
线上 K8s Ingress 访问故障排查思路,看这一篇就够了

具体现象
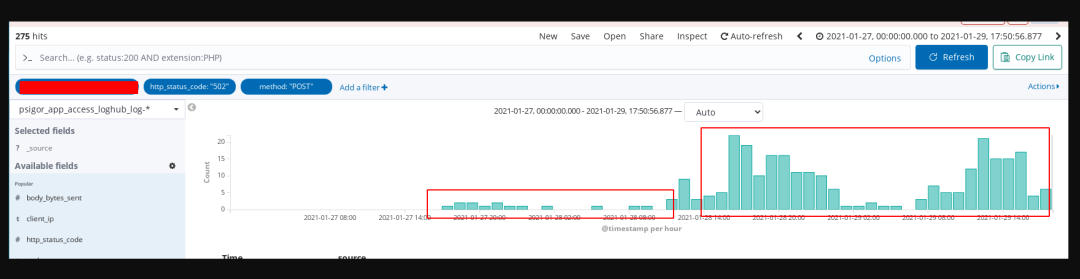
为啥只看到了POST请求
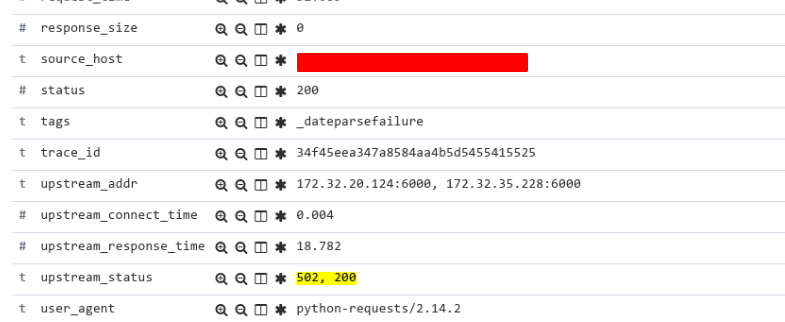
重试机制是Nginx默认的: proxy_next_upstream
http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_next_upstream
因为GET方法会被认为是幂等的, 所以当一个upstream出现502的时候, nginx会再次尝试. 对于我们的问题, 主要想确认为什么有502, 只看POST请求就足够了, 两者的原因应该是一致的.
网络拓扑结构
网络请求流入集群时, 对于我们集群的结构:
用户请求=>Nginx=>Ingress =>uwsgi
统计排查
基于我们对于Nginx和Ingress的错误请求统计,发现两者中的502错误是想等的,说明问题一定是出现在Ingress<=>uwsgi之中。
抓包
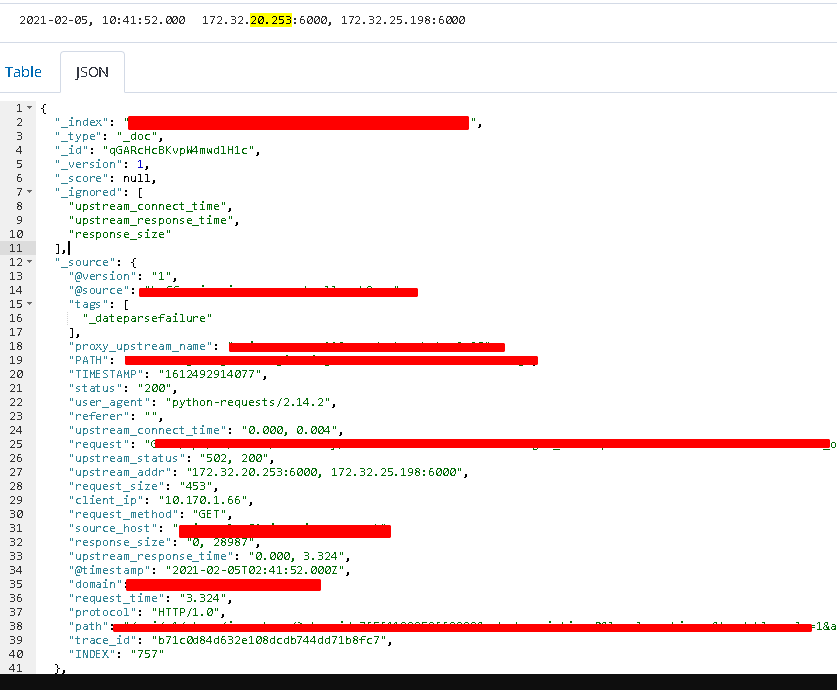
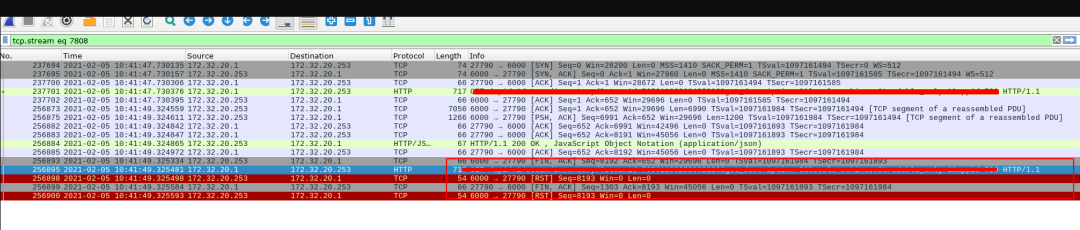
抓包结果如下:
Ingress配置学习
Ingress中, 默认对upstream使用的http版本为1.1, 但是我们的uwsgi使用的是http-socket, 而非http11-socket, 我们Ingress中使用了与后端不同的协议, 出现了意料之外的502错误。
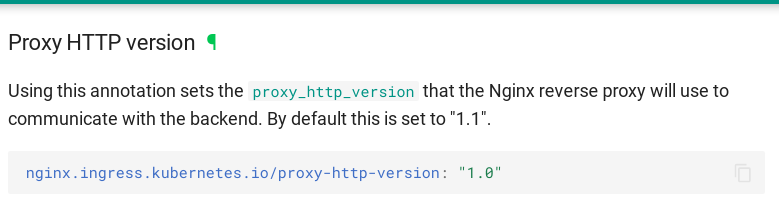
https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/annotations/#proxy-http-version
{% if keepalive_enable is sameas true %}nginx.ingress.kubernetes.io/proxy-http-version: "1.1"{% else %}nginx.ingress.kubernetes.io/proxy-http-version: "1.0"{% endif %}
如果有大佬看到了,可以简单讲讲Ingress会在什么时候复用http1.1的连接,以及为什么Ingress不复用每一个连接,这样问题会尽快的暴露,这些问题我没有继续深究了。毕竟你换个语言比如Golang就没有这个问题了,这个是uwsgi专属错误。
总结
有关这个502问题的排查, 我个人觉得, 最后抓包一次性解决问题其实没什么特别的, 抓了就能发现问题, 不抓就发现不了.
我是希望给大家一个启发, 对于一整条链路, 如何来排查故障: 我们这里既使用了Nginx, 又使用了Ingress, 在排查时, 需要首先检查两者的错误数量, 如果确认错误基本一致, 那就说明错误与Nginx没有关系, 需要检查Ingres上的错误, 对于多个中转的请求, 这样的排查能比较快的确定链路的错误位置.
来源:https://corvo.myseu.cn/archives
文章转载:高效运维
(版权归原作者所有,侵删)

点击下方“阅读原文”查看更多