
你幸福吗?Python分析幸福最重要的因素原来是它!

《世界幸福指数报告》是对全球幸福状况的一次具有里程碑意义的调查。
民意测验机构盖洛普从2012年起,每年都会在联合国计划下发布《世界幸福指数报告》,报告会综合两年内150多个国家的国民对其所处社会、城市和自然环境等因素进行评价后,再根据他们所感知的幸福程度对国家进行排名。
《世界幸福指数报告》的编撰主要依赖于对150多个国家的1000多人提出一个简单的主观性问题:“如果有一个从0分到10分的阶梯,顶层的10分代表你可能得到的最佳生活,底层的0分代表你可能得到的最差生活。你觉得你现在在哪一层?”

那么哪个国家在总体幸福指数上排名最高?
哪些因素对幸福指数的影响最大?
今天我们就带你用Python来聊一聊。
01
数据理解
关键字段含义解释:
02
数据导入和数据整理
《世界幸福指数报告》代码+数据:
链接: https://pan.baidu.com/s/1chufmzPzwxTVNwL7ki1krg 提取码: nd2p
首先导入所需包。
# 数据整理
import numpy as np
import pandas as pd
# 可视化
import matplotlib.pyplot as plt
import seaborn as sns
import plotly as py
import plotly.graph_objs as go
import plotly.express as px
from plotly.offline import init_notebook_mode, iplot, plot
init_notebook_mode(connected=True)
plt.style.use('seaborn')
# 读入数据
df_2015 = pd.read_csv('./deal_data/2015.csv')
df_2016 = pd.read_csv('./deal_data/2016.csv')
df_2017 = pd.read_csv('./deal_data/2017.csv')
df_2018 = pd.read_csv('./deal_data/2018.csv')
df_2019 = pd.read_csv('./deal_data/2019.csv')
# 新增列-年份
df_2015["year"] = str(2015)
df_2016["year"] = str(2016)
df_2017["year"] = str(2017)
df_2018["year"] = str(2018)
df_2019["year"] = str(2019)
# 合并数据
df_all = df_2015.append([df_2016, df_2017, df_2018, df_2019], sort=False)
df_all.drop('Unnamed: 0', axis=1, inplace=True)
df_all.head()

print(df_2015.shape, df_2016.shape, df_2017.shape, df_2018.shape, df_2019.shape)
(158, 10) (157, 10) (155, 10) (156, 11) (156, 11)
df_all.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 782 entries, 0 to 155
Data columns (total 10 columns):
region 782 non-null object
rank 782 non-null int64
happiness 782 non-null float64
gdp_per_capita 782 non-null float64
healthy_life_expectancy 782 non-null float64
freedom_to_life_choise 782 non-null float64
corruption_perceptions 781 non-null float64
generosity 782 non-null float64
year 782 non-null object
social_support 312 non-null float64
dtypes: float64(7), int64(1), object(2)
memory usage: 67.2+ KB
03
数据可视化
2019世界幸福地图

整体来看,北欧的国家幸福指数较高,如冰岛、丹麦、挪威、芬兰;东非和西非的国家幸福指数较低,如多哥、布隆迪、卢旺达和坦桑尼亚。
代码展示:
data = dict(type = 'choropleth',
locations = df_2019['region'],
locationmode = 'country names',
colorscale = 'RdYlGn',
z = df_2019['happiness'],
text = df_2019['region'],
colorbar = {'title':'Happiness'})
layout = dict(title = 'Geographical Visualization of Happiness Score in 2019',
geo = dict(showframe = True, projection = {'type': 'azimuthal equal area'}))
choromap3 = go.Figure(data = [data], layout=layout)
plot(choromap3, filename='./html/世界幸福地图.html')
2019世界幸福国家排行Top10
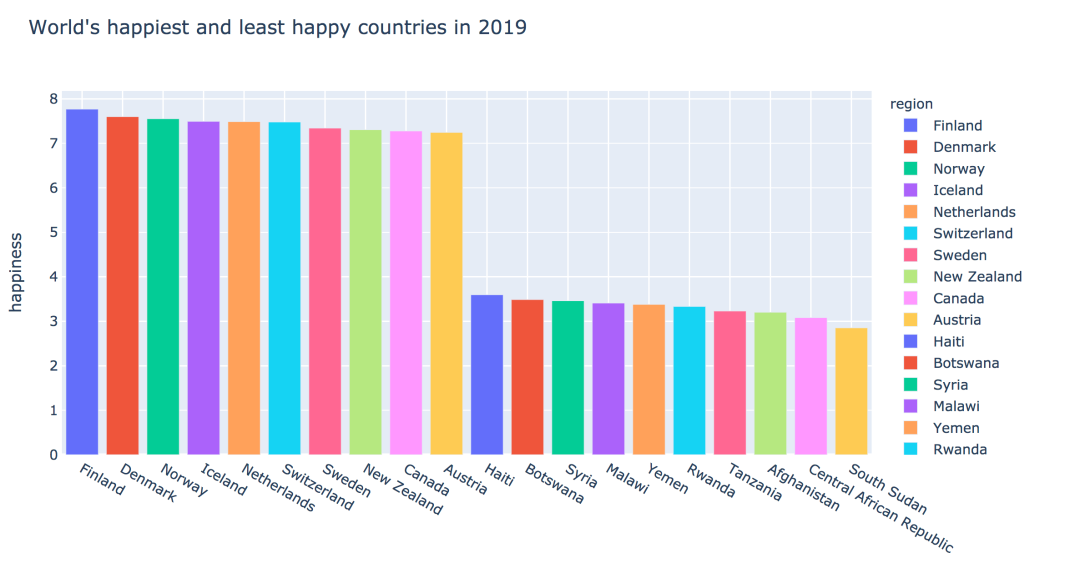
2019年报告,芬兰连续两年被评为“全球最幸福国家”。丹麦、挪威、冰岛、荷兰进入前五名,对比2018年报告,中国从86名下降到93名。
代码展示:
# 合并数据
rank_top10 = df_2019.head(10)[['rank', 'region', 'happiness']]
last_top10 = df_2019.tail(10)[['rank', 'region', 'happiness']]
rank_concat = pd.concat([rank_top10, last_top10])
# 条形图
fig = px.bar(rank_concat,
x="region",
y="happiness",
color="region",
title="World's happiest and least happy countries in 2019")
plot(fig, filename='./html/2019世界幸福国家排行Top10和Last10.html')
幸福指数相关性
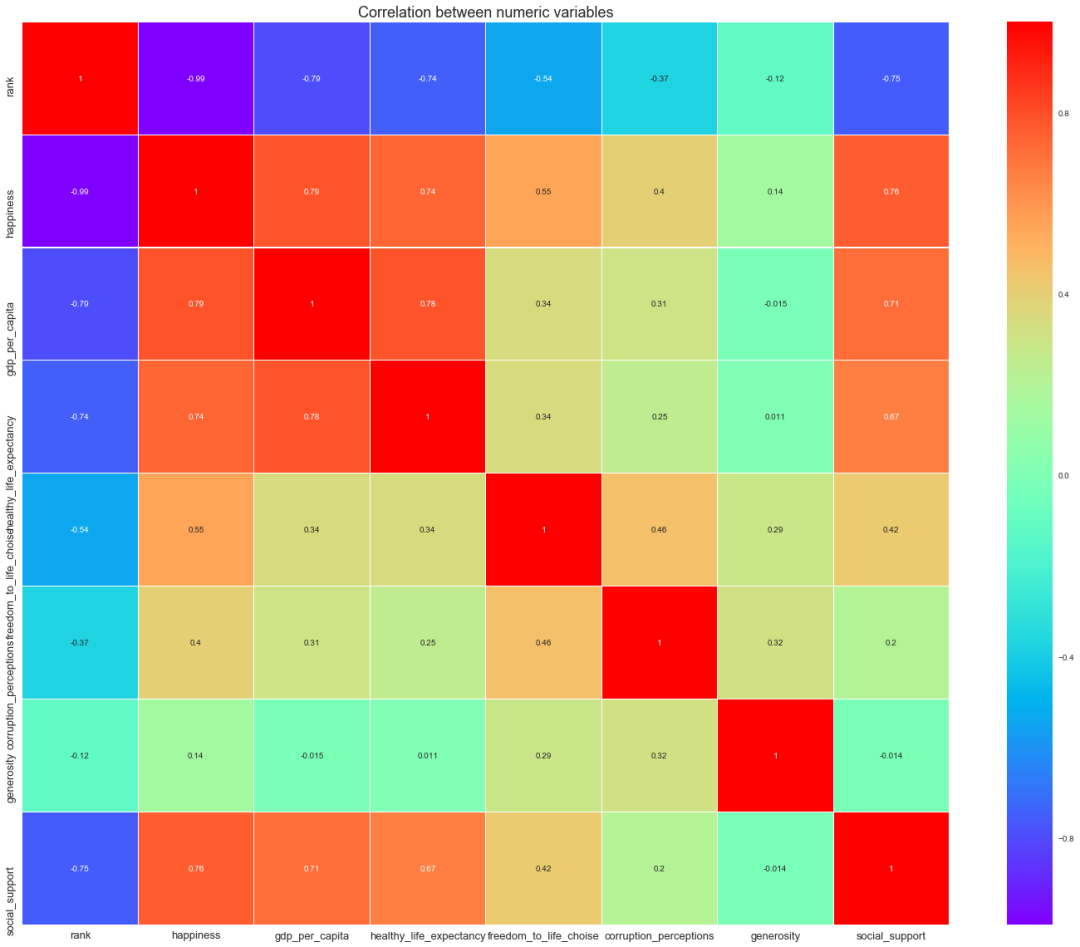
我们可以得出以下结论:
从影响因素相关性热力图可以看出,在影响幸福得分的因素中,GDP、社会支持、健康预期寿命呈现高度相关,自由权呈现中度相关,国家的廉政水平呈现低度相关,慷慨程度则呈现极低的相关性;
GDP与健康预期寿命、社会支持之间存在高度相关。说明GDP高的国家,医疗水平和社会福利较为完善,人民的预期寿命也会越高;
健康预期寿命与社会支持之间存在中度相关性。
以下分别观察各个因素的影响程度。
GDP和幸福得分

人均GDP与幸福得分呈高度线性正相关关系,GDP越高的国家,幸福水平相对越高。
代码展示:
# 散点图
fig = px.scatter(df_all, x='gdp_per_capita',
y='happiness',
facet_row='year',
color='year',
trendline='ols'
)
fig.update_layout(height=800, title_text='GDP per capita and Happiness Score')
plot(fig, filename='./html/GDP和幸福得分.html')
健康预期寿命和幸福得分

健康预期寿命与幸福得分呈高度线性正相关关系,健康预期寿命越高的国家,幸福水平相对越高。
代码展示:
散点图
fig = px.scatter(df_all, x='healthy_life_expectancy',
y='happiness',
facet_row='year',
color='year',
trendline='ols'
)
fig.update_layout(height=800, title_text='Healthy Life Expecancy and Happiness Score')
plot(fig, filename='./html/健康预期寿命和幸福得分.html')
GDP和幸福水平动态图
代码展示:
fig = px.scatter(df_all,
x='gdp_per_capita',
y='happiness',
animation_frame='year',
animation_group='region',
size='rank',
color='region',
hover_name='region',
trendline='ols'
)
fig.update_layout(title_text='Happiness Rank vs GDP per Capita')
plot(fig, filename='./html/GDP和幸福水平动态图展示.html')
健康预期寿命和幸福水平动态图
代码展示:
fig = px.scatter(df_all,
x='healthy_life_expectancy',
y='happiness',
animation_frame='year',
animation_group='region',
size='rank',
color='region',
hover_name='region',
trendline='ols'
)
fig.update_layout(title_text='Happiness Rank vs healthy_life_expectancy')
plot(fig, filename='./html/健康预期寿命和幸福水平动态图展示.html')
04
数据建模
我们使用线性回归进行建立一个基准模型,首先筛选一下建模变量,并删除空值记录。
sel_cols = ['happiness', 'gdp_per_capita', 'healthy_life_expectancy',
'freedom_to_life_choise', 'corruption_perceptions', 'generosity']
# 重置索引
df_model.index = range(df_model.shape[0])
df_model = df_all[sel_cols]
# 删除空值
df_model = df_model.dropna()
df_model.head()

from statsmodels.formula.api import ols
# 建立多元线性回归模型
lm_m = ols(formula='happiness ~ gdp_per_capita + healthy_life_expectancy + freedom_to_life_choise + corruption_perceptions + generosity',
data=df_model).fit()
lm_m.summary()
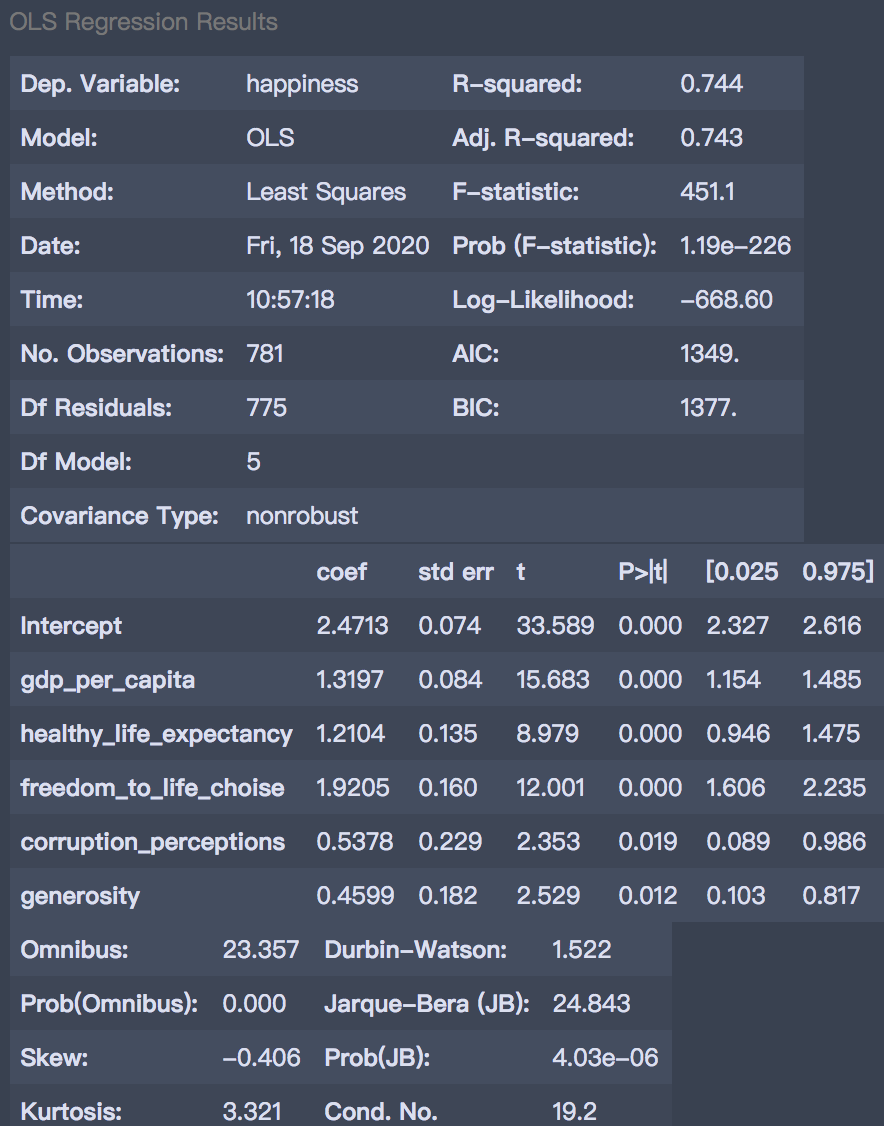
模型的R-squared=0.744,拟合效果尚可,根据模型的参数可知:
变量重要性排序为:gdp_per_capita、freedom_to_life_choise、healthy_life_expectancy、corruption_perceptions、generosity 控制其他变量不变的情况下,GDP指数每增加一个单位,幸福指数增加1.32个单位,健康预期寿命指数每增加一个单位,幸福指数增加1.21个单位。