
微博,作为当下主流的社交平台之一,日活跃用户高达2亿多人。人们可以在微博上发表自己的感悟,自己的照片以及日常的生活内容。微博为广大的用户提供了更加多元化的社交平台。相比于微信,许多小姐姐们更喜欢在微博上同大家分享自己日常生活中的照片。比如菜鸟哥,就非常喜欢冰冰小姐姐。今天就带大家一起,手把手的抓取冰冰小姐姐的微博图片,并保存到本地。一起来看看吧。
00.整体的思路:
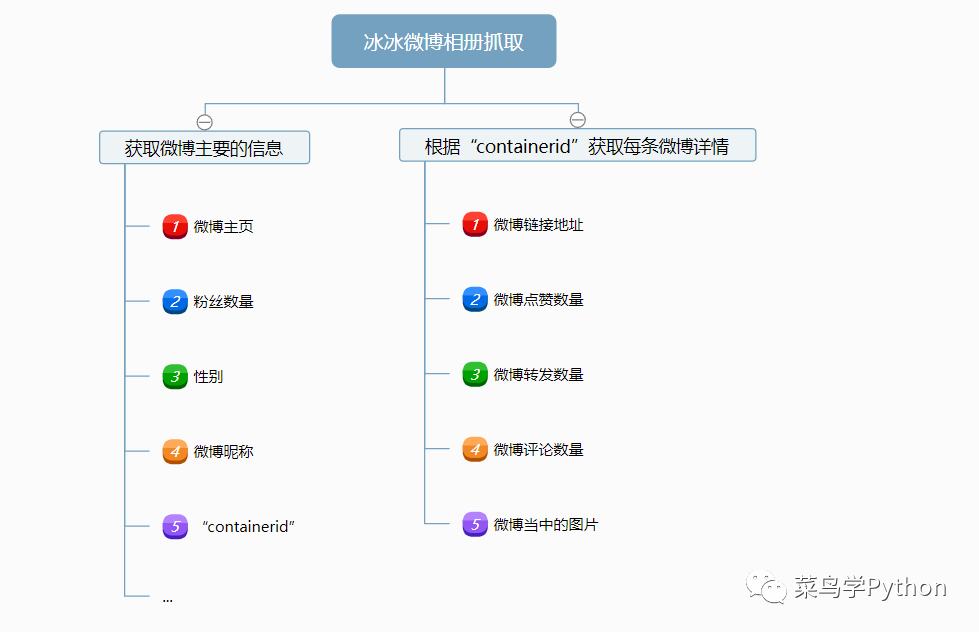
01.微博主页信息
对于微博网页的抓取,很多小伙伴都是通过网络抓包的方式,来获取图片的链接地址,从而获取图片。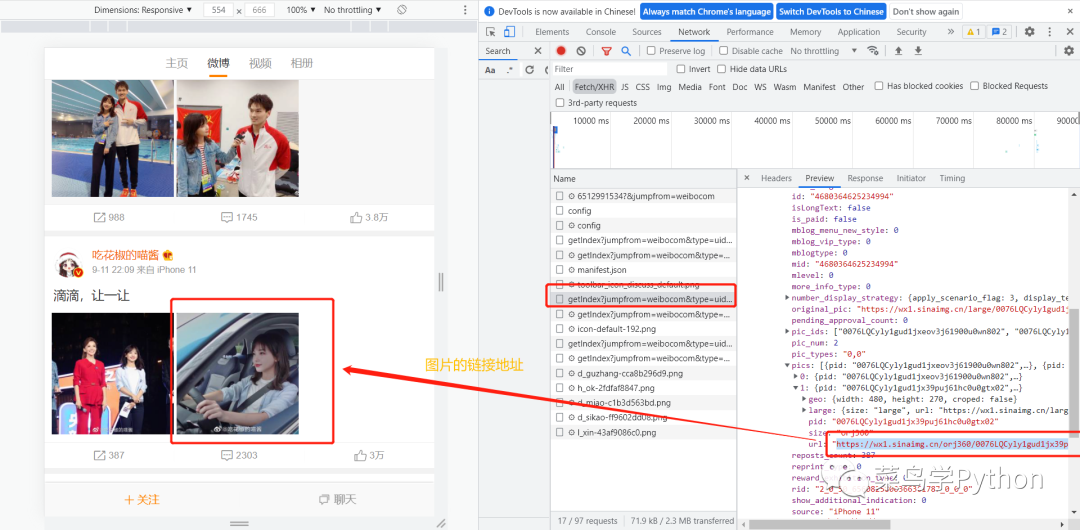
通过抓包的方式来获取图片的链接,非常的麻烦,而且容易被反扒。其实我们可以通过微博的API接口来获取用户的微博的内容。例如,获取微博用户的基本数据,我们只需要知道用户的微博。例如我们打开冰冰酱的网页版微博(https://weibo.com/u/6512991534)。其中的6512991534就是微博id。我们可以打开她的网页地址,返回的就是冰冰微博的主要信息内容:
由于数据是以Unicode的编码显示,而且杂乱无章。没关系,我们通过将数据进行下载,然后进行整理。结果如下图所示:
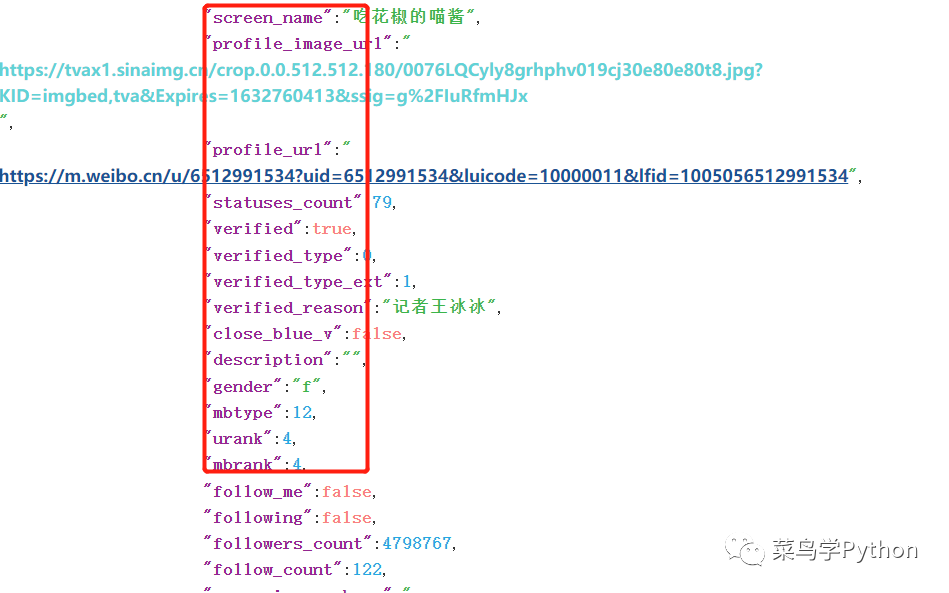
经过解析后的数据,可以清晰的看出,微博的主要信息包含了用户的名称,微博的头像地址,以及性别,粉丝数量等重要信息。通过程序,我们同样可以模仿浏览器来向接口请求结果,并解析数据。
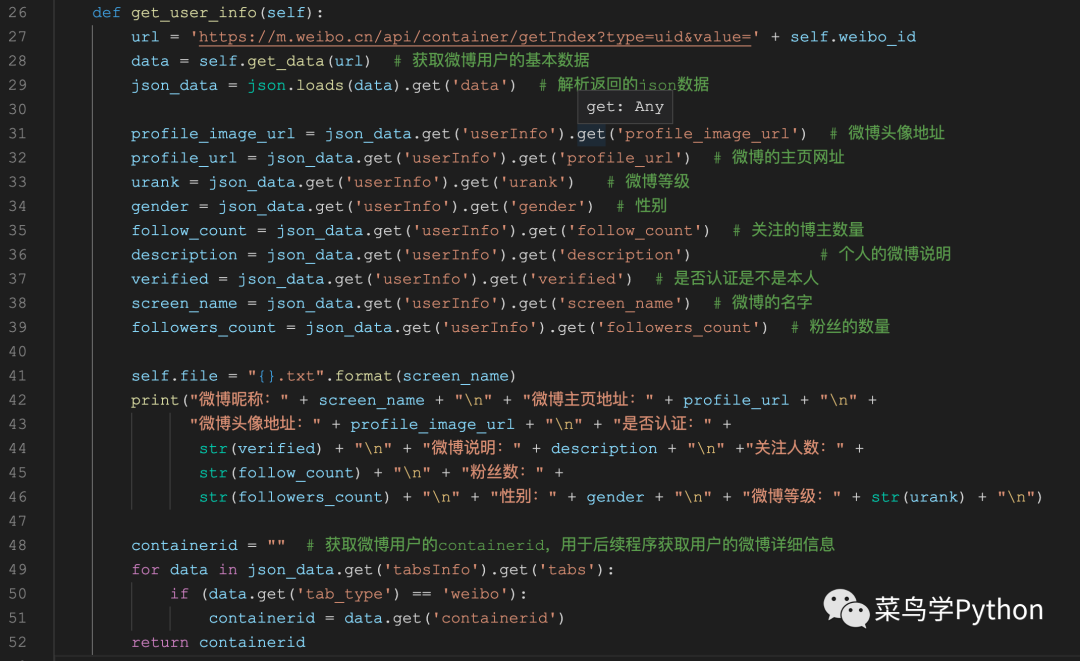
上图程序中,通过self.get_data函数来获取网页的json数据,并进行解析,获取得到json_data数据。(28-29行)接下来,就是获取json_data数据中的关键信息,包括微博的头像地址,微博主页网址等信息(31-41)。在返回的json_data数据中,包含着一项重要的内容:“containerid”。通过containerid信息,我们才能进行后续的微博详情页面的抓取。因此,我们要提取出containerid数值,并返回containerid(42-46)。当执行上述的函数时,得到用户微博的主要信息。结果如下: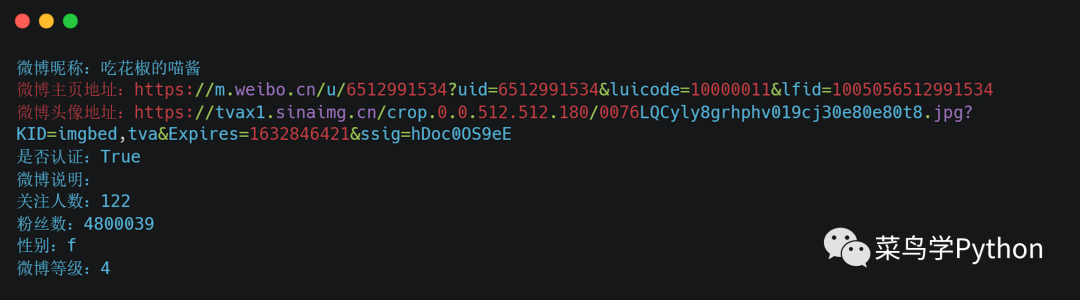
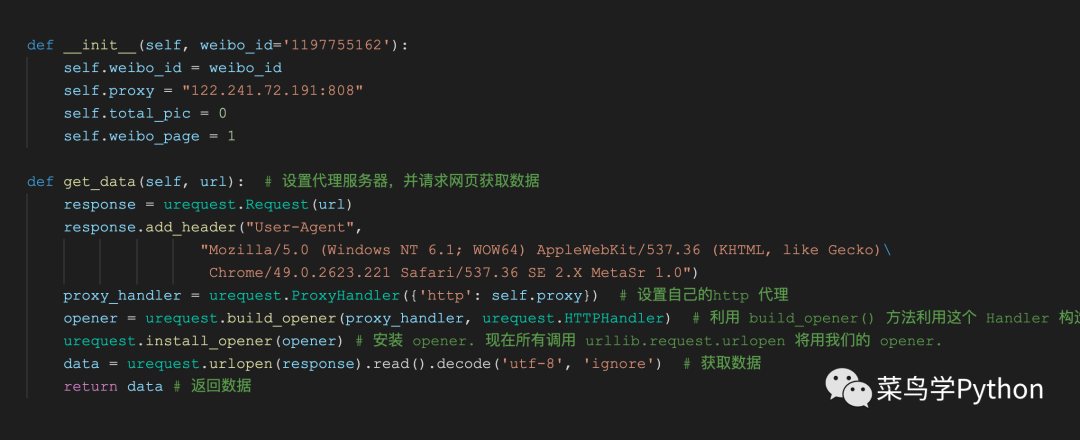
上图函数中,展示的是self.get_data函数。函数的主要作用就是向指定的网页url请求数据。
函数中,通过设置ProxyHandler,来设置我们自己的http代理(18-20行)。函数通过urllib库来获取数据,然后将获取得到的数据进行返回(21-22行)。
02.微博详情页抓取
上面的程序,提供的是用户的微博主要内容信息,那么接下来,就是最重要的微博详情的抓取,包括微博相册以及发布的微博内容信息。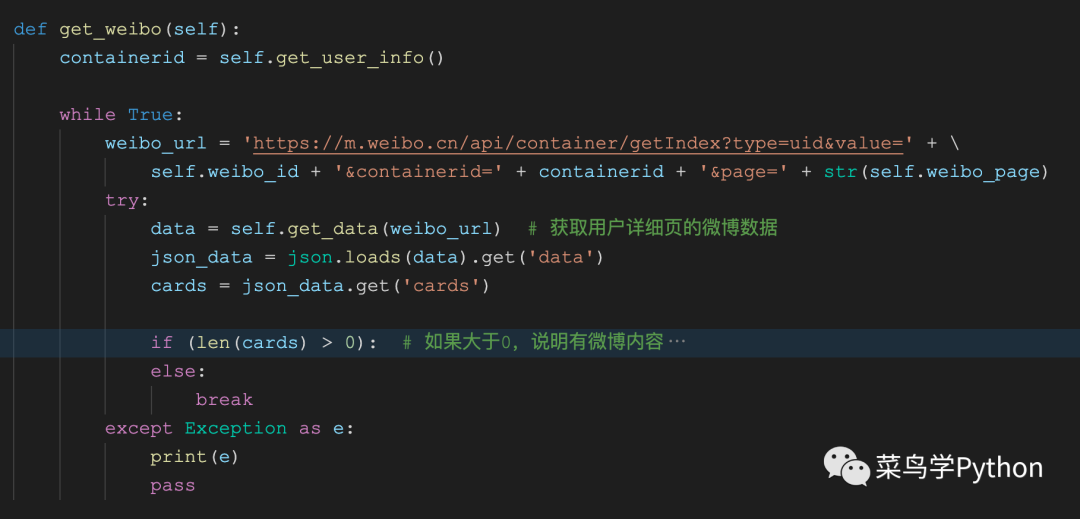
在函数get_weibo中,首先通过self.get_user_info 函数获取得到了containerid的数值(第51行)。接下来在while循环中,利用containerid以及用户的微博id数值以及微博的页数来构造出网页详情的链接地址(第54行)。利用self.get_data函数来获取网页返回的json数据,并解析获取得到cards字典(56-58行)。如果cards的长度大于0,表明该页微博中有微博动态信息,接下来就可以按照字典的操作方式,来层层获取数据,包括微博的文字内容,以及微博动态的点赞数,评论数等信息内容(60-71行)。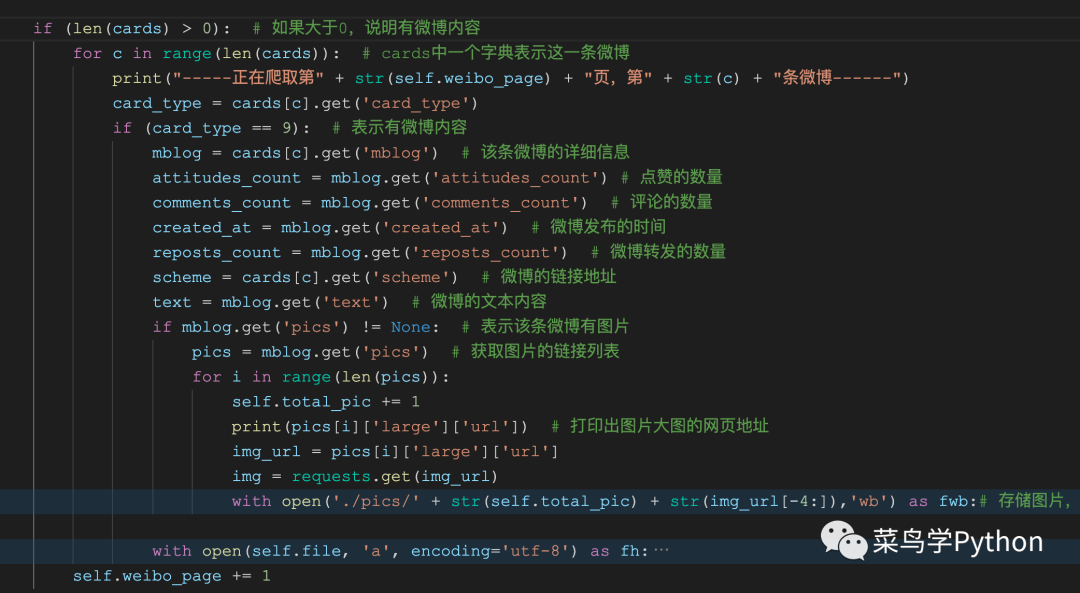
如果mblog中的“pics”值不为None,那么就说明,该条微博动态中包含图片信息,大家就可以提取对应的图片链接地址,并将图片下载到本地文件夹内(72-80行)。
03.保存为相册
最后,将提取到的文字信息,打印到终端当中。这里我们关注的是图片的内容,而不是其他的文本信息,因此不需要将抓取到的文本信息进行保存等特殊的处理。运行上述函数,我们就可以又快又准的抓取冰冰小姐姐的微博相册了。我们一起来看看抓取的结果吧。
如果你也是冰冰的fans,欢迎在留言区吱一声哦,说说你的想法哦。我们月底会给经常来留言打卡的同学送书10本,记得常来指导工作哦!


