
线上 K8s Ingress 访问故障排查思路
原文链接:https://corvo.myseu.cn/archives/
此次排查发生在 2021-02 月份.
具体现象
应用迁移至我们的PaaS平台后会出现偶发性的502问题, 错误见图片:

相比于程序的请求量, 错误肯定是比较少的, 但是错误一直在发生, 会影响调用方的代码, 需要检查下问题原因.
为啥我们只看到了POST请求
读者肯定会说, 你们elk过滤字段里面写的是POST, 所以肯定只有POST请求, hah. 其实不是这样的, GET请求也会有502, 只是Nginx会对GET请求进行重试, 产生类似如下的日志:
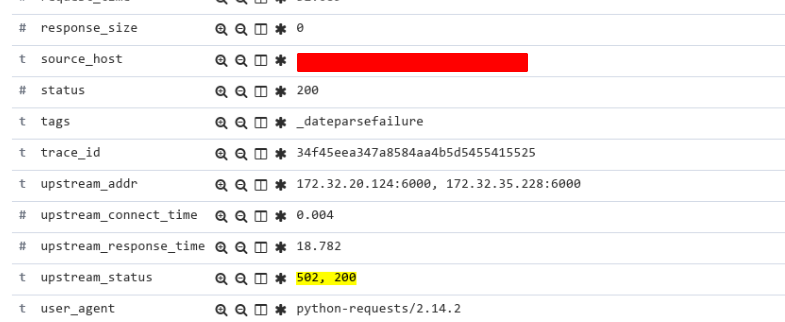
重试机制是Nginx默认的: proxy_next_upstream
http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_next_upstream
因为GET方法会被认为是幂等的, 所以当一个upstream出现502的时候, nginx会再次尝试. 对于我们的问题, 主要想确认为什么有502, 只看POST请求就足够了, 两者的原因应该是一致的.
网络拓扑结构
网络请求流入集群时, 对于我们集群的结构:
1 | 用户请求=>Nginx=>Ingress =>uwsgi |
不要问为什么有了 Ingress 还有 Nginx. 这是历史原因, 有些工作暂时需要由 Nginx 承担.
统计排查
基于我们对于Nginx和Ingress的错误请求统计, 发现两者中的502错误是想等的, 说明问题一定是出现在Ingress<=>uwsgi之中.
抓包
这个并不是最先想到的方案, 因为我们用了很多统计方法也没总结出来规律, 最后只能寄希望于抓包了…
该请求日志如下:
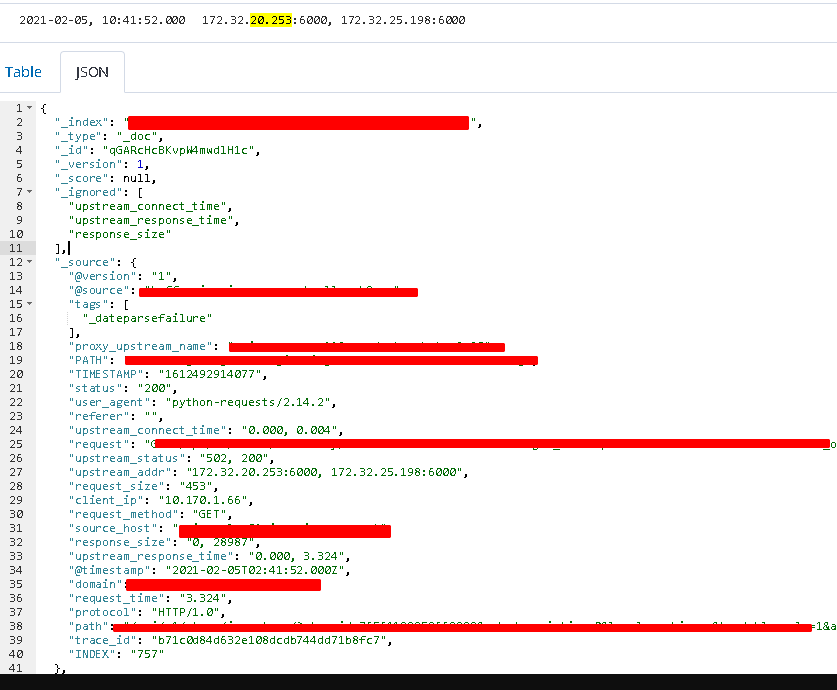
抓包结果如下:
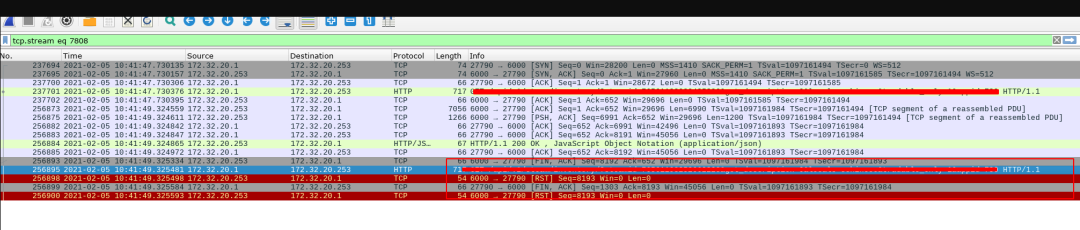
从抓包情况来看, 当前的tcp连接被复用了, 由于Ingress中使用了HTTP1.1协议, 会在一次tcp连接中尝试发送第二个HTTP请求, 但是uwsgi没有支持http1.1, 所以在第二个请求根本不会被处理, 直接拒绝了. 所以在Ingress看来, 这个请求失败了, 因此返回了502. 由于GET请求会重试, 但POST请求无法重试, 所以访问统计中出现了POST请求502的问题.
Ingress配置学习
Ingress中, 默认对upstream使用的http版本为1.1, 但是我们的uwsgi使用的是http-socket, 而非http11-socket, 我们Ingress中使用了与后端不同的协议, 出现了意料之外的502错误.
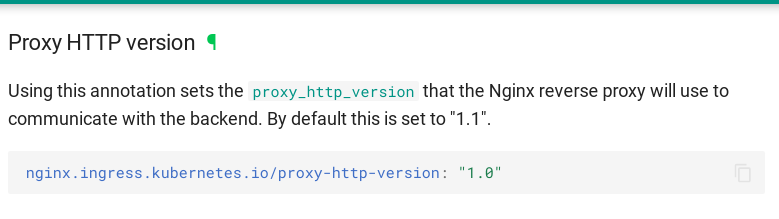
https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/annotations/#proxy-http-version
因为Nginx默认是1.0, 但是切换到Ingress中默认变成了1.1, 而我们没有统一, 解决方案是强制指定Ingress中使用的http协议版本.
{% if keepalive_enable is sameas true %}nginx.ingress.kubernetes.io/proxy-http-version: "1.1"{% else %}nginx.ingress.kubernetes.io/proxy-http-version: "1.0"{% endif %}
如果有大佬看到了, 可以简单讲讲Ingress会在什么时候复用http1.1的连接, 以及为什么Ingress不复用每一个连接, 这样问题会尽快的暴露, 这些问题我没有继续深究了. 毕竟你换个语言比如Golang就没有这个问题了, 这个是uwsgi专属错误.
总结
有关这个502问题的排查, 我个人觉得, 最后抓包一次性解决问题其实没什么特别的, 抓了就能发现问题, 不抓就发现不了.
我是希望给大家一个启发, 对于一整条链路, 如何来排查故障: 我们这里既使用了Nginx, 又使用了Ingress, 在排查时, 需要首先检查两者的错误数量, 如果确认错误基本一致, 那就说明错误与Nginx没有关系, 需要检查Ingres上的错误, 对于多个中转的请求, 这样的排查能比较快的确定链路的错误位置.
- END -
推荐阅读 31天拿下K8S含金量最高的CKA+CKS证书! 
Kubernetes 生态架构图 Prometheus Thanos 多集群监控 20张最全的DevOps架构师技术栈图谱 Linux Shell 脚本编程最佳实践 我的云服务器被植入挖矿木马,CPU飙升200% 做了这么多年运维工作,现在才看清职业方向 一篇文章讲清楚云原生图景及发展路线 K8s kubectl 常用命令总结(建议收藏) 一名运维小哥对运维规则的10个总结 K8s运维锦囊,19个常见故障解决方法 编写 Dockerfile 最佳实践 搭建一套完整的企业级 K8s 集群(kubeadm方式)
点亮,服务器三年不宕机
