
云原生背景下故障演练体系建设的思考与实践—云原生混沌工程系列之指南篇

作者:智妍(郑妍)、浣碧(何颖)
什么是混沌工程,
云原生大潮下的混沌工程特点
Cloud Native
混沌工程实施模式的阶段和发展
Cloud Native

手工演练:一般在高可用能力建设初期阶段,或者一次性验收的情况下手工注入故障完成。通过人为查看告警是否生效,系统恢复情况来进行演练。在这个阶段只需要一些故障注入的小工具或者脚本,方便后续使用即可。
自动化演练:高可用能力建设到一定阶段后,往往会有定期检查高可用能力是否退化的需求,自动化演练开始排上日程。自动化演练步骤一般包括:环境准备 -> 故障注入 -> 检查 -> 环境恢复。在每个步骤中配置相应的脚本来形成演练流程,下一次就可以一键点击自动化执行了。
常态化执行:演练进行到下一阶段,我们会有更高的要求,希望演练可以自主混沌化执行,以无人值守的方式进行,这又对系统的高可用能力有了新的挑战。这要求系统有不仅有监控告警可以发现故障,也有对应的预案模块来负责恢复,而要做到无人值守,需要系统进行更智能精确的判断故障情况,自动执行相应预案。
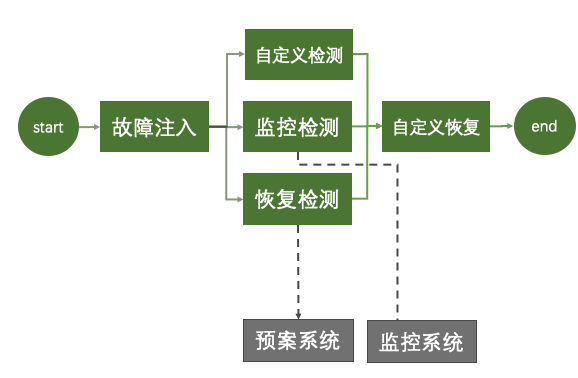
生产突袭:以上演练大多在灰度环境进行,不会影响到业务,生产突袭则要求系统有能力在生产环境控制爆炸半径的前提下进行故障演练,以期发现一些业务相关、规模相关、配置相关、应急响应相关的,在灰度环境遗漏的部分,生产环境的演练对系统的要求较高,需要有一套执行规范,对系统的隔离能力也有较高要求。大多数的工作,能力建设都在灰度环境完成验证,但生产突袭仍作为一个有效且必要的演练手段,用更真实的场景给研发体感,让其真实执行预案,也锻炼了应急能力,对系统有更多信心和认知。
如何进行一次完整的故障演练实施
Cloud Native
业务测试环境:用来进行 e2e 测试,全面的功能验收,这个环境和有业务流量的生产网络是隔离的,从网络上避免了流量错误进入到其他环境,因此可以在这个环境上尽情的进行各种容错性测试。
金丝雀环境:可以理解为是一种全面的链路灰度环境,这个环境有当前系统的所有组件,一般用来做上下游联调,系统内部的链路灰度使用,这个环境是没有实际业务流量的;
安全生产灰度环境:这个环境我们会引入 1% 的生产流量,并提前建设了切流能力,一旦这个环境出现问题,可以把流量迅速切换到生产环境中,该环境一般用来结合用户流量做一段时间的灰度,以免全量发布导致的不可控;
生产环境:真实用户流量的环境,这个环境的任何运维动作都需要进行严格的变更审核和前几个环境的灰度通过才能变更;
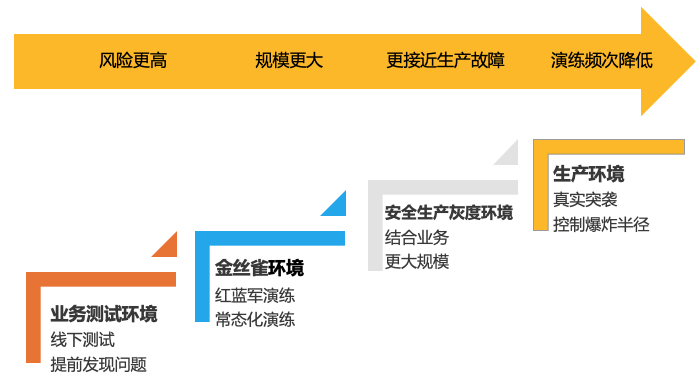
隔离性:灰度环境和生产环境尽量做到隔离,包括但不限于网络隔离,权限隔离,数据隔离等,考虑到一些容灾的能力,还可以将两个集群建设在不同地域的 Kubernetes 集群中。
真实性:灰度环境和生产环境尽量保持一致,比如外部依赖,组件版本。
历史故障:
架构分析
社区经验:
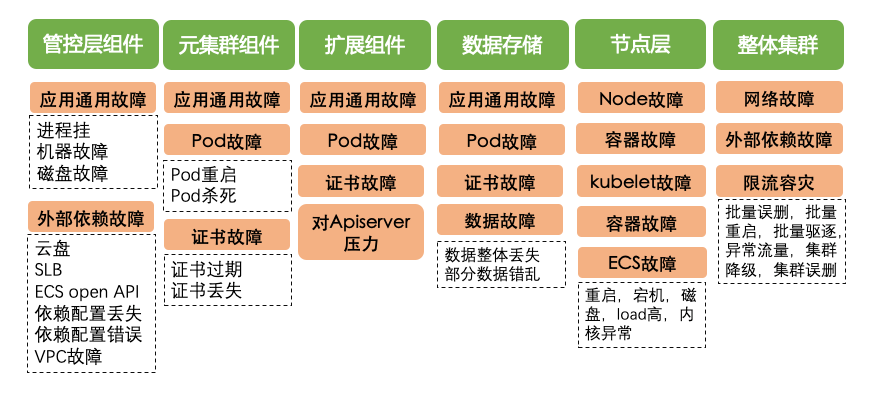
发现能力
恢复能力
结语
Cloud Native
相关链接
Cloud Native
评论