实例详解贝叶斯推理的原理
日期 : 2021年02月14日
正文共 :5866字


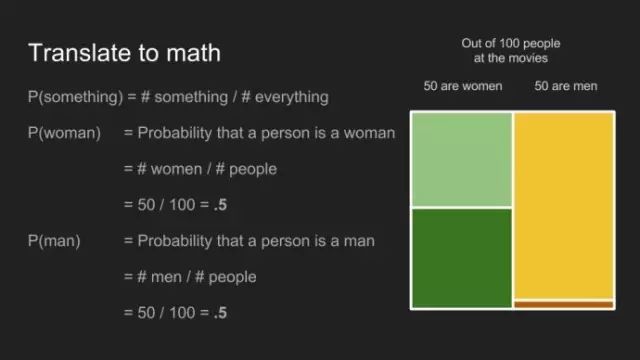


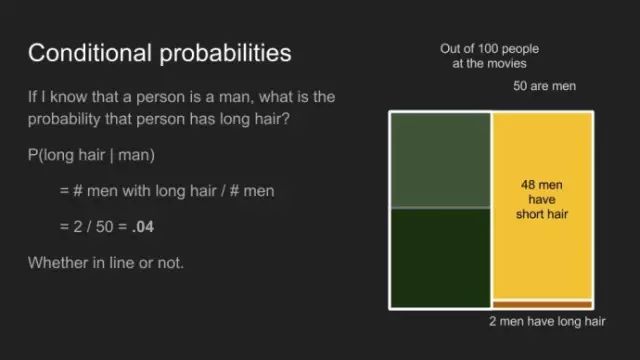




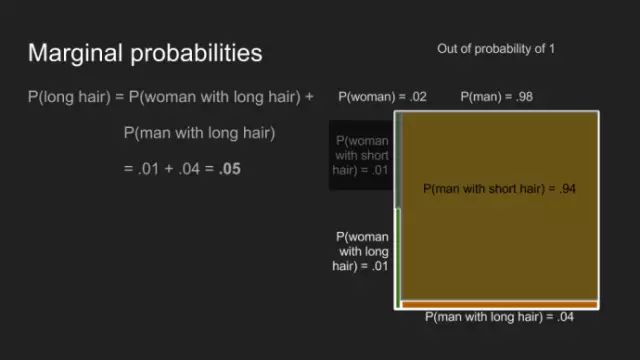
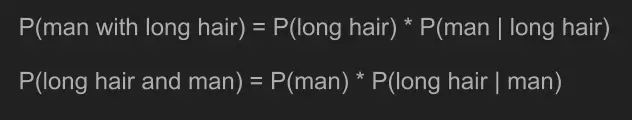
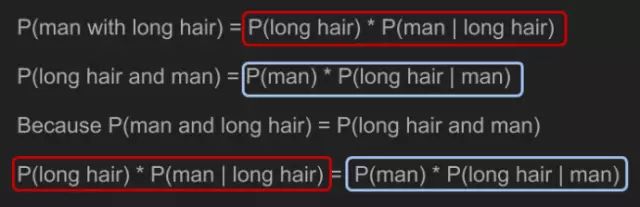


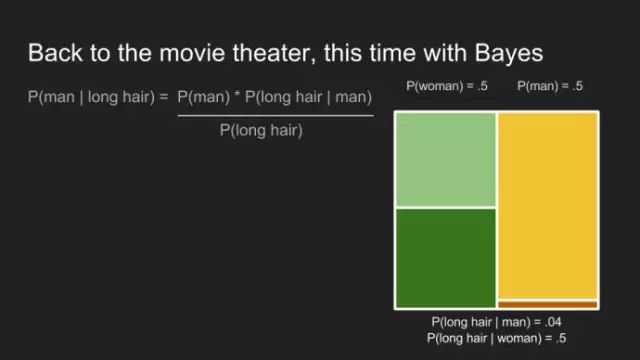
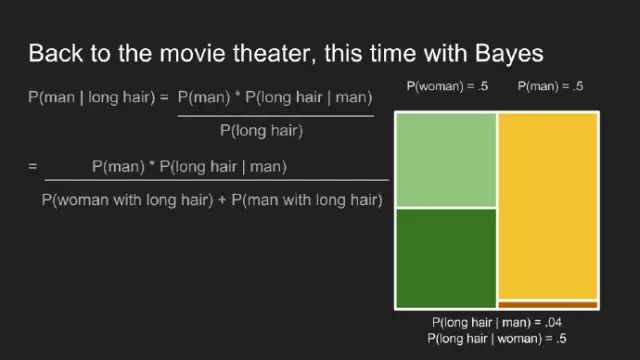

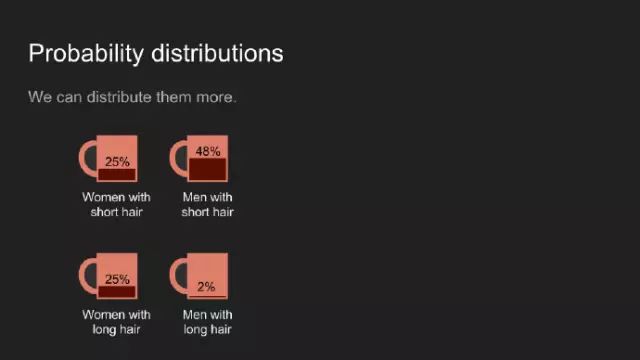
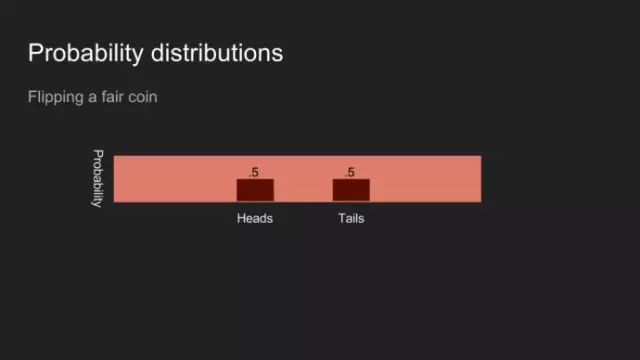
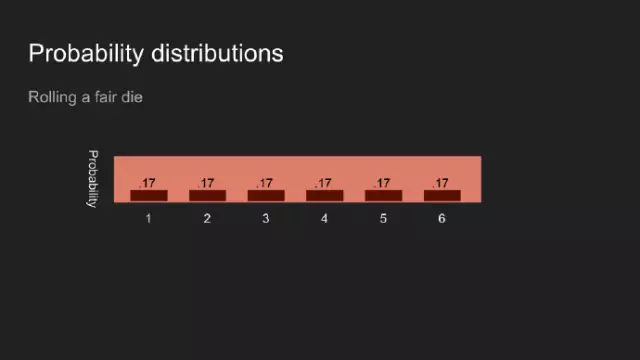
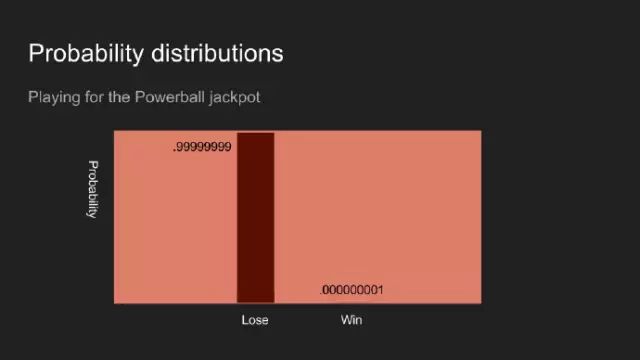
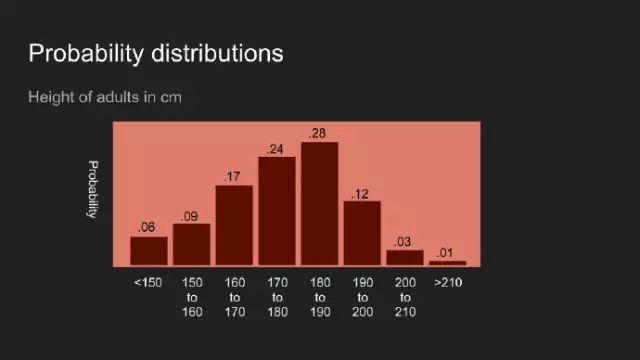
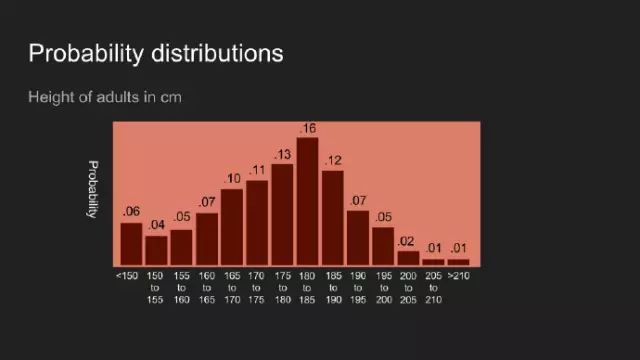
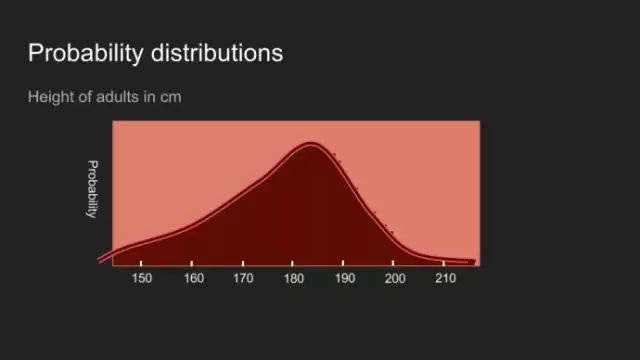

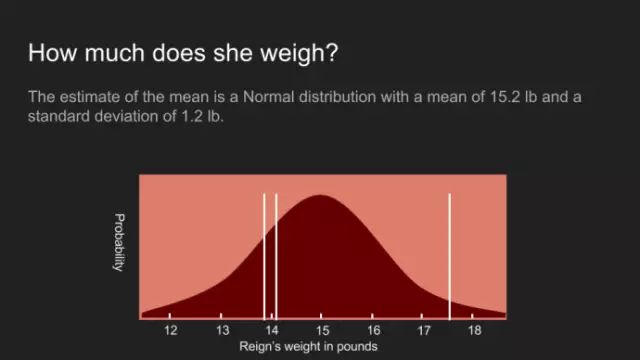

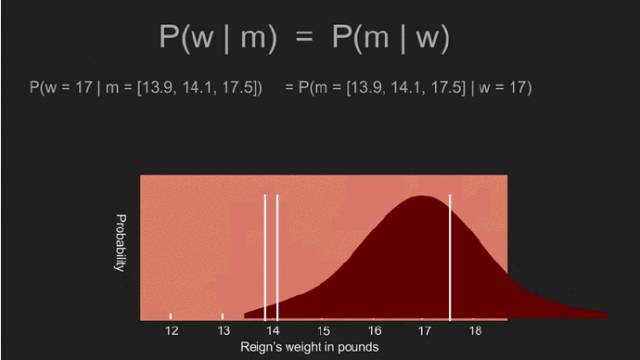
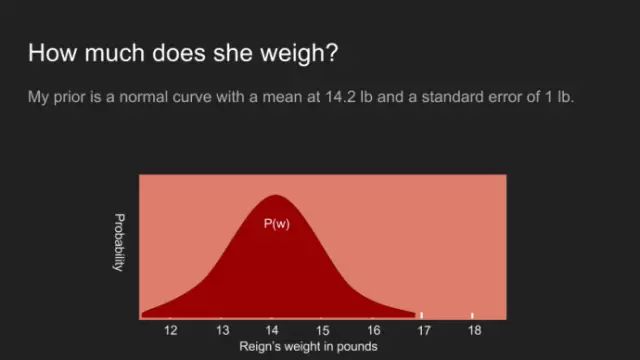
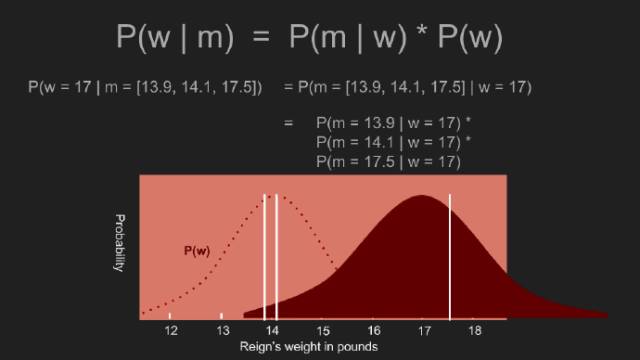
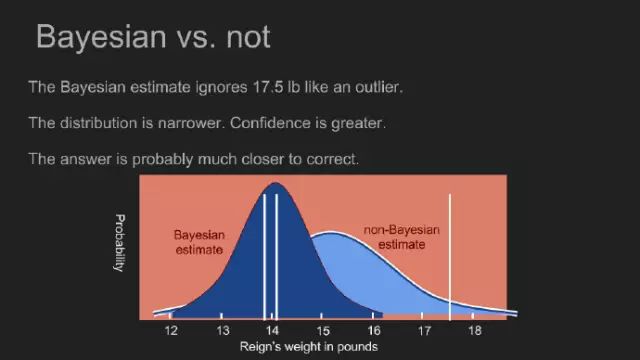

“我敢说你没有太多的练习”,女王回应道,“我年轻的时候,一天中的一个半小时都在闭上眼睛,深呼吸。为何,那是因为有时在早饭前,我已经意识到存在六种不可能了。”来自刘易斯·卡罗尔的《爱丽丝漫游奇境》
— THE END —

评论
 下载APP
下载APP日期 : 2021年02月14日
正文共 :5866字
“我敢说你没有太多的练习”,女王回应道,“我年轻的时候,一天中的一个半小时都在闭上眼睛,深呼吸。为何,那是因为有时在早饭前,我已经意识到存在六种不可能了。”来自刘易斯·卡罗尔的《爱丽丝漫游奇境》
— THE END —