
SQL 优化极简法则,还有谁不会?
点击上方蓝色“小哈学Java”,选择“设为星标”
回复“资源”获取独家整理的学习资料!


文章目录
法则一:只返回需要的结果
法则二:确保查询使用了正确的索引
法则三:尽量避免使用子查询
法则四:不要使用 OFFSET 实现分页
法则五:了解 SQL 子句的逻辑执行顺序
总结
SQL 作为关系型数据库的标准语言,是 IT 从业人员必不可少的技能之一。SQL 本身并不难学,编写查询语句也很容易,但是想要编写出能够高效运行的查询语句却有一定的难度。
查询优化是一个复杂的工程,涉及从硬件到参数配置、不同数据库的解析器、优化器实现、SQL 语句的执行顺序、索引以及统计信息的采集等,甚至应用程序和系统的整体架构。本文介绍几个关键法则,可以帮助我们编写高效的 SQL 查询;尤其是对于初学者而言,这些法则至少可以避免我们写出性能很差的查询语句。
以下法则适用于各种关系型数据库,包括但不限于:MySQL、Oracle、SQL Server、PostgreSQL 以及 SQLite 等。如果觉得文章有用,欢迎评论?、点赞?、推荐?
法则一:只返回需要的结果
一定要为查询语句指定 WHERE 条件,过滤掉不需要的数据行。通常来说,OLTP 系统每次只需要从大量数据中返回很少的几条记录;指定查询条件可以帮助我们通过索引返回结果,而不是全表扫描。绝大多数情况下使用索引时的性能更好,因为索引(B-树、B+树、B*树)执行的是二进制搜索,具有对数时间复杂度,而不是线性时间复杂度。以下是 MySQL 聚簇索引的示意图:
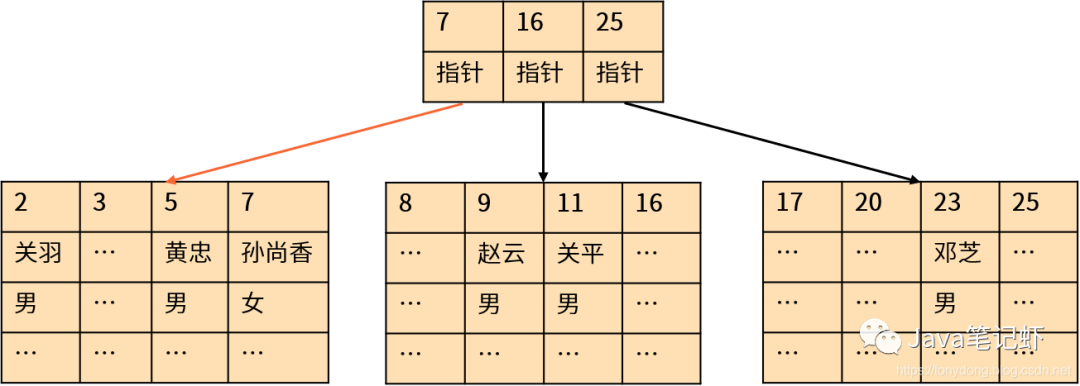
举例来说,假设每个索引分支节点可以存储 100 个记录,100 万(1003)条记录只需要 3 层 B-树即可完成索引。通过索引查找数据时需要读取 3 次索引数据(每次磁盘 IO 读取整个分支节点),加上 1 次磁盘 IO 读取数据即可得到查询结果。
相反,如果采用全表扫描,需要执行的磁盘 IO 次数可能高出几个数量级。当数据量增加到 1 亿(1004)时,B-树索引只需要再增加 1 次索引 IO 即可;而全表扫描则需要再增加几个数量级的 IO。
同理,我们应该避免使用 SELECT * FROM, 因为它表示查询表中的所有字段。这种写法通常导致数据库需要读取更多的数据,同时网络也需要传输更多的数据,从而导致性能的下降。
?关于B-树索引的原理以及利用索引优化各种查询条件、连接查询、排序和分组以及 DML 语句的介绍,可以参考:https://tonydong.blog.csdn.net/article/details/104020721
法则二:确保查询使用了正确的索引
如果缺少合适的索引,即使指定了查询条件也不会通过索引查找数据。因此,我们首先需要确保创建了相应的索引。一般来说,以下字段需要创建索引:
经常出现在 WHERE 条件中的字段建立索引可以避免全表扫描;
将 ORDER BY 排序的字段加入到索引中,可以避免额外的排序操作;
多表连接查询的关联字段建立索引,可以提高连接查询的性能;
将 GROUP BY 分组操作字段加入到索引中,可以利用索引完成分组。
即使创建了合适的索引,如果 SQL 语句写的有问题,数据库也不会使用索引。导致索引失效的常见问题包括:
在 WHERE 子句中对索引字段进行表达式运算或者使用函数都会导致索引失效,这种情况还包括字段的数据类型不匹配,例如字符串和整数进行比较;
使用 LIKE 匹配时,如果通配符出现在左侧无法使用索引。对于大型文本数据的模糊匹配,应该考虑数据库提供的全文检索功能,甚至专门的全文搜索引擎(Elasticsearch 等);
如果 WHERE 条件中的字段上创建了索引,尽量设置为 NOT NULL;不是所有数据库使用 IS [NOT] NULL 判断时都可以利用索引。
执行计划(execution plan,也叫查询计划或者解释计划)是数据库执行 SQL 语句的具体步骤,例如通过索引还是全表扫描访问表中的数据,连接查询的实现方式和连接的顺序等。如果 SQL 语句性能不够理想,我们首先应该查看它的执行计划,通过执行计划(EXPLAIN)确保查询使用了正确的索引。
?关于各种主流数据库中执行计划的查看和解释,可以参考:https://tonydong.blog.csdn.net/article/details/103579177
https://blog.csdn.net/horses/article/details/106905110
法则三:尽量避免使用子查询
以 MySQL 为例,以下查询返回月薪大于部门平均月薪的员工信息:
EXPLAIN ANALYZE
SELECT emp_id, emp_name
FROM employee e
WHERE salary > (
SELECT AVG(salary)
FROM employee
WHERE dept_id = e.dept_id);
-> Filter: (e.salary > (select #2)) (cost=2.75 rows=25) (actual time=0.232..4.401 rows=6 loops=1)
-> Table scan on e (cost=2.75 rows=25) (actual time=0.099..0.190 rows=25 loops=1)
-> Select #2 (subquery in condition; dependent)
-> Aggregate: avg(employee.salary) (actual time=0.147..0.149 rows=1 loops=25)
-> Index lookup on employee using idx_emp_dept (dept_id=e.dept_id) (cost=1.12 rows=5) (actual time=0.068..0.104 rows=7 loops=25)
从执行计划可以看出,MySQL 中采用的是类似 Nested Loop Join 实现方式;子查询循环了 25 次,而实际上可以通过一次扫描计算并缓存每个部门的平均月薪。以下语句将该子查询替换为等价的 JOIN 语句,实现了子查询的展开(Subquery Unnest):
EXPLAIN ANALYZE
SELECT e.emp_id, e.emp_name
FROM employee e
JOIN (SELECT dept_id, AVG(salary) AS dept_average
FROM employee
GROUP BY dept_id) t
ON e.dept_id = t.dept_id
WHERE e.salary > t.dept_average;
-> Nested loop inner join (actual time=0.722..2.354 rows=6 loops=1)
-> Table scan on e (cost=2.75 rows=25) (actual time=0.096..0.205 rows=25 loops=1)
-> Filter: (e.salary > t.dept_average) (actual time=0.068..0.076 rows=0 loops=25)
-> Index lookup on t using (dept_id=e.dept_id) (actual time=0.011..0.015 rows=1 loops=25)
-> Materialize (actual time=0.048..0.057 rows=1 loops=25)
-> Group aggregate: avg(employee.salary) (actual time=0.228..0.510 rows=5 loops=1)
-> Index scan on employee using idx_emp_dept (cost=2.75 rows=25) (actual time=0.181..0.348 rows=25 loops=1)
改写之后的查询利用了物化(Materialization)技术,将子查询的结果生成一个内存临时表;然后与 employee 表进行连接。通过实际执行时间可以看出这种方式更快。
以上示例在 Oracle 和 SQL Server 中会自动执行子查询展开,两种写法效果相同;在 PostgreSQL 中与 MySQL 类似,第一个语句使用 Nested Loop Join,改写为 JOIN 之后使用 Hash Join 实现,性能更好。
另外,对于 IN 和 EXISTS 子查询也可以得出类似的结论。由于不同数据库的优化器能力有所差异,我们应该尽量避免使用子查询,考虑使用 JOIN 进行重写。
搜索公众号 Java笔记虾,回复“后端面试”,送你一份面试题大全.pdf
法则四:不要使用 OFFSET 实现分页
分页查询的原理就是先跳过指定的行数,再返回 Top-N 记录。分页查询的示意图如下:
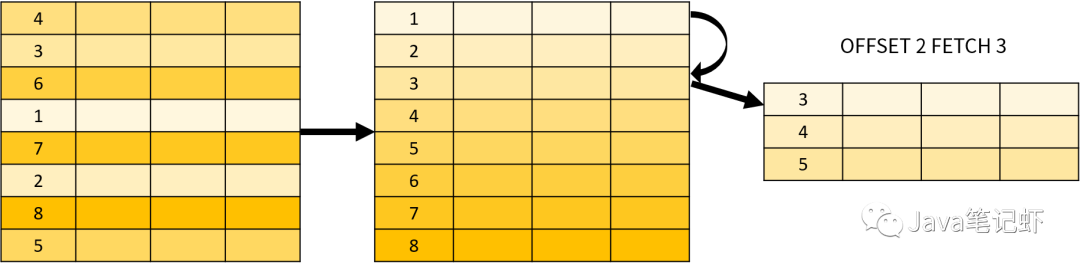
数据库一般支持 FETCH/LIMIT 以及 OFFSET 实现 Top-N 排行榜和分页查询。当表中的数据量很大时,这种方式的分页查询可能会导致性能问题。以 MySQL 为例:
-- MySQL
SELECT *
FROM large_table
ORDER BY id
LIMIT 10 OFFSET N;
以上查询随着 OFFSET 的增加,速度会越来越慢;因为即使我们只需要返回 10 条记录,数据库仍然需要访问并且过滤掉 N(比如 1000000)行记录,即使通过索引也会涉及不必要的扫描操作。
对于以上分页查询,更好的方法是记住上一次获取到的最大 id,然后在下一次查询中作为条件传入:
-- MySQL
SELECT *
FROM large_table
WHERE id > last_id
ORDER BY id
LIMIT 10;
如果 id 字段上存在索引,这种分页查询的方式可以基本不受数据量的影响。
?关于 Top-N 排行榜和分页查询的详细介绍,可以参考:https://tonydong.blog.csdn.net/article/details/108729112
法则五:了解 SQL 子句的逻辑执行顺序
以下是 SQL 中各个子句的语法顺序,前面括号内的数字代表了它们的逻辑执行顺序:
(6)SELECT [DISTINCT | ALL] col1, col2, agg_func(col3) AS alias
(1) FROM t1 JOIN t2
(2) ON (join_conditions)
(3) WHERE where_conditions
(4) GROUP BY col1, col2
(5)HAVING having_condition
(7) UNION [ALL]
...
(8) ORDER BY col1 ASC,col2 DESC
(9)OFFSET m ROWS FETCH NEXT num_rows ROWS ONLY;
也就是说,SQL 并不是按照编写顺序先执行 SELECT,然后再执行 FROM 子句。从逻辑上讲,SQL 语句的执行顺序如下:
首先,FROM 和 JOIN 是 SQL 语句执行的第一步。它们的逻辑结果是一个笛卡尔积,决定了接下来要操作的数据集。注意逻辑执行顺序并不代表物理执行顺序,实际上数据库在获取表中的数据之前会使用 ON 和 WHERE 过滤条件进行优化访问;
其次,应用 ON 条件对上一步的结果进行过滤并生成新的数据集;
然后,执行 WHERE 子句对上一步的数据集再次进行过滤。WHERE 和 ON 大多数情况下的效果相同,但是外连接查询有所区别,我们将会在下文给出示例;
接着,基于 GROUP BY 子句指定的表达式进行分组;同时,对于每个分组计算聚合函数 agg_func 的结果。经过 GROUP BY 处理之后,数据集的结构就发生了变化,只保留了分组字段和聚合函数的结果;
如果存在 GROUP BY 子句,可以利用 HAVING 针对分组后的结果进一步进行过滤,通常是针对聚合函数的结果进行过滤;
接下来,SELECT 可以指定要返回的列;如果指定了 DISTINCT 关键字,需要对结果集进行去重操作。另外还会为指定了 AS 的字段生成别名;
如果还有集合操作符(UNION、INTERSECT、EXCEPT)和其他的 SELECT 语句,执行该查询并且合并两个结果集。对于集合操作中的多个 SELECT 语句,数据库通常可以支持并发执行;
然后,应用 ORDER BY 子句对结果进行排序。如果存在 GROUP BY 子句或者 DISTINCT 关键字,只能使用分组字段和聚合函数进行排序;否则,可以使用 FROM 和 JOIN 表中的任何字段排序;
最后,OFFSET 和 FETCH(LIMIT、TOP)限定了最终返回的行数。
了解 SQL 逻辑执行顺序可以帮助我们进行 SQL 优化。例如 WHERE 子句在 HAVING 子句之前执行,因此我们应该尽量使用 WHERE 进行数据过滤,避免无谓的操作;除非业务需要针对聚合函数的结果进行过滤。
除此之外,理解 SQL 的逻辑执行顺序还可以帮助我们避免一些常见的错误,例如以下语句:
-- 错误示例
SELECT emp_name AS empname
FROM employee
WHERE empname ='张飞';
该语句的错误在于 WHERE 条件中引用了列别名;从上面的逻辑顺序可以看出,执行 WHERE 条件时还没有执行 SELECT 子句,也就没有生成字段的别名。
另外一个需要注意的操作就是 GROUP BY,例如:
-- GROUP BY 错误示例
SELECT dept_id, emp_name, AVG(salary)
FROM employee
GROUP BY dept_id;
由于经过 GROUP BY 处理之后结果集只保留了分组字段和聚合函数的结果,示例中的 emp_name 字段已经不存在;从业务逻辑上来说,按照部门分组统计之后再显示某个员工的姓名没有意义。如果需要同时显示员工信息和所在部门的汇总,可以使用窗口函数。扩展:SQL 语法速成手册
?如果使用了 GROUP BY 分组,之后的 SELECT、ORDER BY 等只能引用分组字段或者聚合函数;否则,可以引用 FROM 和 JOIN 表中的任何字段。
还有一些逻辑问题可能不会直接导致查询出错,但是会返回不正确的结果;例如外连接查询中的 ON 和 WHERE 条件。以下是一个左外连接查询的示例:
SELECT e.emp_name, d.dept_name
FROM employee e
LEFT JOIN department d ON (e.dept_id = d.dept_id)
WHERE e.emp_name ='张飞';
emp_name|dept_name|
--------|---------|
张飞 |行政管理部|
SELECT e.emp_name, d.dept_name
FROM employee e
LEFT JOIN department d ON (e.dept_id = d.dept_id AND e.emp_name ='张飞');
emp_name|dept_name|
--------|---------|
刘备 | [NULL]|
关羽 | [NULL]|
张飞 |行政管理部|
诸葛亮 | [NULL]|
...
第一个查询在 ON 子句中指定了连接的条件,同时通过 WHERE 子句找出了“张飞”的信息。
第二个查询将所有的过滤条件都放在 ON 子句中,结果返回了所有的员工信息。这是因为左外连接会返回左表中的全部数据,即使 ON 子句中指定了员工姓名也不会生效;而 WHERE 条件在逻辑上是对连接操作之后的结果进行过滤。
总结
SQL 优化本质上是了解优化器的的工作原理,并且为此创建合适的索引和正确的语句;同时,当优化器不够智能的时候,手动让它智能。
来源:blog.csdn.net/horses/article/details/105695431
题外话: 目前小哈正在个人博客(新搭建的网站,域名就是犬小哈的拼音) www.quanxiaoha.com 上更新《Go语言教程》,毕竟Go自带天然的并发优势,后端的同学还是要学一下的,这个教程系列小哈会一直更新下去,目前已经更新到 Go语言的基础语法了,欢迎小伙伴们访问哦~
END
有热门推荐?
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)
