
Python自动化办公-玩转图片
有很多非 IT 行业的朋友都在学 Python,他们的目的也很简单,就是想提高下工作效率,简单重复的工作希望用 Python 搞定。
因此我准备写一些 Python 自动化办公系列相关文章,代码都是可以在 Python3 上正确运行的,复制下代码,再调整下细节,就可以使用。
首先发在公众号上,然后同步到知识星球。
为什么同步到知识星球,因为公众号的文章修改起来非常麻烦,而知识星球就比较简单了,这样文章里的代码可以不停迭代更新,重要的是有问题还可以一对一进行提问。加入星球的方式后续会公布。
在日常的工作生活中,我们会经常与图片打交道,比如下载图片,压缩图片,删除图片的元数据防止隐私泄漏,拼接长图,图片文字识别,加水印等等。
今天就来分享下如何简单的使用 Python 来玩转这些操作。
1、下载图片
下载图片是最简单的操作了,无非就是先找到图片的 url,使用标准库或者 requests 库去请求这个 url,然后将得到的数据保存为文件即可。
下面分享三种方法来下载图片。
方法一,使用标准库。
from urllib.request import urlretrieve
from pathlib import Path
import ssl
def urllib_download(img_url, download_path):
ssl._create_default_https_context = ssl._create_unverified_context
urlretrieve(img_url, Path(download_path) / 'image1.png')
方法二,使用 requests。
import requests
def request_download(img_url, download_path):
r = requests.get(img_url)
with open(f'{download_path}/image2.png', 'wb') as f:
f.write(r.content)
方法二,使用 requests 的流式下载,适用于较大,网速慢,容易下载失败的图片。
import requests
def requests_chunk_download(img_url, download_path):
r = requests.get(img_url, stream=True)
with open(f'{download_path}/image3.png', 'wb') as f:
for chunk in r.iter_content(chunk_size=32):
f.write(chunk)
分别下载一个图片看看结果:
if __name__ == '__main__':
img_url = 'https://tinypng.com/images/panda-developing-2x.png'
download_path = Path('/Users/aaron/tmp/images')
download_path.mkdir(exist_ok=True)
urllib_download(img_url,download_path.as_posix())
request_download(img_url, download_path.as_posix())
requests_chunk_download(img_url, download_path.as_posix())

三种方法下载图片的大小是一样的。
如果自动下载某网站的全部图片,其实一点也不复杂,无非就是找规律,如何获取全部图片的 url,然后循环调用以上三个函数。
获取图片 url 可能会涉及正则表达式,关于正则表达式,可以参考前文学会正则表达式,玩弄文本于股掌之中
2、压缩图片
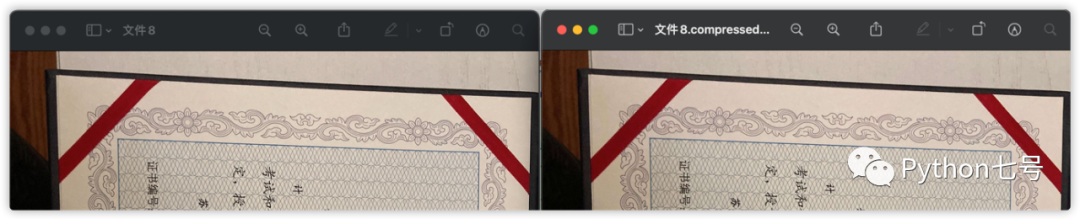
有一次我用邮箱向老板发送 5 张图片时,foxmail 提示我是否启用 QQ 邮箱的超大附件功能,原来 5 张图片已经 40+ MB,现在的手机拍摄的真是太清晰了。
不过工作中的图片能看清楚内容就可以了,完全没有必要整那么清晰,文件太大,发给老板,老板打开图片也会卡,体验非常不好,于是我就想如何使用 Python 来压缩图片。
找了很多方法,都不是很理想,有的软件下载后才发现是付费的,有的在使用时直接导致程序卡死,有的压缩率不够需要多次压缩,有的要求原始图片大小不能超过 5 M
有的失真有些严重。
直到我用了 tinypng 的 api 接口,才发现这真的好用,图片几乎不失真,大多都控制在 1 MB 之内,在此分享给大家。
先打开 https://tinypng.com/developers, 在下方输入你的用户名和邮箱,就可以获取一个 API KEY。
然后 pip 安装一下这个库:
pip install tinify
编写三行代码就可以对图片进行压缩处理了:
import tinify
tinify.key = '此处填入你的key'
tinify.from_file(src_img_path).to_file(dst_img_path)
其中 src_img_path 是原图片,dst_img_path 是压缩后的图片。
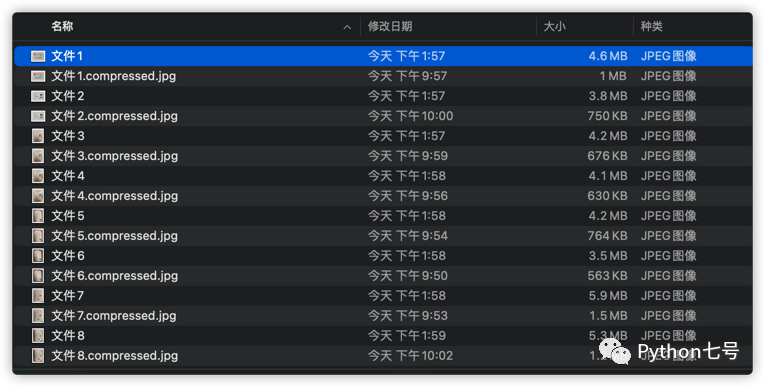
比如找个目录,对文件批量压缩一下:
import tinify
from pathlib import Path
import os
tinify.key = '此处填入你的key'
path = "/Users/aaron/Documents/个人/origin" # 图片存放的路径
for dirpath, dirs, files in os.walk(path):
for file in files:
file = Path(dirpath)/Path(file)
if file.suffix.lower() in ['.jpg','.png','.gif']:
print("compressing ..."+ file.as_posix())
tinify.from_file(file.as_posix()).to_file(file.with_suffix(".compressed.jpg").as_posix())
3、删除图片的元数据
现在大部分快递已经可以对地址信息进行加密,大家的隐私保护意识也越来越高,可是一不小心,你随手发布的照片就可能暴露了你的位置信息。
因此,用户发布照片时去除照片的位置、设备、时间等隐私信息显得很有必要,这些信息又叫元数据,也就是 metadata。
Python 删除图片的元数据是有一个三方库 piexif,我使用它删除后,再用 exiftool 查看时,仍然可以查到许多隐私信息。
也就是说 piexif 删除的不够彻底,于是我用 Python 封装了 exiftool,这下,图片的元数据可以删除的干干净净。
文件 exif_tool.py 代码如下:
import subprocess
import os
import json
from pathlib import Path
class ExifTool(object):
sentinel = "{ready}\n"
#windows
#sentinel = "{ready}\r\n"
def __init__(self, executable="/usr/bin/exiftool"):
exiftool1 = Path("/usr/bin/exiftool")
exiftool2 = Path("/usr/local/bin/exiftool")
self.executable = executable
if exiftool1.exists():
self.executable = exiftool1.as_posix()
elif exiftool2.exists():
self.executable = exiftool2.as_posix()
else:
if Path(self.executable).exists():
pass
else:
raise FileNotFoundError(self.executable)
def __enter__(self):
self.process = subprocess.Popen(
[self.executable, "-stay_open", "True", "-@", "-"],
universal_newlines=True,
stdin=subprocess.PIPE, stdout=subprocess.PIPE)
return self
def __exit__(self, exc_type, exc_value, traceback):
self.process.stdin.write("-stay_open\nFalse\n")
self.process.stdin.flush()
def execute(self, *args):
args = args + ("-execute\n",)
self.process.stdin.write(str.join("\n", args))
self.process.stdin.flush()
output = ""
fd = self.process.stdout.fileno()
while not output.endswith(self.sentinel):
# output += os.read(fd, 4096).decode('utf-8',errors=)
output += os.read(fd, 4096).decode('utf-8',"ignore")
return output[:-len(self.sentinel)]
def get_metadata(self, *filenames):
"""
返回多个文件的 exif 信息
"""
return json.loads(self.execute("-G", "-j", "-n", *filenames))
def get_exif_info(self, source_img):
"""
返回单个文件的 exif 信息
"""
return self.get_metadata(source_img)[0]
def delete_exif_info(self, source_img):
'''
删除 exif 信息后,返回剩余的 exif 信息
'''
self.execute("-all=",source_img)
metadata = self.get_metadata(source_img)
return metadata[0]
使用前先确保操作系统已经安装了 exiftool,程序默认读取两个位置:
/usr/bin/exiftool
/usr/local/bin/exiftool
也可以自己传入 exiftool 的执行路径。
使用举例:
from pprint import pprint
if __name__ == '__main__':
with ExifTool() as e:
exif = e.get_exif_info('/Users/aaron/Documents/个人/origin/文件1.jpg')
pprint(exif)
exif = e.delete_exif_info('/Users/aaron/Documents/个人/origin/文件1.jpg')
print("========删除 exif 信息后========")
pprint(exif)
大家可以用 piexif 和我这里提供的 exif_tool 做个对比,看看哪个删除的更彻底,有问题请留言讨论。
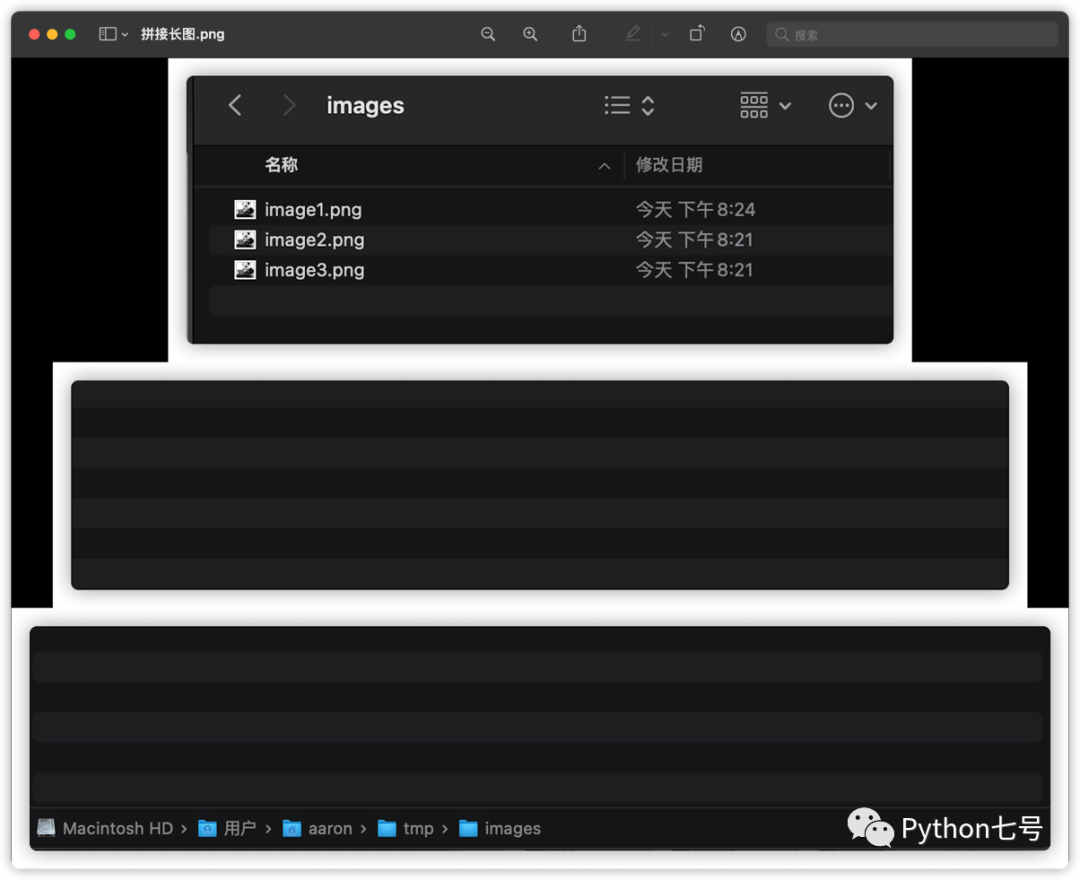
4、拼接长图
思路也简单,也把要拼接的图片放在数组里面,然后计算图片的最大宽度作为拼接后图片的宽度,然后一张一张拼接即可。
排版可以选择靠左对齐,或者水平居中对齐,空白位置的颜色也可以自己定义。
具体代码如下:
from pathlib import Path
from PIL import Image
if __name__ == '__main__':
img_list = []
imgs_path = Path('/Users/aaron/tmp/images')
for img in imgs_path.iterdir():
if img.suffix.lower() in ['.jpg','.png']:
img_list.append(Image.open(img.as_posix()))
width = 0
height = 0
for img in img_list:
# 单幅图像尺寸
w, h = img.size
height += h
# 取最大的宽度作为拼接图的宽度
width = max(width, w)
# 创建空白长图,这里可以传入 color 设置空白地方的颜色,默认黑色
result = Image.new(img_list[0].mode, (width, height))
# 拼接图片
height = 0
for img in reversed(img_list):
w, h = img.size
# 图片水平居中
result.paste(img, box=(round(width / 2 - w / 2), height))
height += h
# 保存图片
result.save('拼接长图.png')
执行后的效果如下所示:
5、如何识别图片上的文字
这其实就是 OCR 了,非常实用,不过个人很难训练出优秀的模型,不如直接用大厂的 API。举个例子,百度云的 AI 产品,你可以在终端下执行这样一个命令来进行安装。
pip install baidu-aip
在这里我使用了百度云提供的在线文字识别产品,提供了 AipOcr 函数实现用户验证、client.basicGeneral 函数实现文字识别功能。
代码如下:
from aip import AipOcr
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('example.png')
""" 调用通用文字识别, 图片参数为本地图片 """
result = client.basicGeneral(image)
print(result)
在这段代码里,实现了三个功能,分别是用户验证、读取图片和识别图片。
为了更直观地看到效果,我这里对着书拍个照片,然后让它识别一下:
原图如下:

识别结果如下:
6、给图片加水印
添加自己的水印来防止别人盗图,也可以宣传品牌形象,如果要为大量图片添加文字水印,不妨使用以下方法。
from PIL import Image, ImageDraw, ImageFont
def add_text_watermark(img, text):
img = Image.open(img)
draw = ImageDraw.Draw(img)
myfont = ImageFont.truetype('/System/Library/Fonts/PingFang.ttc', size=100)
fillcolor = "#ff0000"
width, height = img.size
draw.text((width - 700, height - 250), text, font=myfont, fill=fillcolor)
return img
if __name__ == '__main__':
image = '/Users/aaron/Documents/个人/IMG_2288.compressed.jpg'
img1 = add_text_watermark(image,'@Python七号')
img1.save("result_text_watermark.jpg","jpeg")
说明 draw.text((width - 700, height - 250), '@Python七号', font=myfont, fill=fillcolor)第一个括号填写的是位置,左上角的坐标是 (0,0),右下角的坐标是(width,heigth),本例中 (width - 700, height - 250) 相当于是右下角。
效果如下(红色部分是程序添加的):

那你可能又问下,如果加图片水印呢?比如现在有一个 logo 想添加到图片上,代码如下:
from PIL import Image
def add_img_watermark(img, img_watermark):
rgba_image = Image.open(img).convert("RGBA")
rgba_watermark = Image.open(img_watermark).convert("RGBA")
image_x, image_y = rgba_image.size
watermark_x, watermark_y = rgba_watermark.size
# 缩放图片
scale = 10
watermark_scale = max(image_x / (scale * watermark_x), image_y / (scale * watermark_y))
new_size = (int(watermark_x * watermark_scale), int(watermark_y * watermark_scale))
rgba_watermark = rgba_watermark.resize(new_size, resample=Image.ANTIALIAS)
# 透明度
rgba_watermark_mask = rgba_watermark.convert("L").point(lambda x: min(x, 180))
rgba_watermark.putalpha(rgba_watermark_mask)
watermark_x, watermark_y = rgba_watermark.size
# 水印位置
rgba_image.paste(rgba_watermark, ( (image_x - watermark_x)//2, image_y - watermark_y-100), rgba_watermark_mask) # 右上角
return rgba_image.convert("RGB")
if __name__ == '__main__':
image = '/Users/aaron/Documents/个人/IMG_2288.compressed.jpg'
img_watermark = "/Users/aaron/Downloads/IMG_2568.JPG"
img2 = add_img_watermark(image, img_watermark)
img2.save("result_img_watermark.jpg")
效果如下图所示:

最后的话
图片是我们接触最多的媒体文件了,这里分享了 6 种关于图片的实用操作,需要的可以直接复制这里的代码使用。
如果想了解关于图片的更多的实用操作,请留言,后续再发这方面的文章。