
Pandas 第一轮零基础扫盲
为什么用 Pandas?
你好,我是悦创。
通过对 Numpy 的学习,我们发现 Numpy 的功能确实强大且易用。但是再强大的工具也有其局限性。
例如 Numpy 是基于数组的运算,但是在实际工作中,我们的数据元素会非常复杂,会同时包含文字格式、数字格式、时间格式等,显然 Numpy就不适用了。
通常我们说 Numpy 是基于数组格式构建的一个数组运算工具,而 Pandas 是基于 Numpy 构建的结构化数据处理工具。对 Pandas 来讲,数据格式得到了扩充,提供了时间序列能力,并且能够同时容纳多种数据格式,并且提供了灵活的缺失值处理工具,功能得到极大地拓展。
Pandas 常用的数据结构有两种:Series 和 DataFrame 。其中 Series 是一个带有名称和索引的一维数组,而 DataFrame 则是用来表示多维的数组结构。
总结如下:
快速高效的数据结构 智能的数据处理能力 方便的文件存取功能 科研及商业应用广泛
对于 Pandas 有两种基础的数据结构,基本上我们在使用的时候就是处理 Series 和 DataFrame。
Series:真正的数据是只有一列的,索引列我们是不算进去的。
| 索引 | 数据 |
|---|---|
| A | 10 |
| B | 30 |
| C | 20 |
| D | 40 |
DataFrame:好几个 Series 结合起来,也就是有好几列的数据结合起来。
| 电影 | 评分 | 评分人数 | |
|---|---|---|---|
| 0 | 血观音 | 7.9 | 38478 |
| 1 | 大佛普拉斯 | 8.6 | 58112 |
| 2 | 华盛顿邮报 | 8.2 | 30773 |
| 3 | 三块广告牌 | 8.7 | 250524 |
安装 Pandas
Windows 系统:
pip install pandas
Mac 系统:
pip3 install pandas
新建一个 Python 文件
导入模块
In [1]: import pandas as pd
Pandas 的基础类型1——Series
创建一个 Series 类型的数据
In [2]: data = pd.Series([1, 3, 5, 7])
Series() 里直接填一个由数字组成的列表
In [3]: list_data = [1, 3, 5, 7]
In [4]: data = pd.Series(list_data)
In [5]: data
Out[5]:
0 1
1 3
2 5
3 7
dtype: int64
由结果我们可知,左边把我们的索引也列出来了,右边对应的数值也列出来了。底部告诉你这个 Series 的数据类型 int64。「如果里面最低的数据类型是 float 那结果也会变成浮点数。」
获取 Series 数据的值
In [6]: data.values
Out[6]: array([1, 3, 5, 7])
获取 Series 数据的索引
In [7]: data.index
Out[7]: RangeIndex(start=0, stop=4, step=1)
创建特殊的索引值
有时候,我们索引的名称比较特殊不是我们原本简单的数字了,有可能是 a、b、c、d 之类的。这个时候就我们该如何指定索引值呢?直接在 Series 创建的时候指定一下就 ok 了。
In [7]: data = pd.Series(list_data, index=['a', 'b', 'c', 'd'])
In [8]: data
Out[8]:
a 1
b 3
c 5
d 7
dtype: int64
这里我们就在创建的时候进行的索引值的指定,那我们如果要在创建之后修改索引呢?
修改索引值名称
In [9]: data.index = ['j', 'k', 'x', 'f'] # 长度需要和数组的长度一样
In [10]: data
Out[10]:
j 1
k 3
x 5
f 7
dtype: int64
获取 Series 数据长度
In [11]: len(data)
Out[11]: 4
获取数组中的某个数据
In [12]: data['k'] # data[1]
Out[12]: 3
获取数组中多个数据「不连续」「第一个中括号:告诉程序说,我要索引一下;第二个中括号:用来获取多个数据,一个数据则不用」
In [13]: data[['k', 'f']]
Out[13]:
k 3
f 7
dtype: int64
获取数组中多个数据「连续的」
In [14]: data[1:3] # 也可以有步长
Out[14]:
k 3
x 5
dtype: int64
计算重复元素出现的次数
In [17]: list_data1 = [1, 1, 1, 3, 5, 5, 7, 7, 9]
In [18]: data1 = pd.Series(list_data1)
In [19]: data1.value_counts()
Out[19]:
1 3
7 2
5 2
9 1
3 1
dtype: int64
判断某个索引值是否存在
In [21]: list_data2 = [1, 3, 5, 7]
In [22]: data3 = pd.Series(list_data2, index=['a', 'j', 'b', 'f'])
In [23]: 'a' in data3
Out[23]: True
In [24]: 'z' in data3
Out[24]: False
检查值是否包含在系列
In [4]: s = pd.Series(['lama', 'cow', 'lama', 'beetle', 'lama', 'hippo'], name='animal')
In [5]: s.isin(['cow', 'lama'])
Out[5]:
0 True
1 True
2 True
3 False
4 True
5 False
Name: animal, dtype: bool
In [6]: s.isin(['lama'])
Out[6]:
0 True
1 False
2 True
3 False
4 True
5 False
Name: animal, dtype: bool
从字典创建一个 Series 类型的数据
In [26]: dict_data = {"BeiJing": 1000, "Shanghai": 800, "Shenzhen": 500}
In [27]: data4 = pd.Series(dict_data)
In [28]: data4
Out[28]:
BeiJing 1000
Shanghai 800
Shenzhen 500
dtype: int64
给数据传入索引值「由字典创建的数组,当我们指定的索引超出时,会自动 nan 填充」
In [33]: dict_data = {"BeiJing": 1000, "Shanghai": 800, "Shenzhen": 500}
In [34]: index_list = ["Guangzhou", "BeiJing", "Shanghai", "Shenzhen"]
In [35]: data5 = pd.Series(dict_data, index=index_list)
In [36]: data5
Out[36]:
Guangzhou NaN
BeiJing 1000.0
Shanghai 800.0
Shenzhen 500.0
dtype: float64
检测哪些数据是缺失的(空的)「检测非空用 notnull() 」
In [37]: data5.isnull()
Out[37]:
Guangzhou True
BeiJing False
Shanghai False
Shenzhen False
dtype: bool
数组运算
In [10]: data5 * 5
Out[10]:
Guangzhou NaN
BeiJing 5000.0
Shanghai 4000.0
Shenzhen 2500.0
dtype: float64
数组运算支持 numpy 数组运算
In [12]: import numpy as np
In [13]: np.square(data5) # 求平方
Out[13]:
Guangzhou NaN
BeiJing 1000000.0
Shanghai 640000.0
Shenzhen 250000.0
dtype: float64
两个数组相加「两个的数组的长度可以不一样,顺序也可以不一样」
In [14]: dict_data1 = {"BeiJing": 1000, "Shanghai": 800, "Shenzhen": 500}
...: dict_data2 = {"BeiJing": 1000, "Shanghai": 800, "Shenzhen": 500}
...:
...: index_list = ["Guangzhou", "BeiJing", "Shanghai", "Shenzhen"]
...: data1 = pd.Series(dict_data1, index=index_list)
...: data2 = pd.Series(dict_data2)
In [15]: data1 + data2
Out[15]:
BeiJing 2000.0
Guangzhou NaN
Shanghai 1600.0
Shenzhen 1000.0
dtype: float64
In [16]: data1 = pd.Series(dict_data1, index=index_list)
...: data2 = pd.Series(dict_data2, index=index_list)
In [17]: data1 + data2
Out[17]:
Guangzhou NaN
BeiJing 2000.0
Shanghai 1600.0
Shenzhen 1000.0
dtype: float64
In [21]: data1 = pd.Series([1, 3, 5, 6, 7, 8])
In [22]: data2 = pd.Series([2, 4, 6, 8, 9])
In [23]: data1 + data2
Out[23]:
0 3.0
1 7.0
2 11.0
3 14.0
4 16.0
5 NaN
dtype: float64
设定 Series 对象的 name 和索引名称「类似于给一个表格取个名称,给索引值取个名称」
In [25]: dict_data = {"BeiJing": 1000, "Shanghai": 800, "Shenzhen": 500}
In [26]: data = pd.Series(dict_data)
In [27]: data.name = 'City Data'
In [28]: data.index.name = 'City'
In [29]: data
Out[29]:
City
BeiJing 1000
Shanghai 800
Shenzhen 500
Name: City Data, dtype: int64
当然我们还可以在创建为数组取名字
In [30]: dict_data = {"BeiJing": 1000, "Shanghai": 800, "Shenzhen": 500}
In [31]: data = pd.Series(dict_data, name='City Data')
In [32]: data
Out[32]:
BeiJing 1000
Shanghai 800
Shenzhen 500
Name: City Data, dtype: int64
Pandas 的基础类型2——DataFrame
创建一个 DataFrame 类型的数据
In [39]: dict_data = {
...: 'Student': ['lilei', 'hanmeimei', 'aiyuechuang'],
...: 'Score': [99, 100, 135],
...: 'Gender': ['M', 'F', 'M']
...: }
In [40]: data = pd.DataFrame(dict_data)
In [41]: data
Out[41]:
Student Score Gender
0 lilei 99 M
1 hanmeimei 100 F
2 aiyuechuang 135 M
指定 DataFrame 数据的列顺序「如果出现结果顺序不一样,这个是正常现象」
In [42]: data = pd.DataFrame(dict_data, columns=['Gender', 'Score', 'Student']) # 指定列的顺序
In [43]: data
Out[43]:
Gender Score Student
0 M 99 lilei
1 F 100 hanmeimei
2 M 135 aiyuechuang
获取 DataFrame 数据的列名称
In [45]: data.columns
Out[45]: Index(['Gender', 'Score', 'Student'], dtype='object')
指定 DataFrame 数据的索引值
In [46]: data = pd.DataFrame(dict_data,
...: columns=['Gender', 'Score', 'Student'],
...: index=['a', 'b', 'c'])
In [47]: data
Out[47]:
Gender Score Student
a M 99 lilei
b F 100 hanmeimei
c M 135 aiyuechuang
获取 DataFrame 数据中的某一列数据
In [48]: data['Student'] # 方法一
Out[48]:
a lilei
b hanmeimei
c aiyuechuang
Name: Student, dtype: object
In [49]: data.Student # 方法二
Out[49]:
a lilei
b hanmeimei
c aiyuechuang
Name: Student, dtype: object
获取 DataFrame 数据中的某一行数据
根据行编号
In [51]: data.iloc[0]
Out[51]:
Gender M
Score 99
Student lilei
Name: a, dtype: object
In [59]: data.loc[['a', 'c']] # 指定多行数据
Out[59]:
Gender Score Student
a M 99 lilei
c M 135 aiyuechuang
In [60]: data[0:2]
Out[60]:
Gender Score Student
a M 99 lilei
b F 100 hanmeimei
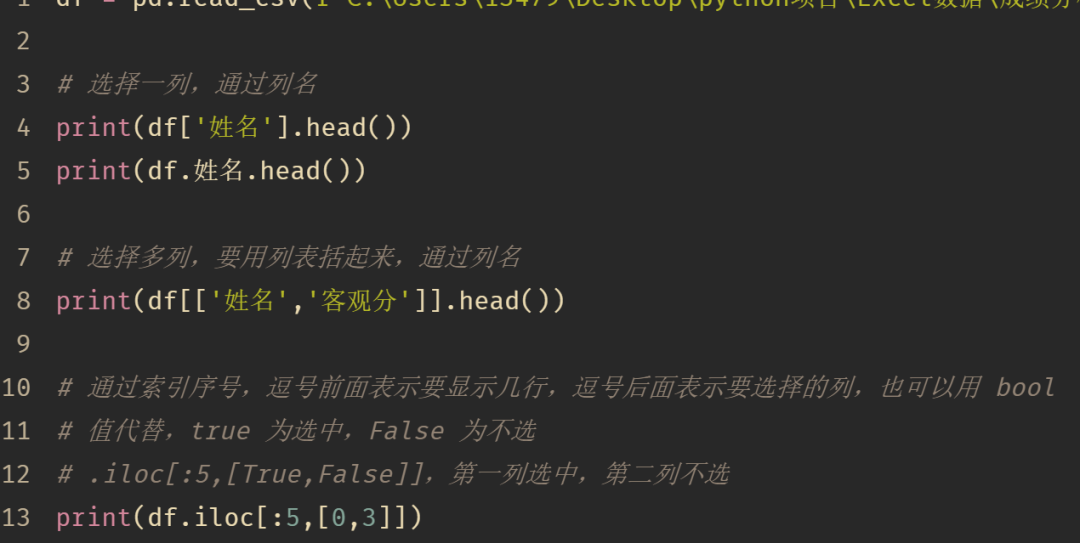
根据行索引
In [52]: data.loc['a']
Out[52]:
Gender M
Score 99
Student lilei
Name: a, dtype: object
切片「单列数据」
In [53]: slice_data = data['Student']
In [54]: slice_data
Out[54]:
a lilei
b hanmeimei
c aiyuechuang
Name: Student, dtype: object
切片「获取多列数据」
In [56]: slice_data = data[['Student', 'Gender']]
In [57]: slice_data
Out[57]:
Student Gender
a lilei M
b hanmeimei F
c aiyuechuang M
注意!切片得到的数据对应的还是原始数据,任何修改都会反映到原始数据上
In [62]: dict_data = {
...: 'Student': ['lilei', 'hanmeimei', 'aiyuechuang'],
...: 'Score': [99, 100, 135],
...: 'Gender': ['M', 'F', 'M']
...: }
...:
...: data = pd.DataFrame(dict_data,
...: columns=['Gender', 'Score', 'Student'],
...: index=['a', 'b', 'c'])
...: slice_data = data['Score'] # data[['Score']]
...: """
...: 第一种 ['Score'] 在确定只提取一个的话使用这种方法;
...: 第二种 [['Score']] 在不确定或者确定会有提取多个的话,推荐使用这个方法。
...: """
...: slice_data[0] = 999 # 当我们在切片的时候,如果只是单纯的切片「不带 copy」没有操作不会出
...: 现"警告" 如果进行的赋值或者修改,则会出现警告。「算是提示吧,也是比较智能的一个点」
/usr/local/bin/ipython:15: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
In [63]: data
Out[63]:
Gender Score Student
a M 999 lilei
b F 100 hanmeimei
c M 135 aiyuechuang
想要一份副本不影响原始数据?
请用 data['score'].copy()
In [64]: slice_data = data['Score'].copy()
...: slice_data[0] = 999
In [65]: data
Out[65]:
Gender Score Student
a M 99 lilei
b F 100 hanmeimei
c M 135 aiyuechuang
如果如果同时切片数据不止一个,那修改之后的数据变成这样:
In [75]: slice_data = data[['Score', 'Student']].copy()
...: slice_data.iloc[0] = 999
In [76]: slice_data
Out[76]:
Score Student
a 999 999
b 100 hanmeimei
c 135 aiyuechuang
注意:如果你是如此操作提取数据的话—— data[['Score']] ,在下一步中修改数据中如果是这样操作的话:slice_data[0] = 999 得到的结果是 添加新的列。所以,就需要使用 iloc 或 loc 来指定了。
In [73]: slice_data = data[['Score', 'Student']].copy()
...: slice_data[0] = 999 # slice_data[列名] = 列值
...: slice_data
Out[73]:
Score Student 0
a 99 lilei 999
b 100 hanmeimei 999
c 135 aiyuechuang 999
修改 DataFrame 数据中的某一列数据
In [77]: data
Out[77]:
Gender Score Student
a M 99 lilei
b F 100 hanmeimei
c M 135 aiyuechuang
In [78]: data['Score'] = 120
In [79]: data
Out[79]:
Gender Score Student
a M 120 lilei
b F 120 hanmeimei
c M 120 aiyuechuang
In [80]: data['Score'] = 10, 20, 30 # [10, 20, 30]、(10, 20, 30)
In [81]: data
Out[81]:
Gender Score Student
a M 10 lilei
b F 20 hanmeimei
c M 30 aiyuechuang
In [88]: data['Score'] = range(95, 98)
In [89]: data
Out[89]:
Gender Score Student
a M 95 lilei
b F 96 hanmeimei
c M 97 aiyuechuang
传入 Series 类型修改 DataFrame 数据中的某一列数据
In [90]: series_data = pd.Series([1, 3, 5])
In [91]: data['Score'] = series_data
In [92]: data
Out[92]:
Gender Score Student
a M NaN lilei
b F NaN hanmeimei
c M NaN aiyuechuang
In [94]: series_data = pd.Series([1, 3, 5], index=['a', 'b', 'c'])
In [95]: data['Score'] = series_data
In [96]: data
Out[96]:
Gender Score Student
a M 1 lilei
b F 3 hanmeimei
c M 5 aiyuechuang
如果 Series 的数据过长,则自动忽略:
In [97]: series_data = pd.Series([1, 3, 5, 7], index=['a', 'b', 'c', 'd'])
In [98]: data['Score'] = series_data
In [99]: data
Out[99]:
Gender Score Student
a M 1 lilei
b F 3 hanmeimei
c M 5 aiyuechuang
删除 DataFrame 数据中的某一列数据
In [102]: del data['Score']
In [103]: data
Out[103]:
Gender Student
a M lilei
b F hanmeimei
c M aiyuechuang
删除一行或一列:drop 函数
DataFrame.drop(labels=None, axis=0, index=None, columns=None, inplace=False)
# labels 就是要删除的行列的名字,用列表给定
# axis 默认为0,指删除行,因此删除 columns 时要指定 axis=1;
# index 直接指定要删除的行
# columns 直接指定要删除的列
# inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新 dataframe;
# inplace=True,则会直接在原数据上进行删除操作,删除后无法返回。
因此,删除行列有两种方式:
labels=None,axis=0 的组合 index 或 columns 直接指定要删除的行或列
In [111]: df = pd.DataFrame(np.arange(12).reshape(3,4), columns=['A', 'B', 'C', 'D'])
In [112]: df
Out[112]:
A B C D
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
#Drop columns,两种方法等价
In [113]: df.drop(['B', 'C'], axis=1)
Out[113]:
A D
0 0 3
1 4 7
2 8 11
In [114]: df.drop(columns=['B', 'C'])
Out[114]:
A D
0 0 3
1 4 7
2 8 11
# 第一种方法下删除 column 一定要指定 axis=1,否则会报错
In [115]: df.drop(['B', 'C'])
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
KeyError: "['B' 'C'] not found in axis"
#Drop rows
In [116]: df.drop([0, 1])
Out[116]:
A B C D
2 8 9 10 11
In [117]: df.drop(index=[0, 1])
Out[117]:
A B C D
2 8 9 10 11
根据新的索引重新排列数据
In [120]: dict_data = {
...: 'Student': ['lilei', 'hanmeimei', 'aiyuechuang'],
...: 'Score': [99, 100, 135],
...: 'Gender': ['M', 'F', 'M']
...: }
In [121]: data = pd.DataFrame(dict_data,
...: columns=['Gender', 'Score', 'Student'],
...: index=['a', 'b', 'c'])
In [122]: data.reindex(['b', 'a', 'c'])
Out[122]:
Gender Score Student
b F 100 hanmeimei
a M 99 lilei
c M 135 aiyuechuang
如果,我们在重新排序的时候,多填了一个 d 那相对应 d 的几个位置的数据 pandas 会自动帮你填上 NaN。
In [123]: data.reindex(['b', 'a', 'c', 'd'])
Out[123]:
Gender Score Student
b F 100.0 hanmeimei
a M 99.0 lilei
c M 135.0 aiyuechuang
d NaN NaN NaN
如果,我们想在多填了之后指定数据呢?
将缺失位置填0
In [124]: data.reindex(['b', 'a', 'c', 'd'], fill_value=0)
Out[124]:
Gender Score Student
b F 100 hanmeimei
a M 99 lilei
c M 135 aiyuechuang
d 0 0 0
将缺失位置通过插值法计算并补上内容
In [125]: data.reindex(['b', 'a', 'c', 'd'], method='ffill')
Out[125]:
Gender Score Student
b F 100 hanmeimei
a M 99 lilei
c M 135 aiyuechuang
d M 135 aiyuechuang
In [126]: data.reindex(['b', 'a', 'c', 'd'], method='bfill')
Out[126]:
Gender Score Student
b F 100.0 hanmeimei
a M 99.0 lilei
c M 135.0 aiyuechuang
d NaN NaN NaN
扔掉包含缺失的数据(NaN)的行「例如:我们数据量很大的时候,有可能想把空值去掉,使用 dropna 来去掉,只要这一行有一个空数据,就会去掉。」这里代码为了方便演示,就先不使用 IPython。
import numpy as np
import pandas as pd
dict_data = {
'Student': ['lilei', 'hanmeimei', 'aiyuechuang'],
'Score': [99, 100, 135],
'Gender': ['M', 'F', 'M']
}
data = pd.DataFrame(dict_data,
columns=['Gender', 'Score', 'Student', 'Age'],
index=['a', 'b', 'c'])
new_data = data.reindex(['a', 'b', 'c', 'd'])
print(new_data)
print(new_data.dropna())
扔掉全部都是缺失的数据(NaN)的行
print(new_data.dropna(how='all'))
填充所有缺失数据为一个值
print(new_data.fillna(0))
按列填充缺失数据为不同值「fillna:按列填写缺失值,如果存在着不填。」
dict_data = {
'Student': ['lilei', 'hanmeimei', 'aiyuechuang'],
'Score': [99, 100, 135],
'Gender': ['M', 'F', 'M']
}
data = pd.DataFrame(dict_data,
columns=['Gender', 'Score', 'Student', 'Age'],
index=['a', 'b', 'c'])
new_data = data.reindex(['a', 'b', 'c', 'd'])
key_value = {'Gender': 'F', 'Score': 145, 'Student': 'Alex', 'Age': 21}
print(new_data.fillna(key_value))
# 输出
Gender Score Student Age
a M 99.0 lilei 21
b F 100.0 hanmeimei 21
c M 135.0 aiyuechuang 21
d F 145.0 Alex 21
筛选数据
dict_data = {
'Student': ['lilei', 'hanmeimei', 'aiyuechuang'],
'Score': [80, 100, 135],
'Gender': ['M', 'F', 'M']
}
data = pd.DataFrame(dict_data,
columns=['Gender', 'Score', 'Student', 'Age'],
index=['a', 'b', 'c'])
print(data[data['Score'] >= 90])
# 输出
Gender Score Student Age
b F 100 hanmeimei NaN
c M 135 aiyuechuang NaN
从列表中筛选数据
dict_data = {
'Student': ['lilei', 'hanmeimei', 'aiyuechuang', 'Alex', 'Cleland', 'AI悦创'],
'Score': [80, 100, 135, 90, 85, 95],
'Gender': ['M', 'F', 'M', 'M', 'F', 'M']
}
data = pd.DataFrame(dict_data)
select_list = [95, 100, 135]
# print(data)
print(data[data['Score'].isin(select_list)])
GroupBy
import pandas as pd
ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings',
'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'],
'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2],
'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017],
'Points':[876,789,863,673,741,812,756,788,694,701,804,690]}
df = pd.DataFrame(ipl_data)
print (df)
# 执行上面示例代码,得到以下结果 -
Points Rank Team Year
0 876 1 Riders 2014
1 789 2 Riders 2015
2 863 2 Devils 2014
3 673 3 Devils 2015
4 741 3 Kings 2014
5 812 4 kings 2015
6 756 1 Kings 2016
7 788 1 Kings 2017
8 694 2 Riders 2016
9 701 4 Royals 2014
10 804 1 Royals 2015
11 690 2 Riders 2017
"""
将数据拆分成组
Pandas对象可以分成任何对象。有多种方式来拆分对象,如 -
- obj.groupby(‘key’)
- obj.groupby([‘key1’,’key2’])
- obj.groupby(key,axis=1)
现在来看看如何将分组对象应用于 DataFrame 对象
示例
"""
import pandas as pd
ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings',
'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'],
'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2],
'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017],
'Points':[876,789,863,673,741,812,756,788,694,701,804,690]}
df = pd.DataFrame(ipl_data)
print (df.groupby('Team'))
# 执行上面示例代码,得到以下结果 -
0x00000245D60AD518>
# 查看分组
import pandas as pd
ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings',
'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'],
'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2],
'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017], 'Points':[876,789,863,673,741,812,756,788,694,701,804,690]}
df = pd.DataFrame(ipl_data)
print (df.groupby('Team').groups)
# 执行上面示例代码,得到以下结果 -
{
'Devils': Int64Index([2, 3], dtype='int64'),
'Kings': Int64Index([4, 6, 7], dtype='int64'),
'Riders': Int64Index([0, 1, 8, 11], dtype='int64'),
'Royals': Int64Index([9, 10], dtype='int64'),
'kings': Int64Index([5], dtype='int64')
}
# 得到的结果类似字典的结构,提取字典的值之后,可以直接用整数索引或者使用 .values 可以提取出分组之后的值「数组」
利用 groupby 对数据进行分组并计算 sum, mean 等
import pandas as pd
data = pd.DataFrame({
"tag_id": ['a', 'b', 'c', 'a', 'a', 'c', 'c'],
'count': [10, 30, 20, 10, 15, 22, 22]
})
grouped_data = data.groupby('tag_id')
print(grouped_data.sum())
# 输出
count
tag_id
a 35
b 30
c 64
data = pd.DataFrame({
"tag_id": ['a', 'b', 'c', 'a', 'a', 'c', 'c'],
'count': [10, 30, 20, 10, 15, 22, '22']
})
grouped_data = data.groupby('tag_id')
print(grouped_data.sum())
# 输出
count
tag_id
a 35.0
b 30.0
c NaN
data = pd.DataFrame({
"tag_id": ['a', 'b', 'c', 'a', 'a', 'c', 'c'],
'count': [10, 30, 20, 10, 15, 22, 22]
})
grouped_data = data.groupby('count')
print(grouped_data.sum())
# 输出
tag_id
count
10 aa
15 a
20 c
22 cc
30 b
数据排序——按索引名称升序排列
import pandas as pd
data = pd.DataFrame({
"tag_id": ['0802', '0823', '0832', '0731'],
'count': [10, 30, 20, 10]
},
index=['b', 'c', 'a', 'd'])
print(data)
print(data.sort_index())
数据排序——按索引名称降序排列
print(data.sort_index(ascending=False)) # ascending 上升
数据排序——按某一列的数据进行排序
print(data.sort_values(by='tag_id'))
数据汇总「对 DataFrame 的数据全部进行求和」
data = pd.DataFrame({
"tag_id": ['AI', 'YC', 'FP', 'MK'],
'count': [10, 30, 20, 10]
})
# print(data)
print(data.sum())
一些常用的方法
| 函数 | 说明 |
| --- | --- |
| count | 计算非 NaN 数据的数量 |
| min、max | 计算最小、最大值 |
| argmin、argmax | 计算最小、最大值位置 |
| sum | 计算数值的和 |
| mean | 计算平均数 |
| median | 计算中位数 |
| var | 计算方差 |
| std | 计算标准差 |同一个轴可以用多种方式来索引
import numpy as np
import pandas as pd
np_data = np.random.randint(1, 5, size=7)
book_ratings = pd.Series(
np_data,
index=[
['b1', 'b1', 'b2', 'b2', 'b3', 'b4', 'b4'],
[1, 2, 1, 2, 1, 2, 3]
])
print(book_ratings)
print(book_ratings.loc['b1'])
# 输出
b1 1 4
2 3
b2 1 4
2 1
b3 1 2
b4 2 1
3 3
dtype: int64
1 4
2 3
dtype: int64
两个 DataFrame 进行合并
import pandas as pd
book_name = pd.DataFrame({
'book_name': ['a', 'b', 'c', 'd', 'e', 'f'],
'book_id': [11, 22, 33, 44, 55, 66]
})
id_rating = pd.DataFrame({
'book_id': [11, 22, 22, 44, 55, 66, 33, 11, 55],
'rating': [1, 3, 5, 2, 4, 3, 2, 4, 5]
})
print(pd.merge(book_name, id_rating))

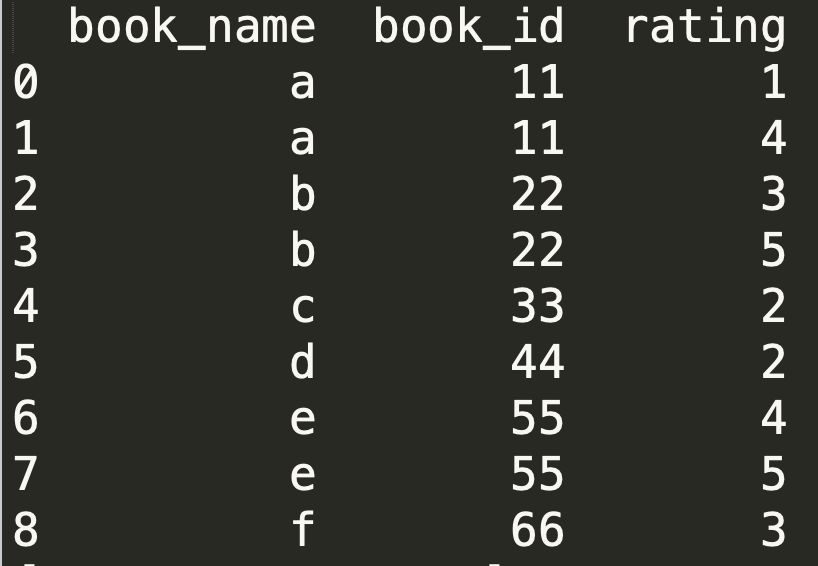
两个 DataFrame 进行合并,不指定连接方式「默认是把他们都有的」
data1 = pd.DataFrame({
'key': ['a', 'b', 'a', 'c', 'b', 'd'],
'data1': [1, 2, 3, 4, 5, 6]
})
data2 = pd.DataFrame({
'key': ['a', 'b', 'c'],
'data2': [8, 9, 7]
})
print(pd.merge(data1, data2))
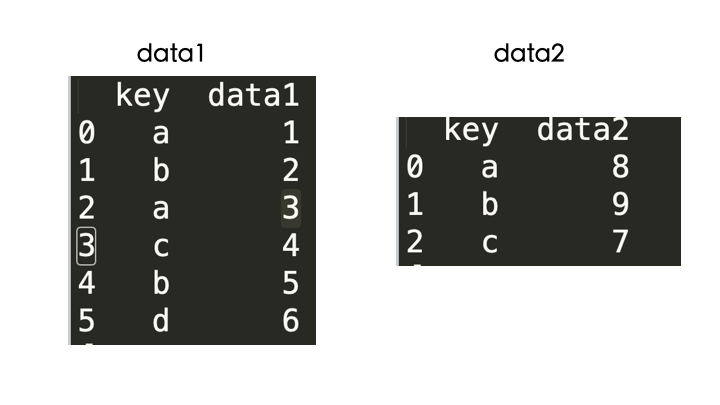
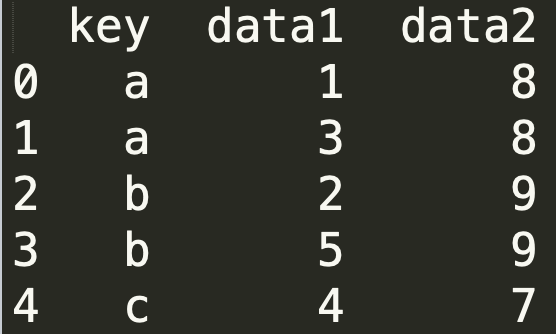
默认把两个数据框都有的数据进行合并。
两个 DataFrame 进行合并,指定连接方式「现在我们希望,你不要把双方都有的留下来,我要把只有一方有的也留下来」
print(pd.merge(data1, data2, how='outer'))
# 输出
key data1 data2
0 a 1 8.0
1 a 3 8.0
2 b 2 9.0
3 b 5 9.0
4 c 4 7.0
5 d 6 NaN
还可以使用 left、right 「类似交集并集、交集之类的」
两个 DataFrame 进行合并,指定连接的列名称「两个数据框都有的一个列,来合并」
data1 = pd.DataFrame({
'key': ['a', 'b', 'a', 'c', 'b', 'b'],
'data1': [1, 2, 3, 4, 5, 6]
})
data2 = pd.DataFrame({
'key': ['a', 'b', 'c'],
'data2': [8, 9, 7]
})
print(pd.merge(data1, data2, on='key'))
两个 DataFrame 进行合并,分别指定连接的列名称「两个数据没有重合的名称,我们分别指定列来合并」
print(pd.merge(data1, data2,
left_on='lkey',
right_on='rkey'))
Pandas 文件存取——读取 CSV 文件「默认会把文件的第一行,变成标题」https://aiyc.lanzoux.com/iSU8ufj79af
data = pd.read_csv('rating.csv')
读取 CSV 文件,不要标题行「取消第一行为标题」
data = pd.read_csv('rating.csv', header=None)
读取 CSV 文件,自定义标题行
data = pd.read_csv('rating.csv', names=['user_id', 'book_id', 'rating'])
读取 CSV 文件,指定索引列「有可能我都某一列是我们的索引列,所以这个时候需要指定索引列」
data = pd.read_csv('rating.csv',
names=['user_id', 'book_id', 'rating'],
index_col='user_id')
读取 CSV 文件,指定分隔符
data = pd.read_csv('rating.csv',
names=['user_id', 'book_id', 'rating'],
sep=',')
读取 CSV 文件,自动处理缺失的数据「pandas 比较智能地方就是会把空的地方补上 Nan」
新建 data.csv 文件,里面存储如下数据
1,2,3,4,5
6,7,8,,10
11,,13,14,15
代码如下:
data = pd.read_csv('data.csv', header=None)
储存数据为 CSV 文件
import pandas as pd
data = pd.DataFrame({
'student': ['lilei', 'hanmeimei', 'madongmei'],
'gender': ['M', 'F', 'F'],
'score': [90, 80, 100]
})
data.to_csv('student.csv')
,student,gender,score
0,lilei,M,90
1,hanmeimei,F,80
2,madongmei,F,100在软件中打开:

读取 Excel 文件,首先安装 xlrd 模块
Windows 系统:
pip install xlrdMac 系统:
pip3 install xlrd新建一个 Excel 文件,保存文件名称为:student.xlsx

读取 Excel 文件
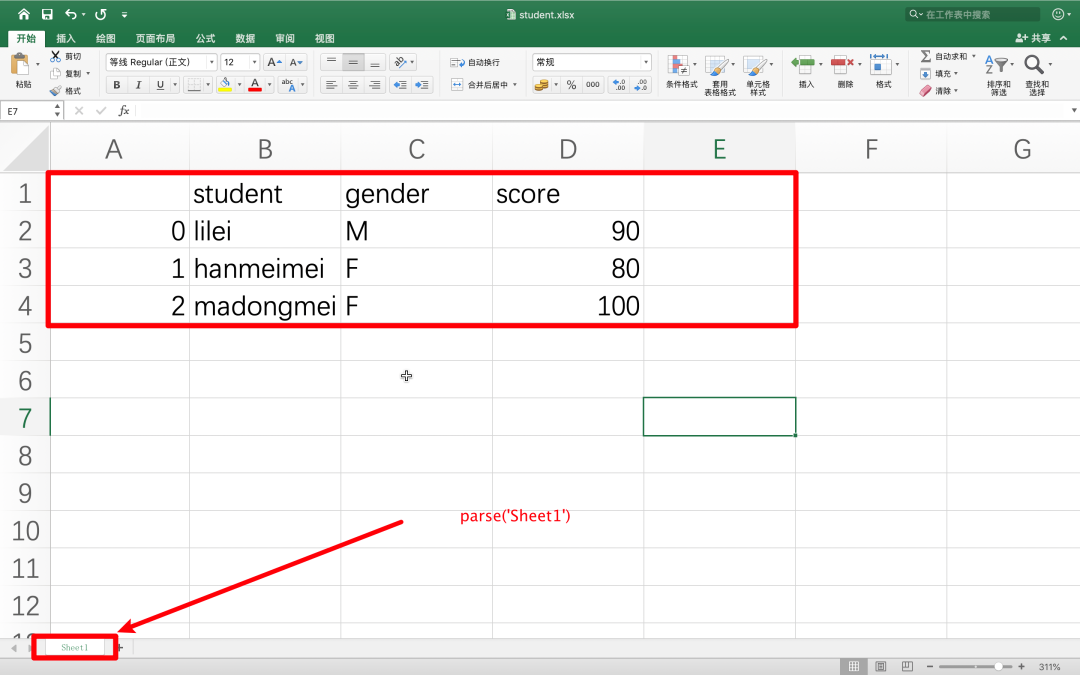
import pandas as pd
file = pd.ExcelFile('student.xlsx')
data = file.parse('Sheet1') # Excel 表格名称
print(data)
# 输出
Unnamed: 0 student gender score
0 0 lilei M 90
1 1 hanmeimei F 80
2 2 madongmei F 100
Pandas VS. Numpy 读取文件速度比较
import numpy as np
import pandas as pd
import time
start_time = time.time()
data = np.genfromtxt('./rating.txt', delimiter=',')
end_reading_time = time.time()
print('Numpy reading time: {}ms'.format(round((end_reading_time - start_time) * 1000, 2)))
start_time = time.time()
data = pd.read_table('./rating.csv',
names=['user_id', 'book_id', 'rating'],
sep=',')
end_reading_time = time.time()
print('Pandas reading time: {}ms'.format(round((end_reading_time - start_time) * 1000, 2)))
# 输出
Numpy reading time: 27029.64ms
Pandas reading time: 1003.31ms
Pandas 读取速度很快,处理起来比 Numpy 慢一些。Numpy 是最底层的,Pandas 会智能的时候给你做一些数据处理,所以很多时候我们使用 Pandas 。
分析热门标签
数据集:https://aiyc.lanzoux.com/iqgPTfxyrxc
任务1:找出最多人想读的 50本书的名称 任务2:找出这 50本书对应最热门的10个标签
文件1:to_read.csv
每行两个数据,用户 id 和该用户想读的书籍 id
文件2:books.csv
书籍的各类 id,名称,作者等信息
文件3:tags.csv
每行两个数据,标签 id 和标签名称
文件4:book_tags.csv
每行三个数据, _goodreads_book_id_(和to_read中的书籍 id 的对应关系可以在books.csv里找到),标签 id,标记次数
解答
Python 原生的处理方式,代码如下「简版代码」:
import pandas as pd
import numpy as np
data = pd.read_csv('../to_read.csv')
# print(data)
new_data = data['book_id']
# array_lengt = len(set(data['book_id']))
# print(array_lengt)
# book_count_array = np.zeros(array_lengt)
# print(set(new_data))
book_id_values = {}
result = list(new_data)
for data in set(new_data):
book_id_values[data] = result.count(data)
# print(book_id_values)
d_sorted_by_value = sorted(book_id_values.items(), key=lambda x: x[1]) # 根据字典值的升序排序
a = d_sorted_by_value[::-1][:50]
print(a)
print(len(a))
[(47, 2772), (143, 1967), (113, 1840), (13, 1812), (11, 1767), (45, 1717), (139, 1650), (39, 1619), (65, 1608), (35, 1576), (342, 1521), (185, 1502), (119, 1499), (8, 1498), (6, 1484), (4, 1478), (94, 1460), (89, 1458), (55, 1441), (61, 1435), (109, 1432), (16, 1425), (31, 1417), (67, 1352), (146, 1342), (54, 1339), (46, 1325), (121, 1313), (5, 1293), (173, 1292), (115, 1285), (68, 1257), (36, 1211), (95, 1208), (167, 1188), (129, 1181), (265, 1180), (137, 1172), (277, 1160), (66, 1158), (267, 1154), (268, 1149), (28, 1148), (38, 1130), (60, 1129), (14, 1127), (225, 1111), (10, 1110), (233, 1106), (252, 1105)]
50
[Finished in 147.9s]
Pandas 代码:
第一步,找到最热的50本书
import pandas as pd
import numpy as np
to_read = pd.read_csv('../to_read.csv')
to_read_counts = to_read['book_id'].value_counts().sort_values(ascending=False)
hottest_50_books_id = to_read_counts[:50].index
hottest_50_books_counts = to_read_counts[:50].values
hottest_50_books = pd.DataFrame({
'book_id': hottest_50_books_id,
'to_read_counts': hottest_50_books_counts
})
"""
涉及到的知识点
1. value_counts(): 计算重复元素出现的次数「显示形式为:值为索引,次数为值」
2. sort_values(): 按某一列的数据进行排序,使用 by=列名,来指定。
默认是升序排序,可以使用 ascending=False 来反转
"""
print(hottest_50_books)
book_id to_read_counts
0 47 2772
1 143 1967
2 113 1840
3 13 1812
4 11 1767
5 45 1717
6 139 1650
7 39 1619
8 65 1608
9 35 1576
10 342 1521
11 185 1502
12 119 1499
13 8 1498
14 6 1484
15 4 1478
16 94 1460
17 89 1458
18 55 1441
19 61 1435
20 109 1432
21 16 1425
22 31 1417
23 67 1352
24 146 1342
25 54 1339
26 46 1325
27 121 1313
28 5 1293
29 173 1292
30 115 1285
31 68 1257
32 36 1211
33 95 1208
34 167 1188
35 129 1181
36 265 1180
37 137 1172
38 277 1160
39 66 1158
40 267 1154
41 268 1149
42 28 1148
43 38 1130
44 60 1129
45 14 1127
46 225 1111
47 10 1110
48 233 1106
49 252 1105
[Finished in 0.6s]
第二步,找到书籍的名称
books = pd.read_csv('../books.csv')
book_id_and_title = books[['book_id', 'goodreads_book_id', 'title']]
hottest_50_books_with_title = pd.merge(
hottest_50_books,
book_id_and_title,
how='left')
print(hottest_50_books_with_title)
hottest_50_books_with_title.to_csv('hottest_50_books_with_title.csv')
第三步,找到这50本书对应最热的10个标签
book_tags = pd.read_csv('../book_tags.csv')
book_tags = book_tags[book_tags['_goodreads_book_id_'].isin(hottest_50_books_with_title['goodreads_book_id'])]
del book_tags['_goodreads_book_id_']
hottest_10_tags = book_tags.groupby('tag_id').sum()
hottest_10_tags = hottest_10_tags.sort_values(by='count', ascending=False)[:10]
hottest_10_tags = pd.DataFrame({
'tag_id': hottest_10_tags.index,
'count': hottest_10_tags['count']
})
print(hottest_10_tags['tag_id'])
第四步,找到这10个标签的名称
tags = pd.read_csv('../tags.csv')
hottest_10_tags_with_tag_name = pd.merge(
hottest_10_tags,
tags,
on='tag_id',
how='left')
print(hottest_10_tags_with_tag_name)
hottest_10_tags_with_tag_name.to_csv('hottest_10_tags_with_tag_name.csv')“AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。QQ、微信在线,随时响应!V:Jiabcdefh
”
黄家宝丨AI悦创
隐形字
摄影公众号「悦创摄影研习社」
在这里分享自己的一些经验、想法和见解。


长按识别二维码关注