
大嘴巴漫谈数据挖掘——经典案例赏析
和你一起学习大数据,这里是大数据科学

大家好,首先很感谢数据分析网的支持,提供这样一个平台,能够和大家一起分享、交流,今天主要给大家带来3个数据挖掘的经典案例。

一、产品精细化运营之道

运营的核心在于持续性改进,运营分析需要保证数据的精确与一致性;可以容忍一定程度上准确性的偏差。那么,准确和精确有什么区别呢?
准确是指现象或者测量值相对事实之间的离散程度小,也就是我们口语的“接近事实、符合事实”等;精确是指在条件不变的情况下,现象或者测量值能够低离散程度的反复再现,也就是我们口语说的“次次如此、回回一样”等。
下面的CRISP-DM代表了数据挖掘的标准过程。
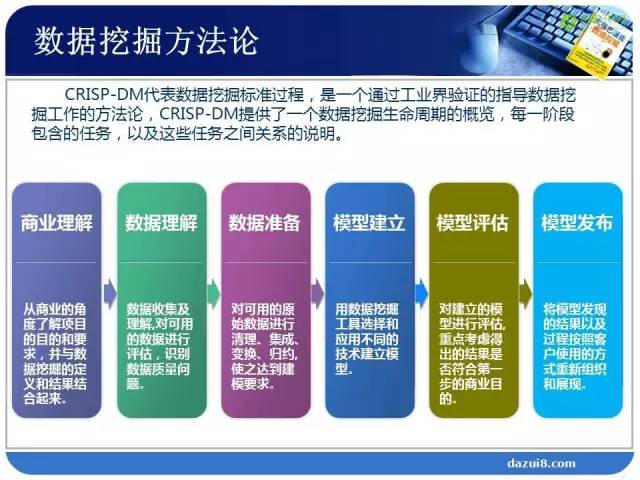
在这个标准过程中最重要的是哪一个环节呢?(讨论ing)
@mountain 所有的业务都是围绕需求来的
@数据哥 需求分析,想清楚怎么干,否则南辕北辙
@fs 只有知道客户需求,才能满足客户的需要
所以最重要的是商业理解。
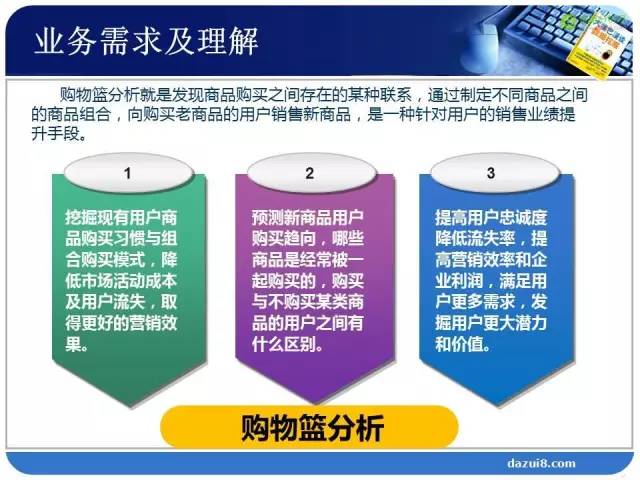
购物篮模型,用一句话来说,就是在合适的时间、合适的地点,通过合适的方式,向合适的人群推荐合适的产品。那么当我们确定了购物篮分析模型的第一目标后,即我们的第一步“商业理解”结束之后,第二步便是“数据理解”。这一步需要将我们的业务模型映射到数据模型,或者换句话说,我们需要什么样的数据来支撑我们的分析目标?我们需要什么样的数据一定要基于我们的分析目标,那么我们来分析下我们的目标。
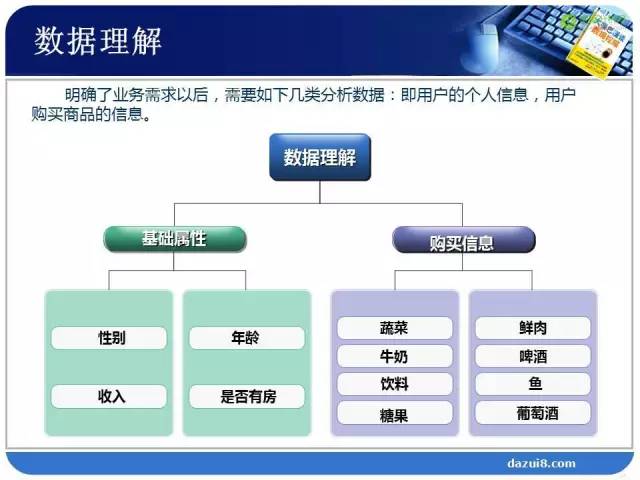
第一个目标是研究我们的商品,找到商品与商品之间的某种联系。研究商品需要什么样的数据呢?消费购物单,就是我们需要超市机构反馈给我们的票单据(小单子),这是我们商品的购买数据。除了商品的购买数据,还需要什么数据?我们除了要研究商品,还要研究消费者。研究消费者需要消费者个人属性数据。(在实际的工作中,根据实际需要,不限于这里列出的数据。)
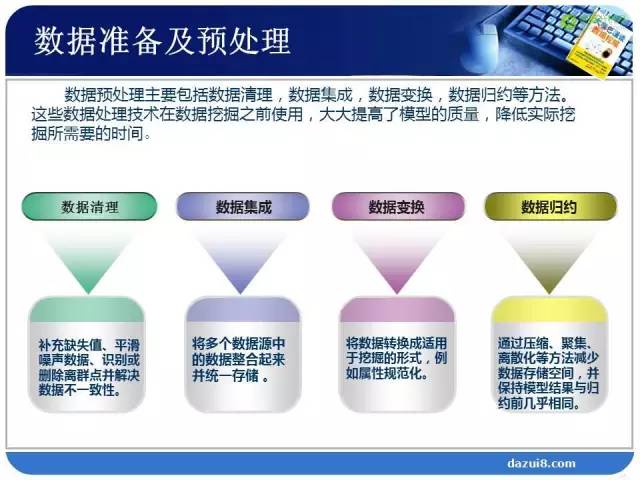
接下来是第三步是“数据准备”。在这个过程中需要理解数据,会用到清理、集成、变换、归约的方法,因为原始数据来自于我们的各种业务平台。
清理:补充缺失值、平滑噪声数据、识别或删除离群点并解决数据不一致性
集成:将多个数据源中的数据整合起来并同意存储
变换:将数据转换为适用于挖掘的形式,例如属性规范化
归约:通过压缩、聚集、离散化等方法减少数据存储空间,并保持模型结果与归约前几乎相同
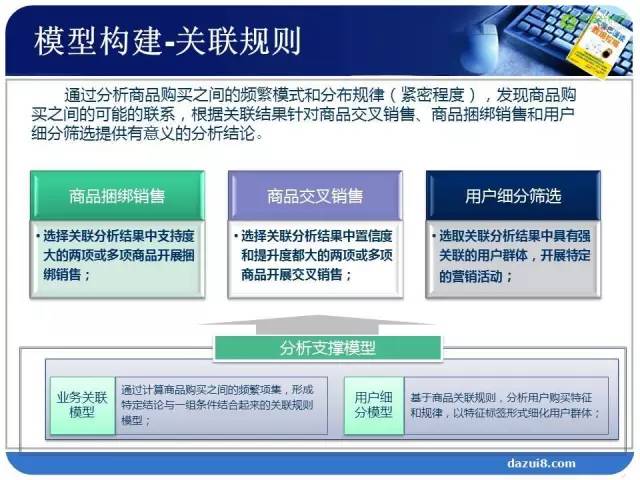
数据准备之后,是数据建模,也就是通过数学的方法来解决业务问题。那么如何把业务问题转化成数据方法呢?
我们的分析目标是找到商品之间的某种联系,这里要用到什么数学方法(业务语言),这句话转化为数学角度来理解,就是找到商品之间某种联系的一种可能性(数据语言)。可能性问题就是概率,概率就是用来量化可能性的问题。
比如:在购买A商品的条件下购买B商品的概率是条件概率,A、B两个商品一起购买的概率是联合概率。

我们最终发现商品之间存在某种联系,就是几个可能性,而这几个可能性就是概率。
一个是联合概率,有购买A商品和购买B商品的概率,这个联合概率我们给它定义一个关联规则算法,叫做支持度。
一个是条件概率,在购买A商品的条件下,又购买了B商品的概率,这个条件概率,我们称之为置信度。支持度越高,置信度越高,那么A、B商品之前的相关性就越强。
在咱们这个概率中或者在数学中,研究相关性还有那些指标?大家要把置信度理解为一个条件概率,严格来说跟置信区间没什么太大关系。研究相关性还有一个相关系数,相关系数的范围是-1到1,绝对值越接近于1,说明相关性越强;绝对值越接近于0,说明相关性越弱。(0,1)之间为正相关,(-1,0)之间为负相关。
正相关和负相关是数学名词,负相关在业务上怎么理解呢?负相关说明A、B这两个商品是互相排斥的,买了A就不会再买B,可以替代。假设A、B这两个商品是互相排斥的,给出两个概率,一个概率是在购买了A商品的前提下购买B商品的概率,一个是没有任何前提条件下直接购买B商品的概率。这两个概率谁大谁小?直接购买的概率大,因为A、B排斥,购买了A会影响购买B,极端情况下,购买了A就不再购买B。支持度和置信度,只能衡量两个商品的正相关,无法衡量负相关。为此我们引入第三个指标,提升度。如果提升度小于1,说明这个两个商品是互相排斥的;如果提升度大于1,说明这个两个商品是互相促进的。提升度等于1,说明A、B相互独立,不存在任何关系。
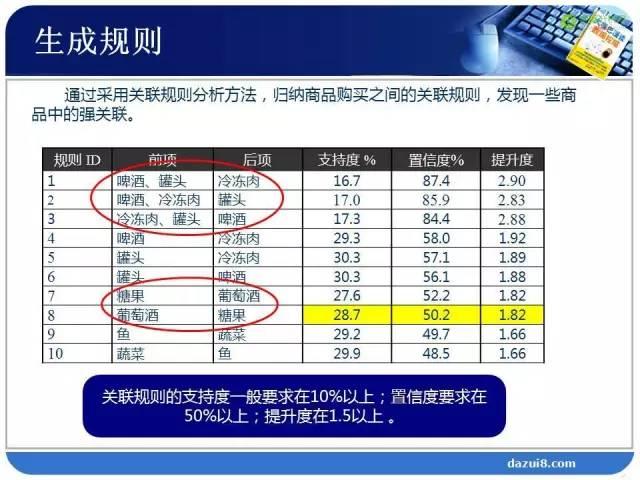 通过以上的分析,最终通过关联规则算法,我们希望支持度和置信度大一些,这里一般会定义一个最小值,这个最小值需要通过业务经验来确定。
通过以上的分析,最终通过关联规则算法,我们希望支持度和置信度大一些,这里一般会定义一个最小值,这个最小值需要通过业务经验来确定。

通过关联规则找到了2类强关联的商品组合之后,接下来需要做什么?看我们的分析目标,我们第一个分析目标就是研究商品,找到商品之间的关联组合。第二个分析目标,研究消费者。什么样的消费者会购买这类商品组合,这是我们接下来要完成的任务。研究消费者,我们用决策树模型。

树主要有3部分组成:根,分支,叶子。其中根是最重要的。什么是决策呢?简单来说,就是做决定,是一种选择,从若干个方案中找到最优的方案。决策首先会有一个决策目标,或者叫决策结论。决策结论不是拍脑袋的,一定要有一个决策依据,通过决策依据做判断。决策由决策依据和决策结论组成。决策结论就是树的叶子,决策依据是树的根,这样决策就和树建立联系了。
哪些消费者会购买强关联的商品组合?对老板来说,这就是一个决策问题。在这个决策问题中,决策依据就是人的特征。老板要根据顾客的基本属性来判断。决策是一个判断题:买还是不买。
决策流程包括决策依据和决策结论。从根到叶子的路径都是一个决策流程。一个决策树上有若干个决策路径,我们就是要从若干个决策路径中找到最优的路径。我们依据什么来判断这个路径的好坏?概率大小,看哪一个路径在样本中出现的次数最多,就认为是最优的。出现次数最多是一个概率问题,频率和概率有什么关系?频率是概率的实验值,概率是频率的理论值。
有同学说“头大了”,其实,我们学习数据挖掘,最终研究的业务问题以及模型构建,就是数学上的统计问题,所以统计学一定要学好,不然学习模型会比较吃力。也就是说数据挖掘也是有一定门槛的,对数学是有要求的。

我们通过决策树模型最后得到两类人群。可以清晰地定位哪些消费者会购买我们的商品组合,而不是漫无目的的推荐。
以上内容是第一个案例。可能今天不能把3个案例都讲完,但是我想的是不用图快,把一些知识点给大家讲清楚,讲透彻。下面我们来看用户体验中的数据挖掘案例。
二、用户体验中的数据挖掘

用户体验如何跟数据挖掘结合起来呢?什么是用户体验?用户是使用产品的人,体验是感受,是主观的,而我们进行数据分析或者数据挖掘是基于客观的对象。第一步就需要量化,把主观的体验量化成客观的数据。如何量化用户体验呢?比如形容一种食品特别好吃,食品的体验特别好。可以用“色香味俱全”来形容,这就是量化的东西。色,指颜色,好看,通过视觉来测量。香,通过嗅觉来测量。味,通过味觉,尝一尝来测量。形容一种食品特别好吃,是很主观的,但是可以通过“色香味”这3个可以测量的方面来形容。
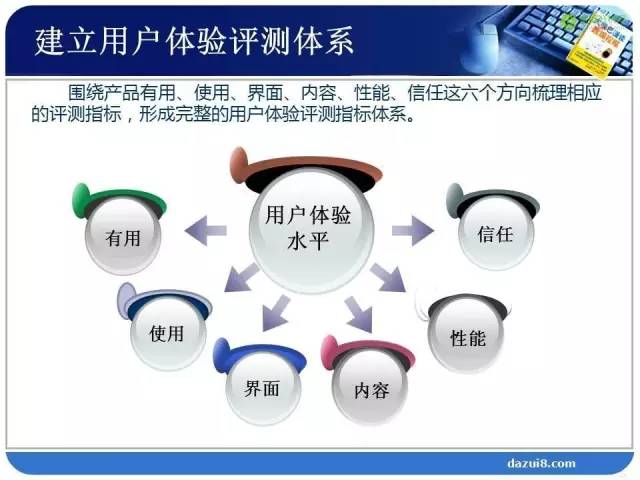
我们再举一个具体的产品,比如一个网站,就是一个产品,我们怎么来形容和描述某一个网站的用户体验好。登录或者打开一个网站,最直接的体验就是界面好看。比如,我们拿数据分析网来说,打开数据分析网觉得界面很美观,视觉效果好。除了界面,我们还要看内容,更新是否及时,是否有价值;还有打开速度。对于一个购物网站,最重要的体验是什么?安全性。总结下,界面、内容、性能、效率、安全等是衡量一个网站发展的体验方面。
通过食品和网站这两个例子,如果让你来量化某一个产品的用户体验,你首先应该怎么办?用户体验是一个主观的东西,主观的东西不能被直接测量,所以需要定指标。
定指标,分解到指标。为什么强调分解这个词呢。因为用户体验本身是个很主观的东西,不能被直接测量,就需要把它分解成若干个可直接测量的指标,这是很关键的第一步。
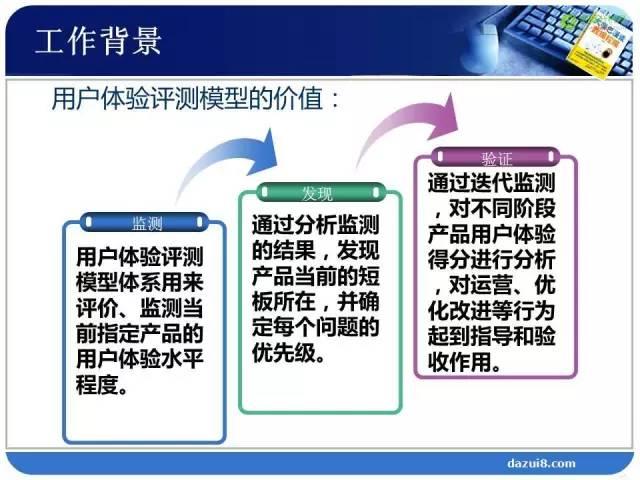
通过这些间接的指标组合,衡量整个产品的用户体验。我们第一步,要构建我们的用户体验评测指标体系。这个评测指标体系就是把我们的产品分解为若干个可以直接测量的指标。我们通过用户体验评测指标体系,衡量产品用户体验的好坏,目的是帮助产品经理发现产品的短板,产品的短板就是用户体验不好的地方,需要改进的地方。在改进的过程中,要确定这些短板的优先级(排序)。优先修改最重要的部分。这就是我们的商业理解。
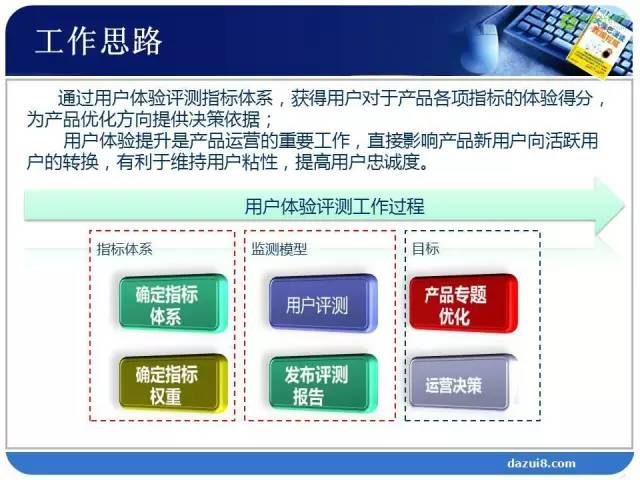
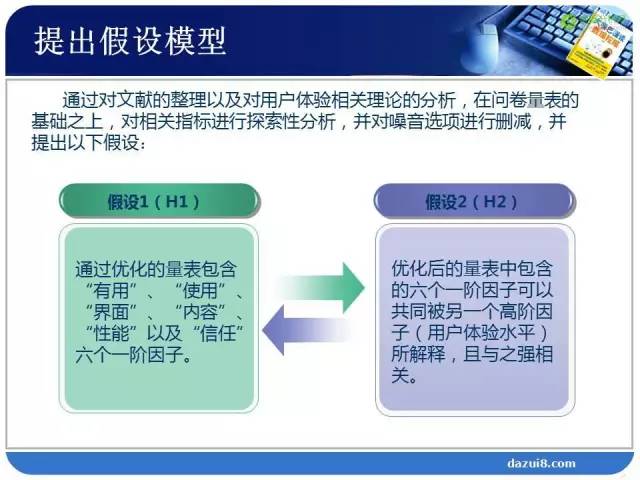
第一步构建了我们的模型,第二步要构建数据模型。需要什么样的数据来支撑我们的分析目标?我们的数据是通过调查问卷,获得那些指标数据。通过问卷调研的题目,对应我们的指标。获得数据支撑以后,构建模型。通过数学的方法,来解决我们的业务问题。我们的业务问题,回到分析目标,第一个目标构建用户体验的指标评测体系,将我们的产品用户体验分解成若干个可以被直接测量的部分。这一个目标隐藏了一个什么样的数学问题?比如一个食品特别好吃,“色香味俱全”,你为什么认为通过“色香味俱全”可以描述这个食品好吃。这个凭的是经验。经验是什么?凭经验得到的模型有可能对,也有可能错。在数学中就是假设检验的过程,需要用数据来验证。
确定了第一个数学问题之后,再看第二个,找到产品的短板所在以及改进。这是个什么数学问题?产品的短板所在,就是每一个指标的评分;改进问题的优先级,就是权重,指标的权重。第2个问题就是找到每一个指标的得分和权重。
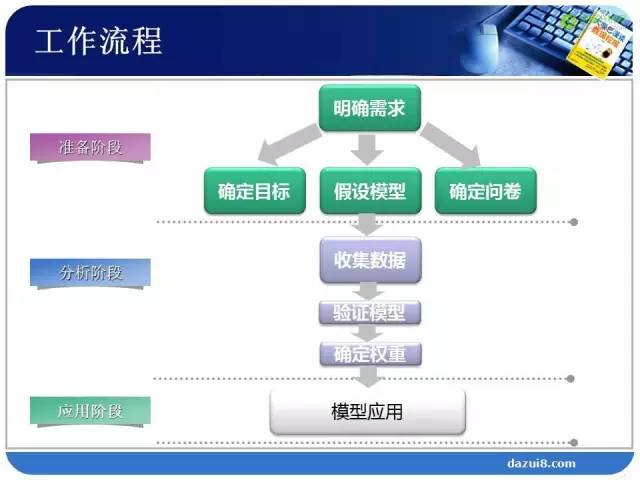
这里的模型应用就是指找到产品的短板所在以及改进。关于用户体验的数据挖掘重点已经都讲的差不多了,由于时间关系,下面我们快速浏览一下整个流程:
第一步:建立用户体验评测指标体系。
 第二步:提出假设
第二步:提出假设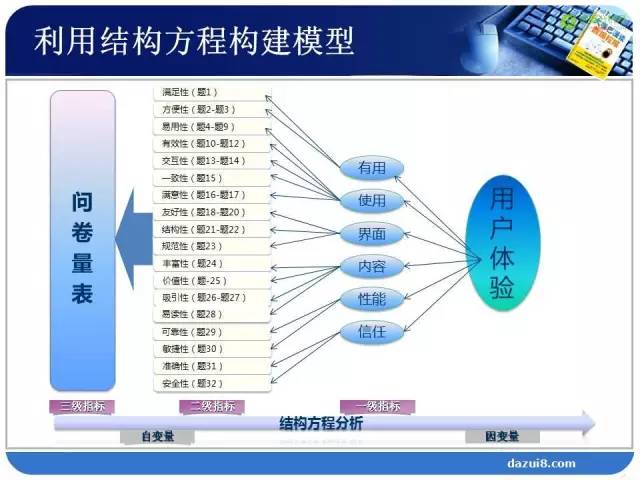 第三步:利用结构方程构建模型
第三步:利用结构方程构建模型
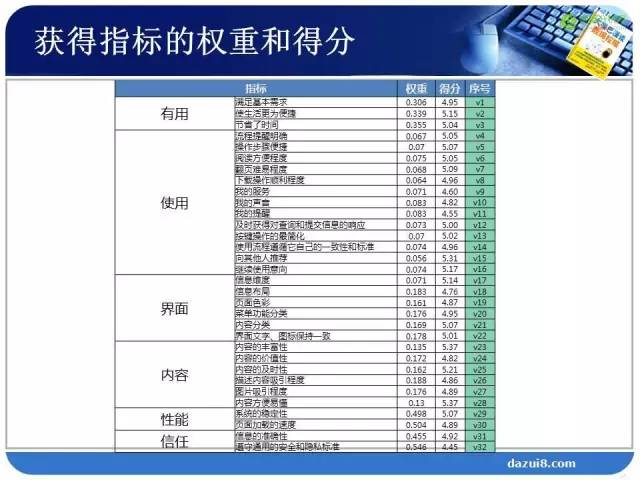 第四步:获得指标的权重和得分
第四步:获得指标的权重和得分 第五步:用户体验综合情况分析
第五步:用户体验综合情况分析
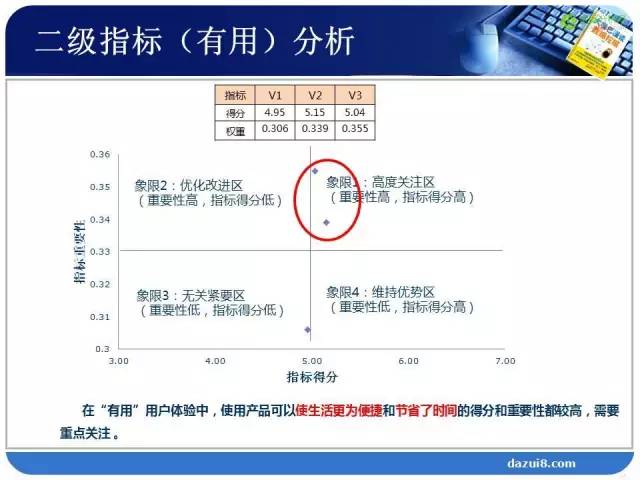
最后,如果大家作为一名产品经理,我们得到了产品的所有体验指标得分和权重后,你首先要把满足什么条件的指标筛选出来呢?得分低、权重大。得分低,说明产品体验不好,即产品短板所在;权重大,是用户关注的比较重要的部分。用一个象限来说明,横轴是指标得分,纵轴是指标重要性。第一象限,得分高、权重高;第二象限,得分低、权重高,这就是我们急需要改进的地方;第三象限,得分低、权重低,对于落在这个象限的指标,作为一个产品经理,你会如何处理?这部分需要砍掉,不能做的大而全,要抓刚需;第四象限,得分高、权重低,这是体验不错的但是用户关注度低的部分。综合来看,我们的产品用户体验要分阶段、分目标的来开展我们的优化工作,逐步提升我们的用户体验水平。

感谢大家,希望大家能把知识点理解透彻。
觉得好看,请点【这里】↓↓↓