
笔记 | 那些不得不掌握的卷积神经网络CNN的架构
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

最近年终总结内容,正好把学习笔记进行总结
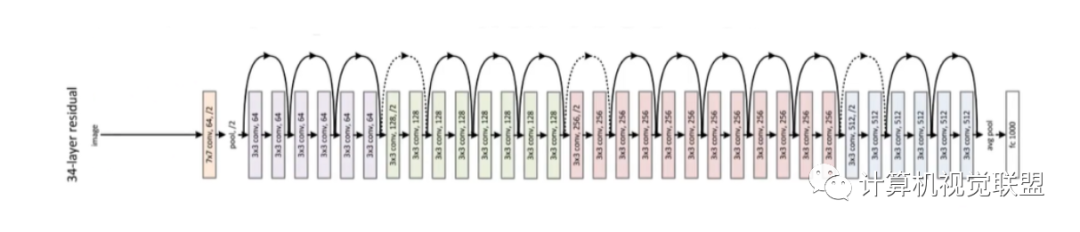
使用残差网络(或ResNet)赢得了ILSVRC 2015挑战赛
它是由大佬何凯明等人开发的。
使用由152层组成的超深CNN,它的前5位错误率达到了惊人的3.6%。它证实了总体趋势:模型越来越多,参数越来越少。能够训练这种深层网络的关键是使用跳过连接(也称为快捷连接):馈入层的信号也将添加到位于堆栈上方的层的输出中。让我们看看为什么这很有用。
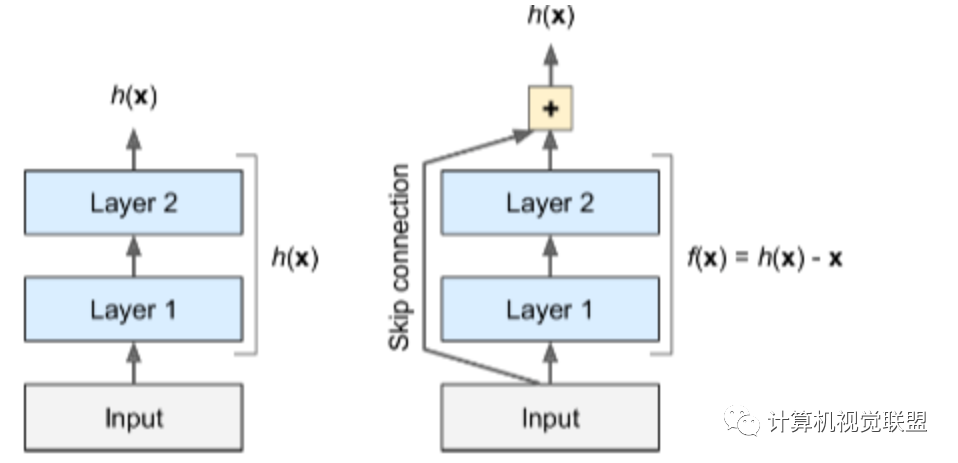
在训练神经网络时,目标是使其成为目标函数h(x)的模型。如果将输入x添加到网络的输出(即,添加跳过连接),则网络将被强制建模为f(x)= h(x)-x而不是h(x)。这称为残差学习。

AlexNet CNN架构大获全胜,赢得了2012年ImageNet ILSVRC挑战:它的前五位错误率达到了17%,而倒数第二位的错误率仅为26%
它是由Alex Krizhevsky,Ilya Sutskever和Geoffrey Hinton开发的。
它与LeNet-5非常相似,只是更大和更深,它是第一个将卷积层直接堆叠在彼此之上的方法,而不是在每个卷积层之上堆叠池化层的方法。
它由8个卷积陆地完全连接层和3个最大池化层组成。
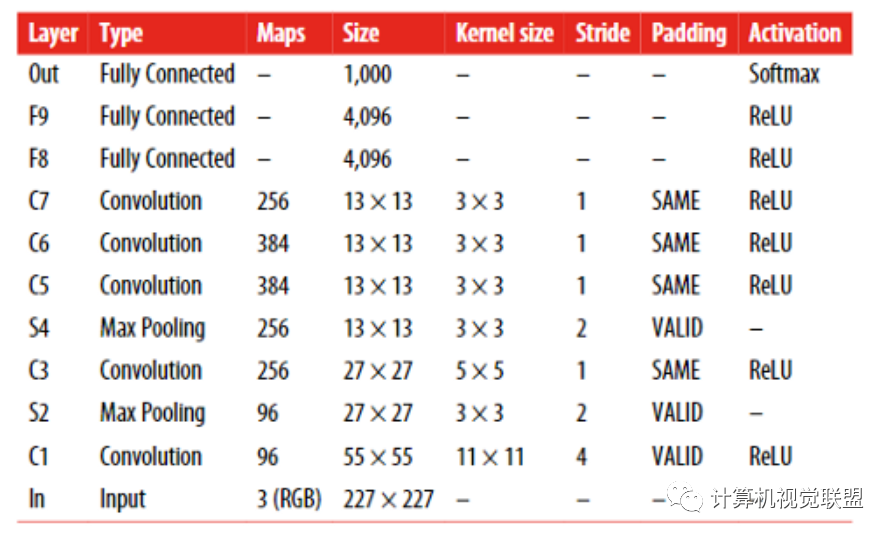
为了减少过度拟合,作者使用了两种正则化技术:首先,他们在训练过程中对F8层和F9层的输出应用了50%的丢失率。其次,他们通过将训练图像随机偏移各种偏移量,水平翻转它们并更改亮度条件来执行数据增强。

VGGNet是2014年ILSVRC挑战赛的亚军。
它由K.Simon-yan和A.Zisserman开发。
在VGGNet的设计中,发现不需要交替的卷积和池化层。因此,VGGnet依次使用多个卷积层,并在其间合并池层。
它具有非常简单和经典的架构,具有2或3个卷积层,一个池化层,然后又是2或3个卷积层,一个池化层,依此类推(总共只有16个卷积层),最后还有一个密集的具有2个隐藏层和输出层的网络。它仅使用3×3过滤器,但使用了许多过滤器。
GoogleNet

GoogLeNet体系结构是由Christian Szegedy等人开发的。由Google Research提供,并通过将前5名错误率降低到7%以下而赢得了2014年ILSVRC挑战。
如此出色的性能很大程度上是因为该网络比以前的CNN更深
这是通过称为初始模块的子网实现的,该子网使GoogLeNet可以比以前的体系结构更有效地使用参数:GoogLeNet的参数实际上比AlexNet少10倍(大约是600万,而不是6000万)。
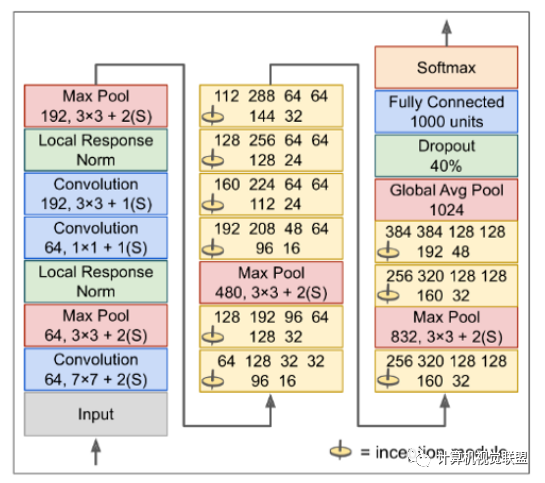
GoogLeNet使用9个初始模块,它使用平均池从7x7x1024到1x1x1024消除了所有完全连接的层。这样可以节省很多参数。
Google研究人员后来提出了GoogLeNet架构的几种变体,包括Inception-v3和Inception-v4,它们使用了稍有不同的inception模块,并获得了更好的性能。
end
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~