
微软全华班放出语音炸弹!NaturalSpeech语音合成首次达到人类水平

新智元报道
新智元报道
编辑:LRS
【新智元导读】最近微软全华班发布了一个新模型NaturalSpeech,在语音合成领域首次达到人类水平,人耳难分真假。




语音合成首次达到人类水平
语音合成首次达到人类水平

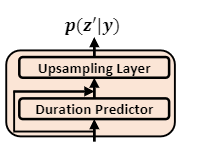

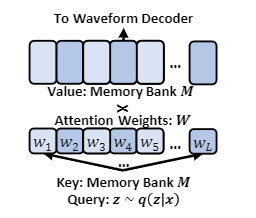
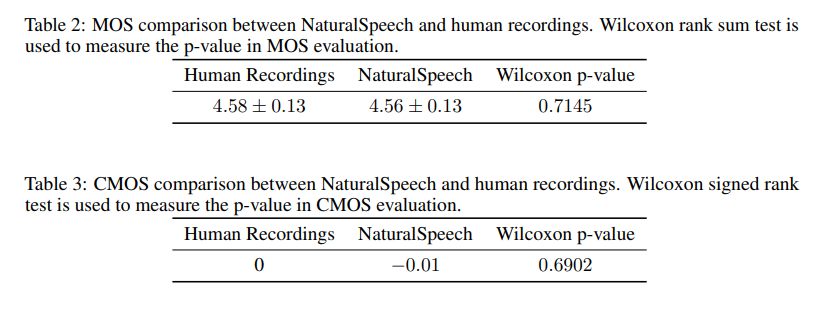
参考资料:
https://www.reddit.com/r/MachineLearning/comments/umgopp/r_naturalspeech_endtoend_text_to_speech_synthesis/

评论