
夺命故障!炸出了投资人!
来源 | 小姐姐味道(ID:xjjdog)
我听说,牛x的人,都关注整体,不关注细节,因为他们觉得没必要;我也听说,管理的哲学,就是协调资源,让人俯首甘为孺子牛,不达目的不罢休。
在这种环境下耳濡目染很多年,人生就有一股若有若无的错觉:管理可以解决一切问题。如果管理解决不了,那一定是流程的问题。
但看了PDD这种企业的管理方式以后,信仰再次转折,我又觉得这是错误的。PDD的管理模式,打脸了所有高校的《管理学》课程,让所有从事管理工作的人,颜面扫地。
只要钱给够,不需要什么管理!只有没钱的穷B公司才在哪里文邹邹的搞管理。要说高能的、正统的管理学,那非传销莫属。
话说的有点远,已经进入了跑题的路上,我们需要用一个故障把它拉回来。

1. 出故障了
没办法,干it这一行,就得天天面对故障,大家就是传说中的消防员,到处救火。不过,这次的故障范围有点大,宿主机都打不开了。
好在监控系统留下了一些证据。
证据发现,机器的CPU、内存、文件句柄,随着业务的增长,持续的上升...上升....,直到监控也无法将信息收集上来。
要命的是,这些宿主机上,部署了非常多的Java进程。没别的原因,就是为了节省成本,混部了应用。当宿主机表现出整体性的异常时,就难以找到罪魁祸首。
因为远程登录也Over,暴躁的运维只能重启机器,重启机器之后开始重启应用。经过漫长的等待,所有的进程都活了,但是,仅仅过了片刻,宿主机又立即死去。
业务一直处于死翘翘的状态,真是让人恼火啊。也让人心急。尝试过几次之后,运维崩溃了,启动了紧急预案:回滚!
最近的上线记录有点多,而且有开发人员私自上线部署的行为,运维蒙圈了:回滚哪些呢?还好有人脑瓜一亮,想起了还有find这个命令,那就找到最近更新的所有jar包,都给它来次回滚吧。
find /apps/deploy -mtime +3 | grep jar$
如果你不知道find这个命令,那可还真的是一场灾难。还好有人知道。
把十来个jar包回滚,还好没有碰到数据库的schema变更,系统终于正常运行了。

2. 找原因
没别的办法,查日志,进行代码审查。
代码审查要追溯到最近1周或者2周之内的代码改动,因为有些功能代码要沉淀一段时间,才能到线上风光一把。
看着满屏的提交记录“OK”,技术经理的脸都绿了。
“xjjdog说过,《80%的程序员,不会写commit记录》,我看你们是100%都不会写”。
大家都静悄悄的,忍着痛翻查历史变更。经过大家的不懈努力,终于在屎山之间,找到了一些问题代码。CxO亲自建了个群,大家一股脑的把可能会出问题的代码,扔到了群里面。
"系统服务中断了接近一个小时,影响非常恶劣",CxO说,“务必把问题彻底解决掉,这个问题投资人非常关注”!
okokok,有了钉钉的助力,大家的手势都变得整齐划一。
3. 线程池的参数
代码有点多,大家对问题代码讨论了老久。包括一些使用并行流的,还有套在lamba表达式里的炫技代码,还重点排查了一些线程池的使用代码。
最后大家决定还是对线程池的代码再过一遍。其中有一段是这么写的。
RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardOldestPolicy();
ThreadPoolExecutor executor = new ThreadPoolExecutor(100,200,
60000,
TimeUnit.MILLISECONDS,
new LinkedBlockingDeque<>(10),
handler);
还别说,参数有模有样的,甚至考虑到了拒绝策略。
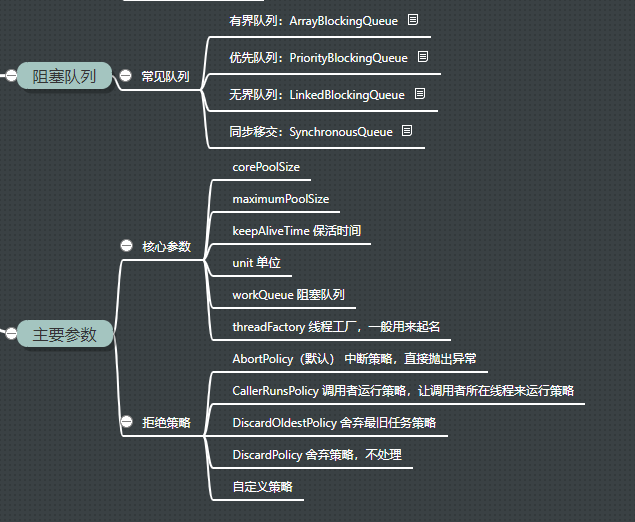
Java的线程池,使得编程变的非常简单。它有很多参数,如上图,我们一一介绍一下,否则代码是无法审查的。
corePoolSize:核心线程数,核心线程创建后会一直存活 maxPoolSize:最大线程数 keepAliveTime:线程空闲时间 workQueue:阻塞队列 threadFactory:线程创建工厂 handler:拒绝策略
下面来介绍一下它们的关系。
当线程数小于核心线程数的时候,有新的任务到来,将会生成一个新的线程进行服务。当当前线程数大于核心线程数,而且阻塞队列未满的时候,将会把任务放在阻塞队列中。当线程数大于核心线程数,而且阻塞队列满了的时候,将会创建新的线程进行服务,直到线程数到达maximumPoolSize的大小。此时,如果还有新的任务,将触发拒绝策略。
再说一下拒绝策略。jdk默认实现了4种策略,默认实现的是AbortPolicy,也就是直接抛出异常。下面介绍其他几种。
DiscardPolicy比abort更加激进,直接丢掉任务,连异常信息都没有CallerRunsPolicy由调用的线程来处理这个任务。比如一个web应用中,线程池资源占满后,新进的任务将会在tomcat线程中运行。这种方式能够延缓部分任务的执行压力,但在更多情况下,会直接阻塞主线程的运行DiscardOldestPolicy丢弃队列最前面的任务,然后重新尝试执行任务
这段线程池的代码是新加的,参数设置还算正常,并没有什么大的问题。唯一有可能的风险,就是使用DiscardOldestPolicy 的拒绝策略。当任务非常多的时候,这个拒绝策略会造成任务排队,请求超时。
当然不能放过这种风险,说实话也是到现在为之能够找到的最可能的风险代码了。
"把DiscardOldestPolicy 改成默认的AbortPolicy吧,重新打包上线一下试试“。技术大牛在群里说。
4. 问题在哪里?
结果,服务灰度上线之后,宿主机不多时,就死掉了。是它的原因没跑了,但是why?
线程池的大小 ,最小100,最大200,说什么也不过分。阻塞队列的容量只有10,说什么也不会造成问题。你要说是这个线程池造成的原因,打死我都不信。
但是业务部门反馈,这段代码加上就死,不加就没事。技术大牛们抓耳挠腮百思不得其姐。
到最后,终于有人忍不住了,下载下业务的代码打算调试一下。
当他打开Idea的时候,瞬间懵逼了,又瞬间领悟了。他终于明白了这段代码为什么会产生问题了。
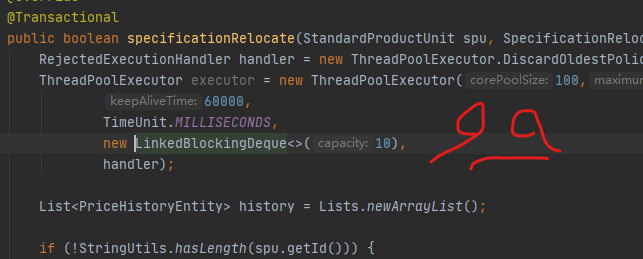
线程池,竟然是在方法里创建的!
当每一个请求到来的时候,它都会创建一个线程池,直到系统再也无法分配资源为止。
可真是霸道啊。
所有人都在关注线程池的参数是怎么设置的,但从来没有人怀疑这段代码所在的位置。
5. 结尾
问题低级又常见,现在我严重怀疑拒绝策略也是网上拷贝的代码。
那么多码农,熬夜选择了个业务低峰期进行上线,还是躲不过命啊,躲不过猪队友的伤害。
当然,这还说明了另外一个问题:技术能力跟不上,再牛的管理也爱莫能助。
最后,连投资人都施压的故障,几乎没有人愿意去实际的翻一下业务的代码看看。这得多大的屎山,才让人这样避而远之,生怕把自己的羽毛染臭啊!
往 期 推 荐 1、全网最全 Java 日志框架适配方案!还有谁不会? 2、Chrome浏览器最新高危漏洞曝光!升级最新版也没用~ 3、Spring中毒太深,离开Spring我居然连最基本的接口都不会写了 4、黑客用GitHub服务器挖矿,三天跑了3万个任务,代码惊现中文 5、惊呆了,Spring Boot居然这么耗内存!你知道吗? 6、Gradle真能干掉Maven?今天体验了一把,贼爽! 7、如何重构千行“又臭又长”的类?IntelliJ IDEA 几分钟就搞定! 点分享
点收藏
点点赞
点在看




