
阿里注册了新公司京西,用 Python 看看网友怎么说

文 | 野客
来源:Python 技术「ID: pythonall」

8 月 13 日,阿里巴巴因注册新公司京西上了微博热搜,不知道东哥此时有没有收到消息,如果东哥看到新闻估计内心会有一万匹草泥马飘过。。。

阿里注册京西这个名字是要搞事情还是常规操作,这里不做揣度与分析,本文我们使用 Python 爬取微博评论看看网友怎么说。
实现
要进行微博评论爬取,我们需要先选好目标,这里我们选择该热搜话题下最热门的一条微博,如下所示:
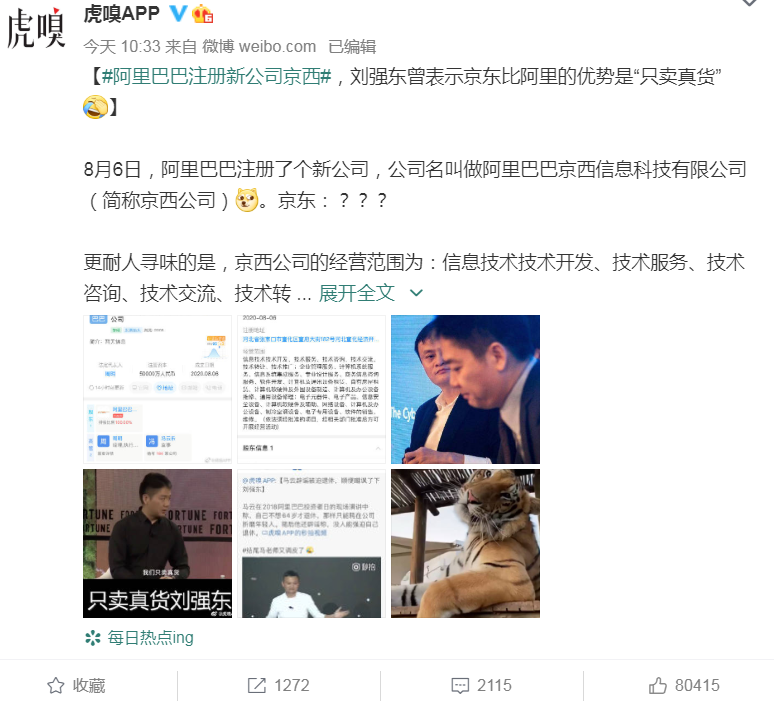
爬取目标选好了之后,我们再接着看爬取的实现。
首先介绍一下微博的主要展现形式,共有如下三种:
网页版(http://weibo.com) 手机端(http://m.weibo.cn) 移动端(http://weibo.cn)
三种展现形式中移动端爬取相对容易一些,这里我们就从移动端下手,首先在浏览器中输入地址 http://weibo.cn 进行访问,如下图所示:
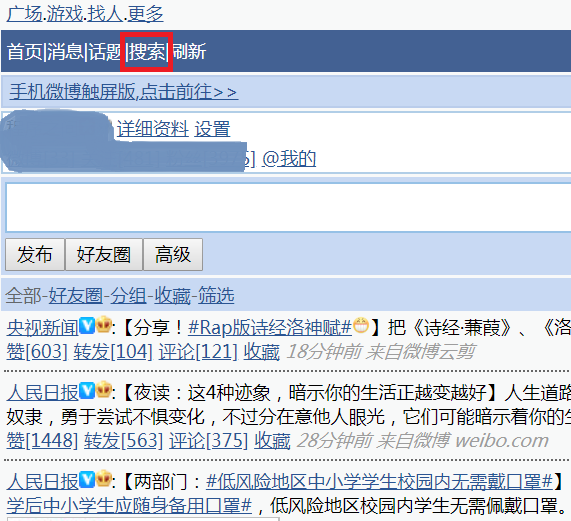
我们可以看出移动端在 PC 浏览器上的展现形式是比较丑陋的,当然这个并不影响我们的爬取实现,因为我们也无需关心页面美丑的问题,接着我们点击上图中的搜索,之后进到如下页面:
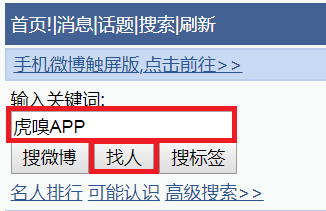
我们在关键词输入框输入刚才那条微博博主的名字,再点击找人按钮,点击之后,我们就可以搜到微博的博主了,如下图所示:
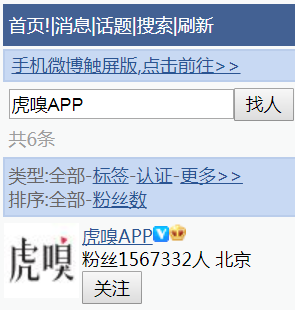
我们接着点击博主名字进入其主页并找到那条微博,如下图所示:
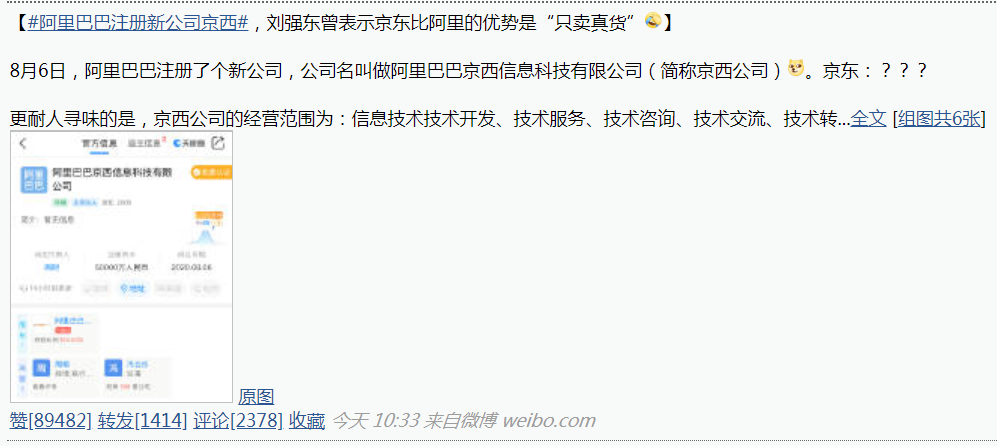
此时,我们打开浏览器的开发者工具并选择 Network,然后点击评论,如下图所示:
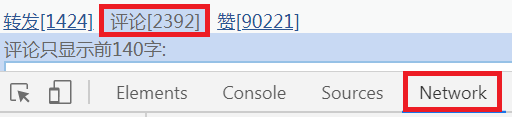
因为评论内容较多,查看更多内容是需要翻页的,我们点下页看一下其具体请求,如下图所示:
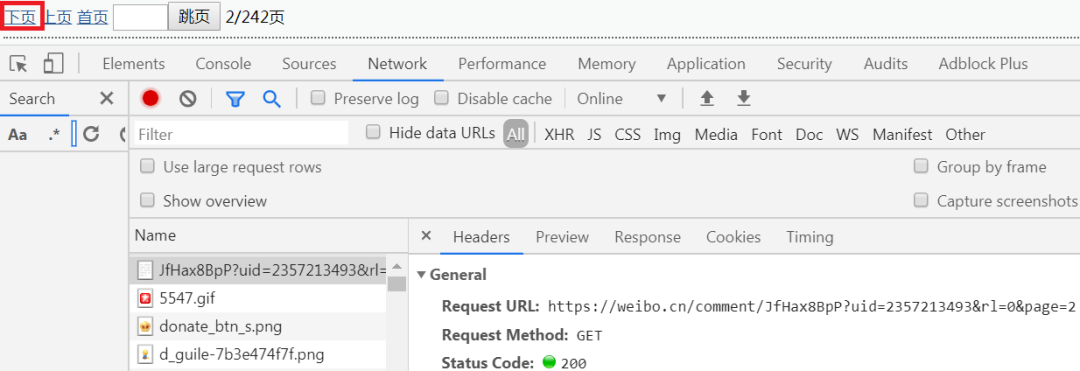
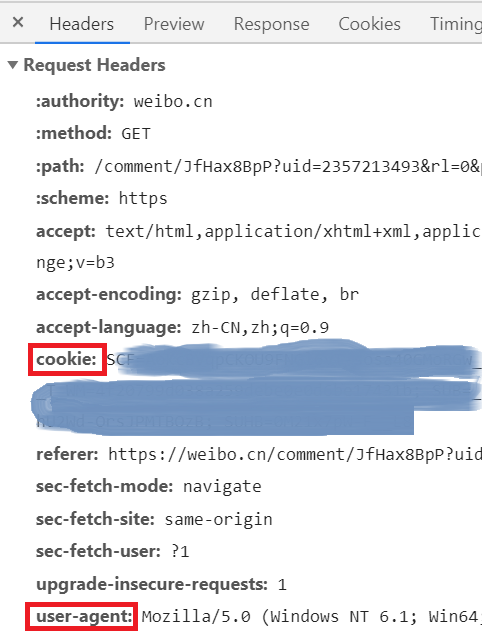
上图中的 Request URL 中的 page 参数前面是固定的,page 是页号,爬取时我们需要用到的就是这个 URL,除此之外,我们还需要用到 cookie 和 user-agent 参数,在下面的 Request Headers 中就可以找到,如下图所示:
准备工作做好之后,我们就可以爬取评论了,主要代码实现如下:
# 爬取一页评论内容
def get_one_page(url):
headers = {
'User-agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3880.4 Safari/537.36',
'Host' : 'weibo.cn',
'Accept' : 'application/json, text/plain, */*',
'Accept-Language' : 'zh-CN,zh;q=0.9',
'Accept-Encoding' : 'gzip, deflate, br',
'Cookie' : '自己的Cookie',
'DNT' : '1',
'Connection' : 'keep-alive'
}
# 获取网页 html
response = requests.get(url, headers = headers, verify=False)
# 爬取成功
if response.status_code == 200:
# 返回值为 html 文档,传入到解析函数当中
return response.text
return None
# 解析保存评论信息
def save_one_page(html):
comments = re.findall('(.*?)', html)
for comment in comments[1:]:
result = re.sub('<.*?>', '', comment)
if '回复@' not in result:
with open('aljx.txt', 'a+', encoding='utf-8') as fp:
fp.write(result)
最终,我们将评论信息爬取后存到了 txt 文件中。
接下来我们把评论信息做成词云看一下,词云的生成之前也做过,这里不再多说了,看一下主要的代码实现:
def jieba_():
stop_words = []
with open('stop_words.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
content = open('aljx.txt', 'rb').read()
# jieba 分词
word_list = jieba.cut(content)
words = []
for word in word_list:
if word not in stop_words:
words.append(word)
global word_cloud
# 用逗号隔开词语
word_cloud = ','.join(words)
def cloud():
# 打开词云背景图
cloud_mask = np.array(Image.open('bg.png'))
# 定义词云的一些属性
wc = WordCloud(
# 背景图分割颜色为白色
background_color='white',
# 背景图样
mask=cloud_mask,
# 显示最大词数
max_words=300,
# 显示中文
font_path='./fonts/simhei.ttf',
# 最大尺寸
max_font_size=100
)
global word_cloud
# 词云函数
x = wc.generate(word_cloud)
# 生成词云图片
image = x.to_image()
# 展示词云图片
image.show()
# 保存词云图片
wc.to_file('cloud.png')
看一下词云效果图:

总结
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【代码获取方式】