
哈工大车万翔:自然语言处理范式正在变迁
Datawhale干货
作者:车万翔,哈工大教授,编辑:李rumor
最近几天被OpenAI推出的ChatGPT[1]刷屏了,其影响已经不仅局限于自然语言处理(NLP)圈,就连投资圈也开始蠢蠢欲动了,短短几天ChatGPT的用户数就超过了百万。通过众多网友以及我个人对其测试的结果看,ChatGPT的效果可以用惊艳来形容,具体结果我在此就不赘述了。不同于GPT-3刚推出时人们的反应,对ChatGPT大家发出更多的是赞叹之词。聊天、问答、写作、编程等等,样样精通。因此也有人惊呼,“通用人工智能(AGI)即将到来”、“Google等传统搜索引擎即将被取代”,所以也对传说中即将发布的GPT-4更加期待。
从技术角度讲,ChatGPT还是基于大规模预训练语言模型(GPT-3.5)强大的语言理解和生成的能力,并通过在人工标注和反馈的大规模数据上进行学习,从而让预训练语言模型能够更好地理解人类的问题并给出更好的回复。这一点上和OpenAI于今年3月份推出的InstructGPT[2]是一致的,即通过引入人工标注和反馈,解决了自然语言生成结果不易评价的问题,从而就可以像玩儿游戏一样,利用强化学习技术,通过尝试生成不同的结果并对结果进行评分,然后鼓励评分高的策略、惩罚评分低的策略,最终获得更好的模型。
不过说实话,我当时并不看好这一技术路线,因为这仍然需要大量的人工劳动,本质上还是一种“人工”智能。不过ChatGPT通过持续投入大量的人力,把这条路走通了,从而更进一步验证了那句话,“有多少人工,就有多少智能”。
不过,需要注意的是,ChatGPT以及一系列超大规模预训练语言模型的成功将为自然语言处理带来新的范式变迁,即从以BERT为代表的 预训练+精调(Fine-tuning)范式,转换为以GPT-3为代表的 预训练+提示(Prompting)的范式[3]。所谓提示,指的是通过构造自然语言提示符(Prompt),将下游任务转化为预训练阶段的语言模型任务。例如,若想识别句子“我喜欢这部电影。”的情感倾向性,可以在其后拼接提示符“它很 ”。如果预训练模型预测空格处为“精彩”,则句子大概率为褒义。这样做的好处是无需精调整个预训练模型,就可以调动模型内部的知识,完成“任意”的自然语言处理任务。当然,在ChatGPT出现之前,这种范式转变的趋势并不明显,主要有两个原因:
第一,GPT-3级别的大模型基本都掌握在大公司手里,因此学术界在进行预训练+提示的研究时基本都使用规模相对比较小的预训练模型。由于规模规模不够大,因此预训练+提示的效果并不比预训练+精调的效果好。而只有当模型的规模足够大后,才会涌现(Emerge)出“智能”[4]。最终,导致之前很多在小规模模型上得出的结论,在大规模模型下都未必适用了。
第二,如果仅利用预训练+提示的方法,由于预训练的语言模型任务和下游任务之间差异较大,导致这种方法除了擅长续写文本这种预训练任务外,对其他任务完成得并不好。因此,为了应对更多的任务,需要在下游任务上继续预训练(也可以叫预精调),而且现在的趋势是在众多的下游任务上预精调大模型,以应对多种、甚至未曾见过的新任务[5]。所以更准确地说,预训练+预精调+提示将成为自然语言处理的新范式。
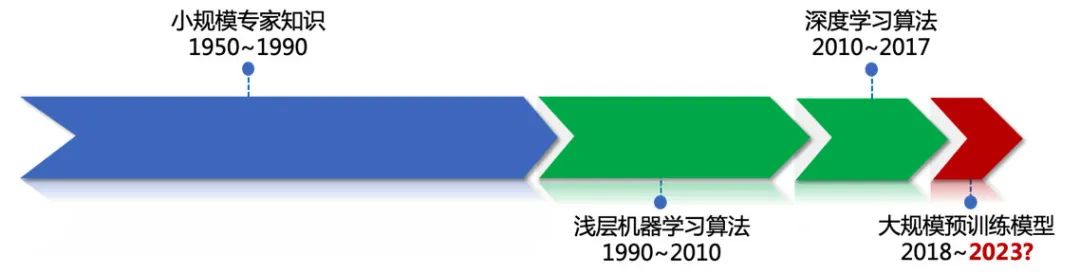
不同于传统预训练+精调范式,预训练+预精调+提示范式将过去一个自然语言处理模型擅长处理一个具体任务的方式,转换为了用一个模型处理多个任务,甚至未曾见过的通用任务的方式。所以从这个角度来讲,通用人工智能也许真的即将到来了。这似乎也和我几年前的预测相吻合,我当时曾预测,“结合自然语言处理历次范式变迁的规律(图1),2018年预训练+精调的范式出现之后5年,即2023年自然语言处理也许将迎来新的范式变迁”。
那么,接下来如何进一步提升预训练+预精调+提示新范式的能力,并在实际应用中将其落地呢?
首先,显式地利用人工标注和反馈仍然费时费力,我们应该设法更自然地获取并利用人类的反馈。也就是在实际应用场景中,获取真实用户的自然反馈,如其回复的语句、所做的行为等,并利用这些反馈信息提升系统的性能,我们将这种方式称为交互式自然语言处理。不过用户的交互式反馈相对稀疏,并且有些用户会做出恶意的反馈,如何克服稀疏性以及避免恶意性反馈都将是亟待解决的问题。
其次,目前该范式生成的自然语言文本具有非常好的流畅性,但是经常会出现事实性错误,也就是会一本正经地胡说八道。当然,使用上面的交互式自然语言处理方法可以一定程度上解决此类问题,不过对于用户都不知道答案的问题,他们是无法对结果进行反馈的。此时又回到了可解释性差,这一深度学习模型的老问题上。如果能够像写论文时插入参考文献一样,在生成的结果中插入相关信息的出处,则会大大提高结果的可解释性。
最后,该范式依赖超大规模预训练语言模型,然而这些模型目前只掌握在少数的大公司手中,即便有个别开源的大模型,由于其过于庞大,小型公司或研究组也无法下载并使用它们。所以,在线调用是目前使用这些模型最主要的模式。在该模式下,如何针对不同用户面对的不同任务,使用用户私有的数据对模型进行进一步预精调,并且不对公有的大模型造成影响,成为该范式实际应用落地所迫切需要解决的问题。此外,为了提高系统的运行速度,如何通过在线的大模型获得离线的小模型,并且让离线小模型保持大模型在某些任务上的能力,也成为模型能实际应用的一种解决方案。
未来已来,让我们共同期待!
注:有幸在车老师的朋友圈学习到了他对于最近ChatGPT的一些见解,征得老师同意后分享给大家,转载请注明作者。
参考文献:
[1] https://chat.openai.com/
[2] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, Ryan Lowe. Training language models to follow instructions with human feedback. https://arxiv.org/abs/2203.02155
[3] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, Graham Neubig. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. https://arxiv.org/abs/2107.13586
[4] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, William Fedus. Emergent Abilities of Large Language Models. https://arxiv.org/abs/2206.07682
[5] Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, Quoc V. Le. Finetuned Language Models Are Zero-Shot Learners. https://arxiv.org/abs/2109.01652
整理不易,
点
赞
三连
↓