
elasticsearch document的索引过程分析



点击上方蓝色“迈莫coding”,选择“设为星标”
一、预备知识
一、预备知识
1 1.1、索引不可变
看到这篇文章相信大家都知道es是倒排索引,不了解也没关系,在我的另一篇博文中详细分析了es的倒排索引机制。在es的索引过程中为了满足一下特点,落盘的es索引是不可变的。
1 不需要锁。如果从来不需要更新一个索引,就不必担心多个程序同时尝试修改。
2 一旦索引被读入文件系统的缓存(内存),它就一直在那儿,因为不会改变。只要文件系统缓存有足够的空间,大部分的读会直接访问内存而不是磁盘。这有助于性能提升。
3 在索引的声明周期内,所有的其他缓存都可用。它们不需要在每次数据变化了都重建,使文本可以被搜索因为数据不会变。写入单个大的倒排索引,可以压缩数据,较少磁盘IO和需要缓存索引的内存大小。
当然,不可变的索引有它的缺点,首先是它不可变!你不能改变它。如果想要搜索一个新文 档,必须重建整个索引。这不仅严重限制了一个索引所能装下的数据,还有一个索引可以被更新的频次。所以es引入了动态索引。
下一个需要解决的问题是如何在保持不可变好处的同时更新倒排索引。答案是,使用多个索引。不是重写整个倒排索引,而是增加额外的索引反映最近的变化。每个倒排索引都可以按顺序查询,从最老的开始,最后把结果聚合。
Elasticsearch底层依赖的Lucene,引入了 per-segment search 的概念。一个段(segment)是有完整功能的倒排索引,但是现在Lucene中的索引指的是段的集合,再加上提交点(commit point,包括所有段的文件),如图1所示。新的文档,在被写入磁盘的段之前,首先写入内存区的索引缓存。然后再通过fsync将缓存中的段刷新到磁盘上,该段将被打开即段落盘之后开始能被检索。
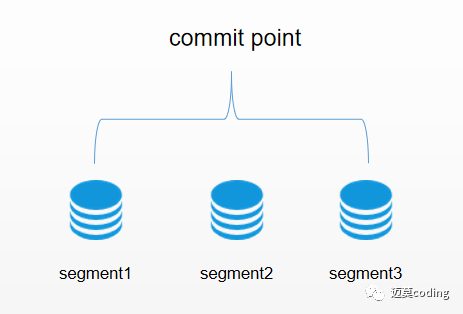
看到这里如果对分段还是有点迷惑,没关系,假如你熟悉java语言,ArrayList这个集合我们都知道是一个动态数组,他的底层数据结构其实就是数组,我们都知道数组是不可变的,ArrayList是动过扩容实现的动态数组。
在这里我们就可以将commit point理解成ArrayList,segment就是一个个小的数组。然后将其组合成ArrayList。假如你知道Java1.8的ConcurrentHashMap的分段锁相信你理解这个分段就很容易了。
在es中“索引”是分片(shard)的集合,在lucene中“索引”从宏观上来说就是es中的一个分片,从微观上来说就是segment的集合。
“document的索引过程”这句话中的这个“索引”,我们可以理解成es为document建立索引的过程。
二、document索引过程
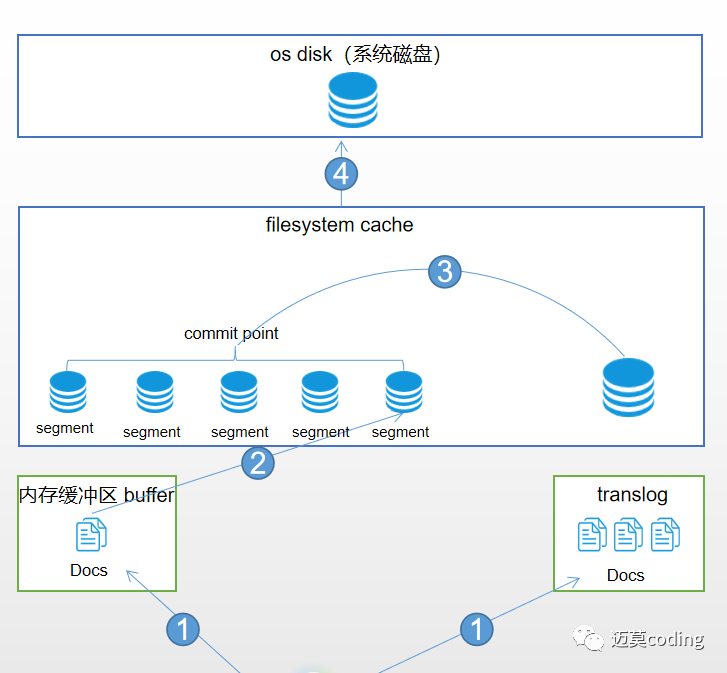
文档被索引的过程如上面所示,大致可以分为 内存缓冲区buffer、translog、filesystem cache、系统磁盘这几个部分,接下来我们梳理一下这个过程。
阶段1:
这个阶段很简单,一个document文档第一步会同时被写进内存缓冲区buffer和translog。
阶段2:
refresh:内存缓冲区的documents每隔一秒会被refresh(刷新)到filesystem cache中的一个新的segment中,segment就是索引的最小单位,此时segment将会被打开供检索。也就是说一旦文档被刷新到文件系统缓存中,其就能被检索使用了。这也是es近实时性(NRT)的关键。后面会详细介绍。
阶段3:
merge:每秒都会有新的segment生成,这将意味着用不了多久segment的数量就会爆炸,每个段都将十分消耗文件句柄、内存、和cpu资源。这将是系统无法忍受的,所以这时,我们急需将零散的segment进行合并。ES通过后台合并段解决这个问题。小段被合并成大段,再合并成更大的段。然后将新的segment打开供搜索,旧的segment删除。
阶段4:
flush:经过阶段3合并后新生成的更大的segment将会被flush到系统磁盘上。这样整个过程就完成了。但是这里留一个包袱就是flush的时机。在后面介绍translog的时候会介绍。
不要着急,接下来我们将以上步骤拆分开来详细分析一下。
1 2.1、近实时化搜索(NRT)
在早起的lucene中,只有当segement被写入到磁盘,该segment才会被打开供搜索,和我们上面所说的当doc被刷新到filesystem cache中生成新的segment就将会被打开。
因为 per-segment search 机制,索引和搜索一个文档之间是有延迟的。新的文档会在几分钟内可以搜索,但是这依然不够快。磁盘是瓶颈。提交一个新的段到磁盘需要 fsync 操作,确保段被物理地写入磁盘,即时电源失效也不会丢失数据。但是 fsync 是昂贵的,它不能在每个文档被索引的时就触发。
所以需要一种更轻量级的方式使新的文档可以被搜索,这意味这移除 fsync 。
位于Elasticsearch和磁盘间的是文件系统缓存。如前所说,在内存索引缓存中的文档被写入新的段,但是新的段首先写入文件系统缓存,这代价很低,之后会被同步到磁盘,这个代价很大。但是一旦一个文件被缓存,它也可以被打开和读取,就像其他文件一样。
在es中每隔一秒写入内存缓冲区的文档就会被刷新到filesystem cache中的新的segment,也就意味着可以被搜索了。这就是ES的NRT——近实时性搜索。
简单介绍一下refresh API
如果你遇到过你新增了doc,但是没检索到,很可能是因为还未自动进行refresh,这是你可以尝试手动刷新
POST /student/_refresh性能优化
在这里我们需要知道一点refresh过程是很消耗性能的。如果你的系统对实时性要求不高,可以通过API控制refresh的时间间隔,但是如果你的新系统很要求实时性,那你就忍受它吧。
如果你对系统的实时性要求很低,我们可以调整refresh的时间间隔,调大一点将会在一定程度上提升系统的性能。
PUT /student{"settings": {"refresh_interval": "30s"}}
1 2.2、合并段——merge
通过每秒自动刷新创建新的段,用不了多久段的数量就爆炸了。有太多的段是一个问题。每个段消费文件句柄,内存,cpu资源。更重要的是,每次搜索请求都需要依次检查每个段。段越多,查询越慢。
ES通过后台合并段解决这个问题。小段被合并成大段,再合并成更大的段。
这是旧的文档从文件系统删除的时候。旧的段不会再复制到更大的新段中。这个过程你不必做什么。当你在索引和搜索时ES会自动处理。
我们再来总结一下段合并的过程。
1 选择一些有相似大小的segment,merge成一个大的segment
2 将新的segment flush到磁盘上去
3 写一个新的commit point,包括了新的segment,并且排除旧的那些segment
4 将新的segment打开供搜索
5 将旧的segment删除
optimize API与性能优化
optimize API 最好描述为强制合并段API。它强制分片合并段以达到指定 max_num_segments 参数。这是为了减少段的数量(通常为1)达到提高搜索性能的目的。
在特定的环境下, optimize API 是有用的。典型的场景是记录日志,这中情况下日志是按照每天,周,月存入索引。旧的索引一般是只可读的,它们是不可能修改的。这种情况下,把每个索引的段降至1是有效的。搜索过程就会用到更少的资源,性能更好:
POST /logstash-2019-10-01/_optimize?max_num_segments=1一般场景下尽量不要手动执行,让它自动默认执行就可以了
1 2.3、容灾与可靠存储
没用 fsync 同步文件系统缓存到磁盘,我们不能确保电源失效,甚至正常退出应用后,数据的安全。为了ES的可靠性,需要确保变更持久化到磁盘。
我们说过一次全提交同步段到磁盘,写提交点,这会列出所有的已知的段。在重启,或重新 打开索引时,ES使用这次提交点决定哪些段属于当前的分片。
当我们通过每秒的刷新获得近实时的搜索,我们依然需要定时地执行全提交确保能从失败中 恢复。但是提交之间的文档怎么办?我们也不想丢失它们。
上面doc索引流程的阶段1,doc分别被写入到内存缓冲区和translog,然后每秒都将会把内存缓冲区的docs刷新到filesystem cache中的新segment,然后众多segment会进行不断的压缩,小段被合并成大段,再合并成更大的段。每次refresh操作后,内存缓冲区的docs被刷新到filesystem cache中的segemnt中,但是tanslog仍然在持续的增大增多。当translog大到一定程度,将会发生一个commit操作也就是全量提交。
详细过程如下:
1、 doc写入内存缓冲区和translog日志文件2、 每隔一秒钟,内存缓冲区中的docs被写入到filesystem cache中新的segment,此时segment被打开并供检索使用3、 内存缓冲区被清空4、 重复1~3,新的segment不断添加,内存缓冲区不断被清空,而translog中的数据不断累加5、 当translog长度达到一定程度的时候,commit操作发生5-1、 内存缓冲区中的docs被写入到filesystem cache中新的segment,打开供检索使用5-2、 内存缓冲区被清空5-3、 一个commit ponit被写入磁盘,标明了所有的index segment5-4、 filesystem cache中的所有index segment file缓存数据,被fsync强行刷到磁盘上5-5、 现有的translog被清空,创建一个新的translog
其实到这里我们发现fsync还是没有被舍弃的,但是我们通过动态索引和translog技术减少了其使用频率,并实现了近实时搜索。其次通过以上步骤我们发现flush操作包括filesystem cache中的segment通过fsync刷新到硬盘以及translog的清空两个过程。es默认每30分钟进行一次flush操作,但是当translog大到一定程度时也会进行flush操作。
对应过程图如下
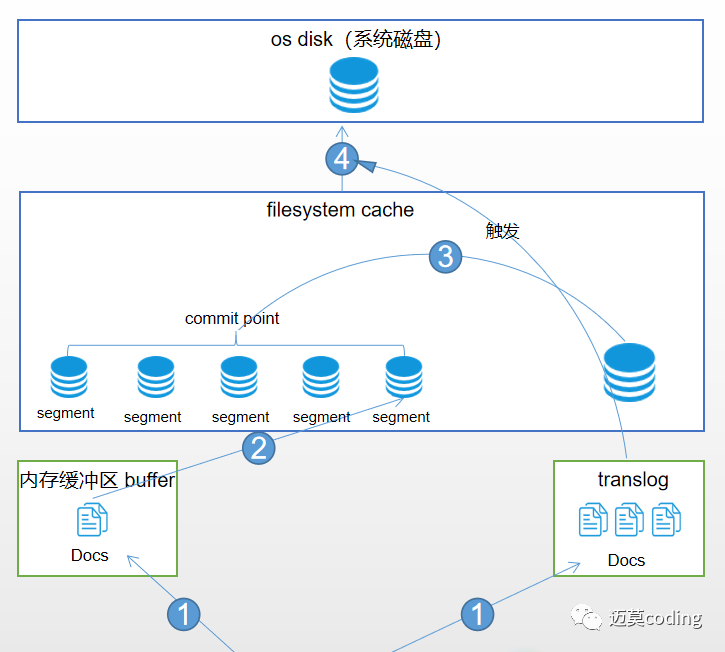
5-5步骤不难发现只有内存缓冲区中的docs全部刷新到filesystem cache中并fsync到硬盘,translog才会被清除,这样就保证了数据不会丢失,因为只要translog存在,我们就能根据translog进行数据的恢复。
简单介绍一下flush API
手动flush如下所示,但是并不建议使用。但是当要重启或关闭一个索引,flush该索引是很有用的。当ES尝试恢复或者重新打开一个索引时,它必须重放所有事务日志中的操作,所以日志越小,恢复速度越快。
POST /student/_flush三、更新和删除
前面我们说过es的索引是不可变的,那么更新和删除是如何进行的呢?
段是不可变的,所以文档既不能从旧的段中移除,旧的段也不能更新以反映文档最新的版本。相反,每一个提交点包括一个.del文件,包含了段上已经被删除的文档。当一个文档被删除,它实际上只是在.del文件中被标记为删除,依然可以匹配查询,但是最终返回之前会被从结果中删除。
文档的更新操作是类似的:当一个文档被更新,旧版本的文档被标记为删除,新版本的文档在新的段中索引。也许该文档的不同版本都会匹配一个查询,但是更老版本会从结果中删除。
分割线
往期推荐
文章也会持续更新,可以微信搜索「 迈莫coding 」第一时间阅读。每天分享优质文章、大厂经验、大厂面经,助力面试,是每个程序员值得关注的平台。
你点的每个赞,我都认真当成了喜欢