
元宇宙:在你眼中是游戏,科学家眼里是人和 AI 的「无限战场」

作者 | 陈彩娴
编辑 | 岑峰
当下大热的元宇宙的故事,大概可以追溯到六七年前:Facebook在2014年收购的Oculus,今天已成为了Facebook“转型元宇宙公司”不可或缺的重要部分;“元宇宙”第一股Roblox,也是在2015年开始突然开了窍,进入了高速增长期;而构建元宇宙的另一基石人工智能,也在2015年迎来了拐点。
这一年,位于英国伦敦的一家小公司 DeepMind 在《Nature》上发表了一篇文章“Human-level control through deep reinforcement learning”,提出了一种新算法叫 Deep Q-Network(简称“DQN”)的深入学习算法,应用在 Atari 2600 游戏时,在49个游戏水平中超过了人类。
但那时人们还不知道这究竟意味着什么,直到第二年,这家公司将DQN应用在 Alpha Go 上,让 Alpha Go 与世界围棋冠军李世石对战,以 4:1 的成绩打败李世石。接着,深度强化学习又被应用于德州扑克、星际争霸、王者荣耀等游戏中,不断挑战人类玩家,甚至以高超的水平多次蒙混过关,当起“职业冒充”排位赛选手,且没有被人类发现…
然而,当深度强化学习在虚拟世界混得风生水起时,它在现实世界的存在感却几乎为零。
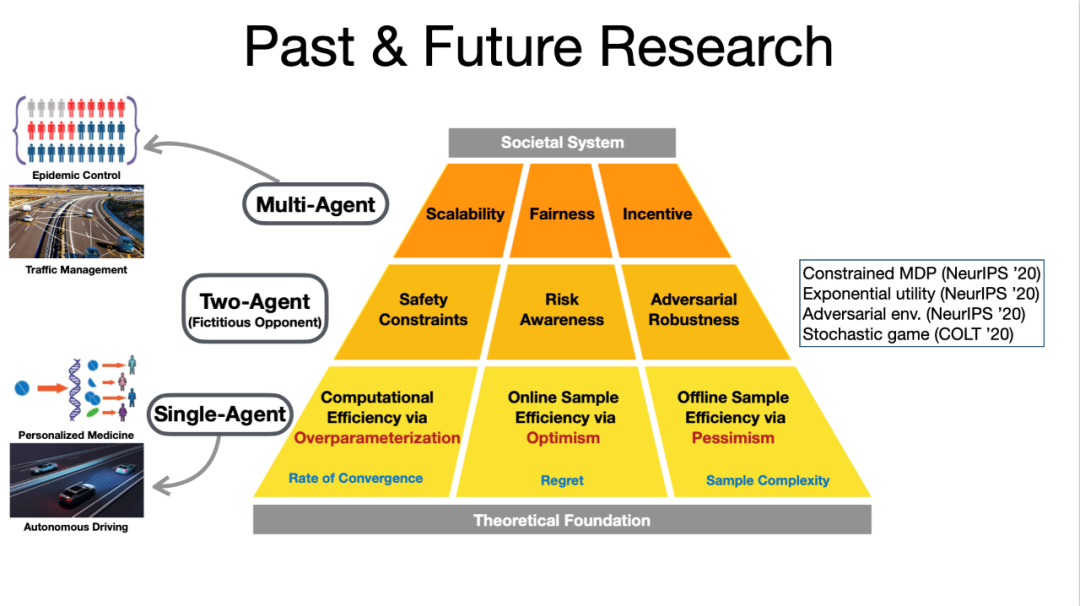
在汪昭然看来,这与深度强化学习当前的两大缺陷有关:一是样本效率与计算效率低;二是缺乏可信度,算法的安全性与鲁棒性低。要将深度强化学习从虚拟世界转到现实世界,一要建立理论框架,二要提高样本效率与计算效率。
汪昭然目前在美国西北大学任教,是工业工程及管理科学系(在运筹科学领域排名美国和世界前三)和计算机科学系的终身轨助理教授,同时隶属于该校的深度学习中心和优化及统计学习中心。
他的长期研究目标是开发出新一代数据驱动的决策智能,推进深度强化学习在现实世界中的落地。
1
元宇宙
1
元宇宙


机器人用到的经典力学模拟器与Roblox的模拟碰撞是完全类似的,只是两者的实现不同,侧重点也不同,但原理是相通的。再比如,策略类的游戏就相当于运筹领域中的最优策略研究,供应链优化或者动态定价与在星际争霸里造基地,在数学上是完全相通的。
2
理论基础

我们如何理解深度强化学习的两大问题?
首先是低效率:汪昭然介绍,深度强化学习要在现实世界中取得成功,需要数百万、甚至数十亿的数据点。这些数据点通过在给定先验下与特定的模拟器(比如《星际争霸》中的游戏引擎)交互而获得,过程需要数天或数周时间,即使在大规模并行计算机架构上也是如此。由此可见,深度强化学习的样本效率与计算效率是非常低的。
其次,仅仅基于奖励(如Atari的总分)来衡量深度强化学习的成功,这种理论在现实世界中是非常危险的。比如,在医疗领域,要获得更高的奖励,意味着疾病的程度恢复更好,风险是服用过量的药剂;在交通领域,更高的奖励等同于更快到达目的地,风险可能是要超速行驶,这就没有考虑到人类的生命安全。
当深度强化学习技术被应用于社会系统的设计与优化时,缺乏效率和可信度将为落地带来更大的阻碍。一个混合自治的社会系统通常涉及到大量智能体,包括人类(只能通过激励来驱动)和机器(可以直接控制)。例如,优步、Lyft 和滴滴等拼车平台不仅涉及到人类司机,还包括了自动驾驶汽车;电力网络不仅包括人类消费者,还包括自动发电机。
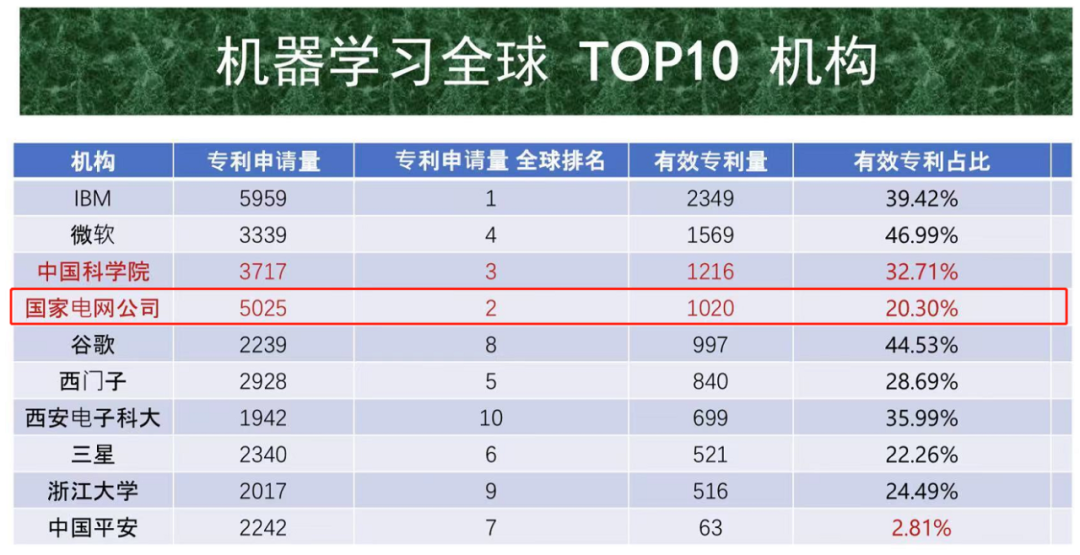
(此处插叙一个“冷知识”:国家电网是隐形的人工智能巨无霸)
用深度强化学习控制大量机器时,比如协调电网中的发电机,样本效率与计算效率的阻碍会变得更加明显,因为当大量智能体同时存在时,联合状态行为空间的容量会呈现指数级增长,也就是所谓的“多智能体诅咒”(“curse of many agents”)。如果不考虑安全性和鲁棒性,那么深度强化学习在现实生活中的落地也许会带来灾难性的影响。
“不用那么多的计算量与样本量,能不能使算法达到出色的性能?”这是汪昭然的研究核心。他解释:
深度强化学习与深度学习不一样的地方在于:深度学习在许多模型上的性能已经很好,大家更多时候是想解释为什么性能这么好;而深度强化学习的一些算法在实际使用中的性能并不好,鲁棒性比较差,只要换一个系统、换一个环境,表现可能就会下降。
所以,他们的思路是用理论来指导算法的设计,在算法应用到新的环境前就能知道算法的性能是好是坏。汪昭然认为,完善的理论框架对算法性能的衡量是必要的:
我们不能说一个算法在某个数据集上的表现好,就说这个算法好。在一些特定的应用下,比如医疗与金融,这是很危险的,可能会有生命危险或金钱损失的风险,所以我们必须要有一个理论框架,根据框架下的细节来分析这个算法。在设计算法时,不仅要可解释,我们还要知道这个算法在什么情况下表现好、最好能到多好。
在这个思路下,他们确实设计出了性能比较好的算法,比如在深度强化学习中加入乐观探索(optimistic exploration)和悲观正则(pessimistic regularization),能在一系列基准测试上打败现有最好算法。
建立深度增强学习的理论框架,让深度增强学习在计算复杂度上和样本复杂度层面更有效率。在理论的指导下,提出一系列安全性、可靠性、数据消耗量都有保障的算法,以帮助深度增强学习落地医疗与金融领域。
拓展深度增强学习的算法框架,设计和优化社会规模的多智能体系统(比如供应链与拼车系统)。在理论的指导下,提出一系列基于动态博弈论的多智能体深度增强学习算法,以帮助深度增强学习落地这些大规模社会系统。
3
成就
其实离线情况在现实中更常见。比如医疗,如果病人一般服用的是有效药剂A,医生就不会贸然尝试给病人服用药剂B,不可能冒险拿病人的生命去试验;比如交通,如果你下班时常走一条不怎么堵车的路线回家,你就不会突发奇想去试新的路线,因为可能有堵车的风险
传统的乐观理论忽略了这一点,因为游戏属于在线学习情况,有很多模拟器,可以不断去试,但在现实生活中,有很多情况是试不起的,会付出很大的代价。
在 ICML 2021 上,汪昭然团队便针对“离线学习时应该使用什么样的算法框架”,发表了一篇工作,叫“Is Pessimism Provably Efficient for Offline RL?”。针对离线学习缺少数据的情况,这篇文章提出了“值迭代算法的悲观变量”(PEVI),包含一个不确定性量词作为惩罚函数。
他们假定覆盖到的数据集有限,为一般的马尔可夫决策过程 (MDP) 建立了 PEVI 次优性的数据依赖上限。结果证明,当 PEVI 用于线性MDP时,在维度与范围的乘法因子影响下,它能匹配到信息理论的下限。换句话说,悲观主义不仅被证明有效,而且能够将最优解进行极小极大。

而且,在给定数据集时,学习到的策略会成为所有策略中的No.1。他们的理论分析证明了悲观主义在消除虚假相关性上的关键作用。
不同的理论框架会产生不同的算法设计。汪昭然的步骤是:从理论到算法,设计出安全、鲁棒的算法,再往上的第三层则是设法在多智能体交互的场景下制定出一个既能提高效率、又不失公平与安全的社会决策。
在一个多智能体系统中,每个参与者都有自己的意图,都想优化自己的利益。比如,在外卖系统中,有骑手、商家和买家,你如何动态设计一个高效又合理的机制,既能提高骑手的送餐速度,又不危害骑手的生命安全,同时令商家与买家满意?
汪昭然观察到,目前深度强化学习的算法设计一块已有许多出色的研究成果,但第三层的社会决策制定则是刚刚起步,它的发展需要来自系统与模拟器的支持。近几年来,他们在理论与算法层面已进行了较深入的探索,之后的两年会集中在多智能体系统决策一块。
正如前面所述,模拟器的设计也是一个难题。“如何设计一个模拟器,让它能够服务于深度强化学习或优化类的算法,让模拟器与算法结合地更紧密?”汪昭然谈道,仿真器(即模拟器)本就承担着连接现实与算法的责任,算法是在模拟器里学到的,如果模拟器能更多地反映现实,那么学到的算法也会更适合现实世界。
在某种程度上,深度强化学习可以被归类为“合作人工智能”问题,即人与机器如何合作;也可以从博弈论的角度看,将深度强化学习看作不同智能体之间的博弈。在他们去年的一个工作“End-to-End Learning and Intervention in Games”中,他们用了一个双层优化的算法。双层优化的性质与经济学领域的斯塔克伯格博弈(Stackelberg Game)方法相似:假设有一个绝对的市场/政府领导者,下属有许多独立的运转体,处于领导地位的智能体要做出更好的决策。
比如,如果机器对骑手的要求太高,骑手在某段路线骑得飞快,或者逆行,就会造成许多不安全的问题。在人机博弈中,算法对现实因素的考虑太少,其中也是因为缺少数据和仿真器去尽可能反映出问题。
4
总结


谷歌健康「分拆」内幕:憋屈的CEO、傲慢的Jeff Dean、狂热的AI信徒

教培已死,硬件方生

AI 商业模式的脱靶、崩塌、救赎