
BeanUtils、BeanCopier、Dozer、Orika 哪个性能最强?
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


来源:https://albenw.github.io/posts/f6a7daea/
背景
在分层的代码架构中,层与层之间的对象避免不了要做很多转换、赋值等操作,这些操作重复且繁琐,于是乎催生出很多工具来优雅,高效地完成这个操作,有BeanUtils、BeanCopier、Dozer、Orika等等,本文将讲述上面几个工具的使用、性能对比及原理分析。
性能分析
其实这几个工具要做的事情很简单,而且在使用上也是类似的,所以我觉得先给大家看看性能分析的对比结果,让大家有一个大概的认识。我是使用JMH来做性能分析的,代码如下:
要复制的对象比较简单,包含了一些基本类型;有一次warmup,因为一些工具是需要“预编译”和做缓存的,这样做对比才会比较客观;分别复制1000、10000、100000个对象,这是比较常用数量级了吧。
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Fork(1)
@Warmup(iterations = 1)
@State(Scope.Benchmark)
public class BeanMapperBenchmark {
@Param({"1000", "10000", "100000"})
private int times;
private int time;
private static MapperFactory mapperFactory;
private static Mapper mapper;
static {
mapperFactory = new DefaultMapperFactory.Builder().build();
mapperFactory.classMap(SourceVO.class, TargetVO.class)
.byDefault()
.register();
mapper = DozerBeanMapperBuilder.create()
.withMappingBuilder(new BeanMappingBuilder() {
@Override
protected void configure() {
mapping(SourceVO.class, TargetVO.class)
.fields("fullName", "name")
.exclude("in");
}
}).build();
}
public static void main(String[] args) throws Exception {
Options options = new OptionsBuilder()
.include(BeanMapperBenchmark.class.getName()).measurementIterations(3)
.build();
new Runner(options).run();
}
@Setup
public void prepare() {
this.time = times;
}
@Benchmark
public void springBeanUtilTest(){
SourceVO sourceVO = getSourceVO();
for(int i = 0; i < time; i++){
TargetVO targetVO = new TargetVO();
BeanUtils.copyProperties(sourceVO, targetVO);
}
}
@Benchmark
public void apacheBeanUtilTest() throws Exception{
SourceVO sourceVO = getSourceVO();
for(int i = 0; i < time; i++){
TargetVO targetVO = new TargetVO();
org.apache.commons.beanutils.BeanUtils.copyProperties(targetVO, sourceVO);
}
}
@Benchmark
public void beanCopierTest(){
SourceVO sourceVO = getSourceVO();
for(int i = 0; i < time; i++){
TargetVO targetVO = new TargetVO();
BeanCopier bc = BeanCopier.create(SourceVO.class, TargetVO.class, false);
bc.copy(sourceVO, targetVO, null);
}
}
@Benchmark
public void dozerTest(){
SourceVO sourceVO = getSourceVO();
for(int i = 0; i < time; i++){
TargetVO map = mapper.map(sourceVO, TargetVO.class);
}
}
@Benchmark
public void orikaTest(){
SourceVO sourceVO = getSourceVO();
for(int i = 0; i < time; i++){
MapperFacade mapper = mapperFactory.getMapperFacade();
TargetVO map = mapper.map(sourceVO, TargetVO.class);
}
}
private SourceVO getSourceVO(){
SourceVO sourceVO = new SourceVO();
sourceVO.setP1(1);
sourceVO.setP2(2L);
sourceVO.setP3(new Integer(3).byteValue());
sourceVO.setDate1(new Date());
sourceVO.setPattr1("1");
sourceVO.setIn(new SourceVO.Inner(1));
sourceVO.setFullName("alben");
return sourceVO;
}
}
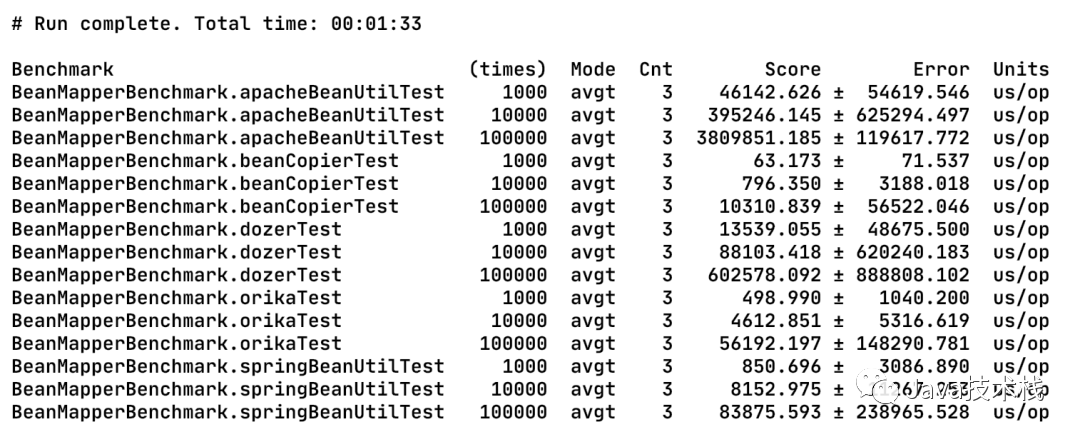
Score表示的是平均运行时间,单位是微秒。从执行效率来看,可以看出 beanCopier > orika > springBeanUtil > dozer > apacheBeanUtil。这样的结果跟它们各自的实现原理有很大的关系,
下面将详细每个工具的使用及实现原理。
Spring的BeanUtils
使用
这个工具可能是大家日常使用最多的,因为是Spring自带的,使用也简单:BeanUtils.copyProperties(sourceVO, targetVO);
原理
Spring BeanUtils的实现原理也比较简答,就是通过Java的Introspector获取到两个类的PropertyDescriptor,对比两个属性具有相同的名字和类型,如果是,则进行赋值(通过ReadMethod获取值,通过WriteMethod赋值),否则忽略。
为了提高性能Spring对BeanInfo和PropertyDescriptor进行了缓存。
(源码基于:org.springframework:spring-beans:4.3.9.RELEASE)
/**
* Copy the property values of the given source bean into the given target bean.
* <p>Note: The source and target classes do not have to match or even be derived
* from each other, as long as the properties match. Any bean properties that the
* source bean exposes but the target bean does not will silently be ignored.
* @param source the source bean
* @param target the target bean
* @param editable the class (or interface) to restrict property setting to
* @param ignoreProperties array of property names to ignore
* @throws BeansException if the copying failed
* @see BeanWrapper
*/
private static void copyProperties(Object source, Object target, Class<?> editable, String... ignoreProperties)
throws BeansException {
Assert.notNull(source, "Source must not be null");
Assert.notNull(target, "Target must not be null");
Class<?> actualEditable = target.getClass();
if (editable != null) {
if (!editable.isInstance(target)) {
throw new IllegalArgumentException("Target class [" + target.getClass().getName() +
"] not assignable to Editable class [" + editable.getName() + "]");
}
actualEditable = editable;
}
//获取target类的属性(有缓存)
PropertyDescriptor[] targetPds = getPropertyDescriptors(actualEditable);
List<String> ignoreList = (ignoreProperties != null ? Arrays.asList(ignoreProperties) : null);
for (PropertyDescriptor targetPd : targetPds) {
Method writeMethod = targetPd.getWriteMethod();
if (writeMethod != null && (ignoreList == null || !ignoreList.contains(targetPd.getName()))) {
//获取source类的属性(有缓存)
PropertyDescriptor sourcePd = getPropertyDescriptor(source.getClass(), targetPd.getName());
if (sourcePd != null) {
Method readMethod = sourcePd.getReadMethod();
if (readMethod != null &&
//判断target的setter方法入参和source的getter方法返回类型是否一致
ClassUtils.isAssignable(writeMethod.getParameterTypes()[0], readMethod.getReturnType())) {
try {
if (!Modifier.isPublic(readMethod.getDeclaringClass().getModifiers())) {
readMethod.setAccessible(true);
}
//获取源值
Object value = readMethod.invoke(source);
if (!Modifier.isPublic(writeMethod.getDeclaringClass().getModifiers())) {
writeMethod.setAccessible(true);
}
//赋值到target
writeMethod.invoke(target, value);
}
catch (Throwable ex) {
throw new FatalBeanException(
"Could not copy property '" + targetPd.getName() + "' from source to target", ex);
}
}
}
}
}
}
小结
Spring BeanUtils的实现就是这么简洁,这也是它性能比较高的原因。
不过,过于简洁就失去了灵活性和可扩展性了,Spring BeanUtils的使用限制也比较明显,要求类属性的名字和类型一致,这点在使用时要注意。
Apache的BeanUtils
使用
Apache的BeanUtils和Spring的BeanUtils的使用是一样的:
BeanUtils.copyProperties(targetVO, sourceVO);
要注意,source和target的入参位置不同。
原理
Apache的BeanUtils的实现原理跟Spring的BeanUtils一样,也是主要通过Java的Introspector机制获取到类的属性来进行赋值操作,对BeanInfo和PropertyDescriptor同样有缓存,但是Apache BeanUtils加了一些不那么使用的特性(包括支持Map类型、支持自定义的DynaBean类型、支持属性名的表达式等等)在里面,使得性能相对Spring的BeanUtils来说有所下降。
(源码基于:commons-beanutils:commons-beanutils:1.9.3)
public void copyProperties(final Object dest, final Object orig)
throws IllegalAccessException, InvocationTargetException {
if (dest == null) {
throw new IllegalArgumentException
("No destination bean specified");
}
if (orig == null) {
throw new IllegalArgumentException("No origin bean specified");
}
if (log.isDebugEnabled()) {
log.debug("BeanUtils.copyProperties(" + dest + ", " +
orig + ")");
}
// Apache Common自定义的DynaBean
if (orig instanceof DynaBean) {
final DynaProperty[] origDescriptors =
((DynaBean) orig).getDynaClass().getDynaProperties();
for (DynaProperty origDescriptor : origDescriptors) {
final String name = origDescriptor.getName();
// Need to check isReadable() for WrapDynaBean
// (see Jira issue# BEANUTILS-61)
if (getPropertyUtils().isReadable(orig, name) &&
getPropertyUtils().isWriteable(dest, name)) {
final Object value = ((DynaBean) orig).get(name);
copyProperty(dest, name, value);
}
}
// Map类型
} else if (orig instanceof Map) {
@SuppressWarnings("unchecked")
final
// Map properties are always of type <String, Object>
Map<String, Object> propMap = (Map<String, Object>) orig;
for (final Map.Entry<String, Object> entry : propMap.entrySet()) {
final String name = entry.getKey();
if (getPropertyUtils().isWriteable(dest, name)) {
copyProperty(dest, name, entry.getValue());
}
}
// 标准的JavaBean
} else {
final PropertyDescriptor[] origDescriptors =
//获取PropertyDescriptor
getPropertyUtils().getPropertyDescriptors(orig);
for (PropertyDescriptor origDescriptor : origDescriptors) {
final String name = origDescriptor.getName();
if ("class".equals(name)) {
continue; // No point in trying to set an object's class
}
//是否可读和可写
if (getPropertyUtils().isReadable(orig, name) &&
getPropertyUtils().isWriteable(dest, name)) {
try {
//获取源值
final Object value =
getPropertyUtils().getSimpleProperty(orig, name);
//赋值操作
copyProperty(dest, name, value);
} catch (final NoSuchMethodException e) {
// Should not happen
}
}
}
}
}
小结
Apache BeanUtils的实现跟Spring BeanUtils总体上类似,但是性能却低很多,这个可以从上面性能比较看出来。阿里的Java规范是不建议使用的。
BeanCopier
使用
BeanCopier在cglib包里,它的使用也比较简单:
@Test
public void beanCopierSimpleTest() {
SourceVO sourceVO = getSourceVO();
log.info("source={}", GsonUtil.toJson(sourceVO));
TargetVO targetVO = new TargetVO();
BeanCopier bc = BeanCopier.create(SourceVO.class, TargetVO.class, false);
bc.copy(sourceVO, targetVO, null);
log.info("target={}", GsonUtil.toJson(targetVO));
}
只需要预先定义好要转换的source类和target类就好了,可以选择是否使用Converter,这个下面会说到。
在上面的性能测试中,BeanCopier是所有中表现最好的,那么我们分析一下它的实现原理。
原理
BeanCopier的实现原理跟BeanUtils截然不同,它不是利用反射对属性进行赋值,而是直接使用cglib来生成带有的get/set方法的class类,然后执行。由于是直接生成字节码执行,所以BeanCopier的性能接近手写
get/set。
BeanCopier.create方法
public static BeanCopier create(Class source, Class target, boolean useConverter) {
Generator gen = new Generator();
gen.setSource(source);
gen.setTarget(target);
gen.setUseConverter(useConverter);
return gen.create();
}
public BeanCopier create() {
Object key = KEY_FACTORY.newInstance(source.getName(), target.getName(), useConverter);
return (BeanCopier)super.create(key);
}
这里的意思是用KEY_FACTORY创建一个BeanCopier出来,然后调用create方法来生成字节码。
KEY_FACTORY其实就是用cglib通过BeanCopierKey接口生成出来的一个类
private static final BeanCopierKey KEY_FACTORY = (BeanCopierKey)KeyFactory.create(BeanCopierKey.class);
interface BeanCopierKey {
public Object newInstance(String source, String target, boolean useConverter);
}
通过设置
System.setProperty(DebuggingClassWriter.DEBUG_LOCATION_PROPERTY, "path");
可以让cglib输出生成类的class文件,我们可以反编译看看里面的代码
下面是KEY_FACTORY的类
public class BeanCopier$BeanCopierKey$$KeyFactoryByCGLIB$$f32401fd extends KeyFactory implements BeanCopierKey {
private final String FIELD_0;
private final String FIELD_1;
private final boolean FIELD_2;
public BeanCopier$BeanCopierKey$$KeyFactoryByCGLIB$$f32401fd() {
}
public Object newInstance(String var1, String var2, boolean var3) {
return new BeanCopier$BeanCopierKey$$KeyFactoryByCGLIB$$f32401fd(var1, var2, var3);
}
public BeanCopier$BeanCopierKey$$KeyFactoryByCGLIB$$f32401fd(String var1, String var2, boolean var3) {
this.FIELD_0 = var1;
this.FIELD_1 = var2;
this.FIELD_2 = var3;
}
//省去hashCode等方法。。。
}
继续跟踪Generator.create方法,由于Generator是继承AbstractClassGenerator,这个AbstractClassGenerator是cglib用来生成字节码的一个模板类,Generator的super.create其实调用AbstractClassGenerator的create方法,最终会调用到Generator的模板方法generateClass方法,我们不去细究AbstractClassGenerator的细节,重点看generateClass。
这个是一个生成java类的方法,理解起来就好像我们平时写代码一样。
public void generateClass(ClassVisitor v) {
Type sourceType = Type.getType(source);
Type targetType = Type.getType(target);
ClassEmitter ce = new ClassEmitter(v);
//开始“写”类,这里有修饰符、类名、父类等信息
ce.begin_class(Constants.V1_2,
Constants.ACC_PUBLIC,
getClassName(),
BEAN_COPIER,
null,
Constants.SOURCE_FILE);
//没有构造方法
EmitUtils.null_constructor(ce);
//开始“写”一个方法,方法名是copy
CodeEmitter e = ce.begin_method(Constants.ACC_PUBLIC, COPY, null);
//通过Introspector获取source类和target类的PropertyDescriptor
PropertyDescriptor[] getters = ReflectUtils.getBeanGetters(source);
PropertyDescriptor[] setters = ReflectUtils.getBeanSetters(target);
Map names = new HashMap();
for (int i = 0; i < getters.length; i++) {
names.put(getters[i].getName(), getters[i]);
}
Local targetLocal = e.make_local();
Local sourceLocal = e.make_local();
if (useConverter) {
e.load_arg(1);
e.checkcast(targetType);
e.store_local(targetLocal);
e.load_arg(0);
e.checkcast(sourceType);
e.store_local(sourceLocal);
} else {
e.load_arg(1);
e.checkcast(targetType);
e.load_arg(0);
e.checkcast(sourceType);
}
//通过属性名来生成转换的代码
//以setter作为遍历
for (int i = 0; i < setters.length; i++) {
PropertyDescriptor setter = setters[i];
//根据setter的name获取getter
PropertyDescriptor getter = (PropertyDescriptor)names.get(setter.getName());
if (getter != null) {
//获取读写方法
MethodInfo read = ReflectUtils.getMethodInfo(getter.getReadMethod());
MethodInfo write = ReflectUtils.getMethodInfo(setter.getWriteMethod());
//如果用了useConverter,则进行下面的拼装代码方式
if (useConverter) {
Type setterType = write.getSignature().getArgumentTypes()[0];
e.load_local(targetLocal);
e.load_arg(2);
e.load_local(sourceLocal);
e.invoke(read);
e.box(read.getSignature().getReturnType());
EmitUtils.load_class(e, setterType);
e.push(write.getSignature().getName());
e.invoke_interface(CONVERTER, CONVERT);
e.unbox_or_zero(setterType);
e.invoke(write);
//compatible用来判断getter和setter是否类型一致
} else if (compatible(getter, setter)) {
e.dup2();
e.invoke(read);
e.invoke(write);
}
}
}
e.return_value();
e.end_method();
ce.end_class();
}
private static boolean compatible(PropertyDescriptor getter, PropertyDescriptor setter) {
// TODO: allow automatic widening conversions?
return setter.getPropertyType().isAssignableFrom(getter.getPropertyType());
}
即使没有使用过cglib也能读懂生成代码的流程吧,我们看看没有使用useConverter的情况下生成的代码:
public class Object$$BeanCopierByCGLIB$$d1d970c8 extends BeanCopier {
public Object$$BeanCopierByCGLIB$$d1d970c8() {
}
public void copy(Object var1, Object var2, Converter var3) {
TargetVO var10000 = (TargetVO)var2;
SourceVO var10001 = (SourceVO)var1;
var10000.setDate1(((SourceVO)var1).getDate1());
var10000.setIn(var10001.getIn());
var10000.setListData(var10001.getListData());
var10000.setMapData(var10001.getMapData());
var10000.setP1(var10001.getP1());
var10000.setP2(var10001.getP2());
var10000.setP3(var10001.getP3());
var10000.setPattr1(var10001.getPattr1());
}
}
public class Object$$BeanCopierByCGLIB$$d1d970c7 extends BeanCopier {
private static final Class CGLIB$load_class$java$2Eutil$2EDate;
private static final Class CGLIB$load_class$beanmapper_compare$2Evo$2ESourceVO$24Inner;
private static final Class CGLIB$load_class$java$2Eutil$2EList;
private static final Class CGLIB$load_class$java$2Eutil$2EMap;
private static final Class CGLIB$load_class$java$2Elang$2EInteger;
private static final Class CGLIB$load_class$java$2Elang$2ELong;
private static final Class CGLIB$load_class$java$2Elang$2EByte;
private static final Class CGLIB$load_class$java$2Elang$2EString;
public Object$$BeanCopierByCGLIB$$d1d970c7() {
}
public void copy(Object var1, Object var2, Converter var3) {
TargetVO var4 = (TargetVO)var2;
SourceVO var5 = (SourceVO)var1;
var4.setDate1((Date)var3.convert(var5.getDate1(), CGLIB$load_class$java$2Eutil$2EDate, "setDate1"));
var4.setIn((Inner)var3.convert(var5.getIn(), CGLIB$load_class$beanmapper_compare$2Evo$2ESourceVO$24Inner, "setIn"));
var4.setListData((List)var3.convert(var5.getListData(), CGLIB$load_class$java$2Eutil$2EList, "setListData"));
var4.setMapData((Map)var3.convert(var5.getMapData(), CGLIB$load_class$java$2Eutil$2EMap, "setMapData"));
var4.setP1((Integer)var3.convert(var5.getP1(), CGLIB$load_class$java$2Elang$2EInteger, "setP1"));
var4.setP2((Long)var3.convert(var5.getP2(), CGLIB$load_class$java$2Elang$2ELong, "setP2"));
var4.setP3((Byte)var3.convert(var5.getP3(), CGLIB$load_class$java$2Elang$2EByte, "setP3"));
var4.setPattr1((String)var3.convert(var5.getPattr1(), CGLIB$load_class$java$2Elang$2EString, "setPattr1"));
var4.setSeq((Long)var3.convert(var5.getSeq(), CGLIB$load_class$java$2Elang$2ELong, "setSeq"));
}
static void CGLIB$STATICHOOK1() {
CGLIB$load_class$java$2Eutil$2EDate = Class.forName("java.util.Date");
CGLIB$load_class$beanmapper_compare$2Evo$2ESourceVO$24Inner = Class.forName("beanmapper_compare.vo.SourceVO$Inner");
CGLIB$load_class$java$2Eutil$2EList = Class.forName("java.util.List");
CGLIB$load_class$java$2Eutil$2EMap = Class.forName("java.util.Map");
CGLIB$load_class$java$2Elang$2EInteger = Class.forName("java.lang.Integer");
CGLIB$load_class$java$2Elang$2ELong = Class.forName("java.lang.Long");
CGLIB$load_class$java$2Elang$2EByte = Class.forName("java.lang.Byte");
CGLIB$load_class$java$2Elang$2EString = Class.forName("java.lang.String");
}
static {
CGLIB$STATICHOOK1();
}
}
小结
BeanCopier性能确实很高,但从源码可以看出BeanCopier只会拷贝名称和类型都相同的属性,而且如果一旦使用Converter,BeanCopier只使用Converter定义的规则去拷贝属性,所以在convert方法中要考虑所有的属性。
Dozer
使用
上面提到的BeanUtils和BeanCopier都是功能比较简单的,需要属性名称一样,甚至类型也要一样。但是在大多数情况下这个要求就相对苛刻了,要知道有些VO由于各种原因不能修改,有些是外部接口SDK的对象,
有些对象的命名规则不同,例如有驼峰型的,有下划线的等等,各种什么情况都有。所以我们更加需要的是更加灵活丰富的功能,甚至可以做到定制化的转换。
Dozer就提供了这些功能,有支持同名隐式映射,支持基本类型互相转换,支持显示指定映射关系,支持exclude字段,支持递归匹配映射,支持深度匹配,支持Date to String的date-formate,支持自定义转换Converter,支持一次mapping定义多处使用,支持EventListener事件监听等等。不仅如此,Dozer在使用方式上,除了支持API,还支持XML和注解,满足大家的喜好。更多的功能可以参考这里
由于其功能很丰富,不可能每个都演示,这里只是给个大概认识,更详细的功能,或者XML和注解的配置,请看官方文档。
private Mapper dozerMapper;
@Before
public void setup(){
dozerMapper = DozerBeanMapperBuilder.create()
.withMappingBuilder(new BeanMappingBuilder() {
@Override
protected void configure() {
mapping(SourceVO.class, TargetVO.class)
.fields("fullName", "name")
.exclude("in");
}
})
.withCustomConverter(null)
.withEventListener(null)
.build();
}
@Test
public void dozerTest(){
SourceVO sourceVO = getSourceVO();
log.info("sourceVO={}", GsonUtil.toJson(sourceVO));
TargetVO map = dozerMapper.map(sourceVO, TargetVO.class);
log.info("map={}", GsonUtil.toJson(map));
}
原理
Dozer的实现原理本质上还是用反射/Introspector那套,但是其丰富的功能,以及支持多种实现方式(API、XML、注解)使得代码看上去有点复杂,在翻阅代码时,我们大可不必理会这些类,只需要知道它们大体的作用就行了,重点关注核心流程和代码的实现。下面我们重点看看构建mapper的build方法和实现映射的map方法。
build方法很简单,它是一个初始化的动作,就是通过用户的配置来构建出一系列后面要用到的配置对象、上下文对象,或其他封装对象,我们不必深究这些对象是怎么实现的,从名字上我们大概能猜出这些对象是干嘛,负责什么就可以了。
DozerBeanMapper(List<String> mappingFiles,
BeanContainer beanContainer,
DestBeanCreator destBeanCreator,
DestBeanBuilderCreator destBeanBuilderCreator,
BeanMappingGenerator beanMappingGenerator,
PropertyDescriptorFactory propertyDescriptorFactory,
List<CustomConverter> customConverters,
List<MappingFileData> mappingsFileData,
List<EventListener> eventListeners,
CustomFieldMapper customFieldMapper,
Map<String, CustomConverter> customConvertersWithId,
ClassMappings customMappings,
Configuration globalConfiguration,
CacheManager cacheManager) {
this.beanContainer = beanContainer;
this.destBeanCreator = destBeanCreator;
this.destBeanBuilderCreator = destBeanBuilderCreator;
this.beanMappingGenerator = beanMappingGenerator;
this.propertyDescriptorFactory = propertyDescriptorFactory;
this.customConverters = new ArrayList<>(customConverters);
this.eventListeners = new ArrayList<>(eventListeners);
this.mappingFiles = new ArrayList<>(mappingFiles);
this.customFieldMapper = customFieldMapper;
this.customConvertersWithId = new HashMap<>(customConvertersWithId);
this.eventManager = new DefaultEventManager(eventListeners);
this.customMappings = customMappings;
this.globalConfiguration = globalConfiguration;
this.cacheManager = cacheManager;
}
map方法是映射对象的过程,其入口是MappingProcessor的mapGeneral方法
private <T> T mapGeneral(Object srcObj, final Class<T> destClass, final T destObj, final String mapId) {
srcObj = MappingUtils.deProxy(srcObj, beanContainer);
Class<T> destType;
T result;
if (destClass == null) {
destType = (Class<T>)destObj.getClass();
result = destObj;
} else {
destType = destClass;
result = null;
}
ClassMap classMap = null;
try {
//构建ClassMap
//ClassMap是包括src类和dest类和其他配置的一个封装
classMap = getClassMap(srcObj.getClass(), destType, mapId);
//注册事件
eventManager.on(new DefaultEvent(EventTypes.MAPPING_STARTED, classMap, null, srcObj, result, null));
//看看有没有自定义converter
Class<?> converterClass = MappingUtils.findCustomConverter(converterByDestTypeCache, classMap.getCustomConverters(), srcObj
.getClass(), destType);
if (destObj == null) {
// If this is a nested MapperAware conversion this mapping can be already processed
// but we can do this optimization only in case of no destObject, instead we must copy to the dest object
Object alreadyMappedValue = mappedFields.getMappedValue(srcObj, destType, mapId);
if (alreadyMappedValue != null) {
return (T)alreadyMappedValue;
}
}
//优先使用自定义converter进行映射
if (converterClass != null) {
return (T)mapUsingCustomConverter(converterClass, srcObj.getClass(), srcObj, destType, result, null, true);
}
//也是对配置进行了封装
BeanCreationDirective creationDirective =
new BeanCreationDirective(srcObj, classMap.getSrcClassToMap(), classMap.getDestClassToMap(), destType,
classMap.getDestClassBeanFactory(), classMap.getDestClassBeanFactoryId(), classMap.getDestClassCreateMethod(),
classMap.getDestClass().isSkipConstructor());
//继续进行映射
result = createByCreationDirectiveAndMap(creationDirective, classMap, srcObj, result, false, null);
} catch (Throwable e) {
MappingUtils.throwMappingException(e);
}
eventManager.on(new DefaultEvent(EventTypes.MAPPING_FINISHED, classMap, null, srcObj, result, null));
return result;
}
一般情况下createByCreationDirectiveAndMap方法会一直调用到mapFromFieldMap方法,而在没有自定义converter的情况下会调用mapOrRecurseObject方法。
大多数情况下字段的映射会在这个方法做一般的解析
private Object mapOrRecurseObject(Object srcObj, Object srcFieldValue, Class<?> destFieldType, FieldMap fieldMap, Object destObj) {
Class<?> srcFieldClass = srcFieldValue != null ? srcFieldValue.getClass() : fieldMap.getSrcFieldType(srcObj.getClass());
Class<?> converterClass = MappingUtils.determineCustomConverter(fieldMap, converterByDestTypeCache, fieldMap.getClassMap()
.getCustomConverters(), srcFieldClass, destFieldType);
//自定义converter的处理
if (converterClass != null) {
return mapUsingCustomConverter(converterClass, srcFieldClass, srcFieldValue, destFieldType, destObj, fieldMap, false);
}
if (srcFieldValue == null) {
return null;
}
String srcFieldName = fieldMap.getSrcFieldName();
String destFieldName = fieldMap.getDestFieldName();
if (!(DozerConstants.SELF_KEYWORD.equals(srcFieldName) && DozerConstants.SELF_KEYWORD.equals(destFieldName))) {
Object alreadyMappedValue = mappedFields.getMappedValue(srcFieldValue, destFieldType, fieldMap.getMapId());
if (alreadyMappedValue != null) {
return alreadyMappedValue;
}
}
//如果只是浅拷贝则直接返回(可配置)
if (fieldMap.isCopyByReference()) {
// just get the src and return it, no transformation.
return srcFieldValue;
}
//对Map类型的处理
boolean isSrcFieldClassSupportedMap = MappingUtils.isSupportedMap(srcFieldClass);
boolean isDestFieldTypeSupportedMap = MappingUtils.isSupportedMap(destFieldType);
if (isSrcFieldClassSupportedMap && isDestFieldTypeSupportedMap) {
return mapMap(srcObj, (Map<?, ?>)srcFieldValue, fieldMap, destObj);
}
if (fieldMap instanceof MapFieldMap && destFieldType.equals(Object.class)) {
destFieldType = fieldMap.getDestHintContainer() != null ? fieldMap.getDestHintContainer().getHint() : srcFieldClass;
}
//对基本类型的映射处理
//PrimitiveOrWrapperConverter类支持兼容了基本类型之间的互相转换
if (primitiveConverter.accepts(srcFieldClass) || primitiveConverter.accepts(destFieldType)) {
// Primitive or Wrapper conversion
if (fieldMap.getDestHintContainer() != null) {
Class<?> destHintType = fieldMap.getDestHintType(srcFieldValue.getClass());
// if the destType is null this means that there was more than one hint.
// we must have already set the destType then.
if (destHintType != null) {
destFieldType = destHintType;
}
}
//#1841448 - if trim-strings=true, then use a trimmed src string value when converting to dest value
Object convertSrcFieldValue = srcFieldValue;
if (fieldMap.isTrimStrings() && srcFieldValue.getClass().equals(String.class)) {
convertSrcFieldValue = ((String)srcFieldValue).trim();
}
DateFormatContainer dfContainer = new DateFormatContainer(fieldMap.getDateFormat());
if (fieldMap instanceof MapFieldMap && !primitiveConverter.accepts(destFieldType)) {
return primitiveConverter.convert(convertSrcFieldValue, convertSrcFieldValue.getClass(), dfContainer);
} else {
return primitiveConverter.convert(convertSrcFieldValue, destFieldType, dfContainer, destFieldName, destObj);
}
}
//对集合类型的映射处理
if (MappingUtils.isSupportedCollection(srcFieldClass) && (MappingUtils.isSupportedCollection(destFieldType))) {
return mapCollection(srcObj, srcFieldValue, fieldMap, destObj);
}
//对枚举类型的映射处理
if (MappingUtils.isEnumType(srcFieldClass, destFieldType)) {
return mapEnum((Enum)srcFieldValue, (Class<Enum>)destFieldType);
}
if (fieldMap.getDestDeepIndexHintContainer() != null) {
destFieldType = fieldMap.getDestDeepIndexHintContainer().getHint();
}
//其他复杂对象类型的处理
return mapCustomObject(fieldMap, destObj, destFieldType, destFieldName, srcFieldValue);
}
mapCustomObject方法。其实你会发现这个方法最重要的一点就是做递归处理,无论是最后调用createByCreationDirectiveAndMap还是mapToDestObject方法。
private Object mapCustomObject(FieldMap fieldMap, Object destObj, Class<?> destFieldType, String destFieldName, Object srcFieldValue) {
srcFieldValue = MappingUtils.deProxy(srcFieldValue, beanContainer);
// Custom java bean. Need to make sure that the destination object is not
// already instantiated.
Object result = null;
// in case of iterate feature new objects are created in any case
if (!DozerConstants.ITERATE.equals(fieldMap.getDestFieldType())) {
result = getExistingValue(fieldMap, destObj, destFieldType);
}
// if the field is not null than we don't want a new instance
if (result == null) {
// first check to see if this plain old field map has hints to the actual
// type.
if (fieldMap.getDestHintContainer() != null) {
Class<?> destHintType = fieldMap.getDestHintType(srcFieldValue.getClass());
// if the destType is null this means that there was more than one hint.
// we must have already set the destType then.
if (destHintType != null) {
destFieldType = destHintType;
}
}
// Check to see if explicit map-id has been specified for the field
// mapping
String mapId = fieldMap.getMapId();
Class<?> targetClass;
if (fieldMap.getDestHintContainer() != null && fieldMap.getDestHintContainer().getHint() != null) {
targetClass = fieldMap.getDestHintContainer().getHint();
} else {
targetClass = destFieldType;
}
ClassMap classMap = getClassMap(srcFieldValue.getClass(), targetClass, mapId);
BeanCreationDirective creationDirective = new BeanCreationDirective(srcFieldValue, classMap.getSrcClassToMap(), classMap.getDestClassToMap(),
destFieldType, classMap.getDestClassBeanFactory(), classMap.getDestClassBeanFactoryId(),
fieldMap.getDestFieldCreateMethod() != null ? fieldMap.getDestFieldCreateMethod() :
classMap.getDestClassCreateMethod(),
classMap.getDestClass().isSkipConstructor(), destObj, destFieldName);
result = createByCreationDirectiveAndMap(creationDirective, classMap, srcFieldValue, null, false, fieldMap.getMapId());
} else {
mapToDestObject(null, srcFieldValue, result, false, fieldMap.getMapId());
}
return result;
}
小结
Dozer功能强大,但底层还是用反射那套,所以在性能测试中它的表现一般,仅次于Apache的BeanUtils。如果不追求性能的话,可以使用。
Orika
Orika可以说是几乎集成了上述几个工具的优点,不仅具有丰富的功能,底层使用Javassist生成字节码,运行 效率很高的。
使用
Orika基本支持了Dozer支持的功能,这里我也是简单介绍一下Orika的使用,具体更详细的API可以参考User Guide。
private MapperFactory mapperFactory;
@Before
public void setup() {
mapperFactory = new DefaultMapperFactory.Builder().build();
ConverterFactory converterFactory = mapperFactory.getConverterFactory();
converterFactory.registerConverter(new TypeConverter());
mapperFactory.classMap(SourceVO.class, TargetVO.class)
.field("fullName", "name")
.field("type", "enumType")
.exclude("in")
.byDefault()
.register();
}
@Test
public void main() {
MapperFacade mapper = mapperFactory.getMapperFacade();
SourceVO sourceVO = getSourceVO();
log.info("sourceVO={}", GsonUtil.toJson(sourceVO));
TargetVO map = mapper.map(sourceVO, TargetVO.class);
log.info("map={}", GsonUtil.toJson(map));
}
原理
在讲解实现原理时,我们先看看Orika在背后干了什么事情。
通过增加以下配置,我们可以看到Orika在做映射过程中生成mapper的源码和字节码。
System.setProperty("ma.glasnost.orika.writeSourceFiles", "true");
System.setProperty("ma.glasnost.orika.writeClassFiles", "true");
System.setProperty("ma.glasnost.orika.writeSourceFilesToPath", "path");
System.setProperty("ma.glasnost.orika.writeClassFilesToPath", "path");
用上面的例子,我们看看Orika生成的java代码:
package ma.glasnost.orika.generated;
public class Orika_TargetVO_SourceVO_Mapper947163525829122$0 extends ma.glasnost.orika.impl.GeneratedMapperBase {
public void mapAtoB(java.lang.Object a, java.lang.Object b, ma.glasnost.orika.MappingContext mappingContext) {
super.mapAtoB(a, b, mappingContext);
// sourceType: SourceVO
beanmapper_compare.vo.SourceVO source = ((beanmapper_compare.vo.SourceVO)a);
// destinationType: TargetVO
beanmapper_compare.vo.TargetVO destination = ((beanmapper_compare.vo.TargetVO)b);
destination.setName(((java.lang.String)source.getFullName()));
if ( !(((java.lang.Integer)source.getType()) == null)){
destination.setEnumType(((beanmapper_compare.vo.TargetVO.EnumType)((ma.glasnost.orika.Converter)usedConverters[0]).convert(((java.lang.Integer)source.getType()), ((ma.glasnost.orika.metadata.Type)usedTypes[0]), mappingContext)));
} else {
destination.setEnumType(null);
}
if ( !(((java.util.Date)source.getDate1()) == null)){
destination.setDate1(((java.util.Date)((ma.glasnost.orika.Converter)usedConverters[1]).convert(((java.util.Date)source.getDate1()), ((ma.glasnost.orika.metadata.Type)usedTypes[1]), mappingContext)));
} else {
destination.setDate1(null);
}if ( !(((java.util.List)source.getListData()) == null)) {
java.util.List new_listData = ((java.util.List)new java.util.ArrayList());
new_listData.addAll(mapperFacade.mapAsList(((java.util.List)source.getListData()), ((ma.glasnost.orika.metadata.Type)usedTypes[2]), ((ma.glasnost.orika.metadata.Type)usedTypes[3]), mappingContext));
destination.setListData(new_listData);
} else {
if ( !(((java.util.List)destination.getListData()) == null)) {
destination.setListData(null);
};
}if ( !(((java.util.Map)source.getMapData()) == null)){
java.util.Map new_mapData = ((java.util.Map)new java.util.LinkedHashMap());
for( java.util.Iterator mapData_$_iter = ((java.util.Map)source.getMapData()).entrySet().iterator(); mapData_$_iter.hasNext(); ) {
java.util.Map.Entry sourceMapDataEntry = ((java.util.Map.Entry)mapData_$_iter.next());
java.lang.Integer newMapDataKey = null;
java.util.List newMapDataVal = null;
if ( !(((java.lang.Long)sourceMapDataEntry.getKey()) == null)){
newMapDataKey = ((java.lang.Integer)((ma.glasnost.orika.Converter)usedConverters[2]).convert(((java.lang.Long)sourceMapDataEntry.getKey()), ((ma.glasnost.orika.metadata.Type)usedTypes[3]), mappingContext));
} else {
newMapDataKey = null;
}
if ( !(((java.util.List)sourceMapDataEntry.getValue()) == null)) {
java.util.List new_newMapDataVal = ((java.util.List)new java.util.ArrayList());
new_newMapDataVal.addAll(mapperFacade.mapAsList(((java.util.List)sourceMapDataEntry.getValue()), ((ma.glasnost.orika.metadata.Type)usedTypes[2]), ((ma.glasnost.orika.metadata.Type)usedTypes[4]), mappingContext));
newMapDataVal = new_newMapDataVal;
} else {
if ( !(newMapDataVal == null)) {
newMapDataVal = null;
};
}
new_mapData.put(newMapDataKey, newMapDataVal);
}
destination.setMapData(new_mapData);
} else {
destination.setMapData(null);
}
destination.setP1(((java.lang.Integer)source.getP1()));
destination.setP2(((java.lang.Long)source.getP2()));
destination.setP3(((java.lang.Byte)source.getP3()));
destination.setPattr1(((java.lang.String)source.getPattr1()));
if ( !(((java.lang.String)source.getSeq()) == null)){
destination.setSeq(((java.lang.Long)((ma.glasnost.orika.Converter)usedConverters[3]).convert(((java.lang.String)source.getSeq()), ((ma.glasnost.orika.metadata.Type)usedTypes[2]), mappingContext)));
} else {
destination.setSeq(null);
}
if(customMapper != null) {
customMapper.mapAtoB(source, destination, mappingContext);
}
}
public void mapBtoA(java.lang.Object a, java.lang.Object b, ma.glasnost.orika.MappingContext mappingContext) {
super.mapBtoA(a, b, mappingContext);
// sourceType: TargetVO
beanmapper_compare.vo.TargetVO source = ((beanmapper_compare.vo.TargetVO)a);
// destinationType: SourceVO
beanmapper_compare.vo.SourceVO destination = ((beanmapper_compare.vo.SourceVO)b);
destination.setFullName(((java.lang.String)source.getName()));
if ( !(((beanmapper_compare.vo.TargetVO.EnumType)source.getEnumType()) == null)){
destination.setType(((java.lang.Integer)((ma.glasnost.orika.Converter)usedConverters[0]).convert(((beanmapper_compare.vo.TargetVO.EnumType)source.getEnumType()), ((ma.glasnost.orika.metadata.Type)usedTypes[3]), mappingContext)));
} else {
destination.setType(null);
}
if ( !(((java.util.Date)source.getDate1()) == null)){
destination.setDate1(((java.util.Date)((ma.glasnost.orika.Converter)usedConverters[1]).convert(((java.util.Date)source.getDate1()), ((ma.glasnost.orika.metadata.Type)usedTypes[1]), mappingContext)));
} else {
destination.setDate1(null);
}if ( !(((java.util.List)source.getListData()) == null)) {
java.util.List new_listData = ((java.util.List)new java.util.ArrayList());
new_listData.addAll(mapperFacade.mapAsList(((java.util.List)source.getListData()), ((ma.glasnost.orika.metadata.Type)usedTypes[3]), ((ma.glasnost.orika.metadata.Type)usedTypes[2]), mappingContext));
destination.setListData(new_listData);
} else {
if ( !(((java.util.List)destination.getListData()) == null)) {
destination.setListData(null);
};
}if ( !(((java.util.Map)source.getMapData()) == null)){
java.util.Map new_mapData = ((java.util.Map)new java.util.LinkedHashMap());
for( java.util.Iterator mapData_$_iter = ((java.util.Map)source.getMapData()).entrySet().iterator(); mapData_$_iter.hasNext(); ) {
java.util.Map.Entry sourceMapDataEntry = ((java.util.Map.Entry)mapData_$_iter.next());
java.lang.Long newMapDataKey = null;
java.util.List newMapDataVal = null;
if ( !(((java.lang.Integer)sourceMapDataEntry.getKey()) == null)){
newMapDataKey = ((java.lang.Long)((ma.glasnost.orika.Converter)usedConverters[2]).convert(((java.lang.Integer)sourceMapDataEntry.getKey()), ((ma.glasnost.orika.metadata.Type)usedTypes[2]), mappingContext));
} else {
newMapDataKey = null;
}
if ( !(((java.util.List)sourceMapDataEntry.getValue()) == null)) {
java.util.List new_newMapDataVal = ((java.util.List)new java.util.ArrayList());
new_newMapDataVal.addAll(mapperFacade.mapAsList(((java.util.List)sourceMapDataEntry.getValue()), ((ma.glasnost.orika.metadata.Type)usedTypes[4]), ((ma.glasnost.orika.metadata.Type)usedTypes[2]), mappingContext));
newMapDataVal = new_newMapDataVal;
} else {
if ( !(newMapDataVal == null)) {
newMapDataVal = null;
};
}
new_mapData.put(newMapDataKey, newMapDataVal);
}
destination.setMapData(new_mapData);
} else {
destination.setMapData(null);
}
destination.setP1(((java.lang.Integer)source.getP1()));
destination.setP2(((java.lang.Long)source.getP2()));
destination.setP3(((java.lang.Byte)source.getP3()));
destination.setPattr1(((java.lang.String)source.getPattr1()));
if ( !(((java.lang.Long)source.getSeq()) == null)){
destination.setSeq(((java.lang.String)((ma.glasnost.orika.Converter)usedConverters[4]).convert(((java.lang.Long)source.getSeq()), ((ma.glasnost.orika.metadata.Type)usedTypes[5]), mappingContext)));
} else {
destination.setSeq(null);
}
if(customMapper != null) {
customMapper.mapBtoA(source, destination, mappingContext);
}
}
}
这个mapper类就两个方法mapAtoB和mapBtoA,从名字看猜到前者是负责src -> dest的映射,后者是负责dest -> src的映射。
好,我们们看看实现的过程。
Orika的使用跟Dozer的类似,首先通过配置生成一个MapperFactory,再用MapperFacade来作为映射的统一入口,这里MapperFactory和MapperFacade都是单例的。mapperFactory在做配置类映射时,只是注册了ClassMap,还没有真正的生成mapper的字节码,是在第一次调用getMapperFacade方法时才初始化mapper。下面看看getMapperFacade。
(源码基于 ma.glasnost.orika:orika-core:1.5.4)
public MapperFacade getMapperFacade() {
if (!isBuilt) {
synchronized (mapperFacade) {
if (!isBuilt) {
build();
}
}
}
return mapperFacade;
}
利用注册的ClassMap信息和MappingContext上下文信息来构造mapper
public synchronized void build() {
if (!isBuilding && !isBuilt) {
isBuilding = true;
MappingContext context = contextFactory.getContext();
try {
if (useBuiltinConverters) {
BuiltinConverters.register(converterFactory);
}
converterFactory.setMapperFacade(mapperFacade);
for (Map.Entry<MapperKey, ClassMap<Object, Object>> classMapEntry : classMapRegistry.entrySet()) {
ClassMap<Object, Object> classMap = classMapEntry.getValue();
if (classMap.getUsedMappers().isEmpty()) {
classMapEntry.setValue(classMap.copyWithUsedMappers(discoverUsedMappers(classMap)));
}
}
buildClassMapRegistry();
Map<ClassMap<?, ?>, GeneratedMapperBase> generatedMappers = new HashMap<ClassMap<?, ?>, GeneratedMapperBase>();
//重点看这里
//在使用mapperFactory配置classMap时,会存放在classMapRegistry里
for (ClassMap<?, ?> classMap : classMapRegistry.values()) {
//对每个classMap生成一个mapper,重点看buildMapper方法
generatedMappers.put(classMap, buildMapper(classMap, false, context));
}
Set<Entry<ClassMap<?, ?>, GeneratedMapperBase>> generatedMapperEntries = generatedMappers.entrySet();
for (Entry<ClassMap<?, ?>, GeneratedMapperBase> generatedMapperEntry : generatedMapperEntries) {
buildObjectFactories(generatedMapperEntry.getKey(), context);
initializeUsedMappers(generatedMapperEntry.getValue(), generatedMapperEntry.getKey(), context);
}
} finally {
contextFactory.release(context);
}
isBuilt = true;
isBuilding = false;
}
}
public Set<ClassMap<Object, Object>> lookupUsedClassMap(MapperKey mapperKey) {
Set<ClassMap<Object, Object>> usedClassMapSet = usedMapperMetadataRegistry.get(mapperKey);
if (usedClassMapSet == null) {
usedClassMapSet = Collections.emptySet();
}
return usedClassMapSet;
}
private GeneratedMapperBase buildMapper(ClassMap<?, ?> classMap, boolean isAutoGenerated, MappingContext context) {
register(classMap.getAType(), classMap.getBType(), isAutoGenerated);
register(classMap.getBType(), classMap.getAType(), isAutoGenerated);
final MapperKey mapperKey = new MapperKey(classMap.getAType(), classMap.getBType());
//调用mapperGenerator的build方法生成mapper
final GeneratedMapperBase mapper = mapperGenerator.build(classMap, context);
mapper.setMapperFacade(mapperFacade);
mapper.setFromAutoMapping(isAutoGenerated);
if (classMap.getCustomizedMapper() != null) {
final Mapper<Object, Object> customizedMapper = (Mapper<Object, Object>) classMap.getCustomizedMapper();
mapper.setCustomMapper(customizedMapper);
}
mappersRegistry.remove(mapper);
//生成的mapper存放到mappersRegistry
mappersRegistry.add(mapper);
classMapRegistry.put(mapperKey, (ClassMap<Object, Object>) classMap);
return mapper;
}
public GeneratedMapperBase build(ClassMap<?, ?> classMap, MappingContext context) {
StringBuilder logDetails = null;
try {
compilerStrategy.assureTypeIsAccessible(classMap.getAType().getRawType());
compilerStrategy.assureTypeIsAccessible(classMap.getBType().getRawType());
if (LOGGER.isDebugEnabled()) {
logDetails = new StringBuilder();
String srcName = TypeFactory.nameOf(classMap.getAType(), classMap.getBType());
String dstName = TypeFactory.nameOf(classMap.getBType(), classMap.getAType());
logDetails.append("Generating new mapper for (" + srcName + ", " + dstName + ")");
}
//构建用来生成源码及字节码的上下文
final SourceCodeContext mapperCode = new SourceCodeContext(classMap.getMapperClassName(), GeneratedMapperBase.class, context,
logDetails);
Set<FieldMap> mappedFields = new LinkedHashSet<FieldMap>();
//增加mapAtoB方法
mappedFields.addAll(addMapMethod(mapperCode, true, classMap, logDetails));
//增加mapBtoA方法
//addMapMethod方法基本就是手写代码的过程,有兴趣的读者可以看看
mappedFields.addAll(addMapMethod(mapperCode, false, classMap, logDetails));
//生成一个mapper实例
GeneratedMapperBase instance = mapperCode.getInstance();
instance.setAType(classMap.getAType());
instance.setBType(classMap.getBType());
instance.setFavorsExtension(classMap.favorsExtension());
if (logDetails != null) {
LOGGER.debug(logDetails.toString());
logDetails = null;
}
classMap = classMap.copy(mappedFields);
context.registerMapperGeneration(classMap);
return instance;
} catch (final Exception e) {
if (logDetails != null) {
logDetails.append("\n<---- ERROR occurred here");
LOGGER.debug(logDetails.toString());
}
throw new MappingException(e);
}
T instance = (T) compileClass().newInstance();
protected Class<?> compileClass() throws SourceCodeGenerationException {
try {
return compilerStrategy.compileClass(this);
} catch (SourceCodeGenerationException e) {
throw e;
}
}
这里的compilerStrategy的默认是用Javassist(你也可以自定义生成字节码的策略)
JavassistCompilerStrategy的compileClass方法
这基本上就是一个使用Javassist的过程,经过前面的各种铺垫(通过配置信息、上下文信息、拼装java源代码等等),终于来到这一步
public Class<?> compileClass(SourceCodeContext sourceCode) throws SourceCodeGenerationException {
StringBuilder className = new StringBuilder(sourceCode.getClassName());
CtClass byteCodeClass = null;
int attempts = 0;
Random rand = RANDOM;
while (byteCodeClass == null) {
try {
//创建一个类
byteCodeClass = classPool.makeClass(className.toString());
} catch (RuntimeException e) {
if (attempts < 5) {
className.append(Integer.toHexString(rand.nextInt()));
} else {
// No longer likely to be accidental name collision;
// propagate the error
throw e;
}
}
}
CtClass abstractMapperClass;
Class<?> compiledClass;
try {
//把源码写到磁盘(通过上面提到的配置)
writeSourceFile(sourceCode);
Boolean existing = superClasses.put(sourceCode.getSuperClass(), true);
if (existing == null || !existing) {
classPool.insertClassPath(new ClassClassPath(sourceCode.getSuperClass()));
}
if (registerClassLoader(Thread.currentThread().getContextClassLoader())) {
classPool.insertClassPath(new LoaderClassPath(Thread.currentThread().getContextClassLoader()));
}
abstractMapperClass = classPool.get(sourceCode.getSuperClass().getCanonicalName());
byteCodeClass.setSuperclass(abstractMapperClass);
//增加字段
for (String fieldDef : sourceCode.getFields()) {
try {
byteCodeClass.addField(CtField.make(fieldDef, byteCodeClass));
} catch (CannotCompileException e) {
LOG.error("An exception occurred while compiling: " + fieldDef + " for " + sourceCode.getClassName(), e);
throw e;
}
}
//增加方法,这里主要就是mapAtoB和mapBtoA方法
//直接用源码通过Javassist往类“加”方法
for (String methodDef : sourceCode.getMethods()) {
try {
byteCodeClass.addMethod(CtNewMethod.make(methodDef, byteCodeClass));
} catch (CannotCompileException e) {
LOG.error(
"An exception occured while compiling the following method:\n\n " + methodDef + "\n\n for "
+ sourceCode.getClassName() + "\n", e);
throw e;
}
}
//生成类
compiledClass = byteCodeClass.toClass(Thread.currentThread().getContextClassLoader(), this.getClass().getProtectionDomain());
//字节码文件写磁盘
writeClassFile(sourceCode, byteCodeClass);
} catch (NotFoundException e) {
throw new SourceCodeGenerationException(e);
} catch (CannotCompileException e) {
throw new SourceCodeGenerationException("Error compiling " + sourceCode.getClassName(), e);
} catch (IOException e) {
throw new SourceCodeGenerationException("Could not write files for " + sourceCode.getClassName(), e);
}
return compiledClass;
}
好,mapper类生成了,现在就看在调用MapperFacade的map方法是如何使用这个mapper类的。
其实很简单,还记得生成的mapper是放到mappersRegistry吗,跟踪代码,在resolveMappingStrategy方法根据typeA和typeB在mappersRegistry找到mapper,在调用mapper的mapAtoB或mapBtoA方法即可。
小结
总体来说,Orika是一个功能强大的而且性能很高的工具,推荐使用。
总结
通过对BeanUtils、BeanCopier、Dozer、Orika这几个工具的对比,我们得知了它们的性能以及实现原理。在使用时,我们可以根据自己的实际情况选择,推荐使用Orika。
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!