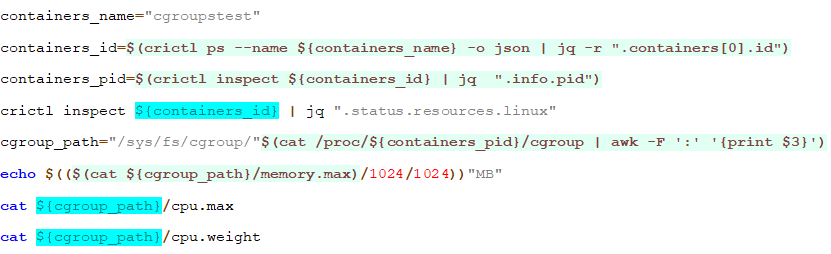
查看结果如下:

其中,cpu.weight的计算是通过如下公式
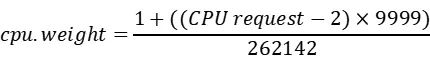
可以看到,容器内存被限制在了128Mb,CPU被限制在了0.1C,即limit配置中100m。
总结
本文对cgroups v1和v2版本进行了介绍和和CPU使用率限制的验证,并对其在Kubernetes中的使用进行了一些初步的调研。
本文仅做了一些cgroups基础能力的调研,没有做深入学习。在功能上,一些文档中看到cgroups甚至可以在线程级别进行限制,在原理上,cgroups涉及到各个资源的分配、调度,比如CPU的资源限制就涉及到linux下的进程调度算法,本文也没有进一步去探究。
最后,由于笔者能力和时间所限,难免存在一些错漏,还请谅解。
参考
1)一篇搞懂容器技术的基石: cgroup,https://zhuanlan.zhihu.com/p/434731896
2)Linux cgroups:深入理解cgroups v1版本, https://www.testerfans.com/archives/linux-cgroups-learn-more
3)Linux CFS and task group, https://mechpen.github.io/posts/2020-04-27-cfs-group/index.html
4)深入理解 Kubernetes 资源限制:CPU, https://icloudnative.io/posts/understanding-resource-limits-in-kubernetes-cpu-time/
5)CFS Bandwidth Control,https://www.kernel.org/doc/html/v5.4/scheduler/sched-bwc.html?highlight=cpu%20cfs_quota_us
6)Cgroup详解,https://juejin.cn/post/6921299245685276686
7)Cgroup限制内存与节点的删除,https://chaochaogege.com/2019/09/11/6/
8)容器内存分析,https://blog.csdn.net/u012986012/article/details/105291831
9)控制组详解,https://blog.gmem.cc/cgroup-illustrated
10)Cgroup V2 and writeback support,http://hustcat.github.io/cgroup-v2-and-writeback-support/
11)Linux CGroup 基础,https://wudaijun.com/2018/10/linux-cgroup/
12)详解Cgroup V2,https://zorrozou.github.io/docs/%E8%AF%A6%E8%A7%A3Cgroup%20V2.html
13)centos 7 升级 systemd,https://lqingcloud.cn/post/systemd-01/
14)容器-cgroup-blkio-cgroup,http://119.23.219.145/posts/%E5%AE%B9%E5%99%A8-cgroup-blkio-cgroup/
15)打通IO栈:一次编译服务器性能优化实战, https://mp.weixin.qq.com/s?__biz=Mzg2OTc0ODAzMw==&mid=2247502495&idx=1&sn=26950b22cba383b14052b441cd356516&source=41#wechat_redirect
16)pod资源限制和QoS探索, https://www.zerchin.xyz/2021/01/31/pod%E8%B5%84%E6%BA%90%E9%99%90%E5%88%B6%E5%92%8CQoS%E6%8E%A2%E7%B4%A2/