
YOLOv5-v6.0学习笔记
网络结构
1.1 Backbone
YOLOv5-6.0版本的Backbone主要分为Conv模块、CSPDarkNet53和SPPF模块。

1.1.1 Conv模块

YOLOv5在Conv模块中封装了三个功能:包括卷积(Conv2d)、Batch Normalization和激活函数,同时使用autopad(k, p)实现了padding的效果。其中YOLOv5-6.0版本使用Swish(或者叫SiLU)作为激活函数,代替了旧版本中的Leaky ReLU。
1.1.2 Focus模块
Focus模块是YOLOv5旧版本中的一个模块,它的结构如下图所示。

其中核心部分是对图片进行切片(slice)操作,并且在通道维度上进行拼接。
如下图所示,对于一张3通道的输入图片,分别在w ww和h hh两个维度上,每隔一个像素取一个值,从而构建得到12张特征图。
这12张特征图在宽度和高度上变为原来的二分之一 但是通道维度扩充了4倍。
同时,这12张特征图包含了输入图片的所有信息,因此Focus模块不仅在减少信息丢失的情况下实现了2倍下采样。
而且减少了参数量(params)和计算量(FLOPs),降低了CUDA显存的消耗,从而提升了前向和后向传递的速度。

最后对拼接后的特征图进行一次卷积操作,将通道数增加到64。
但是在YOLOv5-6.0版本中使用了尺寸大小为6 66×6 66,步长为2,padding为2的卷积核代替了Focus模块,便于模型的导出,且效率更高。
1.1.3 CSPDarkNet53
1.1.3.1 CSPNet
论文链接:https://arxiv.org/abs/1911.11929
CSPNet被提出的主要目的是为了保证在模型检测和识别精度没有下降的情况下,减少计算量,提高推理速度。
它的主要思想是通过分割梯度流,使梯度流通过不同的网络路径传播。通过拼接和过渡等操作,从而实现更丰富的梯度组合信息。
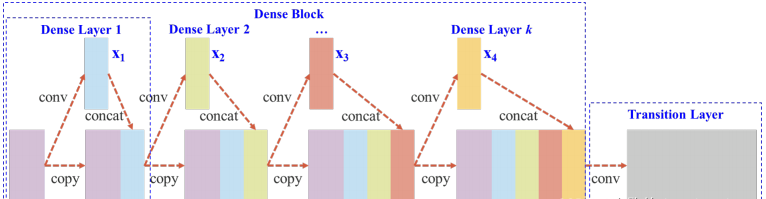

Cross Stage Partial DenseNet
以DenseNet为例,在将特征图输入到Dense_Block之前,将特征图从通道维度上分为两个部分:
其中一部分进入Dense_Block中进行计算,另一部分则通过一个shortcut与Dense_Block的输出特征图进行拼接,最后将拼接后的特征图输入到Transition Layer进行卷积操作。
1.1.3.2 Bottleneck模块
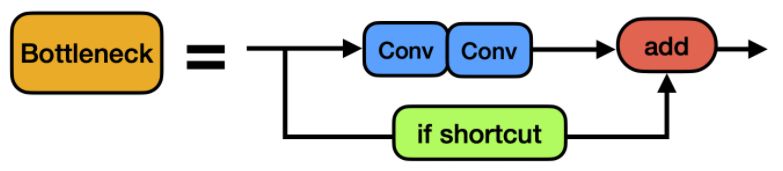
Bottleneck模块借鉴了ResNet的残差结构,其中一路先进行1 11×1 11卷积将特征图的通道数减小一半。
从而减少计算量,再通过3 33×3 33卷积提取特征,并且将通道数加倍,其输入与输出的通道数是不发生改变的。
而另外一路通过shortcut进行残差连接,与第一路的输出特征图相加,从而实现特征融合。
在YOLOv5的Backbone中的Bottleneck都默认使shortcut为True,而在Head中的Bottleneck都不使用shortcut。
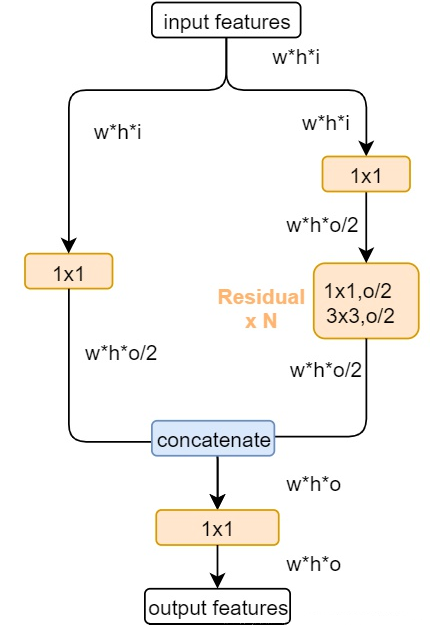
1.1.3.3 C3模块
YOLOv4和YOLOv5均借鉴了CSPNet的思想,将其运用于DarkNet53骨干网络。YOLOv5-6.0版本中使用了C3模块,替代了早期的BottleneckCSP模块。
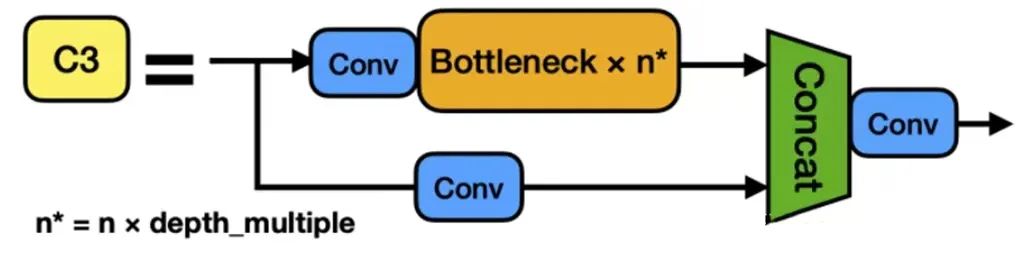
C3模块
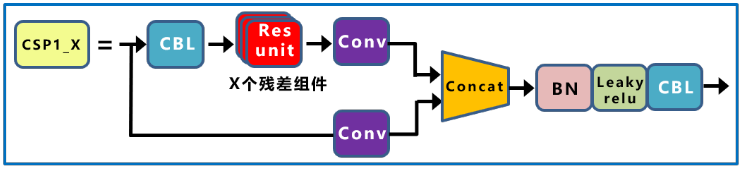
BottleneckCSP模块
这两者结构作用基本相同,均为CSP架构,只是在修正单元的选择上有所不同,C3模块包含了3个标准卷积层以及多个Bottleneck模块。
C3模块相对于BottleneckCSP模块所不同的是,经过Bottleneck模块输出后的Conv模块被去掉了。
但是YOLOv4和YOLOv5的Backbone虽然借鉴了CSPNet,但实际上并没有按照CSPNet原论文中那样将输入的特征图在通道维度上划分成两个部分。
而是直接用两路的1 11×1 11卷积对输入特征图进行变换。
1.1.4 SPPF模块
参考链接:
https://github.com/ultralytics/yolov5/pull/4420
YOLOv5-6.0版本使用了SPPF模块来代替SPP模块,其中SPP是Spatial Pyramid Pooling的简称,即空间金字塔池化,YOLOv5借鉴了SPPNet的思想。
SPPF模块采用多个小尺寸池化核级联代替SPP模块中单个大尺寸池化核,从而在保留原有功能。
即融合不同感受野的特征图,丰富特征图的表达能力的情况下,进一步提高了运行速度。
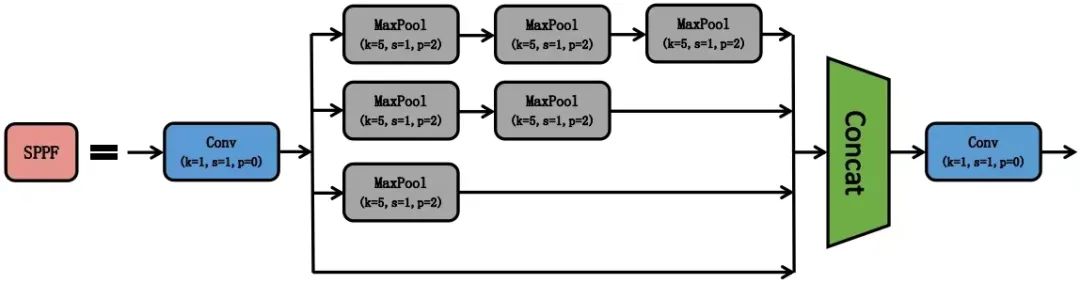
SPPF模块
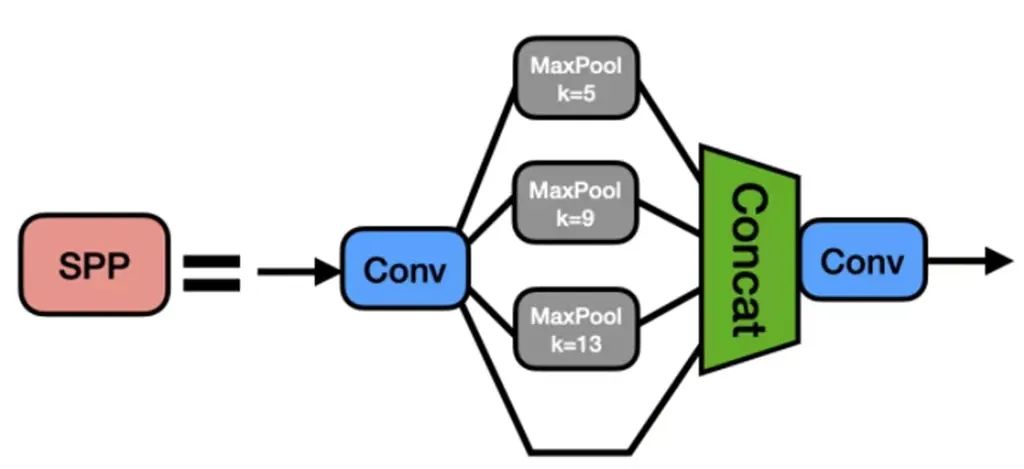
SPP模块
1.2 Neck
YOLOv5的Neck与YOLOV4相似,均借鉴了FPN和PANet的思想。

1.2.1 FPN
论文链接:https://arxiv.org/abs/1612.03144
FPN,即Feature Pyramid Network(特征金字塔)。
原来多数的目标检测算法只是采用顶层特征做预测,但我们知道浅层的特征所携带的语义信息较少,而位置信息更强;
深层的特征所携带的语义信息较丰富,而位置信息更弱。FPN的思想就是把深层的语义信息传递到浅层,从而增强多个尺度上的语义表达。
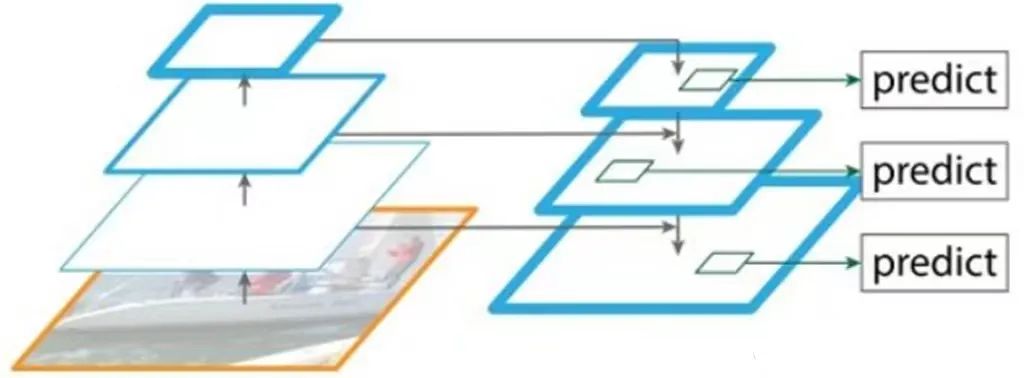
FPN的大致结构如上图所示,左边是一个自底向上(Bottom-up)的传播路径,右边是一个自顶向下(Top-down)的传播路径,中间是通过横向连接(lateral connection)进行特征融合。
其中自底向上(Bottom-up)的过程就是网络的前向传播过程,对应前面的骨干网络(Backbone)。
在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage。
因此每次抽取的特征都是每个stage的最后一层的输出,这样就能构成特征金字塔。
自顶向下(Top-down)的过程是从小尺寸的feature map开始逐个stage进行2倍上采样。
而横向连接则是先由自底向上(Bottom-up)过程中生成的相同大小的feature map经过1 11×1 11的卷积核来减少通道数(如下图所示)。
然后与2倍上采样得到的feature map进行相加融合(在YOLOv5中采用的是拼接融合)。
在融合之后还会对每个融合结果进行3 33×3 33卷积,目的是消除上采样的混叠效应(aliasing effect)。

1.2.2 PANet
论文链接:https://arxiv.org/abs/1803.01534
FPN通过自顶向下(Top-down)的结构,将深层的语义信息传递到浅层,但是浅层的位置信息却无法影响到深层特征。
同时,FPN中顶部信息流需要通过骨干网络(Backbone)逐层地往下传递,由于层数相对较多,因此计算量比较大,而PANet有效地解决了上述这些问题。

如上图(b)所示,PANet在FPN的基础上又引入了一个自底向上(Bottom-up)的路径。
经过自顶向下(Top-down)的特征融合后,再进行自底向上(Bottom-up)的特征融合,这样底层的位置信息也能够传递到深层,从而增强多个尺度上的定位能力。
同时,与FPN相比(如红色线条所示),PANet中的底层特征传递所需要穿越的feature map数量大大减少(如绿色线条所示),使得底层的位置信息更容易传递到顶部。
其中自底向上(Bottom-up)的过程是沿着N 2 → N 3 → N 4 → N 5 的路径,逐个stage通过3 33×3 33卷积进行2倍下采样,然后与FPN中相应大小的feature map进行相加融合(在YOLOv5中采用的是拼接融合)。
1.3 Head
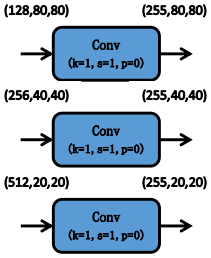
YOLOv5的Head对Neck中得到的不同尺度的特征图分别通过1 11×1 11卷积将通道数扩展,扩展后的特征通道数为(类别数量+5)× ××每个检测层上的anchor数量。
其中5 55分别对应的是预测框的中心点横坐标、纵坐标、宽度、高度和置信度,这里的置信度表示预测框的可信度。
取值范围为( 0 , 1 ) (0,1)(0,1),值越大说明该预测框中越有可能存在目标。
Head中包含3个检测层,分别对应Neck中得到的3种不同尺寸的特征图。
YOLOv5根据特征图的尺寸在这3种特征图上划分网格,并且给每种特征图上的每个网格都预设了3个不同宽高比的anchor,用来预测和回归目标。
因此上述的通道维度可以理解为在特征图的通道维度上保存了所有基于anchor先验框的位置信息和分类信息,如下图所示。
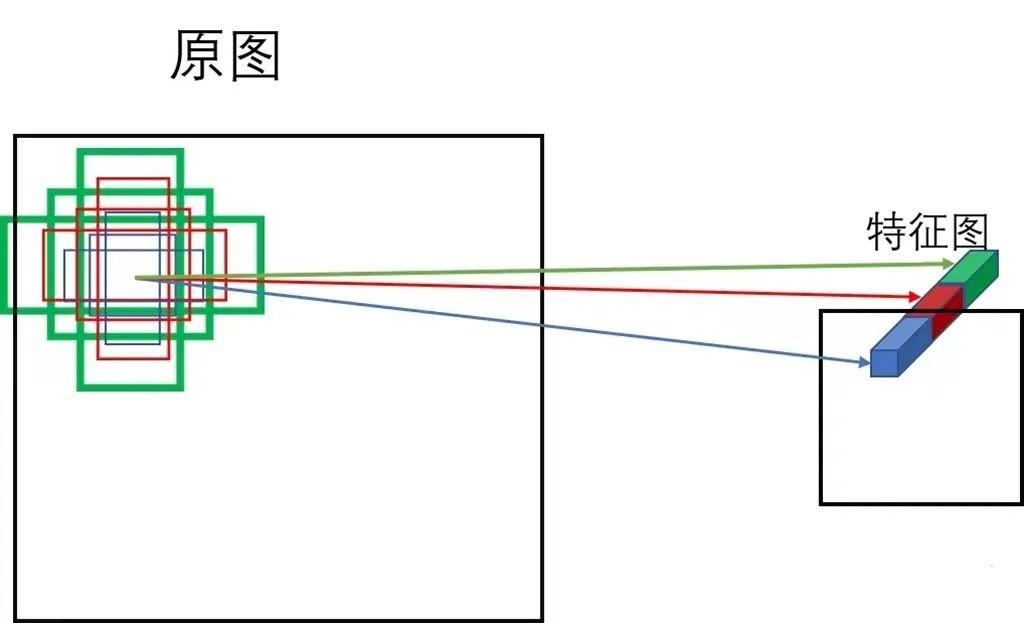
目标框回归

YOLOv5的目标框回归计算公式如下所示:
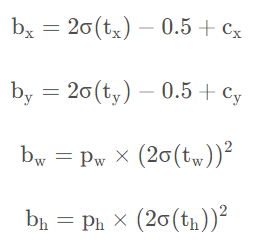
其中( b x , b y , b w , b h )表示预测框的中心点坐标、宽度和高度,( c x , c y )表示预测框中心点所在网格的左上角坐标,( t x , t y )
表示预测框的中心点相对于网格左上角坐标的偏移量,( t w , t h ) 表示预测框的宽高相对于anchor宽高的缩放比例,( p w , p h ) )表示先验框anchor的宽高。
为了将预测框的中心点约束到当前网格中,使用Sigmoid函数处理偏移量,使预测的偏移值保持在( 0 , 1 ) (0,1)(0,1)范围内。
这样一来,根据目标框回归计算公式,预测框中心点坐标的偏移量保持在( − 0.5 , 1.5 ) (-0.5,1.5)(−0.5,1.5)范围内。如上图蓝色区域所示。
正负样本匹配
如上面所述,YOLOv5的每个检测层上的每个网格都预设了多个anchor先验框,但并不是每个网格中都存在目标,也并不是每个anchor都适合用来回归当前目标。
因此需要对这些anchor先验框进行筛选,将其划分为正样本和负样本。本文的正负样本指的是预测框而不是Ground Truth(人工标注的真实框)。
与YOLOv3/4不同的是,YOLOv5采用的是基于宽高比例的匹配策略,它的大致流程如下:
1.对于每一个Ground Truth(人工标注的真实框),分别计算它与9种不同anchor的宽与宽的比值(w1/w2, w2/w1)和高与高的比值(h1/h2, h2/h1)。
2.找到Ground Truth与anchor的宽比(w1/w2, w2/w1)和高比(h1/h2, h2/h1)中的最大值,作为该Ground Truth和anchor的比值。
3.若Ground Truth和anchor的比值小于设定的比值阈值(超参数中默认为anchor_t = 4.0)。
那么这个anchor就负责预测这个Ground Truth,即这个anchor所回归得到的预测框就被称为正样本,剩余所有的预测框都是负样本。
通过上述方法,YOLOv5不仅筛选了正负样本,同时对于部分Ground Truth在单个尺度上匹配了多个anchor来进行预测,总体上增加了一定的正样本数量。
除此以外,YOLOv5还通过以下几种方法增加正样本的个数,从而加快收敛速度。
1.跨网格扩充:假设某个Ground Truth的中心点落在某个检测层上的某个网格中,除了中心点所在的网格之外,其左、上、右、下4个邻域的网格中。
靠近Ground Truth中心点的两个网格中的anchor也会参与预测和回归,即一个目标会由3个网格的anchor进行预测,如下图所示。

2.跨分支扩充:YOLOv5的检测头包含了3个不同尺度的检测层,每个检测层上预设了3种不同长宽比的anchor,假设一个Ground Truth可以和不同尺度的检测层上的anchor匹配。
则这3个检测层上所有符合条件的anchor都可以用来预测该Ground Truth,即一个目标可以由多个检测层的多个anchor进行预测
损失计算
4.1 总损失
YOLOv5对特征图上的每个网格进行预测,得到的预测信息与真实信息进行对比,从而指导模型下一步的收敛方向。
损失函数的作用就是衡量预测信息和真实信息之间的差距,若预测信息越接近真实信息,则损失函数值越小。YOLOv5的损失主要包含三个方面:
矩形框损失(bbox_loss)、分类损失(cls_loss)、置信度损失(obj_loss)。
总损失的表达式为:
Loss=box_gain×bbox_loss+cls_gain×cls_loss+obj_gain×obj_loss
其中b o x _ g a i n box\_gainbox_gain、c l s _ g a i n 分别对应不同的损失权重,默认值分别为0.05,0.5,1.0。
4.2 边界框损失
文链接:https://arxiv.org/abs/1911.08287
IoU,即交并比,它的作用是衡量目标检测中预测框与真实框的重叠程度。假设预测框为A,真实框为B,则IoU的表达式为:IoU= A⋃BA⋂B

但是当预测框与真实框没有相交时,IoU不能反映两者之间的距离,并且此时IoU损失为0,将会影响梯度回传,从而导致无法训练。
此外,IoU无法精确的反映预测框与真实框的重合度大小。因此为了改进IoU,又不断提出了GIoU、DIoU和CIoU等一系列IoU的变种。
YOLOv5默认使用CIoU来计算边界框损失。CIoU是在DIoU的基础上,进一步考虑了Bounding Box的宽高比。
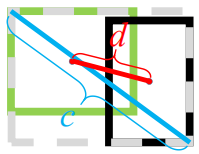
其中DIoU将预测框和真实框之间的距离,重叠率以及尺度等因素都考虑了进去,使得目标框回归变得更加稳定。它的损失计算公式为
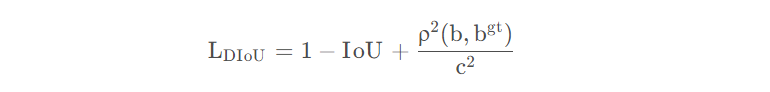
其中b和b^{gt}分别表示预测框和真实框的中心点,ρ \rhoρ表示两个中心点之间的欧式距离,c 表示预测框和真实框的最小闭包区域的对角线距离,如下图所示

4.3 分类损失

4.4 置信度损失
每个预测框的置信度表示这个预测框的可靠程度,值越大表示该预测框越可靠,也表示越接近真实框。
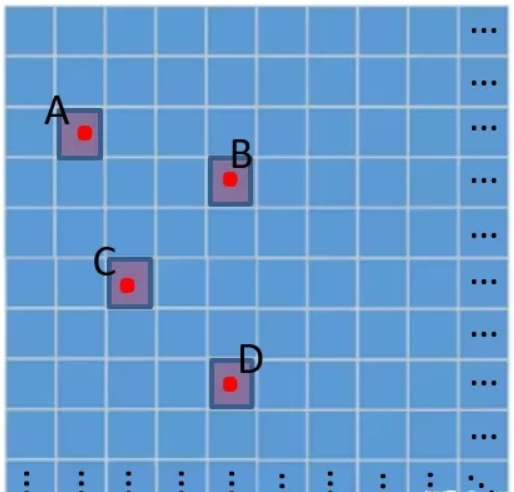
如下图所示,红点A 、B 、C 、D 表示真实框的中心点,那么每个红点所在网格对应的anchor所预测和回归得到的预测框置信度应该比较大甚至接近1,而其它网格对应的预测框置信度则会比较小甚至接近0。
对于置信度标签,YOLO之前的版本认为所有存在目标的网格(正样本)对应的标签值均为1,其余网格(负样本)对应的标签值为0。
但是这样带来的问题是有些预测框可能只是在目标的周围,而并不能很好地框住目标。
因此YOLOv5的做法是,根据网格对应的预测框与真实框的CIoU作为该预测框的置信度标签。它的代码实现如下:
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * score_iou其中self.gr为标签平滑系数,当参数self.gr为1时,置信度标签就等于CIoU。
与计算分类损失一样,YOLOv5默认使用二元交叉熵函数来计算置信度损失。
除此以外,对于不同尺度的检测层上得到的置信度损失,YOLOv5分配了不同的权重系数。
按照检测层尺度从大到小的顺序,对应的默认的权重系数分别为4.0、1.0、0.4,即用于检测小目标的大尺度特征图上的损失权重系数更大,从而使得网络在训练时更加侧重于小目标。
数据增强
5.1 Mosaic
YOLOv5借鉴了YOLOv4中的Mosaic数据增强方法,它是CutMix数据增强方法的进化版。
主要思想是任意抽取四张图片进行随机裁剪,然后拼接到一张图片上作为训练数据,同时每张图片上的标注框也会进行相应的裁剪。

这样做的好处是变相增大了batch_size,丰富了图像背景,同时通过对识别物体的裁剪,使模型根据局部特征识别物体,有助于被遮挡物体的检测,从而提升了模型的检测能力。Mosaic数据增强的操作过程如下:
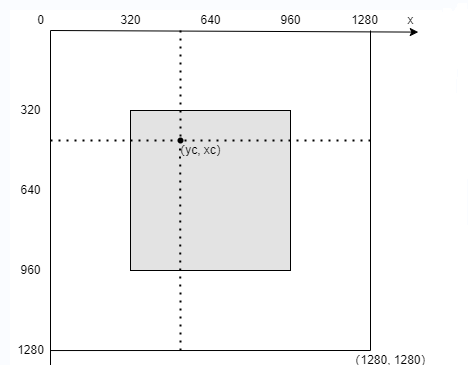
1.假设抽取的每张图片尺寸为( 640 , 640 ) ,重新拼接后的图片尺寸为( 1280 , 1280 ) 。在下图的灰色区域中随机生成一个中心点( x c , y c ) ,从而将平面分割成四块不同大小的区域。
labels4, segments4 = [], []s = self.img_sizeyc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border)
2.在加载第一张图片后,从数据集中再随机抽取三张图片,并打乱这四张图片的顺序。
indices = [index] + random.choices(self.indices, k=3)random.shuffle(indices)
3.将第一张图像放置在左上角的区域,其右下角坐标与随机生成的中心点对齐;
将第二张图像放置在右上角的区域,其左下角坐标与随机生成的中心点对齐;
将第三张图像放置在左下角的区域,其右上角坐标与随机生成的中心点对齐;
将第四张图像放置在右下角的区域,其左上角坐标与随机生成的中心点对齐。
if i == 0:img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8)x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, ycx1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, helif i == 1:x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), ycx1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), helif i == 2:x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)elif i == 3:x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]padw = x1a - x1bpadh = y1a - y1b
4.假设抽取的图片尺寸超过了填充区域给定的大小,则需要对抽取的图片中超过填充区域的部分进行裁剪,如下图所示。
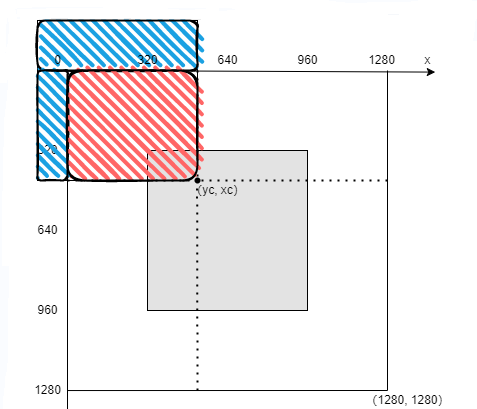
假设抽取的图片尺寸小于填充区域给定的大小,则需要对缺少的区域进行填充,如下图所示。

5.将归一化后的标注框坐标还原到原图尺寸,然后转换到拼接后的坐标系中,得到新的标注框坐标。
labels, segments = self.labels[index].copy(), self.segments[index].copy()if labels.size:labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh)segments = [xyn2xy(x, w, h, padw, padh) for x in segments]labels4.append(labels)segments4.extend(segments)
6.由于重新拼接后的图片尺寸为( 1280 , 1280 ) ,因此还需要将其尺寸缩放到( 640 , 640 ) ,保证与用于训练的输入图片尺寸一致。
5.2 MixUp
MixUp是一种简单的数据增强方法,它的主要思想是将两个随机样本的特征和标签进行加权求和,从而得到一个新的训练样本。
公式如下:
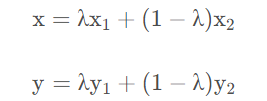
其中x 1和x 2 表示两个不同的输入样本,y 1 和y 2 表示两个不同的输入样本对应的标签,λ表示两个样本融合的比例系数,且满足Beta分布。
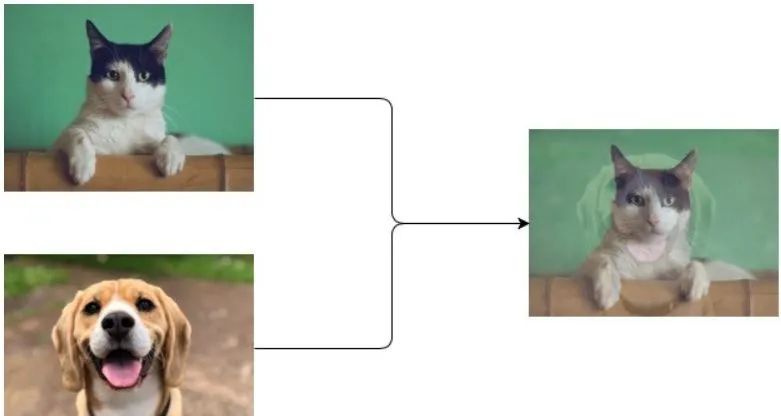
但是在YOLOv5中只对图像特征做了融合,而对标签做了拼接,具体的代码实现如下:
r = np.random.beta(32.0, 32.0)im = (im * r + im2 * (1 - r)).astype(np.uint8)labels = np.concatenate((labels, labels2), 0)
编辑:古月居
本文仅做学术分享,如有侵权,请联系删文。
—THE END—