
消息队列之九问九答
问题1 为什么要用消息队列呀?
答:如下图所示,外呼系统需要将外呼结果发送给业务系统,如果采用rpc的调用方式; 则带来的后果,
则带来的后果,
首先,1、外呼系统与业务系统严重耦合,多个业务系统需要外呼系统传输数据,如果有接口调用的方式,那无论是接入新的业务还是撤掉业务,都需要改动代码;
2、如果业务系统挂掉/访问超时,要保证不能影响其他业务系统;所以:需要利用消息队列解耦,这样做的好处:外呼系统和业务系统解耦,业务系统有需要,消费mq即可
外呼系统也无需关注业务系统的消费情况啦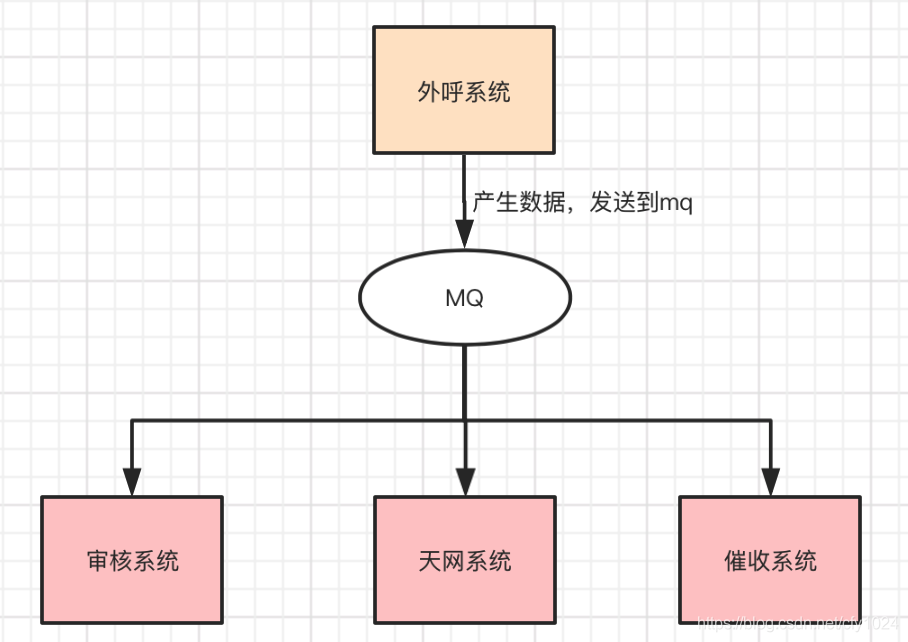 其次,如果采用rpc调用方式(同步),则总体耗时 = 在外呼系统的耗时 + 在审核系统的耗时 + 在天网的耗时。。总体耗时过长,
其次,如果采用rpc调用方式(同步),则总体耗时 = 在外呼系统的耗时 + 在审核系统的耗时 + 在天网的耗时。。总体耗时过长,
使用mq异步化之后,性能优化啦,总耗时 = 外呼系统的耗时 + 发送mq的耗时。
再次,如果不用mq,高峰期的时候,大量请求打入系统,万一系统的处理逻辑涉及到数据库,那么很容易挂掉,高峰期一过,系统压力又大大减小。<小知识,一般的mysql,一般能扛到每秒2000个请求>
所以使用mq削峰,系统慢慢从mq中拉取数据作处理,保证高峰期系统也不会挂掉,虽然有可能堆积消息,但是高峰期一过,请求就会被快速处理掉的。
问题2 消息队列的优点和缺点?
优点:如1所说,可以解耦、低耗时、削峰
缺点:
(1)、系统的可用性降低,mq一旦挂掉,提供者没办法发送消息了,消费者也无法接收到数据了
(2)、系统的复杂性提高,引入了mq,就要考虑消息重复、消息幂等、消息丢失、消息延迟、消息堆积、消息顺序错乱等问题
(3)、系统的一致性问题,如果消费失败,那么有可能导致提供者与消费者状态不一致的问题
问题3 消息队列都有哪些类型,分别有什么优缺点呀?
(1)、常见的消息队列有 kafaka、activemq、rabbitmq、rocketmq
(2)、消息队列的比较
| 特性 | activemq | rabbitmq | rocketmq | kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级 | 万级 | 10万级 支撑高吞吐量 | 10万级 大数据类,实时数据计算,日志采集 |
| topic数量对吞吐量的影响 | topic达到几百几千时,吞吐量会稍微的下降 | topic达到几百几千时,吞吐量会稍微的下降 | ||
| 时效性 | ms | 微妙 | ms | ms |
| 可用性 | 高 主从架构 | 高 主从架构 | 分布式架构 | 非常高,分布式架构,多个副本,少数机器宕机,数据不会丢失 |
| 消息可靠性 | 有较低的概率会丢数据 | 配置参数,可达到0丢失 | 配置参数,可达到0丢失 | |
| 功能支持 | mq领域的功能完备 | erlang开发,并发能力好,性能好,耗时低 | 功能完备,分布式,扩展性好 | 功能简单,大数据领域采用较多 |
| 总结 | 小规模吞吐量,非常成熟,功能强大,在业内大量公司及项目中应用,偶尔会丢数据,但官方维护较少,主要可以基于解耦和异步,不太实用高吞吐量的大规规模场景 | erlang开发,并发能力好,性能好,耗时低,开源提供管理界面,中小型企业可选,社区活跃,缺点是erlang源码不好懂,掌控力较弱,集群动态扩展麻烦 | 接口简单易用,阿里开源,品质有保障,性能好,分布式扩展方便,只是大规模topic,java代码源码可读,但是万一项目被阿里抛弃,需要自己维护 | 功能较少,吞吐量较高,易扩展,适合大数据实时计算和日志采集 |
问题4 如何保证消息队列的高可用呀?
(1)rabbitmq 非分布式
a、单机模式,只有一台机器。b、普通集群模式
rabbitmq 有三台机器,只有一台机器存了元数据和所有数据,如果有消费者需要消费数据,访问了a或c,那么a或c就会根据其元数据路由到b机器上。优点:可随便路由到某台机器,皆可访问;缺点:集群内部产生大量的数据传输,且万一某一个挂掉,则无法找回数据。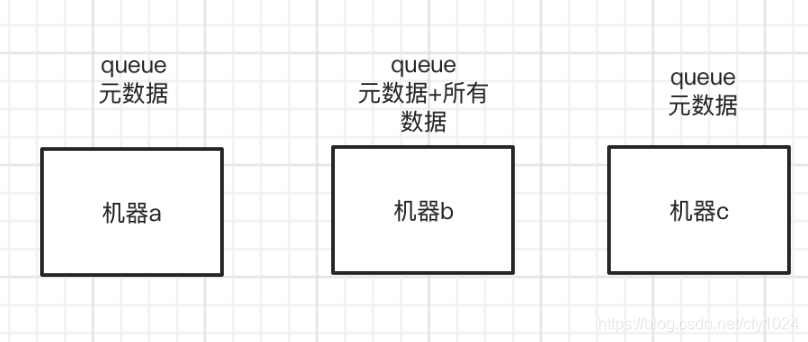 c、镜像集群模式
c、镜像集群模式
在管理控制台新增一个策略,制定所有节点同步数据创建queue的时候,都选择该策略。每个rabbitmq节点上都有queue 元数据 和 所有数据。这样,生产者往queue里写数据,rabbitmq就会自动同步到其他节点上去,每个节点都有queue的完整镜像,消费者可从任一一个节点去消费,如果出现宕机,可以从其他节点去获取数据
(2)rocketmq 分布式
采用 多master多slave模式 同步双写模式
(3)kafka:纯分布式架构的mq。每个topic分为不同的partion,放在不同的机器上,所以每一台机器上都有部分topic数据,每个partion只会被一个消费者消费。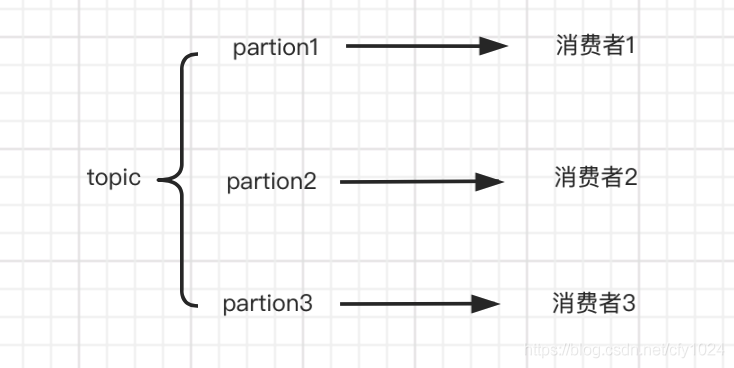 高可用保证:replica 副本机制 每份数据都会有多个副本,会选举一个为leader,其他为follow,对于同一个topic下的partion,只有leader才可以提供读写。如果leader宕机,kafka会感知到,那么会重新选举新的follow为leader。
高可用保证:replica 副本机制 每份数据都会有多个副本,会选举一个为leader,其他为follow,对于同一个topic下的partion,只有leader才可以提供读写。如果leader宕机,kafka会感知到,那么会重新选举新的follow为leader。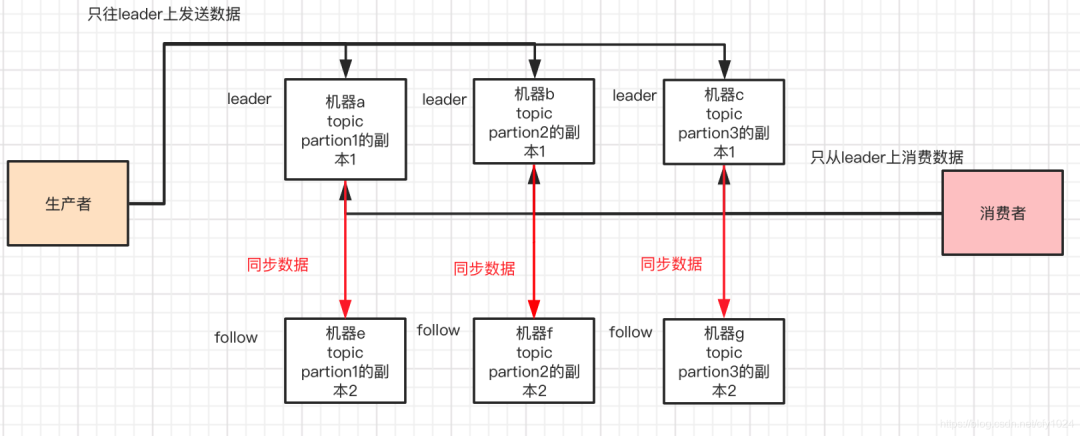
问题5 如何保证消息队列的幂等性?
幂等性:同样的数据只消费一次。为什么会发生消息重复消费的情况?如Kafka,如果在消费者准备提交的时候,被重启了,那么kafka是不知道消费者准确的消费到了哪条数据,就有可能会出现重复消费。总之,就是如果mq和消费者的信息不对等了,就会出现这个问题咯。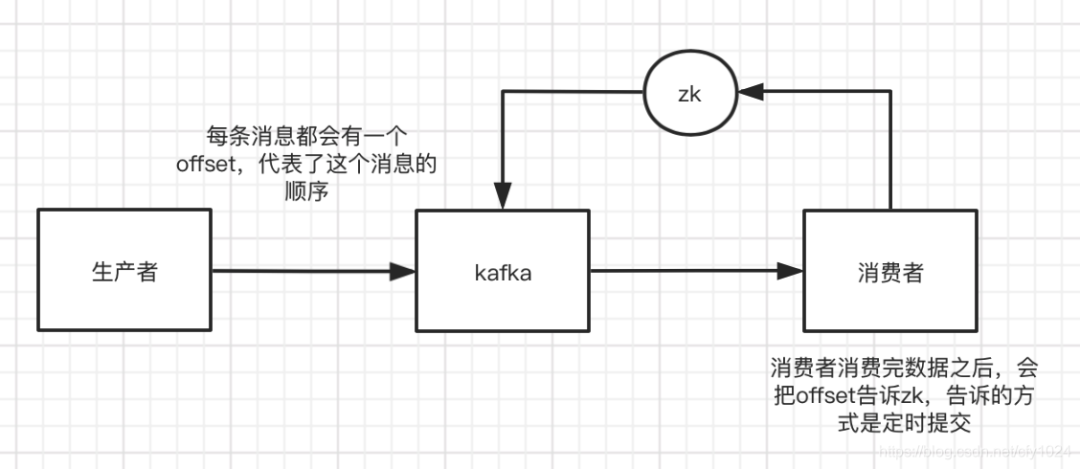 那么,如何解决呢?1、如果是库表类的操作,用业务主键来去重;2、或者可以利用redis、内存等,用一个卫衣标识来保证消息的幂等性。例如:外呼系统中,业务系统拿到结果要落库表,可以用callid作为幂等性的保证。
那么,如何解决呢?1、如果是库表类的操作,用业务主键来去重;2、或者可以利用redis、内存等,用一个卫衣标识来保证消息的幂等性。例如:外呼系统中,业务系统拿到结果要落库表,可以用callid作为幂等性的保证。
问题6 如何保证消息的可靠传输?
1、rabbitmq
生产者->rabbitmq->消费者
可能会丢消息的情况:a、消息因为网络传输等原因没到mq就丢了。b、mq内部出错了,没保存下来。c、mq保存下来了,还没消费呢,mq挂了,被丢了。d、消费者消费到了数据,还没来得及处理,挂掉了,但是mq以为消费完了。如何解决呢?a的解决方案1:rabbitmq支持事物,生产者发消息之前开启一个事务,如果收到异常,就证明没发送成功,那么可以回滚,再重试发送;缺点是同步机制,需要等结果,比较耗时。a的解决方案2:开启confirm模式,生产者提供回调接口,mq接收到了消息去回调该接口通知接收是否成功。b和c的解决方案:把消息持久化到磁盘上。queue设置成持久化,消息的delivery mode 设置成2
d的解决方案:关闭消费者的autoack,不再自动告诉mq,OK了,而是等处理完了再告诉。
2、kafka
生产者->kafka->消费者
a、消费端弄丢数据,kafka自动提交offset,让kafka以为消费完了。解决方案,放弃自动提交,处理完之后再提交。b、kafka本身丢数据。设置四个参数。topic 的 replication factor > 1 ,每个partion至少有2个副本
min.insync.replicas >1 , 要求每一个leader至少有一个follow跟他保持联系
produce ack=all 每条数据必须写入到副本之后,才算写成功
retires = max(很大的值),如果写入失败,就进入无限重试,保证leader和follow切换时,不会丢失数据。
一般的开发过程,只要接入了mq,都会写一个补单脚本做对账。
问题7 如何保证消息的顺序性?
1、rabbitmq
为何会消息错乱呢?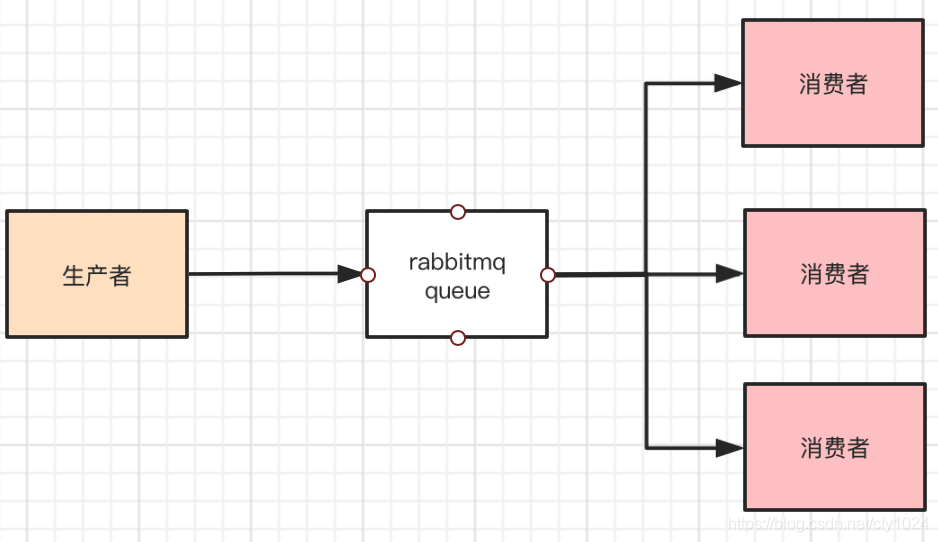 一个queue的数据被多个消费者消费,这时候就有可能会出现顺序错乱的情况。解决方案,多创造几个queue,把需要保证顺序的数据放在一个queue里,每一个queue只有一个消费者。2、kafka
一个queue的数据被多个消费者消费,这时候就有可能会出现顺序错乱的情况。解决方案,多创造几个queue,把需要保证顺序的数据放在一个queue里,每一个queue只有一个消费者。2、kafka kafka的partion只能有一个消费者,但是如果消费者内部是多线程并发处理的,那么是可能会出现顺序错乱的问题。
kafka的partion只能有一个消费者,但是如果消费者内部是多线程并发处理的,那么是可能会出现顺序错乱的问题。
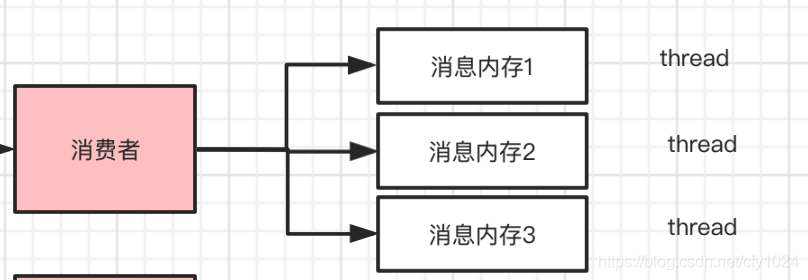 把需要保证顺序的数据放在内存队列里,然后每个线程处理一个队列,这样就可以保证顺序执行啦。
把需要保证顺序的数据放在内存队列里,然后每个线程处理一个队列,这样就可以保证顺序执行啦。
问题8 如何解决消息队列的延时以及过期失效问题呀?
快速扩容呀。具体的方案可参考:(1)、新建一个topic,创建10倍的partion,
(2)、消费者消费到数据之后,啥都不干,就只往新的topic里写数据,
(3)、申请partion数量的机器,去处理里面的数据。
如果大量积压,又无法立刻解决的话,就开启丢消息的模式,后续低峰期的时候,把数据补偿回来。
问题9 如何设计消息队列中间件?
1、可伸缩性,支持快速扩容,增加吞吐量和容量。可参考kafka的设计方案 broker -> topic -> partion,如果需要扩容,增加partion和机器即可。
2、落磁盘,防止数据丢失。
3、可用性,leader和follow的模式
4、保证数据的0丢失。可结合灵魂拷问1-8回答。
原文链接:https://blog.csdn.net/cfy1024/article/details/105753042
1.微服务实战系列
4.中间件等
更多信息请关注公众号:「软件老王」,关注不迷路,软件老王和他的IT朋友们,分享一些他们的技术见解和生活故事。