
拯救pandas计划(16)——将DataFrame的奇偶列位置进行前后对调
拯救pandas计划(16)——将DataFrame的奇偶列位置进行前后对调
最近发现周围的很多小伙伴们都不太乐意使用pandas,转而投向其他的数据操作库,身为一个数据工作者,基本上是张口pandas,闭口pandas了,故而写下此系列以让更多的小伙伴们爱上pandas。
系列文章说明:
系列名(系列文章序号)——此次系列文章具体解决的需求
平台:
windows 10 python 3.8 pandas >=1.2.4
/ 数据需求
首先非常感谢【瑜亮老师】在交流群里给出的问题,有了写下这一篇的灵感。
【瑜亮老师】在群里给出的问题是:把df的奇数列与偶数列调换位置。比如A列,B列,调换成B列,A列…… 其中的数据列是偶数个,在操作方面会稍微简单点,这里做一个拓展,使用奇数个的列进行操作。原始数据如下:
ps: 提到奇偶列为自然数从1开始计数,如A列位置为奇数列
import pandas as pd
en = 'abcdefg'
df = pd.DataFrame(([i + j for j in en] for i in en), columns=list(en.upper()), index=list(en.upper()))

目标样式:

可以进行奇偶匹配的相邻两列发生了位置变换,而最后一列G无法与其后的数据匹配则无需交换,仍然处于最后位置。
/ 需求拆解
在文章开始就有说到,列数量为偶数比奇数容易处理,所以可以先将数据看做列数量为偶数个进行处理。将数据降低为偶数个列的数据框。
/ 需求处理
偶数个列的数据框
import pandas as pd
en = 'abcdef'
df = pd.DataFrame(([i + j for j in en] for i in en), columns=list(en.upper()), index=list(en.upper()))

比问题中提到的数据框少了一列G,因为是奇偶列且相邻的两列进行对调,可以使用numpy将提取出来的奇数列和偶数列组成2*n的二维数组,再以列方向摊平成一维数组,方法如下。
import numpy as np
odd_c = df.columns[::2] # 获取奇数列
even_c = df.columns[1::2] # 获取偶数列
# 生成2*n的数组再从列方向摊平成一维数组,注意:偶数列在上方
new_c = np.array((even_c, odd_c)).flatten('F')
print(df[new_c])

df.columns自身的values对象就是np.array类型的,可以直接通过自身的转换一步步达到目的。
先将df.columns进行重新排序,原来是一维数组改成二维数组,改变过程中,以列方向进行排序,即:
new_c = df.columns.values.reshape((2, len(df.columns) // 2), order='F')
与上一方法不同的是,奇数位置列处于上方,此时将上下位置调换就可以再使用flatten方法将数组摊平,并达到奇偶列位置调换的目的。
df[new_c[::-1].flatten('F')]
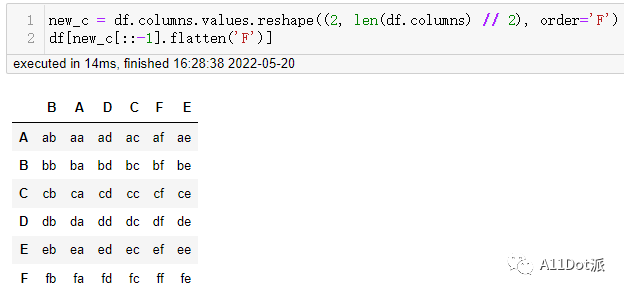
上述两种都是将列名提取重新构造形状再转为一维数组形式,完成奇偶列的位置调换。
还可以运用-1的n次方的性质,如果为奇数,则使用它前一个列,如果为偶数就是用当前列的后一列,例如,[0,1] --> [1,0],在这里就很简单的完成了交换。
new_c = [df.columns[i + (-1) ** i] for i in range(len(df.columns))]
# ['B', 'A', 'D', 'C', 'F', 'E']
df[new_c]
此处的i为各个列名所在的索引位置,A列的索引为0,通过 0 + (-1) ** 0的算数运算得到1,即为B列的索引。而遍历到i=1时,通过计算为1 + (-1) ** 1 = 0,B列处就返回了A列的索引。
奇数个列的数据框
以上使用了简单的方法将偶数个列的数据框中的奇偶列位置完成的对调。
显然,要将奇数个列名重新构造成一个2*n的数组是不行的,且得知最后一列无需跟任何一列进行位置交换,可以将最后一个列名单独拿出,让剩下的组成2*n的数组。
import numpy as np
c = df.columns.values
# 分离最后一个列名
c_ = c[:-1]
c_last = c[-1]
# 方法同偶数个列数据框
c_new_even = c_.reshape((2, len(c_) // 2), order='F')[::-1].flatten('F')
# 将最后一个列名拼接到最后
new_c = np.hstack([c_new_even, c_last])
然而通用性就差了一点,不能将偶数个列的数据框进行转换,可以试下下面这个方式:
import numpy as np
c = df.columns.values
# 获取另一个维度值
c_middle = len(c) // 2
# 获取列中的最后一个列名,如果为偶数列则返回空列表
c_last = [c[-1]] * (0 + len(c) % 2)
# 重构形状,拼接最后一个列名
new_c = np.hstack((c[:c_middle * 2].reshape((2, c_middle), order='F')[::-1].flatten('F'), c_last))
这个就可以即对偶数个列进行操作又能对奇数个列进行操作,两个不同点在于,下面这种动态获取最后一个元素,如果列数量是偶数个,则返回空列表。
在使用(-1)的n次方时处理奇数个列也是会遇到无法将奇偶数位置进行交换。
[i + (-1) ** i for i in range(len(df.columns))]
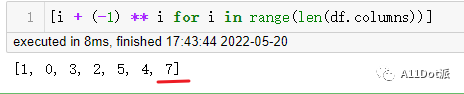
数据列名为A-G,对应的索引为0-6(包括6),使用该方法生成的7是不能从列名中提取的。此时可以使用数据修剪函数,将大于最大索引的数据修正为最大索引。
import numpy as np
np.clip([i + (-1) ** i for i in range(len(df.columns))], 0, len(df.columns) - 1)

生成的索引为该数据中最大的索引值,且此之前的列均发生了奇偶列位置对换。
/ 总结
本例中使用简单的解决方法,通过使用列名的索引查找,numpy数组的形状的灵活变换,数组的数据修剪,数字-1的次方性质等方法,非常简便的将数据框的奇偶列位置进行顺序改变,对此例产生发散思维,多角度解决数据需求,仍有考虑不足之处,烦请各位看官谅解。
绿叶新枝芽初开,望等闲。
于二零二二年五月二十日作