
手把手教你使用 OpenAI 和 Node.js 构建 AI 图像生成器
12月7号,知名人工智能研究机构 Open AI 在Youtub上发布视频介绍使用OpenAI 和 DALL-E 模型创建一个网络应用程序,该应用程序将根据输入的文本从头开始生成图像。 视频链接:https://www.youtube.com/watch?v=fU4o_BKaUZE
前言💖
大家好,这里是opentiny-official小助手前沿技术文章分享,用最通俗易懂的话分享业界前沿WEB技术是我们的座右铭~
介绍📖
OpenAI API 几乎可以应用于任何涉及理解或生成自然语言或代码的任务。他们提供一系列适用于不同的任务模型,并且还能够根据自己的需求微调自定义模型。这些模型可用于从内容生成到语义搜索和分类的所有领域,例如文本补充、代码编写、SQL翻译、JS助手聊天机器人等。
OpenAI官网文档:https://beta.openai.com/docs/introduction

12月7号视频发布他们介绍了使用DALL·E 模型生成并处理图像,并将作为API使用,这意味着开发者可以将该系统构建到他们的应用程序、网站和服务中。

opentiny-official小助手也跟着他们一起体验了一些这款广为热捧的AI艺术生成的体验工具~ 大家也快来试试吧。
👉 Youtube指导视频 :https://www.youtube.com/watch?v=fU4o_BKaUZE
看看效果👀
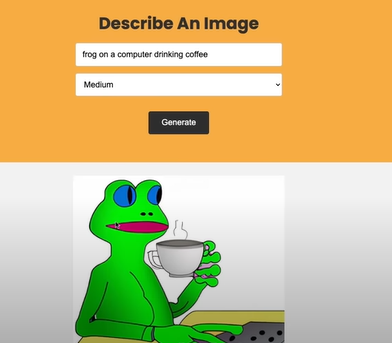
这次他们使用了nodejs作为后端,并输入文本描述“frog on a computer drinking coffee” (一只在电脑旁喝咖啡的青蛙),选择图片大小“Medium”,点击“Generate”,接下来静待片刻,就出现了如下的图片~ 是不是还挺 cool 的!下面咱们就可以跟着作者一步一步地实现下。
实现🚀
第一步 设置和安装依赖
打开vscode编辑器,安装node.js依赖
我们需要安装Express 去创建路由,dotenv用于环境变量的设置
npm init -y
npm i express openai dotev
npm i -D nodemon
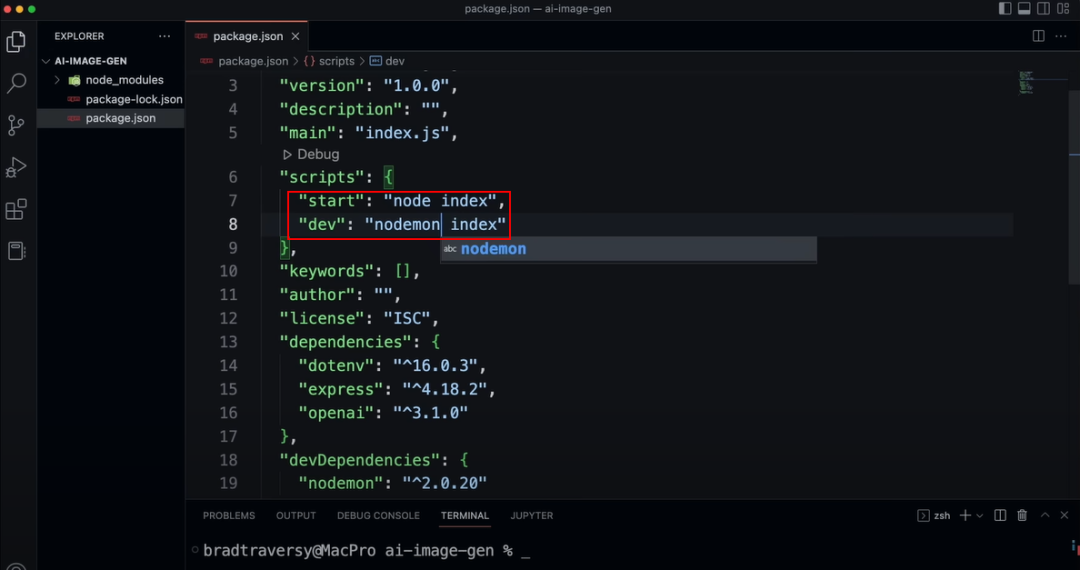
接着打开package.json文件,分别创建start和dev命令
第二步 引入Express服务端和ENV变量
创建index.js文件作为入口文件,分别引入express和detenv
const express = require('express');
const dotenv = require('dotenv').config();
const port = process.env.PORT || 5000;
const app = express();
app.listen(port, () => console.log(`Server started on port ${port}`));
新建.env文件,设置端口号为5000
PORT=5000
OPENAI_API_KEY=''
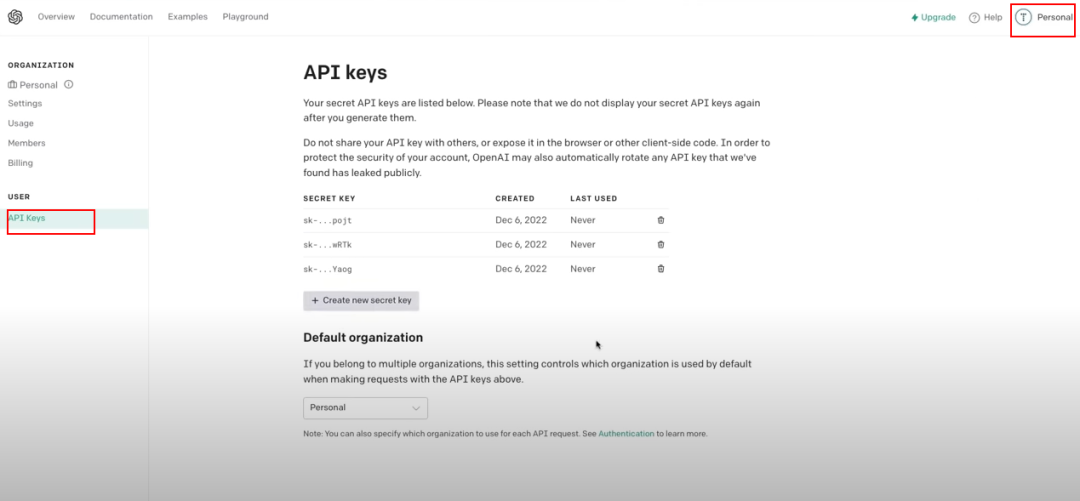
其中OPENAI_API_KEY需要从OPENAI网站上申请
第三步 新增 Route 和 Controller
接下来我们创建一个route文件 openaiRoutes.js, 并在index.js新增使用openai的路径
const express = require('express');
const dotenv = require('dotenv').config();
const port = process.env.PORT || 5000;
const app = express();
// 新增路由
app.use('/openai', require('./routes/openaiRoutes'));
app.listen(port, () => console.log(`Server started on port ${port}`));
openaiRoutes.js文件中新增
const express = require('express');
const router = express.Router();
router.post('/generateimage', (req, res) => {
res.status(200).json({
success: true,
});
});
module.exports = router;
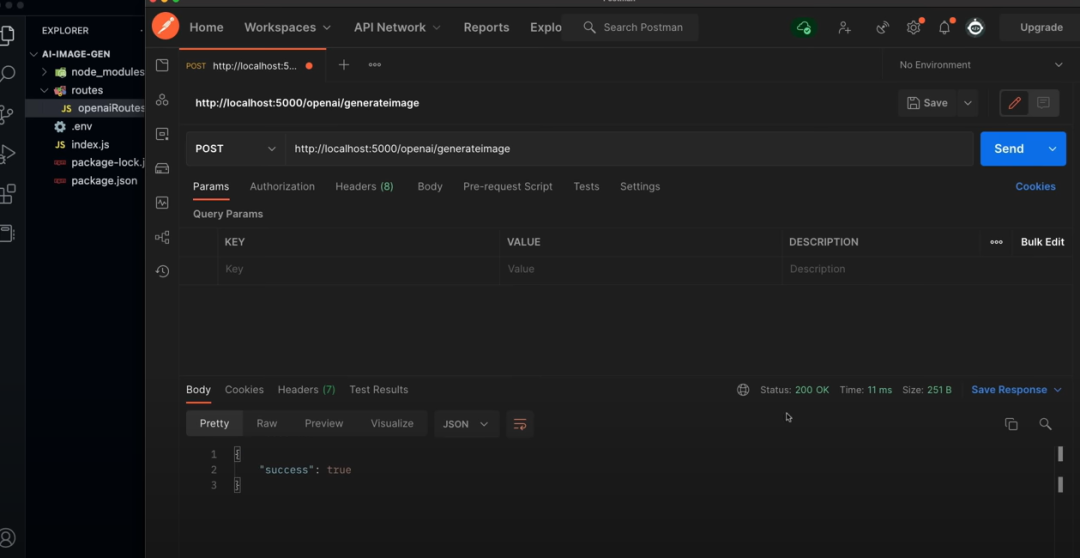
可以使用Postman工具测试接口,发送POST请求
接下来我们新建一个controller, controller里新建文件openaiController.js,在这个文件里我们定义一个生成图像的函数
const generateImage = async (req, res) => {
res.status(200).json({
success: true,
});
});
module.exports = { generateImage };
并在openaiRoutes.js文件里引入
const express = require('express');
// 从controller中引入
const { generateImage } = require('../controllers/openaiController');
const router = express.Router();
router.post('/generateimage', generateImage);
module.exports = router;
同样也可以用Postman测试接口,可以看到同上图一样的json返回。
第四步 OpenAI 库的请求和响应
接下来我们在openaiController.js文件中引入openai的API接口creatImage, 具体使用方法可以查看https://beta.openai.com/docs/guides/images
creatImage函数中定义prompt为Ploar bear on ice skates(一只溜冰的北极熊),n数量为1,大小size为 512x512。
const { Configuration, OpenAIApi } = require('openai');
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
const generateImage = async (req, res) => {
try {
const response = await openai.createImage({
prompt: 'Ploar bear on ice skates',
n: 1,
size: '512x512',
});
const imageUrl = response.data.data[0].url;
res.status(200).json({
success: true,
data: imageUrl,
});
} catch (error) {
if (error.response) {
console.log(error.response.status);
console.log(error.response.data);
} else {
console.log(error.message);
}
res.status(400).json({
success: false,
error: 'The image could not be generated',
});
}
};
module.exports = { generateImage };
同样,我们使用Postman测试接口,返回结果为imageUrl
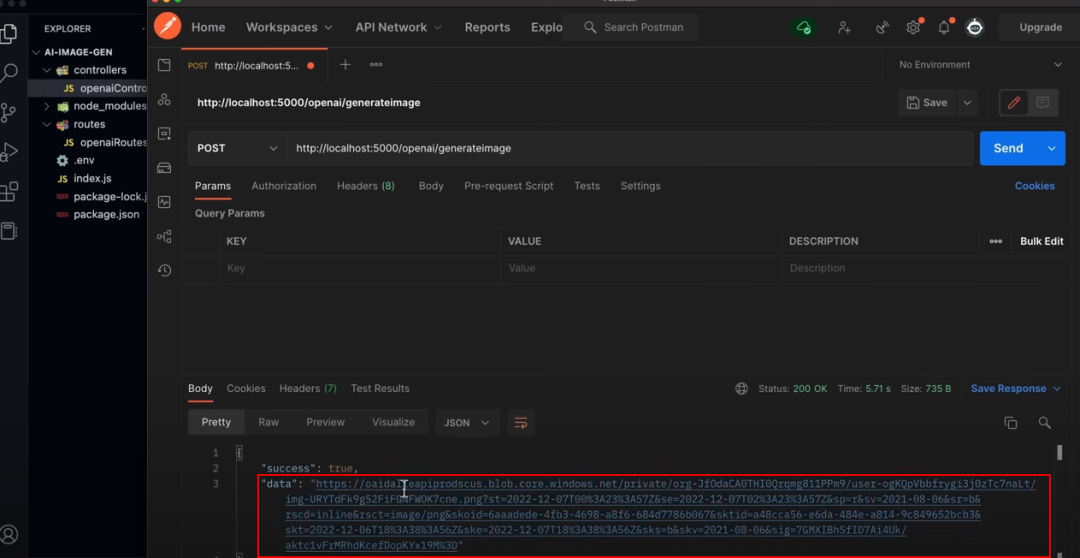
点开url地址,可以看到如下图片~ 哈哈,真的有一只在滑冰的北极熊~

第五步 请求body数据
接下来我们启用body解析,在index.js文件中添加Enable body parser部分内容
const express = require('express');
const dotenv = require('dotenv').config();
const port = process.env.PORT || 5000;
const app = express();
// Enable body parser
app.use(express.json());
app.use(express.urlencoded({ extended: false }));
app.use('/openai', require('./routes/openaiRoutes'));
app.listen(port, () => console.log(`Server started on port ${port}`));
并在openaiController.js中获取到body解析的数据
const { Configuration, OpenAIApi } = require('openai');
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
const generateImage = async (req, res) => {
// 获取body中的数据
const { prompt, size } = req.body;
const imageSize =
size === 'small' ? '256x256' : size === 'medium' ? '512x512' : '1024x1024';
try {
const response = await openai.createImage({
prompt,
n: 1,
size: imageSize,
});
const imageUrl = response.data.data[0].url;
res.status(200).json({
success: true,
data: imageUrl,
});
} catch (error) {
if (error.response) {
console.log(error.response.status);
console.log(error.response.data);
} else {
console.log(error.message);
}
res.status(400).json({
success: false,
error: 'The image could not be generated',
});
}
};
module.exports = { generateImage };
同样,我们用Postman测试接口,并在body中增加参数,这次我们设置的prompt为“man on the moon”(月球上的人),size选择为“mudium”
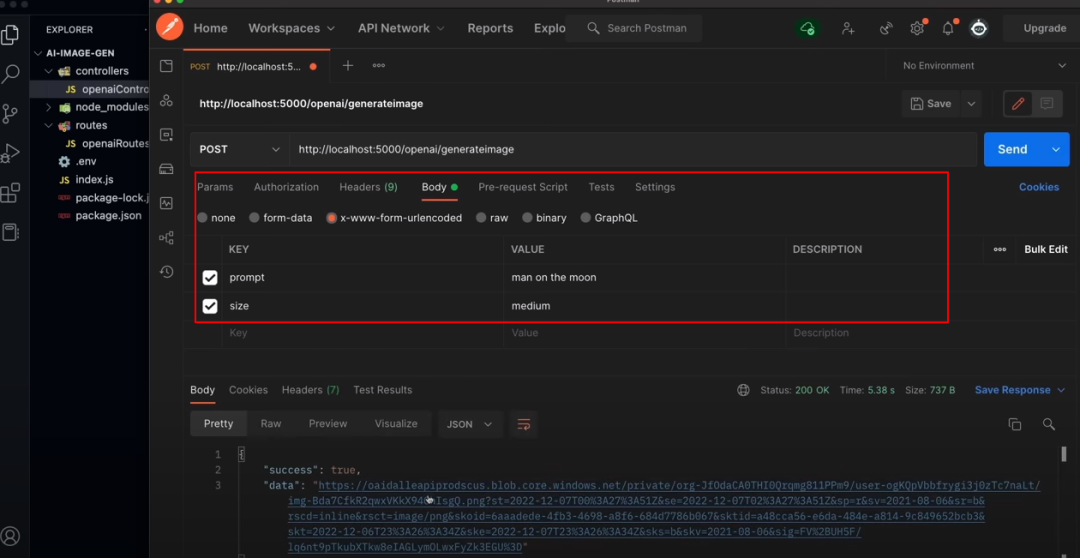
打开imageUrl查看结果, 有没有一种奇幻的感觉~

第六步 前端设置 Frontend Setup
接下来我们新建一个public文件夹去放置静态资源文件,并在index.js文件中设置静态文件。
const path = require('path');
const express = require('express');
const dotenv = require('dotenv').config();
const port = process.env.PORT || 5000;
const app = express();
app.use(express.json());
app.use(express.urlencoded({ extended: false }));
// Set static folder
app.use(express.static(path.join(__dirname, 'public')));
app.use('/openai', require('./routes/openaiRoutes'));
app.listen(port, () => console.log(`Server started on port ${port}`));
public文件夹里我们新建index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<link rel="stylesheet" href="css/style.css" />
<link rel="stylesheet" href="css/spinner.css" />
<script src="js/main.js" defer></script>
<title>OpenAI Image Genrator</title>
</head>
<body>
<header>
<div class="navbar">
<div class="logo">
<h2>OpenAI Image Genrator</h2>
</div>
<div class="nav-links">
<ul>
<li>
<a href="https://beta.openai.com/docs" target="_blank"
>OpenAI API Docs</a
>
</li>
</ul>
</div>
</div>
</header>
<main>
<section class="showcase">
<form id="image-form">
<h1>Describe An Image</h1>
<div class="form-control">
<input type="text" id="prompt" placeholder="Enter Text" />
</div>
<!-- size -->
<div class="form-control">
<select name="size" id="size">
<option value="small">Small</option>
<option value="medium" selected>Medium</option>
<option value="large">Large</option>
</select>
</div>
<button type="submit" class="btn">Generate</button>
</form>
</section>
<section class="image">
<div class="image-container">
<h2 class="msg"></h2>
<img style="max-width:100%" src="" alt="" id="image" />
</div>
</section>
</main>
<div class="spinner"></div>
</body>
</html>
并新增css文件夹用于存放css样式 ,css样式可查看github地址 public文件夹下。
第七步 表单事件监听
接下来我们需要为第六步创建的表单增加事件监听,在public文件夹下新建js文件夹并新增main.js文件。
function onSubmit(e) {
e.preventDefault();
document.querySelector('.msg').textContent = '';
document.querySelector('#image').src = '';
const prompt = document.querySelector('#prompt').value;
const size = document.querySelector('#size').value;
if (prompt === '') {
alert('Please add some text');
return;
}
console.log(prompt, size);
}
document.querySelector('#image-form').addEventListener('submit', onSubmit);
此时我们点击generate按钮会在控制台打印prompt, size的信息。
第八步 新增GenerateImageRequest()函数
同样是main.js文件里,我们补充GenerateImageRequest()函数去调用/openai/generateimage接口,并设置DOM中显示图像。
function onSubmit(e) {
e.preventDefault();
document.querySelector('.msg').textContent = '';
document.querySelector('#image').src = '';
const prompt = document.querySelector('#prompt').value;
const size = document.querySelector('#size').value;
if (prompt === '') {
alert('Please add some text');
return;
}
generateImageRequest(prompt, size);
}
// 新增GenerateImageRequest()函数
async function generateImageRequest(prompt, size) {
try {
showSpinner();
const response = await fetch('/openai/generateimage', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
prompt,
size,
}),
});
if (!response.ok) {
removeSpinner();
throw new Error('That image could not be generated');
}
const data = await response.json();
// console.log(data);
const imageUrl = data.data;
// DOM中显示图像
document.querySelector('#image').src = imageUrl;
removeSpinner();
} catch (error) {
document.querySelector('.msg').textContent = error;
}
}
function showSpinner() {
document.querySelector('.spinner').classList.add('show');
}
function removeSpinner() {
document.querySelector('.spinner').classList.remove('show');
}
document.querySelector('#image-form').addEventListener('submit', onSubmit);
以上步骤补充完成之后我们就可以看看最终效果啦。
演示💻
输入框中输入“brad traversy person web development”,大小输入“Medium”,显示效果如下:
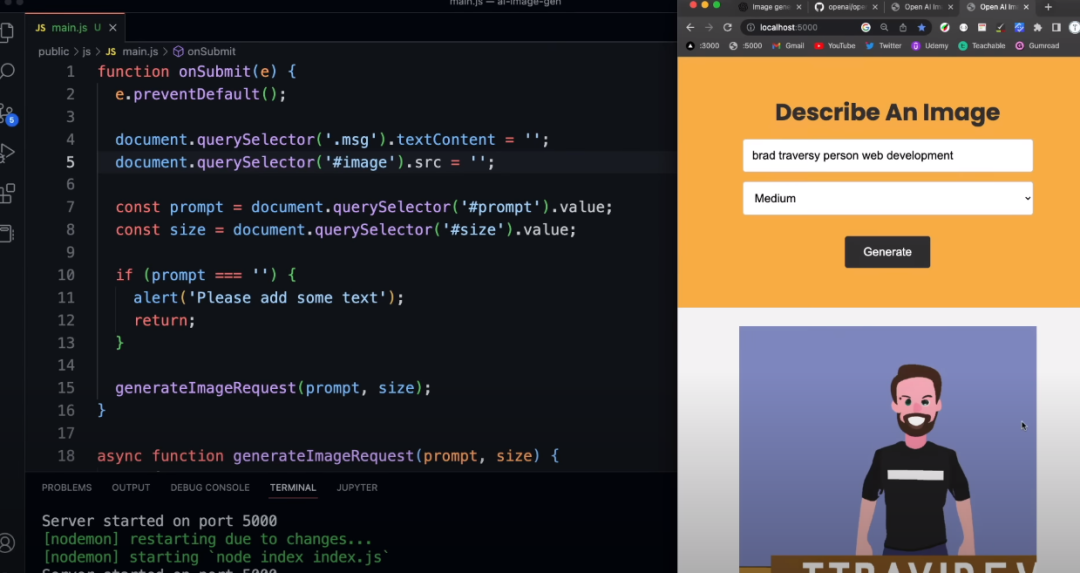
输入框中输入“cow dancing on a rainbow while juggling”,大小输入“Medium”,显示效果如下:
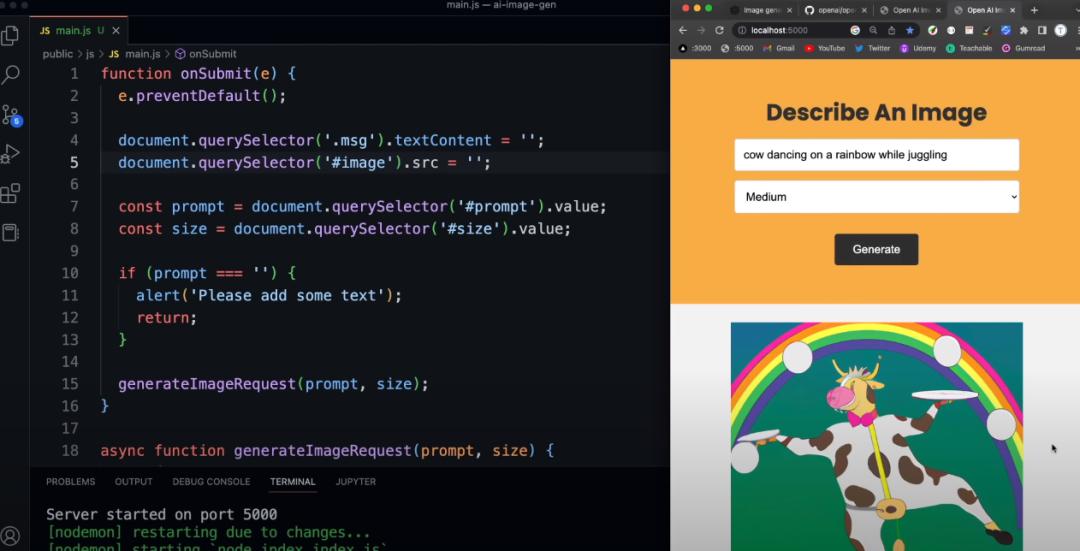
最后⭐
以上就是 opentiny-official小助手 本周的前沿WEB技术分享了,也欢迎各位爱好WEB的小伙伴一起互助交流~🤪欢迎关注我们接下来的开源项目—OpenTiny, 微信搜索我们的微信小助手: opentiny-official,拉你进群,了解它最新的动态。
💻 Code: https://github.com/bradtraversy/nodejs-openai-image
📄 OpenAI Docs: https://beta.openai.com/
⭐ All Courses: https://traversymedia.com
💖 Show Support
Patreon: https://www.patreon.com/traversymedia
PayPal: https://paypal.me/traversymedia
👇 Follow Traversy Media On Social Media:
Twitter: https://twitter.com/traversymedia
Instagram: https://www.instagram.com/traversymedia
Linkedin: https://www.linkedin.com/in/bradtraversy