
GPT-3再进化:通过浏览网页来提高事实准确率
大数据文摘
共 3020字,需浏览 7分钟
· 2021-12-24


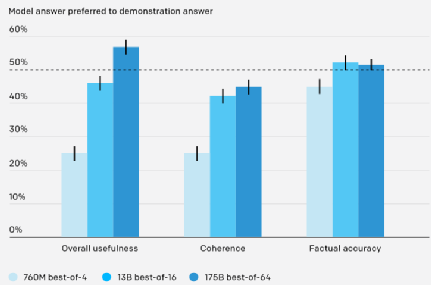

但结果可能是技术性的、主观的或模糊的,评估起来非常具有挑战性。为此,研究人员要求模型引用答案的来源[6],使人们可以通过检查答案来源的可靠性来评估事实准确性。这种方法使问题更容易处理,同时减少了问题的模糊性,对于减少错误标签方面非常重要。
研究者们认为目前的模型还没有能力注意到这些细微差别,所以仍然会犯一些低级错误。但随着人工智能系统的改进,这类问题的答案会越来越重要。因此需要通过交叉学科研究,来制定既实用又有理有据的标准。比如研究者们准备开始考虑模型的可理解性[1]。

评论
HorsemanNode.js 的网页浏览扩展
Horseman是一个Node.js扩展模块,利用PhantomJS实现直接链式API和方便理解的控制流来实现无需图形化界面的网页浏览和数据获取。示例代码:var Horseman = require
HorsemanNode.js 的网页浏览扩展
0
RoboBrowser浏览网页的Pythonic库
RoboBrowser 是一款简单的浏览网页的Pythonic库,无需依赖独立的浏览器。使用示例代码
RoboBrowser浏览网页的Pythonic库
0
RoboBrowser浏览网页的Pythonic库
RoboBrowser是一款简单的浏览网页的Pythonic库,无需依赖独立的浏览器。使用示例代码:import refrom robobrowser import RoboBrowser# Brow
RoboBrowser浏览网页的Pythonic库
0