
干货 | 百度实习算法岗面试题分享!

问题1:LR推导目标函数并求梯度
逻辑回归损失函数及梯度推导公式如下:

求导:
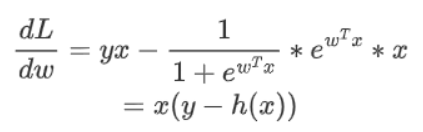

问题2:GBDT和XGBOOST差别
1、利用二阶信息;
2、处理缺失值;
3、弱分类器选择;
4、列抽样和行抽样;
5、正则项做预剪枝;
6、并行化处理(特征排序等)。
问题3:Batch Normalization 缺点
batch太小,会造成波动大;对于文本数据,不同有效长度问题;测试集上两个数据均值和方差差别很大就不合适了
附:LN是对一个样本的一个时间步上的数据进行减均除标准差,然后再回放(参数学习)对应到普通线性回归就是一层节点求均除标准差。
问题4:分词如何做
基于规则(超大词表);基于统计(两字同时出现越多,就越可能是词);基于网络LSTM+CRF词性标注,也可以分词。
问题5:Adam缺点
后期梯度很小,几乎不动了,没有SGD好,前期快是优点;泛化能力不强。
问题6:各类激活函数优缺点
常见的激活函数有:Sigmoid、Tanh、ReLU、Leaky ReLU
Sigmoid函数:
特点:它能够把输入的连续实值变换为0和1之间的输出,特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1。
缺点:
缺点1:在深度神经网络中梯度反向传递时导致梯度消失,其中梯度爆炸发生的概率非常小,而梯度消失发生的概率比较大。
缺点2:Sigmoid 的 output不是0均值(即zero-centered)。
缺点3:其解析式中含有幂运算,计算机求解时相对来讲比较耗时。对于规模比较大的深度网络,这会较大地增加训练时间。
Tanh函数:
特点:它解决了Sigmoid函数的不是zero-centered输出问题,收敛速度比sigmoid要快,然而,梯度消失(gradient vanishing)的问题和幂运算的问题仍然存在。
ReLU函数:
特点:
1.ReLu函数是利用阈值来进行因变量的输出,因此其计算复杂度会比剩下两个函数低(后两个函数都是进行指数运算)
2.ReLu函数的非饱和性可以有效地解决梯度消失的问题,提供相对宽的激活边界。
3.ReLU的单侧抑制提供了网络的稀疏表达能力。
ReLU的局限性:在于其训练过程中会导致神经元死亡的问题。
这是由于函数f(x)=max(0,x)导致负梯度在经过该ReLU单元时被置为0,且在之后也不被任何数据激活,即流经该神经元的梯度永远为0,不对任何数据产生响应。在实际训练中,如果学习率(Learning Rate)设置较大,会导致超过一定比例的神经元不可逆死亡,进而参数梯度无法更新,整个训练过程失败。
Leaky ReLu函数:
LReLU与ReLU的区别在于, 当z<0时其值不为0,而是一个斜率为a的线性函数,一般a为一个很小的正常数, 这样既实现了单侧抑制,又保留了部分负梯度信息以致不完全丢失。但另一方面,a值的选择增加了问题难度,需要较强的人工先验或多次重复训练以确定合适的参数值。
基于此,参数化的PReLU(Parametric ReLU)应运而生。它与LReLU的主要区别是将负轴部分斜率a作为网络中一个可学习的参数,进行反向传播训练,与其他含参数网络层联合优化。而另一个LReLU的变种增加了“随机化”机制,具体地,在训练过程中,斜率a作为一个满足某种分布的随机采样;测试时再固定下来。Random ReLU(RReLU)在一定程度上能起到正则化的作用。
ELU函数:
ELU函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的,而且这部分输出还具有一定的抗干扰能力。这样可以消除ReLU死掉的问题,不过还是有梯度饱和和指数运算的问题。
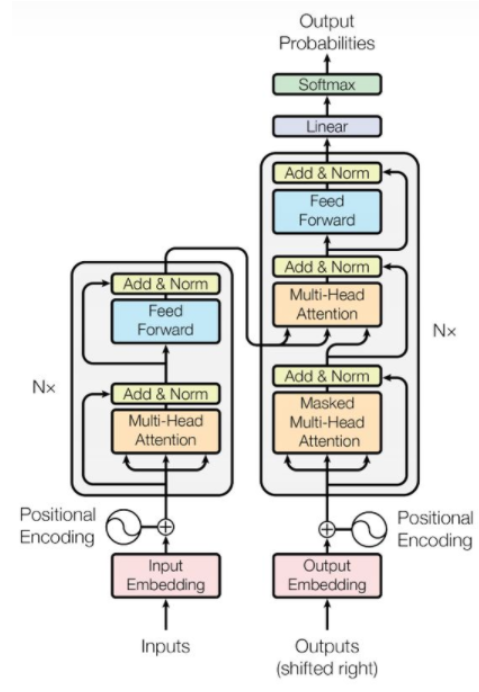
问题7:画一下Transformer结构图
问题8:word2vector负采样时为什么要对频率做3/4次方?
在保证高频词容易被抽到的大方向下,通过权重3/4次幂的方式,适当提升低频词、罕见词被抽到的概率。如果不这么做,低频词,罕见词很难被抽到,以至于不被更新到对应Embedding。

— 推荐阅读 — 最新大厂面试题
干货资料
AI开源项目论文
NLP ( 自然语言处理 )
CV(计算机视觉)
推荐
戳↓↓“阅读原文”领取PDF!