NaturalSpeech模型合成语音在CMOS测试中首次达到真人语音水平

大数据文摘转载自微软研究院AI头条
AI 合成语音如今已经屡见不鲜,然而在用户听来却不能让人产生与真人对话和阅读般的沉浸感。
不过,微软亚洲研究院和微软 Azure 语音团队近日联合推出的全新端到端语音合成模型 NaturalSpeech,在 CMOS 测试中首次达到了真人说话水准。这将近一步提升微软 Azure 中合成语音的水平,让所有合成声音都惟妙惟肖。
文本到语音合成(Text to Speech,TTS)是一项根据文本生成可懂且自然的语音的计算机技术 。近年来,随着深度学习的发展,TTS 在学术界和工业界取得了快速突破并且被广泛应用。在 TTS 的研究和产品上,微软一直有着深厚的积累。
在研究方面,微软曾创新提出了多个 TTS 模型,包括基于 Transformer 的语音合成(TransformerTTS)、快速语音合成(FastSpeech 1/2、LightSpeech)、低资源语音合成(LRSpeech)、定制化语音合成(AdaSpeech 1/2/3/4)、歌声合成(HiFiSinger)、立体声合成(BinauralGrad)、声码器(HiFiNet、PriorGrad)、文本分析、说话人脸合成等,而且推出了 TTS 领域最详尽的文献综述。同时,微软亚洲研究院还在多个学术会议上(如 ISCSLP 2021、IJCAI 2021、ICASSP 2022)举办了语音合成教程,并在 Blizzard 2021 语音合成比赛中推出了 DelightfulTTS,获得了最好成绩。此外,微软还推出了开源语音研究项目 NeuralSpeech 等。
在产品方面,微软在 Azure 认知服务中提供了强大的语音合成功能,开发人员可以借助其中的 Neural TTS 功能将文本转换为逼真的语音,用于众多场景之中,例如语音助手、有声读物、游戏配音、辅助工具等等。利用 Azure Neural TTS,用户既可以直接选择预置的音色,也可以自己录制上传声音样本自定义音色。目前,Azure Neural TTS 支持超过120种语言,包括多语言变体或方言,同时该功能也已整合到了多个微软产品中,并且被业界诸多合作伙伴所采用。为了持续推动技术创新,提高服务质量,微软 Azure 语音团队与微软亚洲研究院密切合作,让 TTS 在不同场景下听起来更多样、更悦耳,也更自然。
近日,微软亚洲研究院和微软 Azure 语音团队研发出了全新的端到端 TTS 模型 NaturalSpeech,该模型在广泛使用的 TTS 数据集(LJSpeech)上使用 CMOS (Comparative Mean Opinion Score) 作为指标,首次达到了与自然语音无明显差异的优异成绩。这一创新性的科研成果未来也将集成到微软 Azure TTS 服务中供更多用户使用。
四大创新设计让NaturalSpeech超越传统TTS系统
NaturalSpeech 是一个完全端到端的文本到语音波形生成系统(见图1),能够弥合合成语音与真人声音之间的质量差距。具体而言,该系统利用变分自编码器(Variational Auto-Encoder, VAE),将高维语音 (x) 压缩成连续的帧级表达 z(记作后验 q(z|x)),用于对语音波形 x(记作 p(x|z))的重构。相应的先验(记作 p(z|y))则从文本序列 y 中获取。

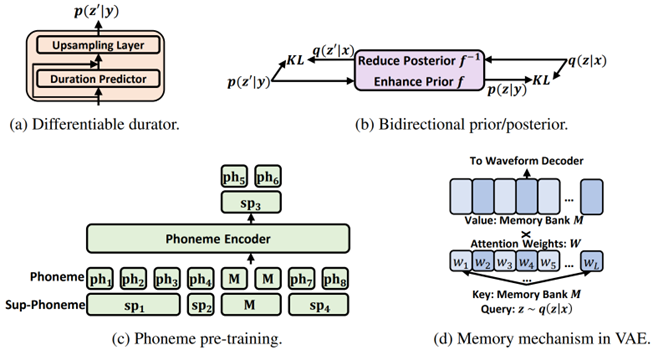
考虑到来自语音的后验比来自文本的先验更加复杂,研究员们设计了几个模块(见图2),尽可能近似地对后验和先验进行匹配,从而通过y→p(z|y)→p(x|z)→x实现文本到语音的合成。
在音素编码器上利用大规模音素预训练(phoneme pre-training),从音素序列中提取更好的表达。 利用由时长预测器和上采样层组成的完全可微分的时长模块(durator),来改进音素的时长建模。 基于流模型(flow)的双向先验/后验模块(bidirectional prior/posterior),可以进一步增强先验 p(z|y) 以及降低后验 q(z|x) 的复杂性。 基于记忆的变分自编码器(Memory VAE),可降低重建波形所需的后验复杂性。


微软 Azure 认知服务 TTS https://azure.microsoft.com/en-us/services/cognitive-services/text-to-speech/ 微软亚洲研究院语音相关研究 https://speechresearch.github.io/ 微软开源语音研究项目 NeuralSpeech https://github.com/microsoft/neuralspeech NaturalSpeech 论文:NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality https://arxiv.org/abs/2205.04421 Responsible AI principles from Microsoft https://www.microsoft.com/en-us/ai/responsible-ai Our approach to responsible AI at Microsoft https://www.microsoft.com/en-us/ai/our-approach The building blocks of Microsoft’s responsible AI program https://blogs.microsoft.com/on-the-issues/2021/01/19/microsoft-responsible-ai-program/