周志华:“数据、算法、算力” 人工智能三要素,在未来要加上“知识”!
共
8604字,需浏览
18分钟
·
2022-05-24 04:44

作者:李雨晨 编辑:丛末
在CCF-GAIR 2020 的人工智能前沿专场上,南京大学计算机系主任、人工智能学院院长、CCF会士、ACM、AAAI、IEEE、IAPR Fellow周志华教授以“反绎学习”为题发表了大会报告。周志华表示,当今的人工智能热潮是由于机器学习,特别是其中的深度学习技术取得巨大进展,在大数据、大算力的支持下发挥出巨大的威力。机器学习算法模型用了更多数据和算力后,获得的性能增长可能远超算法模型设计者的预想。但是,把模型“做大”要付出高昂的成本代价。因此,他认为,在人工智能研究上,学术界和工业界适宜有不同的分工:把“对性能的追求”交给工业界,学术界回到本源,做“探路”和“思考未来”的事情。如何将“机器学习“与“逻辑推理”相结合,是人工智能领域的“圣杯问题”,以往的努力有的是“重推理”,有的是“重学习”,另一侧未能充分发挥力量。周志华教授提出了“反绎学习”,希望在一个框架下让机器学习和逻辑推理二者能更均衡更充分地发挥效用。他说到,“现在都知道人工智能技术发挥作用需要数据、算法和算力这三要素,未来需要把知识这个要素也考虑进来。知识凝聚了人的智慧。过去十几年,我们都是从数据驱动的角度来研究人工智能,现在是时候把数据驱动和知识驱动结合起来。”
以下为周志华教授的现场演讲内容,AI 科技评论进行了不改变原意的整理和编辑:
周志华:各位专家、朋友,大家上午好。感谢CCF和杜子德秘书长邀请,作为CCF的老会员,很高兴来参加这个活动。今天我跟大家分享的主题是《Abductive Learning(反绎学习)》。

人工智能技术的发展需要三个要素:数据、算法和算力。前几年,“大数据时代”是一个热词。大家都知道,大数据本身并不必然意味着大价值。数据是资源,要得到资源的价值,就必须进行有效的数据分析。在今天,有效的数据分析主要依靠机器学习算法。

今天的人工智能热潮主要就是由于机器学习,特别是其中的深度学习技术取得巨大进展,而且是在大数据、大算力的支持下发挥出巨大的威力。谈到深度学习,就要谈到深度神经网络。深度神经网络是非常庞大的系统,要训练出来需要很多数据、很强算力的支撑。人工智能算法模型对于算力的巨大需求,也推动了今天芯片业的发展。例如现在训练深度神经网络用到的GPU,更早是用于动画、渲染。如果没有深度神经网络这么大的需求,GPU也很难有今天这么大的市场,更不用说现在还有TPU等新的设计。所以我们可以看到,人工智能算法模型的发展,与算力、芯片发展之间,有相互促进的作用。这几方面的要素是互相促进、互相支撑。另一方面,把强大的算力、超大的数据往上堆,可能把现有机器学习算法模型的能力发挥到极致,所能达到的性能水平甚至可能令算法研究者自己都感到惊讶。这种“大力出奇迹”的“暴力美学”,已经产生出了非常强大的模型。比方说,最近大家谈到的当前最大人工智能模型——GPT3。它用到的训练数据是45TB,模型参数1750亿参数,模型大小700G。基于这个模型,很多困难的问题像自然语言处理里的许多问题都取得大幅度进展。我们来看看这篇关于GPT3的论文。和我们这个学科一般的论文不太一样,作者非常多,31位作者。文章后面有分工介绍,有的作者是专门写代码、有的是专门调参数、有的专门做数据采样、有的专门写论文…… 流水线分工作业,简直是工业化大生产的模式。再看看论文中的算法模型,可以看到,都是已有的技术,里面每一部分都不是新的。但是,基于强大的工程化组织,让它发挥了巨大作用。核心要点就是做大、做大、再做大。做大就必然付出代价。读这篇文章可以注意到里面有一句话,说作者发现这个工作中有一个Bug,但是由于成本太高,就没有重新训练。据说训练一次的成本大约1300万美元,所以即便发现有Bug,也就忍着算了。这样的模型能够解决很多问题,带来很大的性能提升。但是如此高昂的成本,也给我们从事人工智能研究的人带来了新的挑战,特别值得让学术界从事人工智能研究的学者思考一个问题:昂贵的成本必须换来效益回报,模型性能提升,在工业界能提升经济效益,有时哪怕性能提升一两个点,带来的回报可能足以弥补投入。但学术界如果花这么大成本,怎么能带来足够的回报?

学术界和工业界在人工智能研究上,适宜有不同的分工:把对“性能”的追求交给工业界,学术界不必过多地关注“性能”,因为模型性能提高那么几个点,对于学术界并没有多大的意义,仅仅是发表几篇论文的话,对不起这么巨大的投入。当然,我们培养了人才,人才是无价的,但是不用花这么多成本也可以培养优秀人才。把对性能的追求交给工业界,那么学术界做什么呢?回到本源,做学术界该做的工作:“探路”、“思考未来”。只要是全新的探索,成功了可以指出新的道路,即便不成功,也可以指出此路不通,都是有巨大意义的。一条道路探明之后,进一步的改进和提升就交给工业界。开头我们说到,人工智能技术发挥作用要有算法、算力和数据三大要素,未来是不是还这样呢?要不要往里面加东西?这是我们现在要思考的。疫情期间我们跟合作者,包括公司企业和医学专家,一起做了一点事,做的人工智能疫情分析推演模型为相关部门疫情防控决策做了一点微小的辅助。这个工作中大量使用了机器学习技术,但是仅有机器学习够不够?不够!我们使用了很多高水平医学专家、病毒专家的知识。我们深深体会到,如果机器学习技术能够跟专家知识很好地结合起来,或许会发挥超出我们预想的作用。事实上,在人工智能领域有一个长期存在的“圣杯”问题,就是我们什么时候能够把机器学习和逻辑推理很好地融合起来?如果能够得到一个完整的框架,能够让这二者同时在其中很好的发挥作用,那这是我们非常希望达到的一个目标。为什么要考虑这件事?我们首先可以看一看。逻辑推理它非常容易来利用我们的知识, 而机器学习呢比较容易来利用数据、利用证据、事实。但是如果从人类决策来看,很多决策的时候同时要使用知识以及证据。那么这两者能不能很好地弄到一起去呢?

非常遗憾,虽然逻辑推理和机器学习在人工智能历史上有很多研究,但是这两者基本上是独立发展起来的。比方说在1956年代到1990年代期间,逻辑推理和知识工程是人工智能的主流技术,但这时候机器学习的研究还很冷清。而到了90年代中期之后,机器学习研究变得非常的热门,但这时候逻辑推理和知识工程的研究又变得冷清起来,甚至今天从事这方面研究的人在全世界都已经很少了。

如果想把两者结合起来,最主要的障碍是什么呢?最主要的是,这两者几乎是基于完全不同的表示方式。逻辑推理我们一般来说可以认为它是基于一阶逻辑规则的表示。这里我们看一个例子,这里面有三个子句,第一个字句:对于任意X和Y,如果X是Y的父母,那么X比Y年长;第二个字句:对于任何两个人,X是Y的妈妈,那么X就是Y的父母;第三:LuLu是FiFi的妈妈。现在如果我们问:谁更年长一些?那么如果从这样的一个逻辑系统,我们马上就可以知道,第三句话,我们知道Lulu是Fifi的妈妈,那么从第2句话我们就知道她是Fifi的父母。又从第1句话我们知道她肯定比Fifi年长。逻辑推理就是基于这样的一些逻辑规则描述出来的知识,来帮助我们做这样的推理判断。机器学习呢,它走的是另外一个路线。我们会收集很多的数据,比方说把这个数据组织成这么一个表格形式,每一行就是一个对象或者事件,每一列是刻画它的一个属性或特征,这就是所谓的“属性-值“表示形式。如果从逻辑的角度来看,这种表示是非常基础的命题逻辑的表示方式,可以把属性值表对应成逻辑真值表。而命题逻辑和硬件逻辑中间是有非常大的差别,很重要的就是有对于“任意”以及“存在”这样的量词会发生作用。一阶逻辑表示由于涉及量词,比方说如果要把“任意”这个量词拆开把每个可能的X当做一个样本,那就会变成无限大的样本集。如果把一阶逻辑中的谓词比方说“parent”当作一个属性,那么你会发现,每个逻辑子句刻画的并不是某个样本,而是在刻画样本之间的某种关系。于是,当我们把谓词直接当做属性试图展开成普通数据集的时候,会发现数据集里甚至没有真正的属性-值的描述。虽然很困难,但大家都知道,如果能把两者结合起来,可能会有更大的威力,因此历史上已经有很多研究者在做努力。我们可以归结是大致两个方向的努力。一个方向主要是做逻辑推理方面的学者,尝试引入一些机器学习里面的基础的技术或者概念。这里面形成了一大类技术,有很多的做法。我们举一个最简单的例子,比方说刚刚给大家看到的几个子句,每个逻辑子句是确定的:要么成立,要么不成立。我们现在可以给每个逻辑子句加上一个权重,一定程度上我们可以认为它反映这个子句成立的概率。比如说:如果一个人是大学三年级,另一个人是大学一年级,那么第一个人很可能比第二个人年长,这个可能性是80%。通过加一个0.8,我们就使得这个事实变成一个概率的成立。这样得到的带有概率权重的子句,就可以进行一定程度的概率推理。另一个方向是从机器学习的角度,尝试把一些逻辑推理方面的东西引进来。比方说我们看到有这么一条子句,如果一个人他抽烟,那么他很有可能得癌症。有了这么一个知识,我们就可以在做贝叶斯网初始化的时候,把任何一个X,如果他smoke,我们就把它和cancer之间的这条边连起来,也就是说我们用这个初步的规则帮助我们做这个网络的初始化。初始化之后,原来贝叶斯网该怎么学就怎么学。

所以我们可以看上面这两大类做法。第一类,我们可以看到它是把机器学习往逻辑推理中引,但是后面主体还是通过推理来解决问题,所以我们称它是推理重而学习轻。第二种做法基本上是反过来,它把逻辑推理的技术往机器学习里面引,但是后期主要的解决问题是靠机器学习,所以我们称它是学习重而推理轻。总是一头重一头轻,这就意味着有一头的技术没有充分发挥威力。所以我们现在就想,能不能有一个新的机制帮助我们把这两大类技术的威力都充分地发挥起来呢?我们最近提出了一个新的方案,叫做Abductive Learning。要去理解Abductive learning之前,我们先来理解这个abductive是什么含义。

在人类对知识的处理上,或者说对现实问题的抽象上,我们通常有两种做法。一种是演绎,我们从一个一般性的原理出发,然后把一些特定的结果能够得出来,而且这个得出的过程是有保障的。比方说我们做定理证明,首先拿到一些数学公理,然后基于这些数学公理,把与它们一致的所有别的定理都证明出来。这就是一个“从一般到特殊”的过程,这是演绎。另一种做法是归纳,就是说我们先看到一些特定的事实,然后我们从特定的事实中总结出一般的规律。其实机器学习做的就是这么一件事。我们看到很多很多的数据,然后希望学习出反映一般规律的模型,这就是“从特殊到一般”。定理证明可以说是演绎的典型代表,而机器学习是归纳的典型代表。我们今天讲到的这个反绎,不太一样。Abductive这个词在逻辑里有时候翻译成诱导。但是在我们这个框架下,再把它翻译成诱导就不是特别合适,所以我们另译为反绎。反绎学习就大致是把演绎反向嵌入到机器学习归纳过程中去。反绎是什么意思呢?它是首先从一个不完备的观察出发,然后希望得到一个关于某一个我们特别关心的集合的最可能的解释。直接从这句话来理解可能有困难。那么下面我就先给大家看一个例子,是关于怎么去破译玛雅历法这么一个故事。大家知道中美洲有一个古老的玛雅文明。他们建立起了非常复杂、精致的历法系统,具体是有三套历法。
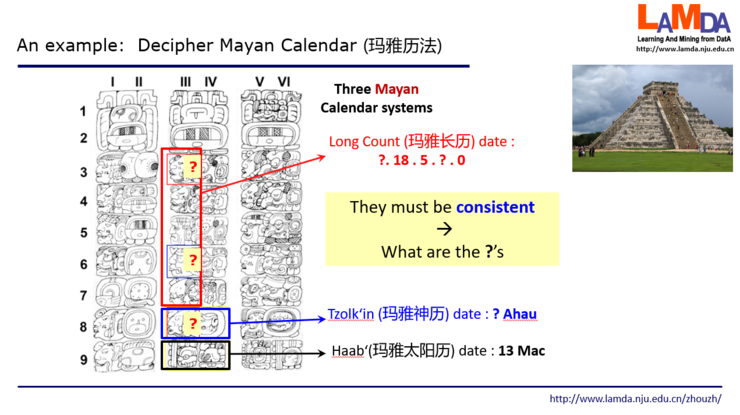
左边这三个石柱子上画出了很多的图案,每个图案它会表达一个含义。看中间红色方框中间的5个图像,考古学家知道是对应了玛雅的一个历法叫做长历。这是一组看起来像是IP地址的数字,它实际是不严格的20进制,描述了一个日期,就是玛雅文明认为从创世开始一共经过了多少天。这里面第1个和第4个是什么含义还不知道,所以打了问号,第2个图像对应于18,第3个对应于5,最后一个对应于0。接下来,蓝色框出来这两位,对应于玛雅的神历。左边这个图像是什么含义还不知道,打了问号;右边这个符号已经知道代表一个东西叫做Ahau。这两位结合起来也代表了一天。其实这两位一个是指月,一个是指日,有点像我们中国天干、地支的搭配,类似于在说“庚月子日”。但仅靠它肯定是不精确的,即便知道“庚月子日”也不知道具体是哪一天,因为历史上有很多的庚月子日,还需要要和别的信息结合起来。最后这两位是13 Mac,对应玛雅的太阳历,是说这一年第13个月第14天。但是,这是哪一年?仅凭它还不知道。但是如果这三个历法里的问号都清楚了,那么这一天的定位就非常精确了。现在需要把这三个问号破译出来。我们有一个重要的知识:这三个历法系统,由于它们指的是同一天,那么揭示出来的这三个问号的值一定会使这三个计数达到一致。那我们看看考古学家会怎么做这个事。拿到这个图像之后,他们首先根据以往破译图像的经验去“猜“ 这些数字是什么。但这很难,考古学家现在只知道这两个红色的应该是同一个数,蓝色的应该是另外一个数,但这个红色的既有可能是1,也有可能是8,也有可能是9。因为玛雅人刻石柱是手工而不是机器做的,每次都有变化。比方说大家看到最上面这个红色的图像,它好像和这个1最左边这个很像,和8的第二个也很像,跟9最右边的这个也比较像。
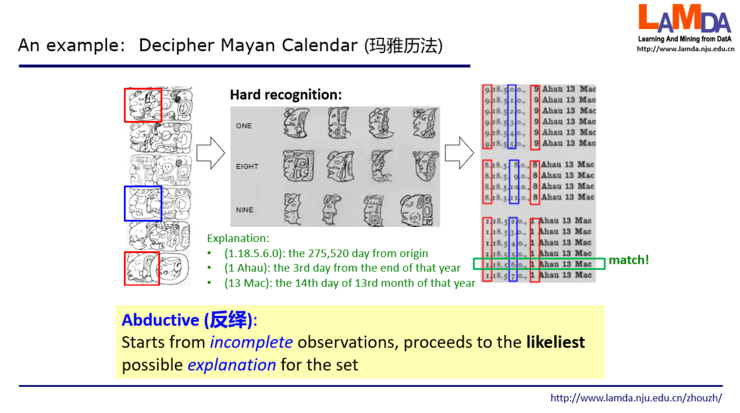
然后接下来考古学家做什么呢?他们把可能的情况全部展开。比方说如果我们认为红色的这个是1,那我们现在这个蓝色的就有几种可能,2 3 4 5 6 7这些可能都有,例如右边的最下面一行是1.18.5.7.0,这是从观察到的图像得出的猜测。也就是说从观测到的石柱,他们得出了这么几个可能的假设。接下来的一步,他们就要利用所掌握的知识来做判断。所掌握的知识是告诉我们现在这三个历法系统,它对应的日期应该是同一天。这里恰好找到红色是1、蓝色是6的这一行,对应的破译结果是长历的创世以来第275520天,恰好是神历中一年的倒数第三天,也恰好是太阳历中第13个月的第14天,一切都一致了!于是,这就得到了结果。我们回顾一下,首先它来自一个不完备的观察,有的图像是什么我们知道,有的图像是什么我们不知道。然后基于这个观察,我们得到一个假设。有了这个假设之后,根据我们的知识来找一个最可能的解释。而这个解释就是现在红色,蓝色这个我们当前所关心的集合。这就是反绎的含义。
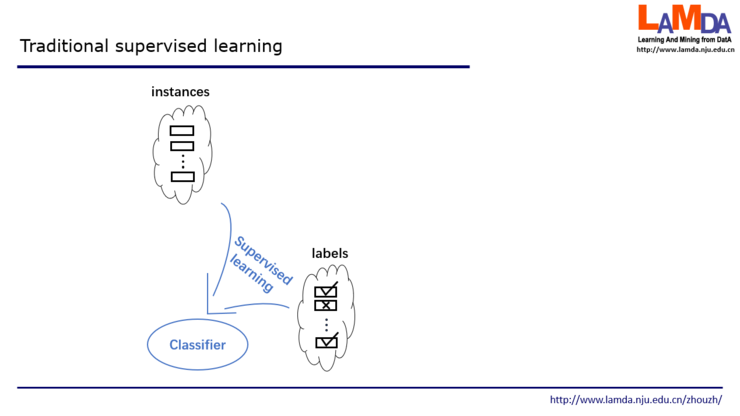
我们现在回头看一看现在的机器学习。首先我们要有很多instance,这是我们的样本。我们要有很多label,这是关于训练样本的已经知道的结果。我们把它合起来做监督学习,训练出一个分类器。反绎学习的设置不太一样。我们有一些样本,但只有样本的表现,不知道结果。这就类似于刚才在玛雅这个故事里面我们看到很多图像,但这个图像对应的含义是什么还不知道。反绎学习中假设有一个知识库,这就类似于刚才考古学家所拥有的关于历法的知识。同时我们还有一个初始分类器,这就好比说考古学家一开始看到这个图像,他会猜这个图像到底是什么?那么他凭什么猜呢?是他脑子里面有这么一个分类器。
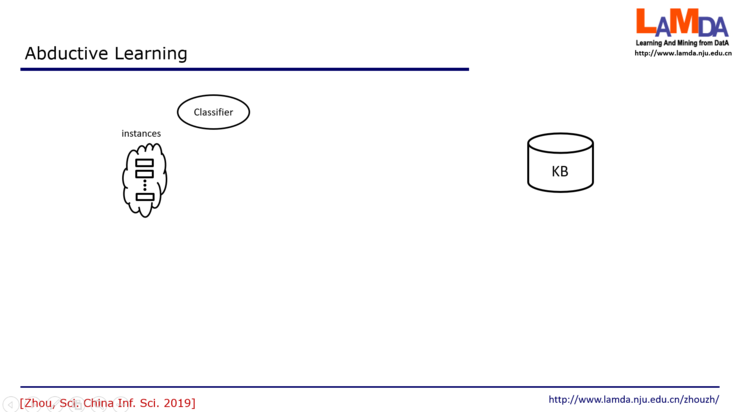
在这个学习中,我们先把所有的数据提供给这个初始分类器,这个初始分类器就会猜出一个结果,比方说红色的可能是1等等。然后得到这个结果之后,我们就会把它转化成一个知识推理系统它能够接受的符号表示。比如说从这些label里面,得到了A,非B,非C等等。那么接下来这一步,我们就要根据知识库里面的知识来发现有没有什么东西是不一致的?刚才在玛雅历法的故事里,第一轮就一致了,但在一般的任务中未必那么早就能发现一致的结果。如果有不一致,我们能不能找到某一个东西,一旦修改之后它就能变成一致?这就是我们要去找最小的不一致。假设我们现在找到,只要把这个非C改成C,那么你得到的事实就和知识都一致了。我们就把它改过来,这就是红色的这个部分。那这就是一个反绎的结果。而反绎出来的这个C,我们现在会回到原来的label中,把这个label把它改掉,接下来我们就用修改过的label和原来的数据一起来训练一个新分类器。这个过程可以不断地迭代下去。这个分类器可以代替掉老的分类器。这个过程一直到分类器不发生变化,或者我们得到的事实和知识库完全一致,这时候就停止了。
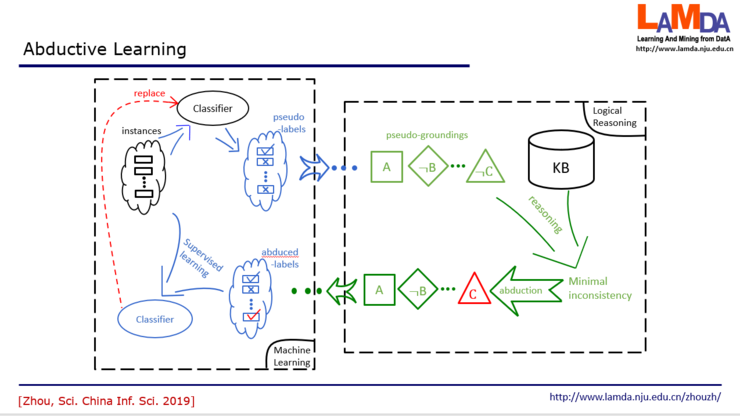
可以看到,左边这一半就是在做机器学习,而右边这一半是在做逻辑推理。而且,它不是说一头重一头轻,而是这两者互相依赖,一直这样循环处理下去,这么一个过程。反绎学习的形式化描述,我们今天就不展开了。有几点内容我们来讨论一下。首先我们看这个数据部分。在反绎学习中,这个数据只需要有instance,不需要有label。那么我们靠什么来做监督学习呢?主要就是靠初始分类器以及知识库中的知识。可以认为这个监督信息是来自于数据之外的地方,所以从这个角度上说,反绎学习可以看成是一个很广义的弱监督学习。但另一方面,如果初始数据中确实是有label的,那这个学习过程,label信息完全可以用上去。比方说,我们把真的label和反绎出来的label一起用来对分类器做更新等等。第二个方面,初始的分类器从哪来?这可以有很多的办法,比方说类似于深度学习的预训练或者迁移学习,做一个任务时可以用另外一个任务的结果做初步模型。甚至把数据聚类的结果作为粗糙的起点,有时也可以。这里的关键是,初始分类器未必要准确可靠,只不过用它把过程启动起来。当初始模型非常粗糙时,如果知识库的知识靠谱,那就能通过知识库的信息来修正分类器,能进行下去。如果知识不太精准,而初始模型比较好,也能往下学。如果两者都好,当然可以做得更好。也就是说,至少有一个好就能往下做。当然,如果数据没有label、初始分类器不靠谱、知识也不靠谱,那这样的任务本身就没法做。那接下来,这个知识库从哪来?这个目前还是需要人类专家来提供。最近一些关于知识图谱的工作能提供很多帮助。另外,有可能初始的知识并不是完美的,那么这个过程中,也可以通过对数据的学习来对知识做精化,所以反绎学习本身也可以认为是一个对知识精化的过程。接下来这个过程中涉及到怎么样具体地去做学习,去做推理等等,这些具体算法机制的设计。反绎学习本身是一个框架,对里面这些机制细节做不同的设计,可以产生出不同特点的反绎学习模型和算法。下面就介绍一个简单的例子,面对的这个任务是破译长代码。

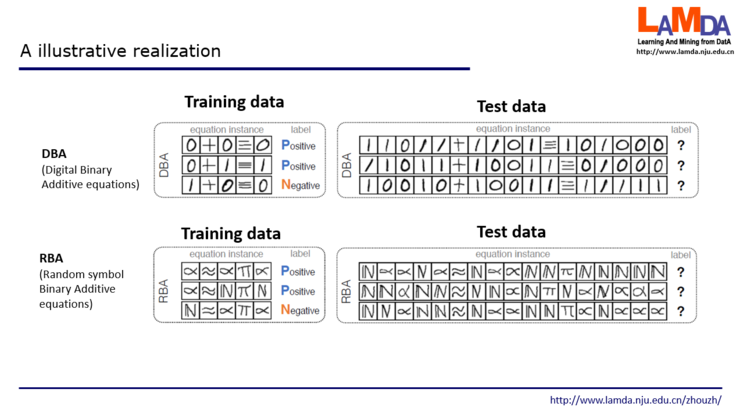
例如上面三行代码,这个代码是以图像形式呈现,比方说第一行是正例,第二行是反例,能不能判断第三行是正例还是反例?这里训练数据的长度和测试数据所用的长度不一样。而且,数据的语义是什么事先也不知道。这和破译密码有点像。现在考虑简单的XNOR问题。第一个是DBA任务,左边是训练数据,每个数据都是由5个图像组成,可以认为它是5位,0+0=0是正例,1+0=0是反例。我们对这5位图像组成的数据学习之后,测试数据是右边这样,长度要比训练数据长得多,而且有些数据特点也不同,例如训练数据中的等号总在倒数第二位,而测试数据中的等号可以出现在很不一样的位置。第二个RBA任务更困难,连图像的含义都看不出来,图像都是随机生成的。
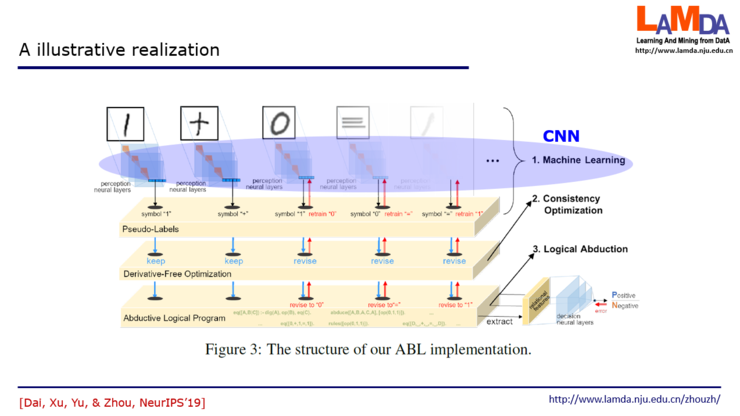
我们用了一个简单的实现。机器学习部分就是用卷积神经网络,逻辑推理部分用ALP,都有开源代码可以直接用。把两者衔接起来,中间的优化求解过程跟一般机器学习里不太一样,我们在神经网络、统计学习里的优化一般用到的是数值优化,通常用梯度下降来做,但现在是面对符号优化,不能求导、梯度下降。这里就用到我们研究团队近五六年一直在做的零阶优化方法,不用求梯度地做优化。把这几个技术结合起来,就是这个简单的实现。
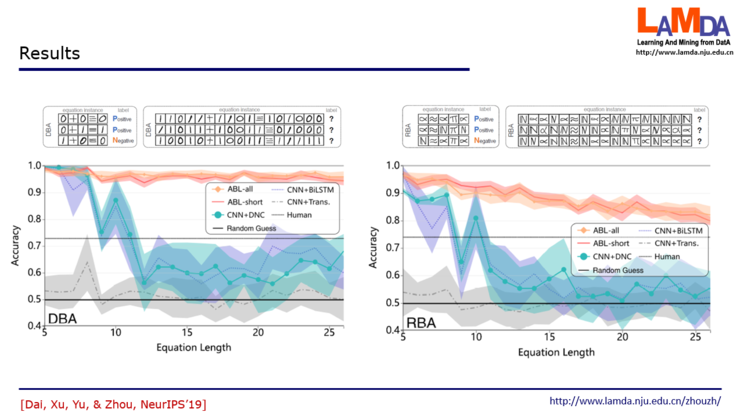
我们看看这个实验结果,图上蓝色和紫色分别对应基于卷积神经网络、 LSTM处理得到的结果。下面有一条横线对应的是随机猜测,上面一条横线对应的是人的水平。第一个图的DBA任务,我们可以看到,如果长度在12位以内,神经网络比人做得好。但是长度超过12位,人比这些神经网络要强。橙色部分是反绎学习的结果,通过把机器学习跟逻辑推理结合起来之后,在这个任务上比一般人做得好。右边的RBA任务情况类似,在这个更困难的任务上,随着串长度的增加,所有方法的性能都在下降,但是基于反绎学习的方法还是比人的水平高一些。实验里这个简单任务本身并不重要,重要的是显示出把机器学习和逻辑推理以”相对均衡”的反绎学习方式结合起来,虽然仅用了很简单的实现,就焕发出令人兴奋的能力。今后如果设计出更精致、巧妙的实现方式,可能会给我们带来更多惊喜。

大家感兴趣的话,上面第一篇文献是发表在中国科学上的文章,跳出细节来描述整个框架,很容易读。第二个是描述了刚才的这个具体实现。
最后做一个简单的小结和展望:我们现在经常在谈数据、算法和算力三要素,未来或许应该考虑进知识这个要素,知识凝聚了人类积累的智慧。过去十几年,我们都是从数据驱动的角度来研究人工智能,现在可能是时候把数据驱动和知识驱动结合起来了。我们的这个工作只是非常粗浅的初步探索,这里的研究空间很大,大家如果有兴趣,相信会在这方面做出更好的工作。谢谢!
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报

 下载APP
下载APP