
6000字我就写了个数据探索分析?
大家好,我是宝器!
今天的这篇文章比较肝,是一篇比较贴合实际工作的数分实战案例
全文 6000 多字,可能阅读会花一些时间,但是 绝对物超所值。特别是对于没有项目可以练手的同学来说,建议跟着实操一遍,收获很大!
下面是正文:
这个项目官方给出的背景是这样的:

解读一下,大致意思是:现在有一批已经更换5G套餐的用户数据,数据维度有很多,包括:基础信息、消费行为、超套信息、宽带信息、其他信息,共 46 个用户特征。
目的是 通过这批用户数据去分析什么样的用户更倾向于更换5G套餐,从而进行潜客营销
如果是第一次做分析类项目的同学,可能拿到这个数据的第一印象是:靠,咋这么多特征列?
其实数据一共就 14w 条,5 个用户维度一共 46 个特征,比较正常的数据,实际真正应用的话这个数据量甚至还有点点少,训练出来的模型需要多轮测试才能部署。
ok,背景也说完了,下面开始正文
整体分析
在分析之前需要明确,当前的工作是探索性数据分析(EDA)。探索性数据分析属于数据清洗之前的部分,主要是探索数据,只看数据不操作数据
先来看看数据:
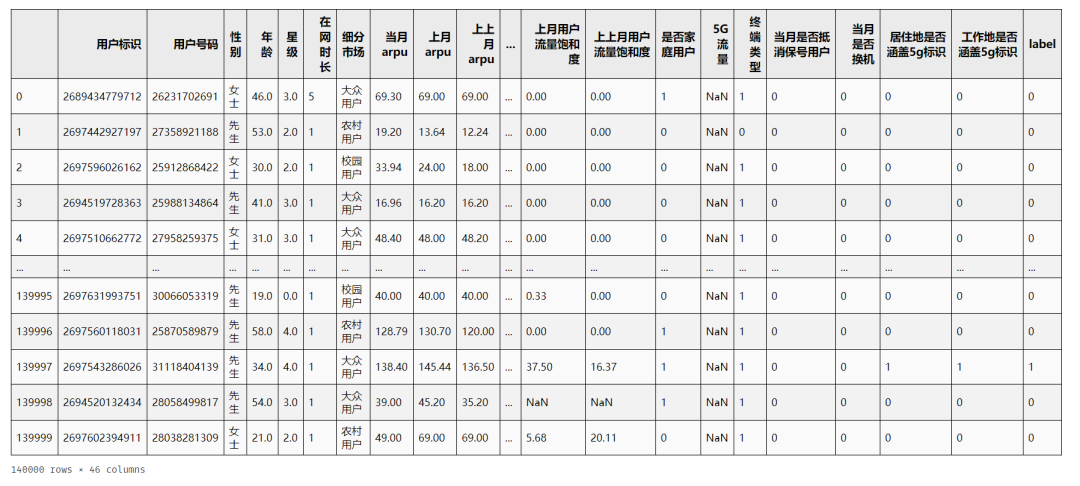
整体数据就这样,一共 14w 条数据,46 个特征
1. 缺失分析
缺失分析应该算是最早应该做的,如果有缺失值,后面的探索 不要忘了考虑缺失 情况
一个 46 个特征,肯定会有缺失值,代码也很简单:
"""查看数据整体缺失情况"""
df_data.isnull().sum()
图很长,放一部分吧:

这个图看的不是很明了,换种方式,我们可以计算每个特征的缺失程度,然后排序一下
代码如下:
"""查看特征的缺失程度"""
missing_series = df_data.isnull().sum()/df_data.shape[0]
missing_df = pd.DataFrame(missing_series).reset_index()
missing_df = missing_df.rename(columns={'index': 'col', 0: 'missing_pct'})
missing_df = missing_df.sort_values('missing_pct', ascending=False).reset_index(drop=True)
效果是这样的:

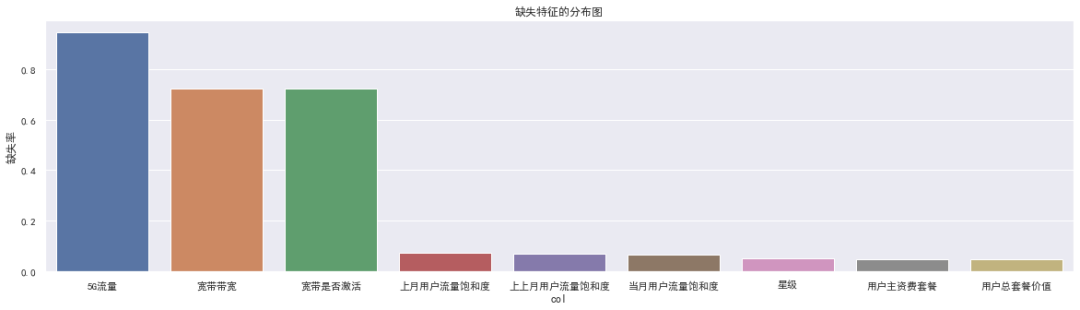
1.2 缺失分析-看图分析
用户标识维度无数据缺失
用户基础信息维度中星级缺失 6849 条数据、细分市场缺失 691 条数据 消费行为信息维度、超套信息维度中所有特征均分别缺失 89、392 条数据 宽带信息维度中宽带贷款和宽带是否激活特征缺失 101060 条数据,缺失较严重 签约信息维度、套餐信息维度中所有特征均分别缺失 774、6617 条数据 流量饱和度信息维度中所有特征均缺失 9000+ 条数据,需要进一步分析 其他信息特征中,5G流量特征缺失 132559 条数据,缺失非常严重
另外,缺失分析不光是特征分析,还需要 对样本进行缺失分析
如果一个样本在多个特征上都缺失,那默认该样本可用价值比较少,可以直接丢弃
代码如下:
"""查看样本的缺失程度"""
missing_series = df_data.isnull().sum(axis=1)
list_missing_num = sorted(list(missing_series.values))
绘图如下:
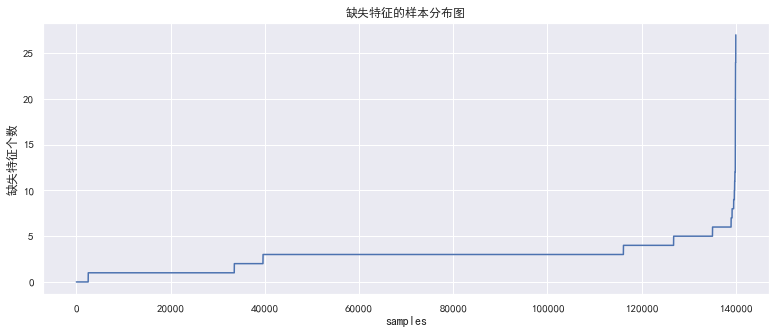
1.3 缺失分析-总结
首先,数据呈现阶段性缺失,可以初步判定同一维度中的多个特征缺失实为同一样本的缺失。
其次,部分样本的特征缺失较多,可以考虑删除此部分样本
2. 类别分析
常见的数据类型一般分为两种:类别型特征和数值型特征
像样本数据中的 细分市场 就属于类别特征,属性包括:校园用户、集团用户等等,对应的 5G流量 就属于数值特征,有具体的数值大小。
pandas 中对于类别和数值特征的区分很简单:
# 查看特征的数值特征有哪些,类别特征有哪些
numerical_fea = list(df_data.select_dtypes(exclude=['object']).columns)
category_fea = list(filter(lambda x: x not in numerical_fea, list(df_data.columns)))
但是,上述代码存在根本上的问题
pandas 在读取数据的时候会自动声明数据类别,导致有部分脱敏后的类别数据会被其认为是数值数据
例如,终端类型、是否异网宽带用户特征,因为数据需要脱敏处理,所以你看到的数据值为:1、2... ,实质上它们都是类别特征,像终端类型的原始数据可能是:华为、小米、苹果这些
这里推荐一种比较取巧的方法:同值过滤法
解释一下:如果一个被 pandas 认定的数值特征中出现不同值的个数超过 10,那么这个特征就是数值特征,否则就是类别特征
上面的 10 你也可以人为调整
代码如下:
"""划分数值型变量中的连续变量和分类变量"""
def get_numerical_serial_fea(data, feas):
numerical_serial_fea = []
numerical_noserial_fea = []
for fea in feas:
temp = data[fea].nunique()
# 如果同值个数小于10,则认为是类别型数据
if temp <= 10:
numerical_noserial_fea.append(fea)
else:
numerical_serial_fea.append(fea)
return numerical_serial_fea,numerical_noserial_fea
在今天的项目中,这个方法效果很明显:

原本认定的 4 个类别特征,增加到 19 个
3. 同值化分析
同值化就是一个特征中某个属性的占比很高,那么用这个特征去分类极有可能得不出好效果
同值化在类别特征中比较容易出现,代码如下:
"""查看特征中特征的单方差(同值化)性质"""
threshold_const = 0.95
const_list = [x for x in df_data.columns if x!='label']
const_col = []
const_val = []
for col in const_list:
# value_counts 的最多的一个样本类别的样本数
max_samples_count = df_data[col].value_counts().iloc[0]
# 总体非空样本数
sum_samples_count = df_data[df_data[col].notnull()].shape[0]
# 计算特征中类别最多的样本占比
const_val.append(max_samples_count/sum_samples_count)
# 过滤同值化特征
if max_samples_count/sum_samples_count >= threshold_const:
const_col.append(col)
print('常变量/同值化比例大于{}的特征个数为{}'.format(threshold_const, len(const_col)))
效果如下:
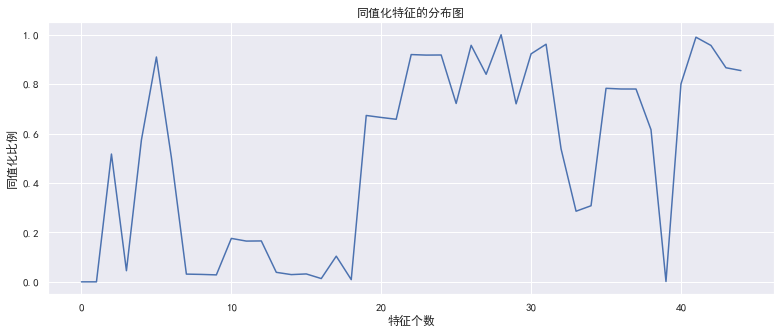
可以发现,同值化比例大于 95% 的有 5 个特征,甚至有一个特征全为同一个值,需要特别注意
单特征深度分析
单特征分析主要是针对类别型特征和数值型特征挨个进行分析
但是用户信息中缺失情况比较一致,处于同一维度的特征也可以同时做对比分析
1. 类别特征分析-整体
先来看整体类别特征的分布情况:
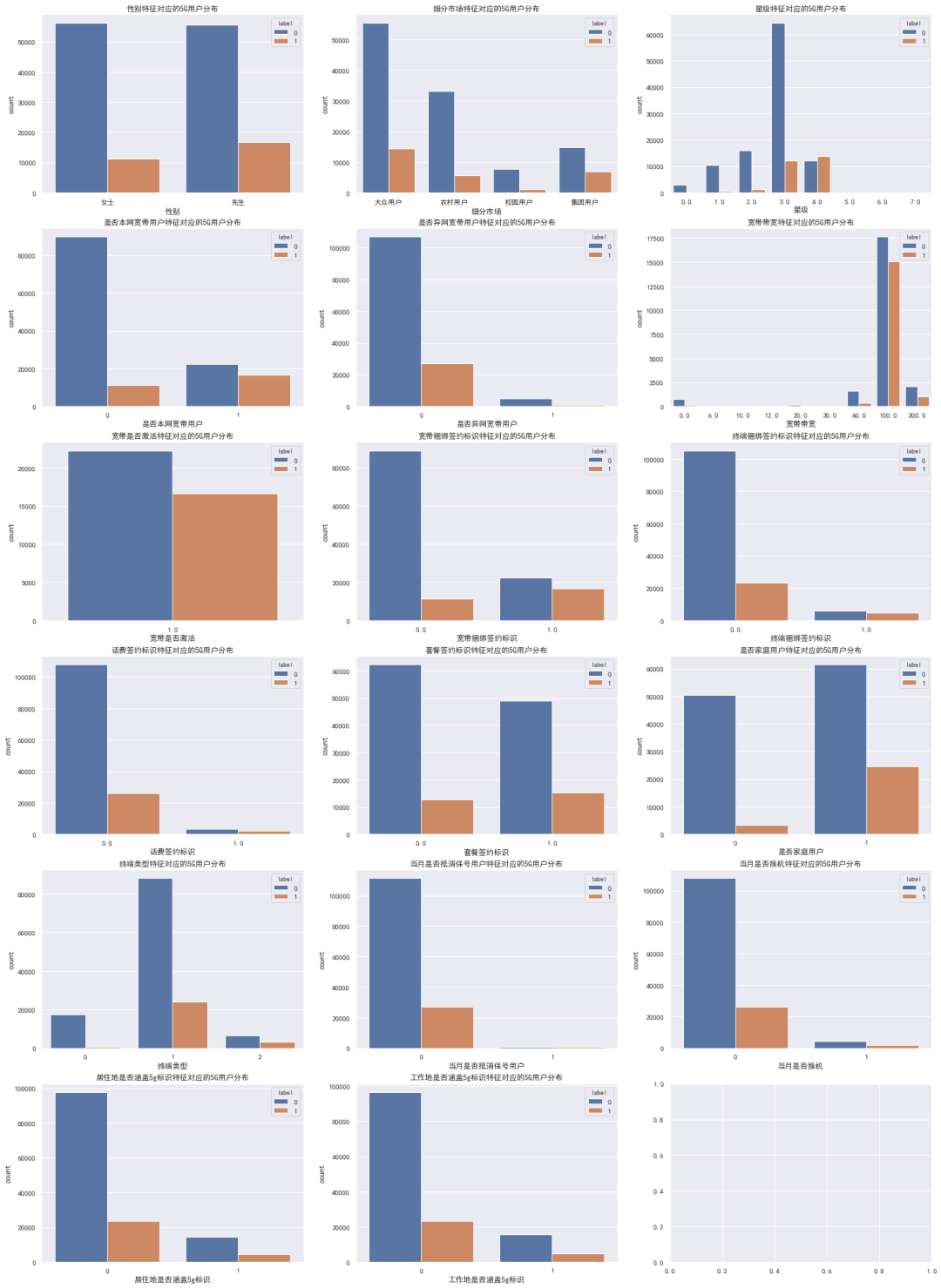
1. 类别特征分析-看图说话
从上图可以得出很多有用的信息,其中:
性别中,男性5G用户开通率略微高于女性 市场中,集团用户更倾向于开通5G 星级中,四星级用户更愿意使用5G 本网宽带用户比异网宽带用户更倾向于使用5G,而且宽带带宽为100的用户占比更高、200次之 宽带、终端捆绑的用户更愿意使用5G 家庭用户比非家庭用户更愿意使用5G 终端类型为1的用户最多,为2的5G用户率最高
另外:
宽带是否激活特征只有唯一值和缺失值 当月是否保号保号用户特征同值化较高
还有:星级、宽带带宽特征个别特征占比较低,可以考虑分箱处理;上述倾向于使用5G的用户特征(例如:细分市场)中类别存在空值,缺失的是否重要?同值化特征是否可以删除?
别急着下结论,都需要进一步分析
1.1 星级特征-分析
上面说过,星级特征需要特别考虑缺失值是否重要
小技巧:将缺失值单独分为一列
代码如下:
"""进一步对上述类别特征进行分析"""
df_data_2 = df_data.copy()
# 星级特征
df_data_2.loc[df_data_2['星级'].isnull(), '星级'] = '空'
"""星级特征对应的5G用户"""
plt.figure(figsize=(13, 5))
# 设置标题
plt.title('不同星级特征对应的5G用户')
sns.countplot(x='星级', hue='label', data=df_data_2)
plt.show()
效果如下:
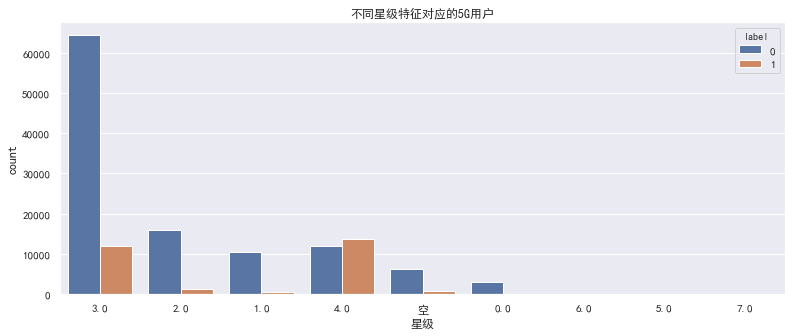
另外,也可以看看星级用户对应的5G用户具体占比情况
"""星级对应的5G用户占比"""
df_bucket = df_data_2.groupby('星级')
user_5G_trend = pd.DataFrame()
user_5G_trend['total'] = df_bucket['label'].count()
user_5G_trend['5G'] = df_bucket['label'].sum()
user_5G_trend['5G_rate'] = user_5G_trend['5G']/user_5G_trend['total']
user_5G_trend = user_5G_trend.reset_index()
user_5G_trend
绘图如下:
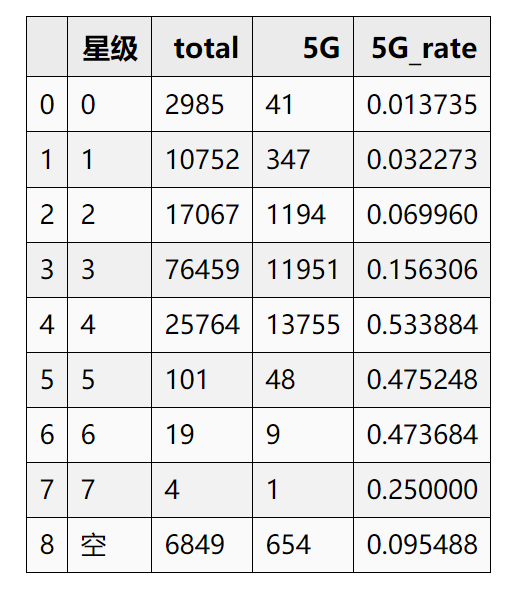
1.1 星级特征-结论
星级 0、1、2、3、4 对应的5G用户占比逐渐增高,星级 5、6、7 用户数较少,但是整体5G用户占比还是高于平均值
操作建议:可以进行分箱,空值对应的5G用户可单独分为一类,或者根据5G用户占比率进行分箱合并
具体的,后期可根据模型的具体预测效果进行选择
1.2 细分市场特征-分析
和星级特征一样,先考虑缺失值,然后在分析
代码类似上一步,直接看图
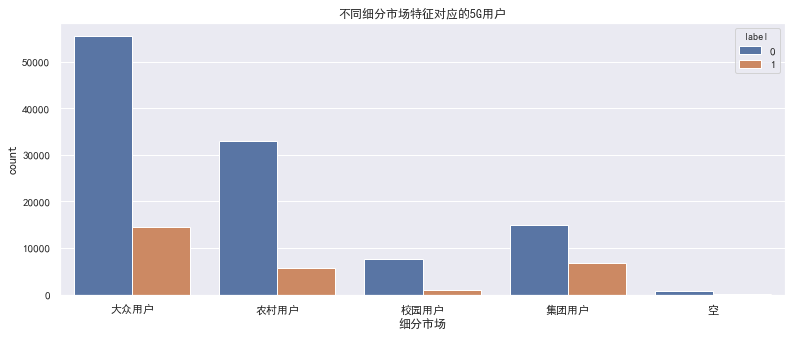
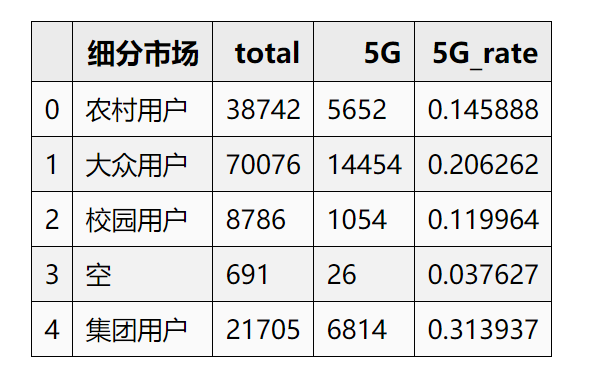
1.2 细分市场特征-结论
校园用户占比最少,5G开通率最低;集团用户5G用户占比最高
操作建议:空值对应的5G用户 占比极低,分箱会影响其他箱的5G用户占比,所以不建议进行箱体合并,可尝试直接单独当做一箱
具体的,后期可根据模型的具体预测效果进行选择
1.3 宽带带宽&是否激活特征-分析
同样的思路,先考虑缺失值,然后在分析
不同的是,宽带带宽 特征与另一个特征 宽带是否激活 需要综合考虑
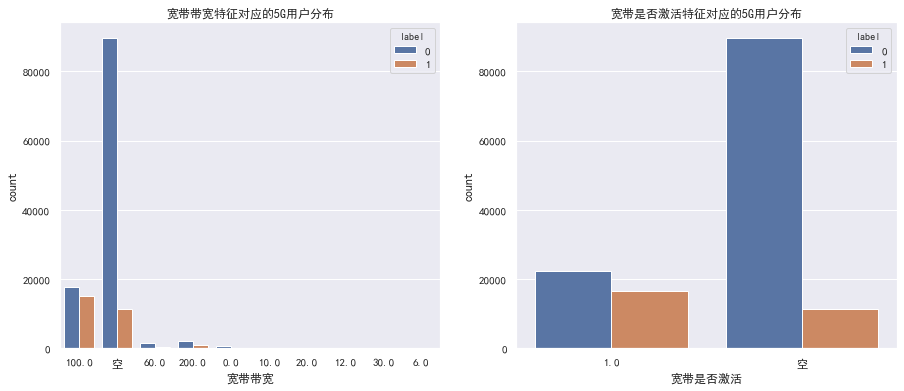
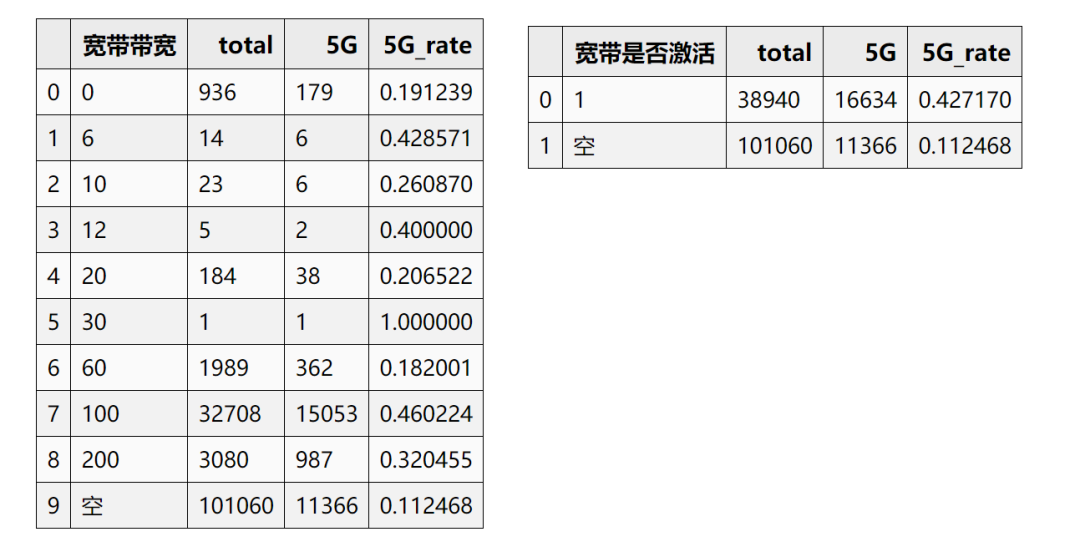
1.3 宽带带宽&是否激活特征-结论
宽带带宽特征:
带宽在60以下的特征因为样本数据太少,可以进行合箱 带宽在100以上的因为总体5G用户占比较高,可以进行合箱
操作建议:最终的宽带带宽特征可以分为3箱:<=60、>100、空
宽带是否激活特征:
因为属性只有1,表示宽带已经激活,所以这里大胆预测缺失的数据就是表示宽带没有激活,对应的可以用0表示
1.4 其他类别特征-分析
剩余 6 个特征中 4 个为签约维度特征,2 个为其他维度特征,可以一并进行分析
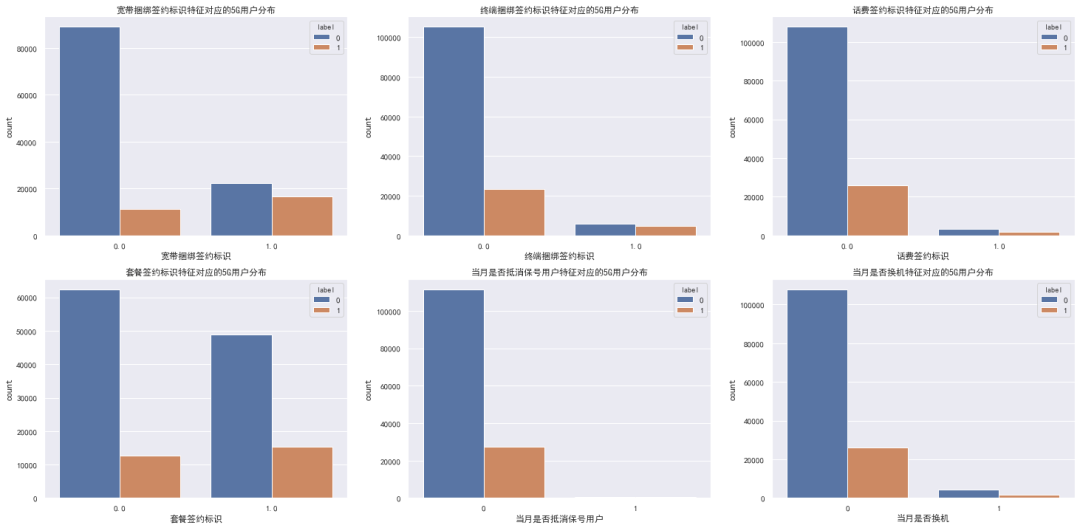


1.4 其他类别特征-总结
前 4 个签约维度特征中存在缺失数据,任选两个特征分析发现缺失数据的5G用户占比较低
提供如下操作建议:
合并到概率相近的箱中,例如上述特征中的0属性 用众数填充 用同类别用户该特征的众数填充 直接删除样本
后 2 个特征虽然同值化较严重,但是样本少的5G用户占比较高,或许在模型训练中会拿到一个不错的贡献分
暂时不做处理,后面特征工程中尝试通过 lgb 进行特征筛选后在确定
2. 数值特征分析-整体
离散特征中有两个例外的特征需要单独分析:年龄和在网时长
年龄字段虽然是数值型,但是将其进行分箱后模型的性能会大大提升,分析如下:
2.1 年龄特征-分析
计算每个年龄5G用户占比情况,观察是否可以分箱,以及分箱策略
代码如下:
"""
年龄特征分析
计算不同年龄的5G用户分布情况
"""
df_bucket = df_data_2.groupby('年龄')
user_5G_trend = pd.DataFrame()
user_5G_trend['total'] = df_bucket['label'].count()
user_5G_trend['5G'] = df_bucket['label'].sum()
user_5G_trend['5G_rate'] = user_5G_trend['5G']/user_5G_trend['total']
user_5G_trend = user_5G_trend.reset_index()
绘图如下:
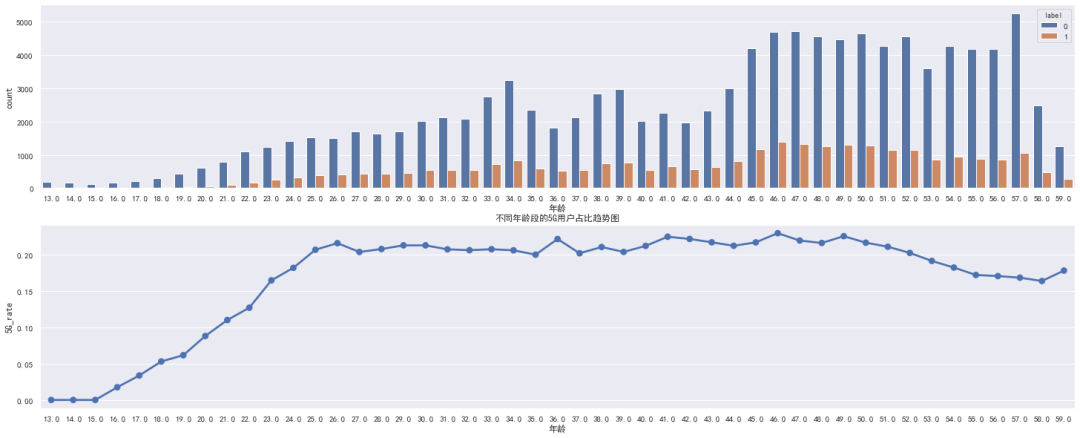
2.1 年龄特征-总结
从图中可以发现:
25-50岁 之间5G用户整体占比较高,基本在 20% 上方波动 13-25岁 的5G用户占比随着年龄呈上升趋势 50岁 以上的5G用户占比随着年龄呈下降趋势
基于这个特性,可以将年龄特征进行分箱,大致如下:
13-20、20-25、25-45、45-50、>50
上面分组不绝对,例如对于第1、2组也可以合为一组,3、4组合为一组
具体的分组效果需要根据模型的得分去判断
2.2 在网时长特征-分析
思路同年龄特征,直接统计各自的5G用户占比情况
绘图如下:
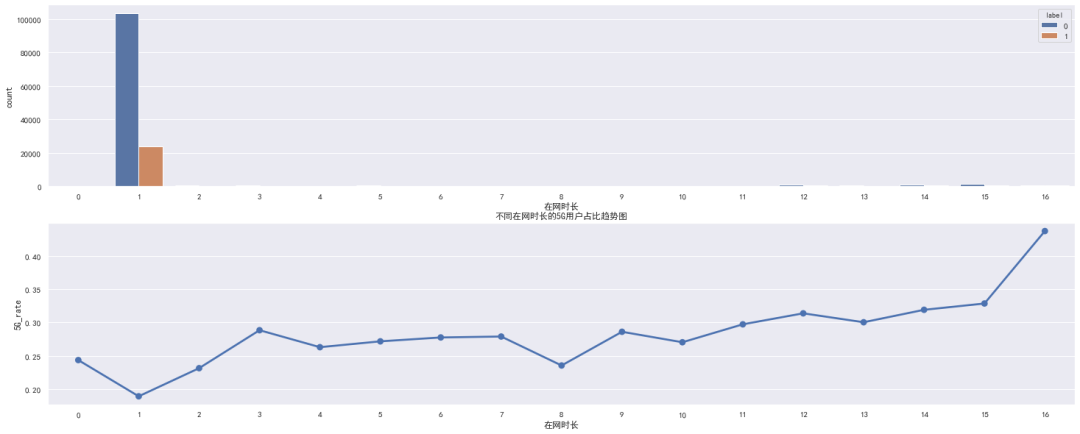
2.2 在网时长特征-总结
从图中可以发现:
在网时长为 1 的样本占比最多,但同时5G用户占比率也最低
当在网时长在 2-10 之间时,5G用户占比在 25%-30% 中间波动
当在网时长 >10 时,5G用户占比率高于 30%,并呈现加速上升趋势
其实,分析到这,不难猜出,对应的数字应该代表用户在网年份
具体的操作建议:还是分箱操作 ① 0-1 ② 2-10 ③ >10
具体的分组效果还是需要根据模型的得分去判断,这里不绝对
2.3 数值特征-分析
数值特征的分析比较简单,最常见的是对极大极小值进行过滤,或者设定一个最大值赋给超过该值的所有值
其次是对数据进行无量纲化,使得不同的特征能够保持在一个量纲上,模型训练起来也快一些
直接绘图看特征分布:
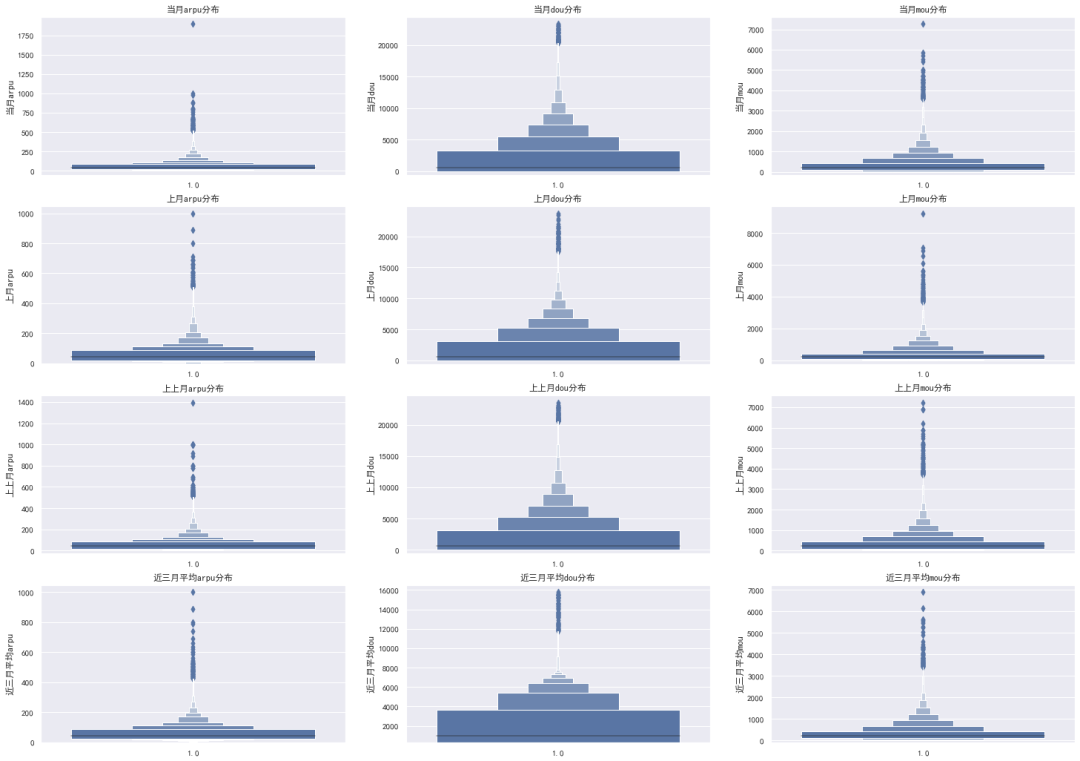
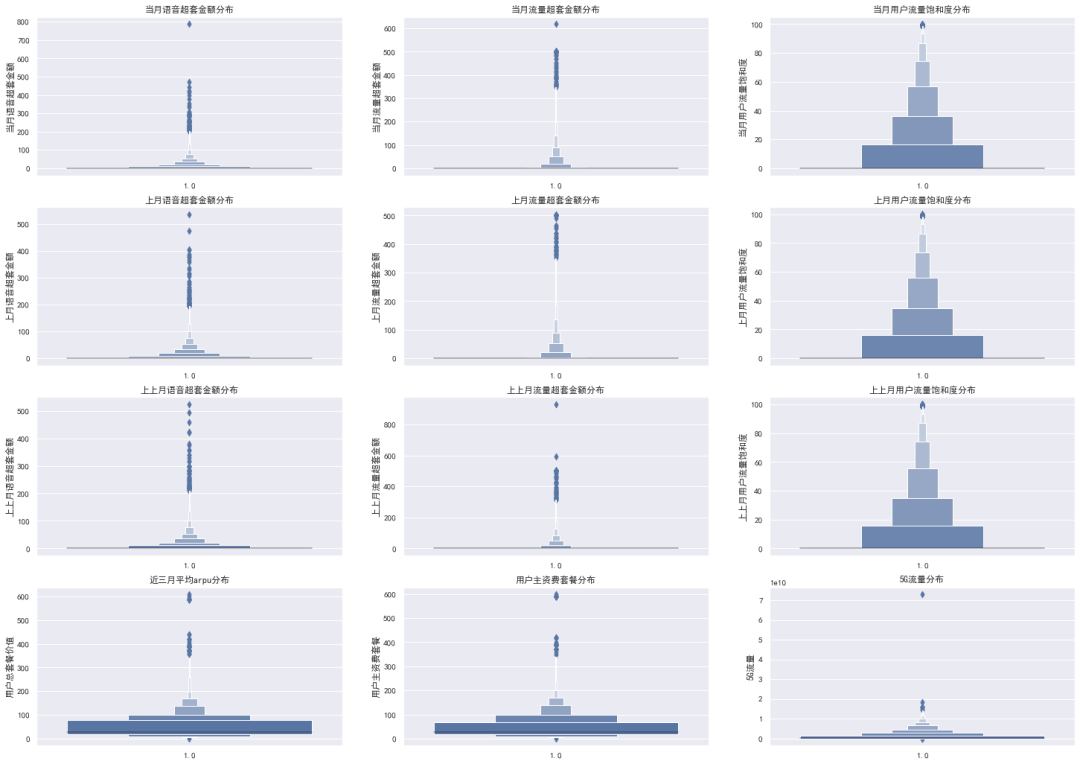
操作建议:去极值、标准化,常见的操作手法
总结一下
以上就是在数据探索阶段需要做的事情,常见的探索手法还会对多个特征特征进行联立分析
例如:不同星级的男性和女性5G用户占比是什么样的?不同细分市场不同年龄段的5G用户占比又是什么样的?
很多时候,特征之间的互相融合就是源自于多维度的探索分析
总结一下今天的内容,方便在特征工程部分进行相应的处理
首先很明显能看出:
性别中,男性5G用户开通率略微高于女性 市场中,集团用户更倾向于开通5G 星级中,四星级用户更愿意使用5G 本网宽带用户更倾向于使用5G,而且宽带带宽为100的用户意愿更强 宽带、终端捆绑的用户更愿意使用5G 家庭用户比非家庭用户更愿意使用5G 终端类型为为2的5G用户率最高
更细致一点的:
星级 0、1、2、3、4 对应的5G用户占比逐渐增高,星级 5、6、7 用户数最少,但是5G用户占比率相近
校园用户占比最少,5G开通率最低;集团用户5G开通率最高
带宽在 60 以下的样本数据太少,带宽在100以上的5G用户占比较高
宽带是否激活中属性只有1,表示宽带已经激活
签约维度特征中签约信息为空的5G用户占比较低
是否抵消保号用户和当月是否换机这两个特征虽然同值化较严重,但是样本少的属性5G用户占比较高

推荐阅读
欢迎长按扫码关注「数据管道」