
双重检查锁,原来是这样演变来的,你了解吗

最近在看Nacos的源代码时,发现多处都使用了“双重检查锁”的机制,算是非常好的实践案例。这篇文章就着案例来分析一下双重检查锁的使用以及优势所在,目的就是让你的代码格调更加高一个层次。
同时,基于单例模式,讲解一下双重检查锁的演变过程。
Nacos中的双重检查锁
在Nacos的InstancesChangeNotifier类中,有这样一个方法:
private final Map<String, ConcurrentHashSet<EventListener>> listenerMap = new ConcurrentHashMap<String, ConcurrentHashSet<EventListener>>();
private final Object lock = new Object();
public void registerListener(String groupName, String serviceName, String clusters, EventListener listener) {
String key = ServiceInfo.getKey(NamingUtils.getGroupedName(serviceName, groupName), clusters);
ConcurrentHashSet<EventListener> eventListeners = listenerMap.get(key);
if (eventListeners == null) {
synchronized (lock) {
eventListeners = listenerMap.get(key);
if (eventListeners == null) {
eventListeners = new ConcurrentHashSet<EventListener>();
listenerMap.put(key, eventListeners);
}
}
}
eventListeners.add(listener);
}
该方法的主要功能就是对监听器事件进行注册。其中注册的事件都存在成员变量listenerMap当中。listenerMap的数据结构是key为String,value为ConcurrentHashSet的Map。也就是说,一个key对应一个集合。
针对这种数据结构,在多线程的情况下,Nacos处理流程如下:
通过key获取value值; 判断value是否为null; 如果value值不为null,则直接将值添加到Set当中; 如果为null,就需要创建一个ConcurrentHashSet,在多线程时,有可能会创建多个,因此要使用锁。 通过synchronized锁定一个Object对象; 在锁内再获取一次value值,如果依然是null,则进行创建。 进行后续操作。
上述过程,在锁定前和锁定之后,做了两次判断,因此称作”双重检查锁“。使用锁的目的就是避免创建多个ConcurrentHashSet。
Nacos中的实例稍微复杂一下,下面以单例模式中的双重检查锁的演变过程。
未加锁的单例
这里直接演示单例模式的懒汉模式实现:
public class Singleton {
private static Singleton instance;
private Singleton() {
}
public Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
这是一个最简单的单例模式,在单线程下运转良好。但在多线程下会出现明显的问题,可能会创建多个实例。
以两个线程为例: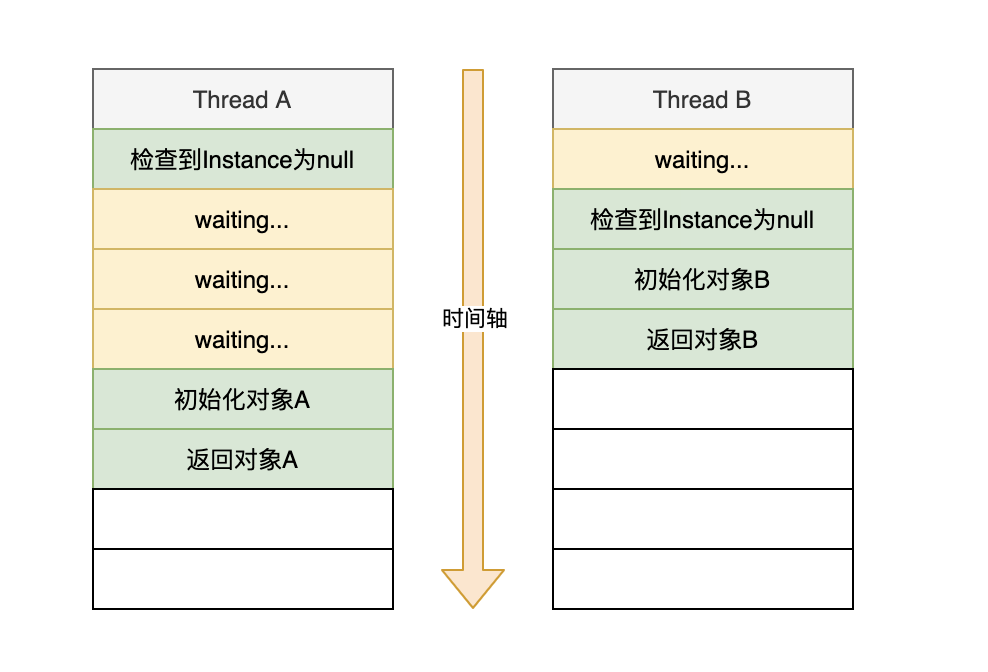
可以看到,当两个线程同时执行时,是有可能会创建多个实例的,这很明显不符合单例的要求。
加锁单例
针对上述代码的问题,很直观的想到是进行加锁处理,实现代码如下:
public class Singleton {
private static Singleton instance;
private Singleton() {
}
public synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
与第一个示例唯一的区别是在方法上添加了synchronized关键字。这时,当多个线程进入该方法时,需要先获得锁才能进行执行。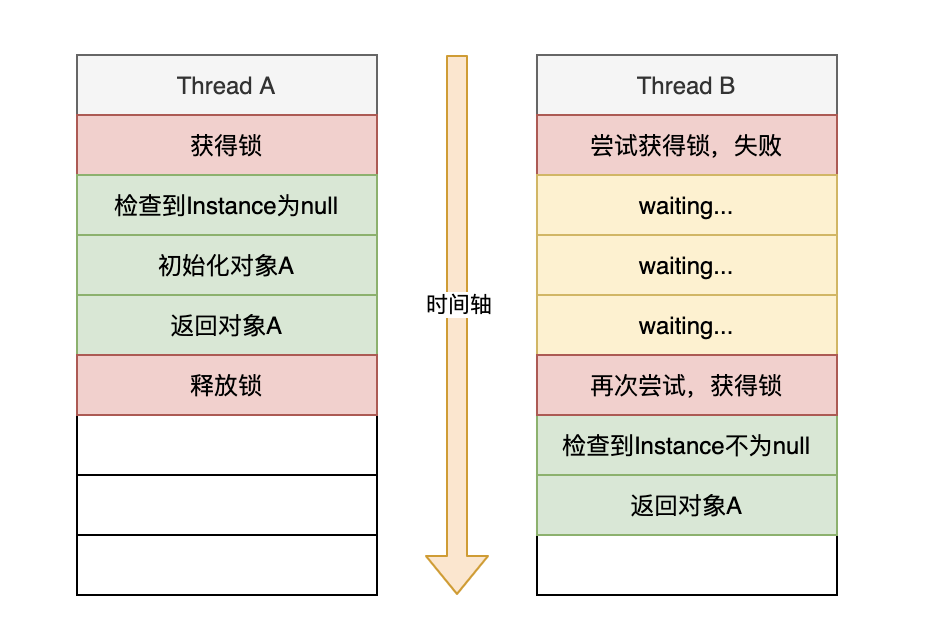
通过在方法上添加synchronized关键字,看似完美的解决了多线程的问题,但却带了性能问题。
我们知道使用锁会导致额外的性能开销,对于上面的单例模式,只有第一次创建时需要锁(防止创建多个实例),但查询时是不需要锁的。
如果针对方法进行加锁,每次查询也要承担加锁的性能损耗。
双重检查锁
针对上面的问题,就有了双重检查锁,示例如下:
public class Singleton {
private static Singleton instance;
private Singleton() {
}
public Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
第一,将锁的范围缩小的方法内;
第二,锁之前先判断一下是不是null,如果不为null,说明已经实例化了,直接返回,没必要进行创建;
第三,如果为null,进行加锁,然后再次判断是否为null。为什么要再次判断?因为一个线程判断为null之后,另外一个线程可能已经创建了对象,所以在锁定之后,需要再次核实一下,真的为null,则进行对象创建。
改进之后,既保证了线程的安全性,又避免了锁导致的性能损失。问题到此结束了吗?并没有,继续往下看。
JVM的指令重排
在某些JVM当中,编译器为了性能问题,会进行指令重排。在上述代码中new Singleton()并不是原子操作,有可能会被编译器进行重排操作。
创建对象可抽象为三步:
memory = allocate(); //1:分配对象的内存空间
ctorInstance(memory); //2:初始化对象
instance = memory; //3:设置instance指向刚分配的内存地址
上面操作中,操作2依赖于操作1,但操作3并不依赖于操作2。因此,JVM是可以进行指令重排优化的,可能会出现如下的执行顺序:
memory = allocate(); //1:分配对象的内存空间
instance = memory; //3:instance指向刚分配的内存地址,此时对象还未初始化
ctorInstance(memory); //2:初始化对象
指令重排之后,将操作3的赋值操作放在了前面,那就会出现一个问题:当线程A执行完步骤赋值操作,但还未执行对象初始化。此时,线程B进来了,在第一层判断时发现Instance已经有值了(实际上还未初始化),直接返回对应的值。那么,程序在使用这个未初始化的值时,便会出现错误。
针对此问题,可在instance上添加volatile关键字,使得instance在读、写操作前后都会插入内存屏障,避免重排序。
最终,单例模式实现如下:
public class Singleton {
private static volatile Singleton instance;
private Singleton() {
}
public Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
至此,一个完善的单例模式实现了。此时,你是否有一个疑问,为什么Nacos中的双重检查锁没有使用volatile关键字呢?
答案很简单:上面单例模式如果出现指令重排,会导致单例实例被使用。那么,再看Nacos的代码,由于创建ConcurrentHashSet并不会影响到查询,而真正影响查询的是listenerMap.put方法,而ConcurrentHashSet本身是线程安全的。因此,也就不会出现线程安全问题,不用使用volatile关键字了。
小结
阅读源码最有意思的一个地方就是可以看到很多经典知识的实践,如果能够深入思考,拓展一下,会获得意想不到的收获。
再回顾一下本文的重点:
阅读Nacos源码,发现双重检查锁的使用; 未加锁单例模式使用,会创建多个对象; 方法上加锁,导致性能下降; 代码内局部加锁,双重判断,既满足线程安全,又满足性能需求; 单例模式特例:创建对象分多步,会出现指令重排现象,采用volatile进行避免指令重排;
最后,想学习更多类似干货,关注一下吧,持续输出。

往期推荐

ReentrantLock 中的 4 个坑!

synchronized 中的 4 个优化,你知道几个?

synchronized 加锁 this 和 class 的区别!