
Android中GC的触发时机和条件
本文分析基于Android R(11)源码
Java对象的创建由Allocator负责,回收由Collector负责。从Android O开始,对于前台应用默认的GC Collector是CC(Concurrent Copying) Collector,与之相匹配的Allocator则是Region-based Bump Pointer Allocator(with TLAB)。
本文不打算讨论CC Collector和Region TLAB的细节和实现,一是因为这些内容受众较少,二是因为我自己还在慢慢摸索和吃透其中的细节,可能日后会专门成文介绍他们。
除去繁杂的细节介绍,本文希望回答一个简单的问题:
对前台应用而言,GC到底会在何时触发?
art/runtime/gc/gc_cause.h
25 // What caused the GC?
26 enum GcCause {
27 // Invalid GC cause used as a placeholder.
28 kGcCauseNone,
29 // GC triggered by a failed allocation. Thread doing allocation is blocked waiting for GC before
30 // retrying allocation.
31 kGcCauseForAlloc,
32 // A background GC trying to ensure there is free memory ahead of allocations.
33 kGcCauseBackground,
34 // An explicit System.gc() call.
35 kGcCauseExplicit,
36 // GC triggered for a native allocation when NativeAllocationGcWatermark is exceeded.
37 // (This may be a blocking GC depending on whether we run a non-concurrent collector).
38 kGcCauseForNativeAlloc,
39 // GC triggered for a collector transition.
40 kGcCauseCollectorTransition,
41 // Not a real GC cause, used when we disable moving GC (currently for GetPrimitiveArrayCritical).
42 kGcCauseDisableMovingGc,
43 // Not a real GC cause, used when we trim the heap.
44 kGcCauseTrim,
45 // Not a real GC cause, used to implement exclusion between GC and instrumentation.
46 kGcCauseInstrumentation,
47 // Not a real GC cause, used to add or remove app image spaces.
48 kGcCauseAddRemoveAppImageSpace,
49 // Not a real GC cause, used to implement exclusion between GC and debugger.
50 kGcCauseDebugger,
51 // GC triggered for background transition when both foreground and background collector are CMS.
52 kGcCauseHomogeneousSpaceCompact,
53 // Class linker cause, used to guard filling art methods with special values.
54 kGcCauseClassLinker,
55 // Not a real GC cause, used to implement exclusion between code cache metadata and GC.
56 kGcCauseJitCodeCache,
57 // Not a real GC cause, used to add or remove system-weak holders.
58 kGcCauseAddRemoveSystemWeakHolder,
59 // Not a real GC cause, used to prevent hprof running in the middle of GC.
60 kGcCauseHprof,
61 // Not a real GC cause, used to prevent GetObjectsAllocated running in the middle of GC.
62 kGcCauseGetObjectsAllocated,
63 // GC cause for the profile saver.
64 kGcCauseProfileSaver,
65 // GC cause for running an empty checkpoint.
66 kGcCauseRunEmptyCheckpoint,
67 };
根据GcCause可知,可以触发GC的条件还是很多的。对于开发者而言,常见的是其中三种:
GcCauseForAlloc:通过new分配新对象时,堆中剩余空间(普通应用默认上限为256M,声明largeHeap的应用为512M)不足,因此需要先进行GC。这种情况会导致当前线程阻塞。 GcCauseExplicit:当应用调用系统API System.gc()时,会产生一次GC动作。 GcCauseBackground:后台GC,这里的“后台”并不是指应用切到后台才会执行的GC,而是GC在运行时基本不会影响其他线程的执行,所以也可以理解为并发GC。相比于前两种GC,后台GC出现的更多也更加隐秘,因此值得详细介绍。下文讲述的全是这种GC。
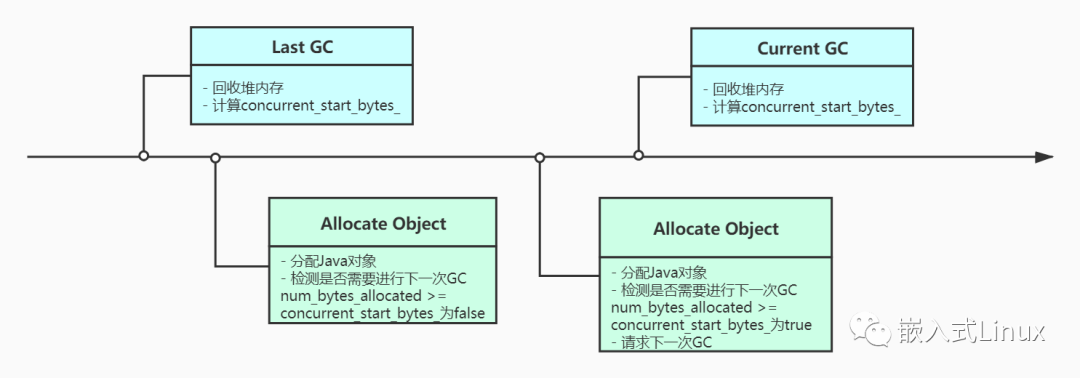
Java堆的实际大小起起伏伏,影响的因素无非是分配和回收。分配的过程是离散且频繁的,它来自于不同的工作线程,而且可能每次只分配一小块区域。回收的过程则是统一且偶发的,它由HeapTaskDaemon线程执行,在GC的多个阶段中都采用并发算法,因此不会暂停工作线程(实际上会暂停很短一段时间)。
当我们在Java代码中通过new分配对象时,虚拟机会调用AllocObjectWithAllocator来执行真实的分配。在每一次成功分配Java对象后,都会去检测是否需要进行下一次GC,这就是GcCauseBackground GC的触发时机。
art/runtime/gc/heap-inl.h
44 template <bool kInstrumented, bool kCheckLargeObject, typename PreFenceVisitor>
45 inline mirror::Object* Heap::AllocObjectWithAllocator(Thread* self,
46 ObjPtr klass,
47 size_t byte_count,
48 AllocatorType allocator,
49 const PreFenceVisitor& pre_fence_visitor) {
...
243 // IsGcConcurrent() isn't known at compile time so we can optimize by not checking it for
244 // the BumpPointer or TLAB allocators. This is nice since it allows the entire if statement to be
245 // optimized out. And for the other allocators, AllocatorMayHaveConcurrentGC is a constant since
246 // the allocator_type should be constant propagated.
247 if (AllocatorMayHaveConcurrentGC(allocator) && IsGcConcurrent()) {
248 // New_num_bytes_allocated is zero if we didn't update num_bytes_allocated_.
249 // That's fine.
250 CheckConcurrentGCForJava(self, new_num_bytes_allocated, &obj); <===================== This line
251 }
252 VerifyObject(obj);
253 self->VerifyStack();
254 return obj.Ptr();
255 }
467 inline void Heap::CheckConcurrentGCForJava(Thread* self,
468 size_t new_num_bytes_allocated,
469 ObjPtr* obj) {
470 if (UNLIKELY(ShouldConcurrentGCForJava(new_num_bytes_allocated))) { <======================= This line
471 RequestConcurrentGCAndSaveObject(self, false /* force_full */, obj);
472 }
473 }
460 inline bool Heap::ShouldConcurrentGCForJava(size_t new_num_bytes_allocated) {
461 // For a Java allocation, we only check whether the number of Java allocated bytes excceeds a
462 // threshold. By not considering native allocation here, we (a) ensure that Java heap bounds are
463 // maintained, and (b) reduce the cost of the check here.
464 return new_num_bytes_allocated >= concurrent_start_bytes_; <======================== This line
465 }
466
触发的条件需要满足一个判断,如果new_num_bytes_allocated(所有已分配的字节数,包括此次新分配的对象) >= concurrent_start_bytes_(下一次GC触发的阈值),那么就请求一次新的GC。new_num_bytes_alloated是当前分配时计算的,concurrent_start_bytes_是上一次GC结束时计算的。以下将分别介绍这两个值的计算过程和背后的设计思想。
1. new_num_bytes_allocated的计算过程
art/runtime/gc/heap-inl.h
44 template <bool kInstrumented, bool kCheckLargeObject, typename PreFenceVisitor>
45 inline mirror::Object* Heap::AllocObjectWithAllocator(Thread* self,
46 ObjPtr klass,
47 size_t byte_count,
48 AllocatorType allocator,
49 const PreFenceVisitor& pre_fence_visitor) {
...
83 size_t new_num_bytes_allocated = 0;
84 {
85 // Do the initial pre-alloc
86 pre_object_allocated();
...
107 if (IsTLABAllocator(allocator)) {
108 byte_count = RoundUp(byte_count, space::BumpPointerSpace::kAlignment);
109 }
110 // If we have a thread local allocation we don't need to update bytes allocated.
111 if (IsTLABAllocator(allocator) && byte_count <= self->TlabSize()) {
112 obj = self->AllocTlab(byte_count);
113 DCHECK(obj != nullptr) << "AllocTlab can't fail";
114 obj->SetClass(klass);
115 if (kUseBakerReadBarrier) {
116 obj->AssertReadBarrierState();
117 }
118 bytes_allocated = byte_count;
119 usable_size = bytes_allocated;
120 no_suspend_pre_fence_visitor(obj, usable_size);
121 QuasiAtomic::ThreadFenceForConstructor();
122 } else if (
123 !kInstrumented && allocator == kAllocatorTypeRosAlloc &&
124 (obj = rosalloc_space_->AllocThreadLocal(self, byte_count, &bytes_allocated)) != nullptr &&
125 LIKELY(obj != nullptr)) {
126 DCHECK(!is_running_on_memory_tool_);
127 obj->SetClass(klass);
128 if (kUseBakerReadBarrier) {
129 obj->AssertReadBarrierState();
130 }
131 usable_size = bytes_allocated;
132 no_suspend_pre_fence_visitor(obj, usable_size);
133 QuasiAtomic::ThreadFenceForConstructor();
134 } else {
135 // Bytes allocated that includes bulk thread-local buffer allocations in addition to direct
136 // non-TLAB object allocations.
137 size_t bytes_tl_bulk_allocated = 0u;
138 obj = TryToAllocatefalse>(self, allocator, byte_count, &bytes_allocated,
139 &usable_size, &bytes_tl_bulk_allocated);
140 if (UNLIKELY(obj == nullptr)) {
141 // AllocateInternalWithGc can cause thread suspension, if someone instruments the
142 // entrypoints or changes the allocator in a suspend point here, we need to retry the
143 // allocation. It will send the pre-alloc event again.
144 obj = AllocateInternalWithGc(self,
145 allocator,
146 kInstrumented,
147 byte_count,
148 &bytes_allocated,
149 &usable_size,
150 &bytes_tl_bulk_allocated,
151 &klass);
152 if (obj == nullptr) {
153 // The only way that we can get a null return if there is no pending exception is if the
154 // allocator or instrumentation changed.
155 if (!self->IsExceptionPending()) {
156 // Since we are restarting, allow thread suspension.
157 ScopedAllowThreadSuspension ats;
158 // AllocObject will pick up the new allocator type, and instrumented as true is the safe
159 // default.
160 return AllocObject</*kInstrumented=*/true>(self,
161 klass,
162 byte_count,
163 pre_fence_visitor);
164 }
165 return nullptr;
166 }
167 }
168 DCHECK_GT(bytes_allocated, 0u);
169 DCHECK_GT(usable_size, 0u);
170 obj->SetClass(klass);
171 if (kUseBakerReadBarrier) {
172 obj->AssertReadBarrierState();
173 }
174 if (collector::SemiSpace::kUseRememberedSet &&
175 UNLIKELY(allocator == kAllocatorTypeNonMoving)) {
176 // (Note this if statement will be constant folded away for the fast-path quick entry
177 // points.) Because SetClass() has no write barrier, the GC may need a write barrier in the
178 // case the object is non movable and points to a recently allocated movable class.
179 WriteBarrier::ForFieldWrite(obj, mirror::Object::ClassOffset(), klass);
180 }
181 no_suspend_pre_fence_visitor(obj, usable_size);
182 QuasiAtomic::ThreadFenceForConstructor();
183 if (bytes_tl_bulk_allocated > 0) {
184 size_t num_bytes_allocated_before =
185 num_bytes_allocated_.fetch_add(bytes_tl_bulk_allocated, std::memory_order_relaxed);
186 new_num_bytes_allocated = num_bytes_allocated_before + bytes_tl_bulk_allocated;
187 // Only trace when we get an increase in the number of bytes allocated. This happens when
188 // obtaining a new TLAB and isn't often enough to hurt performance according to golem.
189 if (region_space_) {
190 // With CC collector, during a GC cycle, the heap usage increases as
191 // there are two copies of evacuated objects. Therefore, add evac-bytes
192 // to the heap size. When the GC cycle is not running, evac-bytes
193 // are 0, as required.
194 TraceHeapSize(new_num_bytes_allocated + region_space_->EvacBytes());
195 } else {
196 TraceHeapSize(new_num_bytes_allocated);
197 }
198 }
199 }
200 }
...
243 // IsGcConcurrent() isn't known at compile time so we can optimize by not checking it for
244 // the BumpPointer or TLAB allocators. This is nice since it allows the entire if statement to be
245 // optimized out. And for the other allocators, AllocatorMayHaveConcurrentGC is a constant since
246 // the allocator_type should be constant propagated.
247 if (AllocatorMayHaveConcurrentGC(allocator) && IsGcConcurrent()) {
248 // New_num_bytes_allocated is zero if we didn't update num_bytes_allocated_.
249 // That's fine.
250 CheckConcurrentGCForJava(self, new_num_bytes_allocated, &obj);
251 }
...
255 }
AllocObjectWithAllocator的实际分配可以分为三条分支,但如果限定为Region-based Bump Pointer Allocator,则只剩两条分支:
如果当前线程TLAB区域的剩余空间可以容纳下这次分配的对象,则在TLAB区域中直接分配。分配算法采用Bump Pointer的方式,仅仅更新已分配区域的游标,简单高效。
art/runtime/thread-inl.h
307 inline mirror::Object* Thread::AllocTlab(size_t bytes) {
308 DCHECK_GE(TlabSize(), bytes);
309 ++tlsPtr_.thread_local_objects;
310 mirror::Object* ret = reinterpret_cast
311 tlsPtr_.thread_local_pos += bytes;
312 return ret;
313 }在这种情况下,new_num_bytes_allocated为0,表明Java堆的已使用区域并没有增大。这是因为TLAB在创建之初,它的大小已经计入了num_bytes_allocated_,所以这次虽然分配了新的对象,但num_bytes_allocated_没必要增加。
那么紧接着就来了一个问题:为什么TLAB在创建之初就要将大小计入num_bytes_allocated_呢?可是此时TLAB明明还没有被使用。这实际上是一个空间换时间的策略。以下是当时这笔改动的commit message,通过事先将大小计入num_bytes_allocated_从而不必要每次分配都更新它,减少针对num_bytes_allocated_的原子操作,提高性能。代价就是会导致num_bytes_allocated_略大于真实使用的字节数。
[Commit Message]
Faster TLAB allocator.
New TLAB allocator doesn't increment bytes allocated until we allocate
a new TLAB. This increases allocation performance by avoiding a CAS.
MemAllocTest:
Before GSS TLAB: 3400ms.
After GSS TLAB: 2750ms.
Bug: 9986565
Change-Id: I1673c27555330ee90d353b98498fa0e67bd57fad
Author: mathieuc@google.com
Date: 2014-07-12 05:18如果当前线程TLAB区域的剩余空间无法容纳下这次分配的对象,则为当前线程创建一个新的TLAB。在这种情况下,新分配出来的TLAB大小需要计入num_bytes_allocated_,因此new_num_bytes_allocated = num_bytes_allocated_before + bytes_tl_bulk_allocated。
2. concurrent_start_bytes_的计算过程
art/runtime/gc/heap.cc
2573 collector::GcType Heap::CollectGarbageInternal(collector::GcType gc_type,
2574 GcCause gc_cause,
2575 bool clear_soft_references) {
...
2671 collector->Run(gc_cause, clear_soft_references || runtime->IsZygote());
2672 IncrementFreedEver();
2673 RequestTrim(self);
2674 // Collect cleared references.
2675 SelfDeletingTask* clear = reference_processor_->CollectClearedReferences(self);
2676 // Grow the heap so that we know when to perform the next GC.
2677 GrowForUtilization(collector, bytes_allocated_before_gc);
2678 LogGC(gc_cause, collector);
2679 FinishGC(self, gc_type);
2680 // Actually enqueue all cleared references. Do this after the GC has officially finished since
2681 // otherwise we can deadlock.
2682 clear->Run(self);
2683 clear->Finalize();
2684 // Inform DDMS that a GC completed.
2685 Dbg::GcDidFinish();
2686
2687 old_native_bytes_allocated_.store(GetNativeBytes());
2688
2689 // Unload native libraries for class unloading. We do this after calling FinishGC to prevent
2690 // deadlocks in case the JNI_OnUnload function does allocations.
2691 {
2692 ScopedObjectAccess soa(self);
2693 soa.Vm()->UnloadNativeLibraries();
2694 }
2695 return gc_type;
2696 }
CollectGarbageInternal是HeapTaskDaemon线程执行GC时需要调用的函数。其中2671行将执行真正的GC,而concurrent_start_bytes_的计算则在2677行的GrowForUtilization函数中。
art/runtime/gc/heap.cc
3514 void Heap::GrowForUtilization(collector::GarbageCollector* collector_ran,
3515 size_t bytes_allocated_before_gc) {
3516 // We know what our utilization is at this moment.
3517 // This doesn't actually resize any memory. It just lets the heap grow more when necessary.
3518 const size_t bytes_allocated = GetBytesAllocated();
3519 // Trace the new heap size after the GC is finished.
3520 TraceHeapSize(bytes_allocated);
3521 uint64_t target_size, grow_bytes;
3522 collector::GcType gc_type = collector_ran->GetGcType();
3523 MutexLock mu(Thread::Current(), process_state_update_lock_);
3524 // Use the multiplier to grow more for foreground.
3525 const double multiplier = HeapGrowthMultiplier();
3526 if (gc_type != collector::kGcTypeSticky) {
3527 // Grow the heap for non sticky GC.
3528 uint64_t delta = bytes_allocated * (1.0 / GetTargetHeapUtilization() - 1.0);
3529 DCHECK_LE(delta, std::numeric_limits<size_t>::max()) << "bytes_allocated=" << bytes_allocated
3530 << " target_utilization_=" << target_utilization_;
3531 grow_bytes = std::min(delta, static_cast<uint64_t>(max_free_));
3532 grow_bytes = std::max(grow_bytes, static_cast<uint64_t>(min_free_));
3533 target_size = bytes_allocated + static_cast<uint64_t>(grow_bytes * multiplier);
3534 next_gc_type_ = collector::kGcTypeSticky;
3535 } else {
...
3562 // If we have freed enough memory, shrink the heap back down.
3563 const size_t adjusted_max_free = static_cast<size_t>(max_free_ * multiplier);
3564 if (bytes_allocated + adjusted_max_free < target_footprint) {
3565 target_size = bytes_allocated + adjusted_max_free;
3566 grow_bytes = max_free_;
3567 } else {
3568 target_size = std::max(bytes_allocated, target_footprint);
3569 // The same whether jank perceptible or not; just avoid the adjustment.
3570 grow_bytes = 0;
3571 }
3572 }
3573 CHECK_LE(target_size, std::numeric_limits<size_t>::max());
3574 if (!ignore_target_footprint_) {
3575 SetIdealFootprint(target_size);
...
3585 if (IsGcConcurrent()) {
3586 const uint64_t freed_bytes = current_gc_iteration_.GetFreedBytes() +
3587 current_gc_iteration_.GetFreedLargeObjectBytes() +
3588 current_gc_iteration_.GetFreedRevokeBytes();
3589 // Bytes allocated will shrink by freed_bytes after the GC runs, so if we want to figure out
3590 // how many bytes were allocated during the GC we need to add freed_bytes back on.
3591 CHECK_GE(bytes_allocated + freed_bytes, bytes_allocated_before_gc);
3592 const size_t bytes_allocated_during_gc = bytes_allocated + freed_bytes -
3593 bytes_allocated_before_gc;
3594 // Calculate when to perform the next ConcurrentGC.
3595 // Estimate how many remaining bytes we will have when we need to start the next GC.
3596 size_t remaining_bytes = bytes_allocated_during_gc;
3597 remaining_bytes = std::min(remaining_bytes, kMaxConcurrentRemainingBytes);
3598 remaining_bytes = std::max(remaining_bytes, kMinConcurrentRemainingBytes);
3599 size_t target_footprint = target_footprint_.load(std::memory_order_relaxed);
3600 if (UNLIKELY(remaining_bytes > target_footprint)) {
3601 // A never going to happen situation that from the estimated allocation rate we will exceed
3602 // the applications entire footprint with the given estimated allocation rate. Schedule
3603 // another GC nearly straight away.
3604 remaining_bytes = std::min(kMinConcurrentRemainingBytes, target_footprint);
3605 }
3606 DCHECK_LE(target_footprint_.load(std::memory_order_relaxed), GetMaxMemory());
3607 // Start a concurrent GC when we get close to the estimated remaining bytes. When the
3608 // allocation rate is very high, remaining_bytes could tell us that we should start a GC
3609 // right away.
3610 concurrent_start_bytes_ = std::max(target_footprint - remaining_bytes, bytes_allocated);
3611 }
3612 }
3613 }
concurrent_start_bytes_的计算分为两个步骤:
计算出target_size,一个仅具有指导意义的最大可分配字节数。 根据target_size计算出下一次GC的触发水位concurrent_start_bytes_。
2.1 target_size的计算过程
2.1.1 Sticky GC
kGcTypeSticky是分代GC下的一种GC类型,表示只针对两次GC时间内新分配的对象进行回收,也可以理解为Young-generation GC。如果gc_type为kGcTypeSticky,则执行如下过程:
art/runtime/gc/heap.cc
3562 // If we have freed enough memory, shrink the heap back down.
3563 const size_t adjusted_max_free = static_cast<size_t>(max_free_ * multiplier);
3564 if (bytes_allocated + adjusted_max_free < target_footprint) {
3565 target_size = bytes_allocated + adjusted_max_free;
3566 grow_bytes = max_free_;
3567 } else {
3568 target_size = std::max(bytes_allocated, target_footprint);
3569 // The same whether jank perceptible or not; just avoid the adjustment.
3570 grow_bytes = 0;
3571 }
max_free_的本意是target_size与已分配内存间可允许的最大差异,差异过小会导致GC频繁,差异过大则又会延迟下一次GC的到来,目前很多设备将这个值设为8M,min_free_设为512K。其实针对RAM超过6G的大内存设备,Google建议可以提高min_free_,用空间换时间获取更好的GC性能。multiplier的引入主要是为了优化前台应用,默认的前台multipiler为2,这样可以在下次GC前有更多的空间分配对象。以下是引入multipiler的代码的commit message,增大free的空间自然就降低了利用率。
[Commit Message]
Decrease target utilization for foreground apps.
GC time in FormulaEvaluationActions.EvaluateAndApplyChanges goes from
26.1s to 23.2s. Benchmark score goes down ~50 in
FormulaEvaluationActions.EvaluateAndApplyChanges, and up ~50 in
GenericCalcActions.MemAllocTest.
Bug: 8788501
Change-Id: I412af1205f8b67e70a12237c990231ea62167bc0
Author: mathieuc@google.com
Date: 2014-04-17 03:37
当bytes_allocated + adjusted_max_free < target_footprint时,说明这次GC释放了很多空间,因此可以适当地降低下次GC的触发水位。
如果bytes_allocated + adjusted_max_free ≥ target_footprint,则取target_footprint和bytes_allocated中的较大值作为target_size。
这种情况这次GC释放的空间不多。当target_footprint较大时,即便bytes_allocated逼近target_footprint也不增大target_size,是因为当前GC为Sticky GC(又可理解为Young-generation GC),如果它释放的空间不多,接下来还可以采用Full GC来更彻底地回收。换言之,只有等Full GC回收完,才能决定将GC的水位提升,因为这时已经尝试了所有的回收策略。
当bytes_allocated较大时,说明在GC过程中新申请的对象空间大于GC释放的空间(因为并发,所以申请和释放可以同步进行)。这样一来,最终计算的水位值将会小于bytes_allocated,那岂不是下一次调用new分配对象时必然会阻塞?实则不然。因为不论是target_size还是concurrent_start_bytes_,他们都只有指导意义而无法实际限制堆内存的分配。对于CC Collector而言,唯一限制堆内存分配的只有growth_limit_。不过水位值小于bytes_allocated倒是会使得下一次对象分配成功后立马触发一轮新的GC。
2.1.2 Non-sticky GC
art/runtime/gc/heap.cc
3526 if (gc_type != collector::kGcTypeSticky) {
3527 // Grow the heap for non sticky GC.
3528 uint64_t delta = bytes_allocated * (1.0 / GetTargetHeapUtilization() - 1.0);
3529 DCHECK_LE(delta, std::numeric_limits<size_t>::max()) << "bytes_allocated=" << bytes_allocated
3530 << " target_utilization_=" << target_utilization_;
3531 grow_bytes = std::min(delta, static_cast<uint64_t>(max_free_));
3532 grow_bytes = std::max(grow_bytes, static_cast<uint64_t>(min_free_));
3533 target_size = bytes_allocated + static_cast<uint64_t>(grow_bytes * multiplier);
3534 next_gc_type_ = collector::kGcTypeSticky;
3535 }
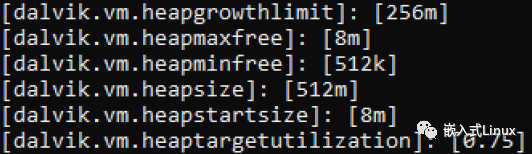
首先会根据目标的利用率计算出新的delta,然后将delta与min_free_和max_free_进行比较,使得最终的grow_bytes落在[min_free_,max_free_]之间。target_size的计算还需考虑multipiler的影响,这样会降低前台应用的堆利用率,从而留有更多空间进行分配(降低GC的频率,代价就是内存资源向前台应用倾斜)。以下是一部手机的堆配置,其中数值可做参考。
2.2 concurrent_start_bytes_的计算
art/runtime/gc/heap.cc
3585 if (IsGcConcurrent()) {
3586 const uint64_t freed_bytes = current_gc_iteration_.GetFreedBytes() +
3587 current_gc_iteration_.GetFreedLargeObjectBytes() +
3588 current_gc_iteration_.GetFreedRevokeBytes();
3589 // Bytes allocated will shrink by freed_bytes after the GC runs, so if we want to figure out
3590 // how many bytes were allocated during the GC we need to add freed_bytes back on.
3591 CHECK_GE(bytes_allocated + freed_bytes, bytes_allocated_before_gc);
3592 const size_t bytes_allocated_during_gc = bytes_allocated + freed_bytes -
3593 bytes_allocated_before_gc;
3594 // Calculate when to perform the next ConcurrentGC.
3595 // Estimate how many remaining bytes we will have when we need to start the next GC.
3596 size_t remaining_bytes = bytes_allocated_during_gc;
3597 remaining_bytes = std::min(remaining_bytes, kMaxConcurrentRemainingBytes);
3598 remaining_bytes = std::max(remaining_bytes, kMinConcurrentRemainingBytes);
3599 size_t target_footprint = target_footprint_.load(std::memory_order_relaxed);
3600 if (UNLIKELY(remaining_bytes > target_footprint)) {
3601 // A never going to happen situation that from the estimated allocation rate we will exceed
3602 // the applications entire footprint with the given estimated allocation rate. Schedule
3603 // another GC nearly straight away.
3604 remaining_bytes = std::min(kMinConcurrentRemainingBytes, target_footprint);
3605 }
3606 DCHECK_LE(target_footprint_.load(std::memory_order_relaxed), GetMaxMemory());
3607 // Start a concurrent GC when we get close to the estimated remaining bytes. When the
3608 // allocation rate is very high, remaining_bytes could tell us that we should start a GC
3609 // right away.
3610 concurrent_start_bytes_ = std::max(target_footprint - remaining_bytes, bytes_allocated);
3611 }
首先需要计算出在GC过程中新分配的对象大小,记为bytes_allocated_during_gc。然后将它与kMinConcurrentRemainingBytes和kMaxConcurrentRemainingBytes进行比较,使得最终的grow_bytes落在[kMinConcurrentRemainingBytes,kMaxConcurrentRemainingBytes]之间。
art/runtime/gc/heap.cc
108 // Minimum amount of remaining bytes before a concurrent GC is triggered.
109 static constexpr size_t kMinConcurrentRemainingBytes = 128 * KB;
110 static constexpr size_t kMaxConcurrentRemainingBytes = 512 * KB;
最终concurrent_start_bytes_的计算如下。之所以需要用target_footprint减去remaining_bytes,是因为在理论意义上,target_footprint_代表当前堆的最大可分配字节数。而由于是同步GC,回收的过程中可能会有其他线程依然在分配。所以为了保证本次GC的顺利进行,需要将这段时间分配的内存空间预留出来。
art/runtime/gc/heap.cc
concurrent_start_bytes_ = std::max(target_footprint - remaining_bytes, bytes_allocated);
不过需要注意的是,上面阐述的理由仅局限在理论意义上,就像target_footprint_和concurrent_start_bytes_只具有指导意义一样。所以即便下一次GC过程中分配的内存超过了预留的空间,也并不会出现内存分配不出来而等待的情况。
