
入职大厂,齐姐精选的9道Java集合面试题!

快到秋招季/跳槽季,很多读者都有了好消息,在这里也分享给大家:
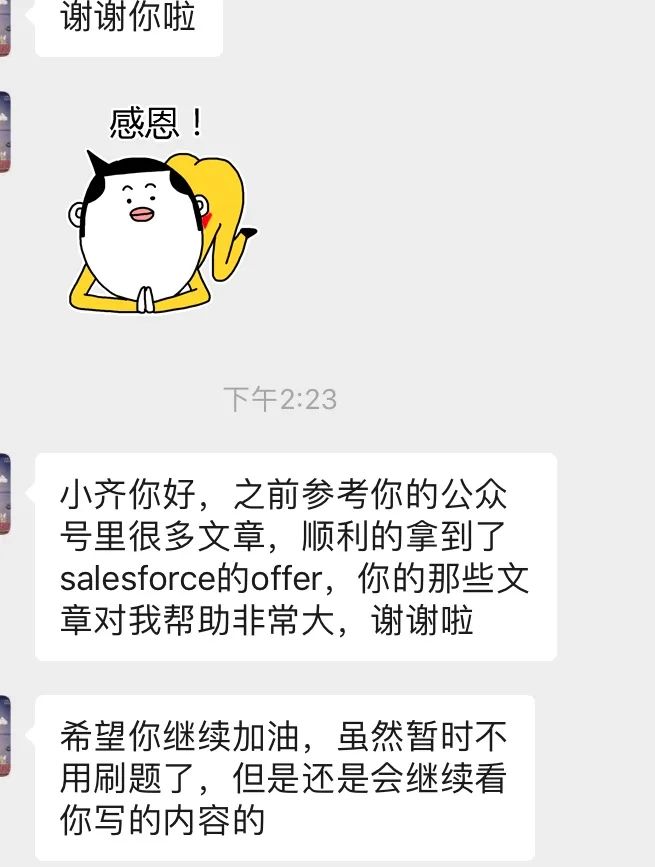
还有很多读者正在刷题、学习准备的,所以最近开启了「齐姐自习室」的云自习活动,里面有很多准备面试、刷题、做自己的项目、学英语的小伙伴,大家每天签到打卡获得积分:
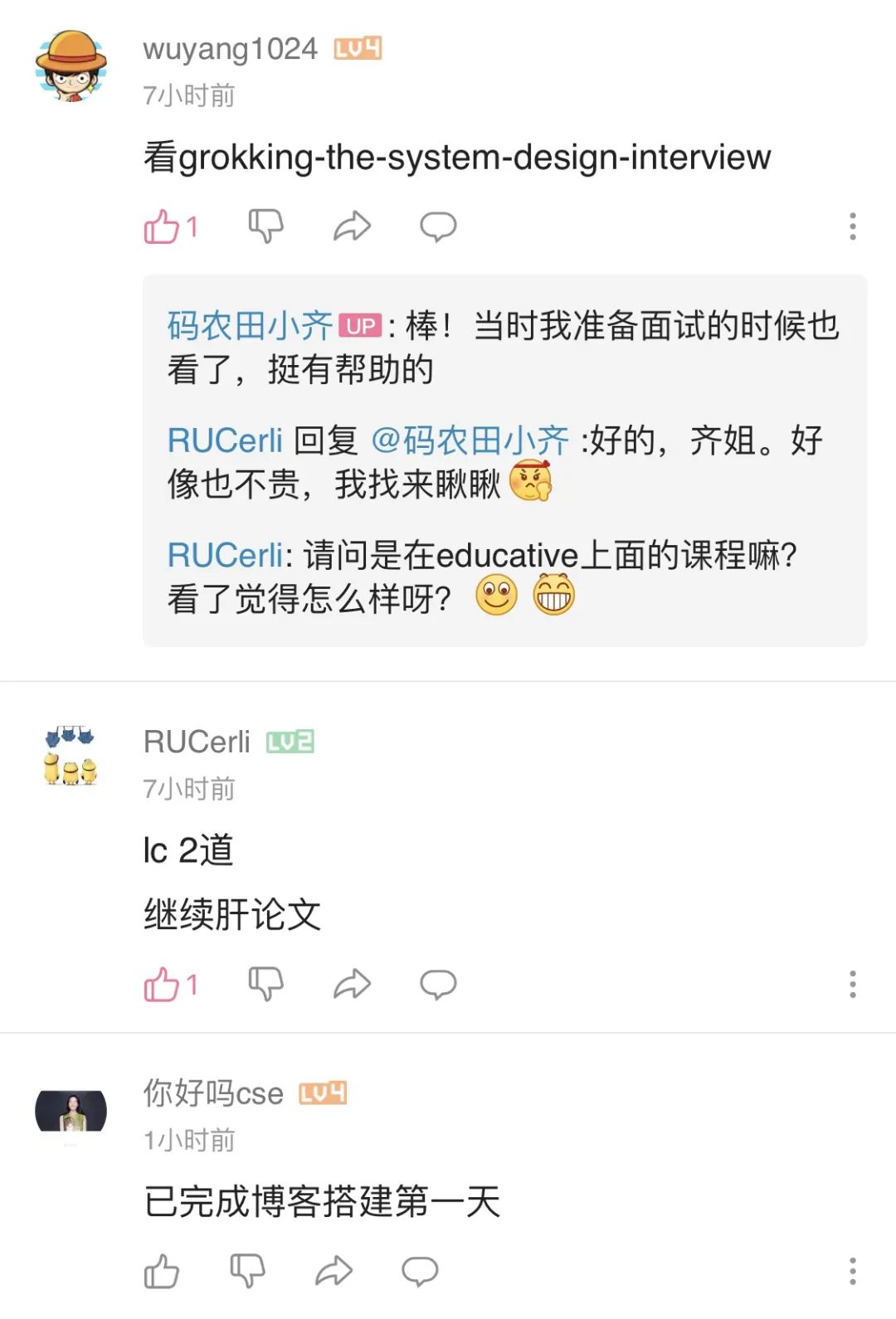
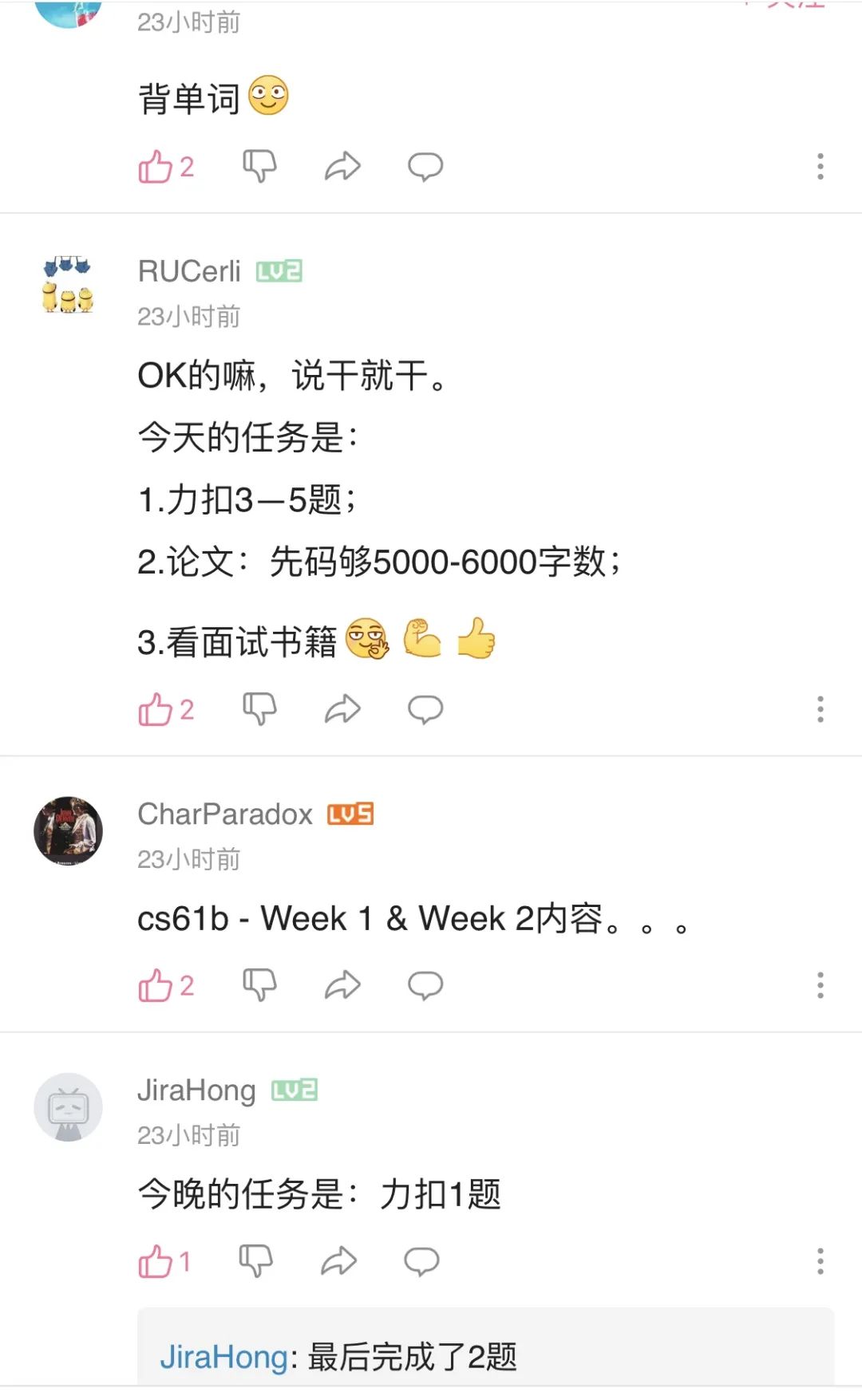
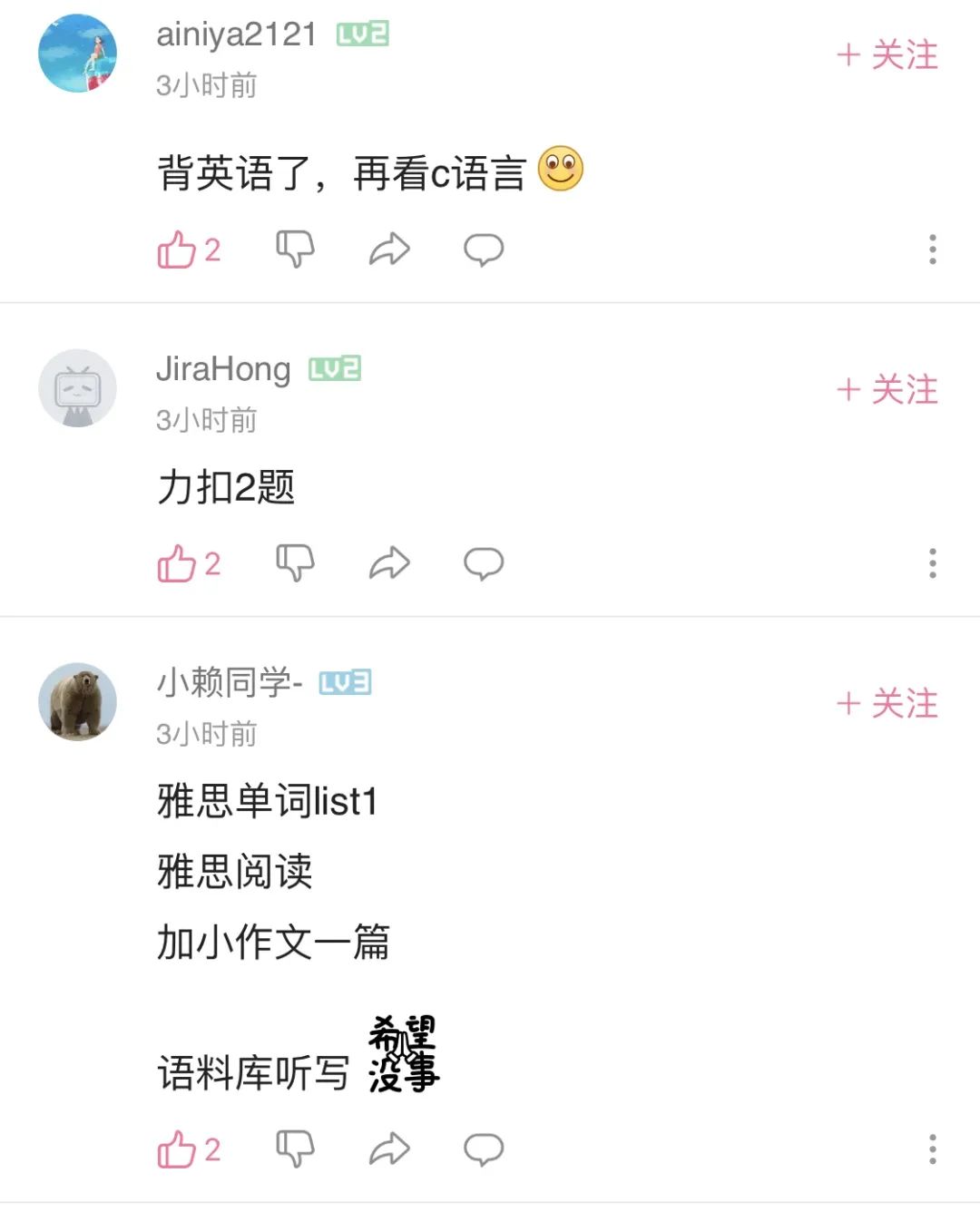
<<< 左右滑动见更多 >>>
有时候你或许不想学习,只是想过来打个卡,但看到大家都在认真学习,也会积极起来
感兴趣的小伙伴可以去 B 站关注我有相关信息,或者加我微信拉你进打卡群。
现在正文开始~

Java 集合框架其实都讲过了,有一篇讲 Collection 的,有一篇讲 HashMap 的,那没有看过的小伙伴快去补下啦,文末也都有链接;看过的小伙伴,那本文就是检测学习成果的时候啦
今天这篇文章是单纯的从面试的角度出发,以回答面试题为线索,再把整个 Java 集合框架复习一遍,希望能帮助大家拿下面试。
先上图:
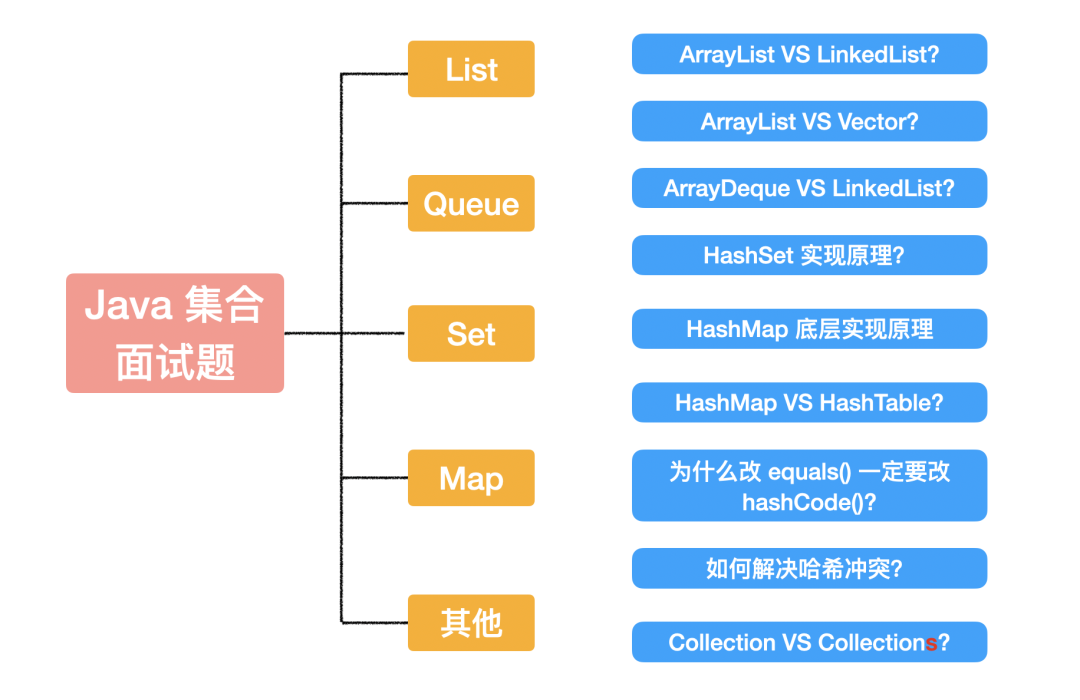
当面试官问问题时,我会先把问题归类,锁定这个知识点在我的知识体系中的位置,然后延展开来想这一块有哪些重点内容,面试官问这个是想考察什么、接下来还想问什么。
这样自己的思路不会混乱,还能预测面试官下一个问题,或者,也可以引导面试官问出你精心准备的问题,这场面试本质上就是你在主导、你在 show off 自己扎实的基础知识和良好的沟通交流能力。
其实我在 LRU 那篇文章里就说到过这个观点,然后就有读者问我,说会不会被面试官看穿?
答:看出来了又怎样?面试官阅人无数,是有可能看出来的,但是也只会莞尔一笑,觉得这个同学很用心。
精心准备面试既是对面试官个人时间的尊重,也是表明了你对这家公司的兴趣,这样的员工不是每家公司都想要的吗?
好了,进入正题,今天就来解决这 9 大面试题。
1. ArrayList vs LinkedList
这题的问法很多,比如
最简单的就直接问 ArrayList 和 LinkedList 的区别和联系;
或者问你什么时候要选择 ArrayList,什么时候选择 LinkedList;
或者在你们聊到某个场景、或者在算法题中,面试官问你如何选择。
万变不离其宗。
首先结论是:
绝大多数的情形下都偏向于用ArrayList,除非你有明确的要使用LinkedList的理由。
如果你不确定用哪个,就用ArrayList。
两者在实现层面的区别是:
ArrayList是用一个可扩容的数组来实现的 (re-sizing array);
LinkedList是用doubly-linked list来实现的。
而数组和链表之间最大的区别就是数组是可以随机访问的(random access)。
这个特点造成了在数组里可以通过下标用 O(1) 的时间拿到任何位置的数,而链表则做不到,只能从头开始逐个遍历。
两者在增删改查操作上的区别:
在「改查」这两个功能上,因为数组能够随机访问,所以 ArrayList 的效率高;
在「增删」这两个功能上,如果不考虑找到这个元素的时间,数组因为物理上的连续性,当要增删元素时,在尾部还好,但是其他地方就会导致后续元素都要移动,所以效率较低;而链表则可以轻松的断开和下一个元素的连接,直接插入新元素或者移除旧元素。
但是呢,实际上你不能不考虑找到元素的时间啊。。。虽然 LinkedList 可以 O(1) 的时间插入和删除元素,可以你得先找到地方啊!
不是有个例子么,修理这个零件只需要 1 美元,但是找到这个零件需要 9999 美元。我们平时修 bug 也是如此,重点是找到 root cause 的过程。
而且如果是在尾部操作,数据量大时 ArrayList 会更快的。
事实上,LinkedList 是很多性能问题的 bug,那么为什么呢?
因为 ListNode 在物理内存里的不连续,导致它用了很多小的内存片段,这会影响很多进程的性能以及 cache-locality(局部性);所以即便是理论上的时间复杂度和 ArrayList 一样时,也会导致实际上比 ArrayList 慢很多。
2. ArrayList vs Vector
答:
Vector是线程安全的,而ArrayList是线程不安全的;
扩容时扩多少的区别,文邹邹的说法就是data growth methods不同,
Vector默认是扩大至 2 倍;
ArrayList默认是扩大至 1.5 倍。
回顾下这张图,
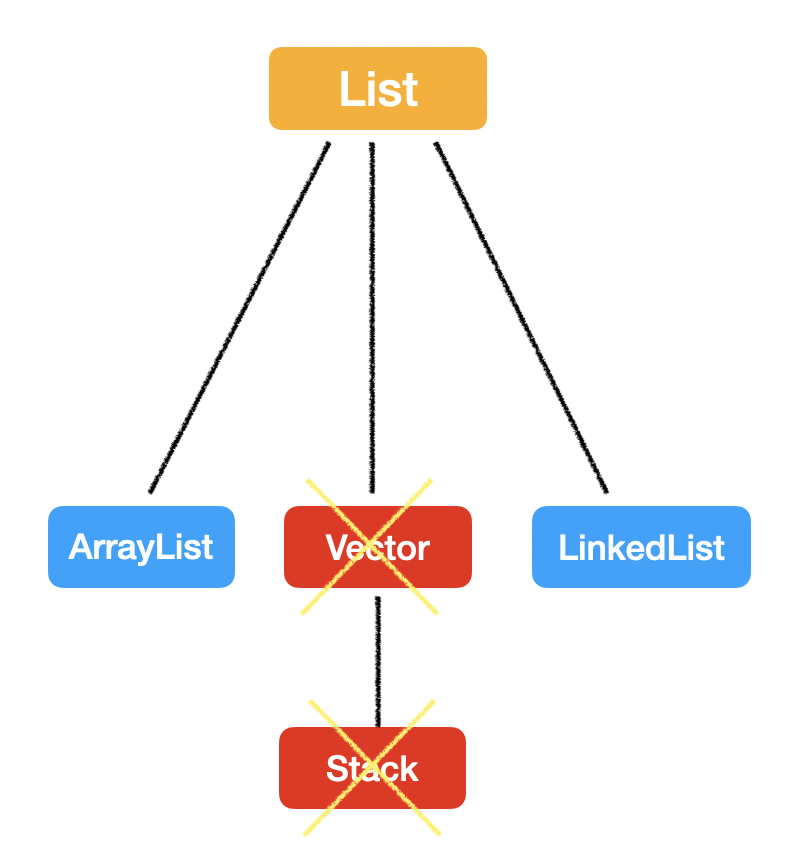
Vector 和 ArrayList 一样,也是继承自 java.util.AbstractList,底层也是用数组来实现的。
但是现在已经被弃用了,因为它是线程安全的。任何好处都是有代价的,线程安全的代价就是效率低,在某些系统里很容易成为瓶颈,所以现在大家不再在数据结构的层面加 synchronized,而是把这个任务转移给我们程序员。
那怎么知道扩容扩多少的呢?
看源码:
 这是 Vecotr 的扩容实现,因为通常并不定义 capacityIncrement,所以默认情况下它是扩容两倍。
这是 Vecotr 的扩容实现,因为通常并不定义 capacityIncrement,所以默认情况下它是扩容两倍。
VS
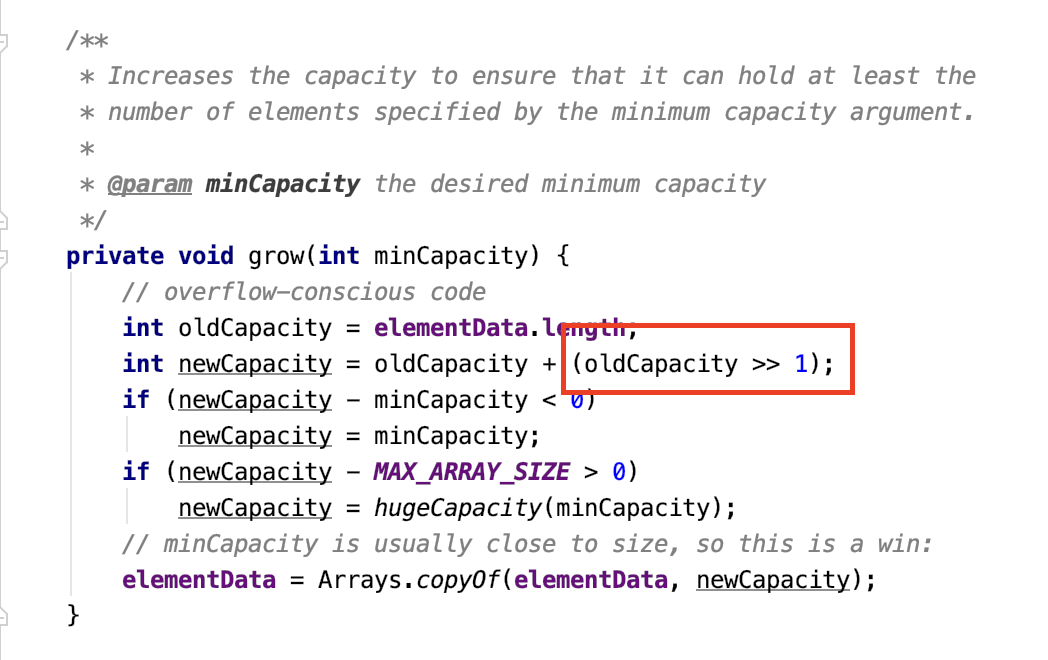
这是 ArrayList 的扩容实现,算术右移操作是把这个数的二进制往右移动一位,最左边补符号位,但是因为容量没有负数,所以还是补 0.
那右移一位的效果就是除以 2,那么定义的新容量就是原容量的 1.5 倍。
3. ArrayDeque vs LinkedList
首先要清楚它们之间的关系:
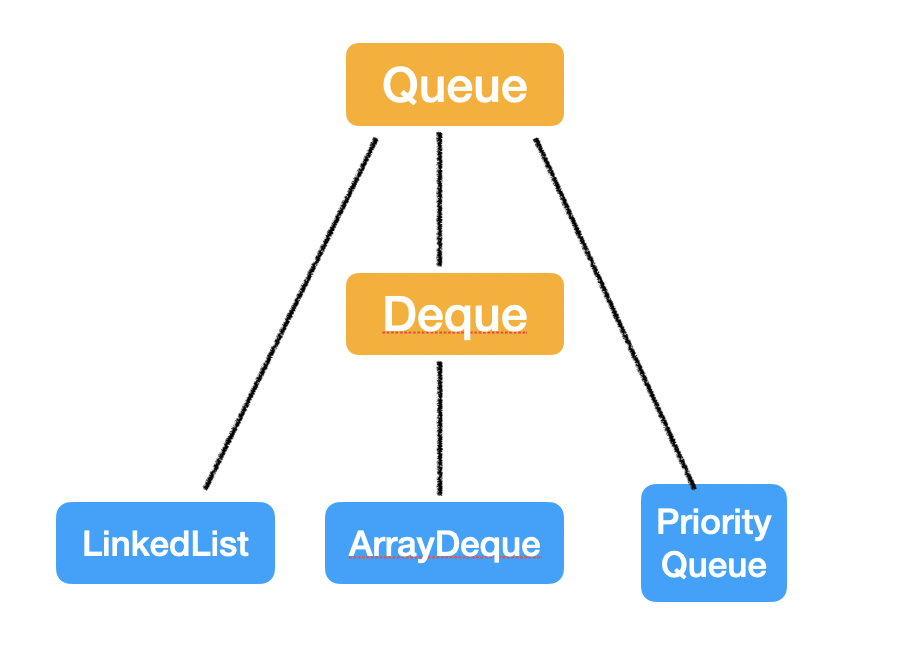
答:
ArrayDeque 是一个可扩容的数组,LinkedList 是链表结构;
ArrayDeque 里不可以存 null 值,但是 LinkedList 可以;
ArrayDeque 在操作头尾端的增删操作时更高效,但是 LinkedList 只有在当要移除中间某个元素且已经找到了这个元素后的移除才是 O(1) 的;
ArrayDeque 在内存使用方面更高效。
所以,只要不是必须要存 null 值,就选择 ArrayDeque 吧!
那如果是一个很资深的面试官问你,什么情况下你要选择用 LinkedList 呢?
答:Java 6 以前。因为 ArrayDeque 在 Java 6 之后才有的。为了版本兼容的问题,实际工作中我们不得不做一些妥协。
4. HashSet 实现原理
答:
HashSet 是基于 HashMap 来实现的,底层采用 Hashmap 的 key 来储存元素,主要特点是无序的,基本操作都是 O(1) 的时间复杂度,很快。所以它的实现原理可以用 HashMap 的来解释。
5. HashMap 实现原理
答:
在JDK1.6/1.7,数组 + 链表;
在JDK 1.8,数组 + 红黑树。
具体说来,
对于 HashMap 中的每个 key,首先通过 hash function 计算出一个哈希值,这个哈希值就代表了在桶里的编号,而“桶”实际上是通过数组来实现的,但是桶有可能比数组大呀,所以把这个哈希值模上数组的长度得到它在数组的 index,就这样把它放在了数组里。
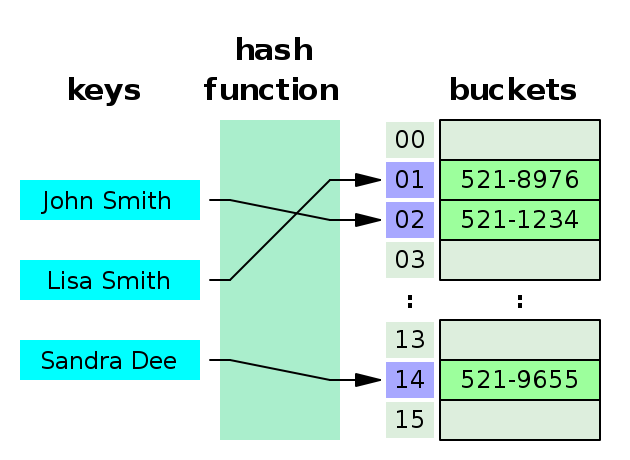
这是理想情况下的 HashMap,但现实中,不同的元素可能会算出相同的哈希值,这就是哈希碰撞,即多个 key 对应了同一个桶。
为了解决哈希碰撞呢,Java 采用的是 Separate chaining 的解决方式,就是在碰撞的地方加个链子,也就是上文说的链表或者红黑树。
具体的 put() 和 get()这两个重要 API 的操作过程和原理,大家可以在公众号后台回复「HashMap」获取文章阅读。
6. HashMap vs HashTable
答:
Hashtable是线程安全的,HashMap并非线程安全;
HashMap允许key中有null值,Hashtable是不允许的。这样的好处就是可以给一个默认值。
其实 HashMap 与 Hashtable 的关系,就像 ArrayList 与 Vector,以及 StringBuilder 与 StringBuffer。
Hashtable 是早期 JDK 提供的接口,HashMap 是新版的。这些新版的改进都是因为 Java 5.0 之后允许数据结构不考虑线程安全的问题,因为实际工作中我们发现没有必要在数据结构的层面上上锁,加锁和放锁在系统中是有开销的,内部锁有时候会成为程序的瓶颈。
所以 HashMap, ArrayList, StringBuilder 不再考虑线程安全的问题,性能提升了很多。
7. 为什么改 equals() 一定要改 hashCode()?
答:
首先基于一个假设:任何两个 object 的 hashCode 都是不同的。也就是 hash function 是有效的。
那么在这个条件下,有两个 object 是相等的,那如果不重写 hashCode(),算出来的哈希值都不一样,就会去到不同的 buckets 了,就迷失在茫茫人海中了,再也无法相认,就和 equals() 条件矛盾了,证毕。
hashCode()决定了key放在这个桶里的编号,也就是在数组里的index;
equals()是用来比较两个object是否相同的。
8. 如何解决哈希冲突?
一般来说哈希冲突有两大类解决方式:
Separate chaining
Open addressing
Java 中采用的是第一种 Separate chaining,即在发生碰撞的那个桶后面再加一条“链”来存储。
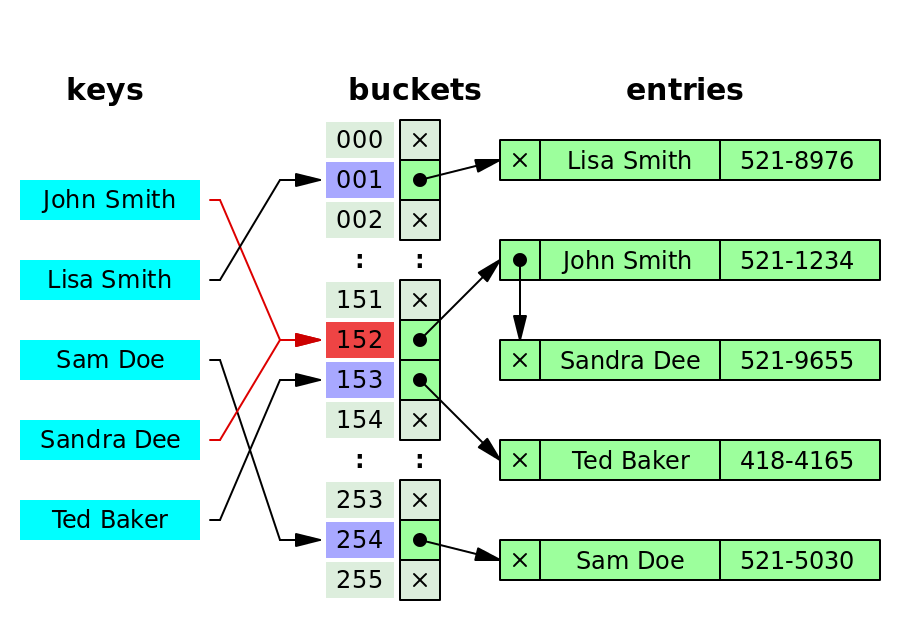
那么这个“链”使用的具体是什么数据结构,不同的版本稍有不同,上文也提到过了:
JDK1.6 和 1.7 是用链表存储的,这样如果碰撞很多的话,就变成了在链表上的查找,worst case 就是 O(n);
JDK 1.8 进行了优化,当链表长度较大时(超过 8),会采用红黑树来存储,这样大大提高了查找效率。
(话说,这个还真的喜欢考,已经在多次面试中被问过了,还有面试官问为什么是超过“8”才用红黑树 ?)
第二种方法 open addressing 也是非常重要的思想,因为在真实的分布式系统里,有很多地方会用到 hash 的思想但又不适合用 seprate chaining。
这种方法是顺序查找,如果这个桶里已经被占了,那就按照“某种方式”继续找下一个没有被占的桶,直到找到第一个空的。
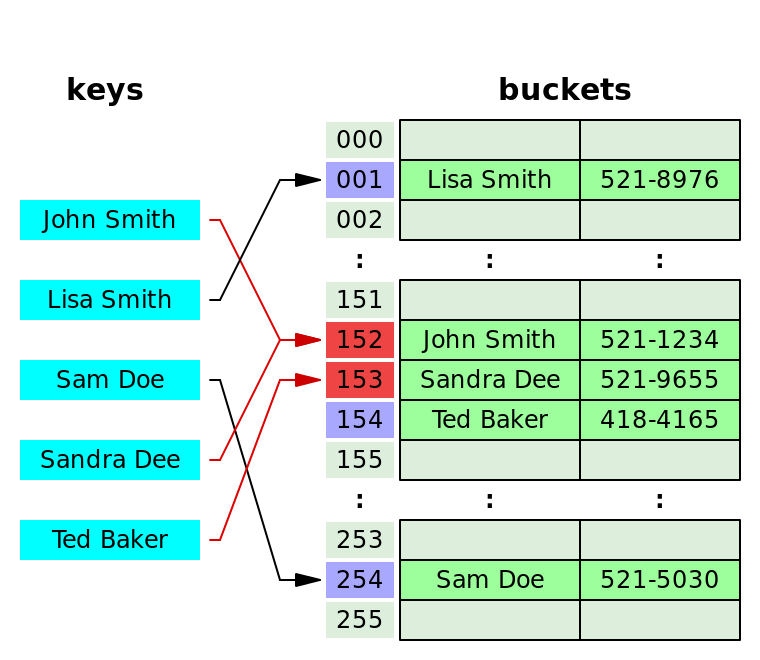
如图所示,John Smith 和 Sandra Dee 发生了哈希冲突,都被计算到 152 号桶,于是 Sandra 就去了下一个空位 - 153 号桶,当然也会对之后的 key 发生影响:Ted Baker 计算结果本应是放在 153 号的,但鉴于已经被 Sandra 占了,就只能再去下一个空位了,所以到了 154 号。
这种方式叫做 Linear probing 线性探查,就像上图所示,一个个的顺着找下一个空位。当然还有其他的方式,比如去找平方数 Double hashing.
9. Collection vs Collections
这俩看似相近,实则相差十万八千里,就好像好人和好人卡的区别似的。
Collection 是
集合接口;
是
Java 集合框架的root interface;
落脚点是一个
interface;
包含了以下这些接口和类:
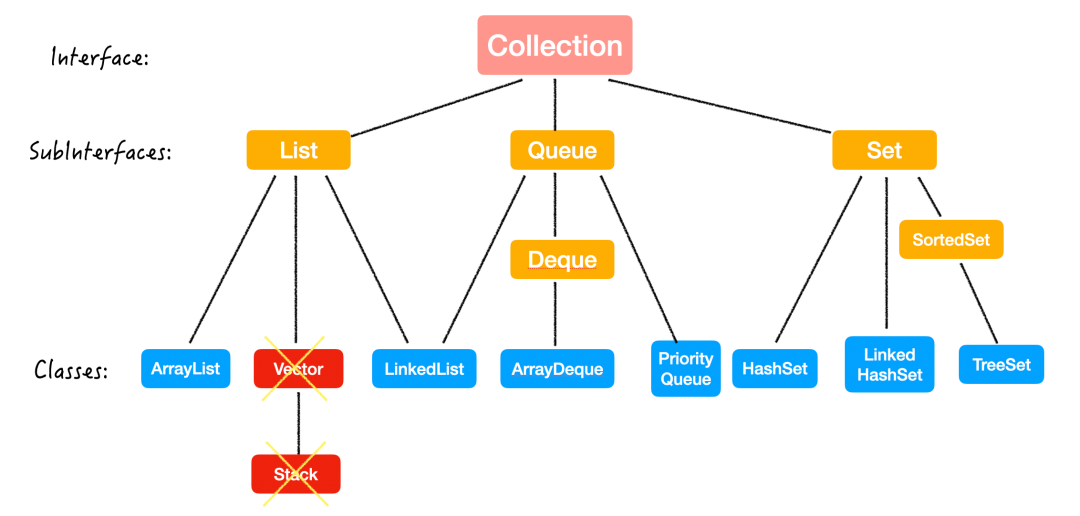
想系统学习 Collection,可以在公众号内回复「集合」,获取爆款文章。
而 Collections 是工具类 utility class,是集合的操作类,提供了一些静态方法供我们使用,比如:
addAll()
binarySearch()
sort()
shuffle()
reverse()
好了,以上就是集合的常考面试题汇总和答案了,希望不仅能帮助你拿下面试,也能真的理解透彻,灵活运用。

2. 一个空格引发的“惨案“
3. 大型网站架构演化发展历程

扫码二维码关注我
·end·
—如果本文有帮助,请分享到朋友圈吧—
我们一起愉快的玩耍!

你点的每个赞,我都认真当成了喜欢