
详解圈复杂度

详解圈复杂度
圈复杂度概念
圈复杂度(Cyclomatic complexity,简写CC)也称为条件复杂度,是一种代码复杂度的衡量标准。由托马斯·J·麦凯布(Thomas J. McCabe, Sr.)于1976年提出,用来表示程序的复杂度,其符号为VG或是M。它可以用来衡量一个模块判定结构的复杂程度,数量上表现为独立现行路径条数,也可理解为覆盖所有的可能情况最少使用的测试用例数。圈复杂度大说明程序代码的判断逻辑复杂,可能质量低且难于测试和 维护。程序的可能错误和高的圈复杂度有着很大关系。
圈复杂度计算方法
点边计算法
圈复杂度的计算方法很简单,计算公式为:
V(G) = E - N + 2
其中,e表示控制流图中边的数量,n表示控制流图中节点的数量。
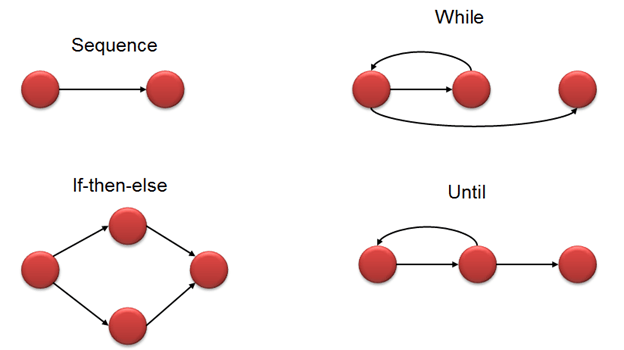
几个节点通过边连接。下面是典型的控制流程,如if-else,While,until和正常的流程顺序:
节点判定法
其实,圈复杂度的计算还有更直观的方法,因为圈复杂度所反映的是“判定条件”的数量,所以圈复杂度实际上就是等于判定节点的数量再加上1,也即控制流图的区域数,对应的计算公式为:
V (G) = P + 1
其中P为判定节点数,判定节点举例:
if语句
while语句
for语句
case语句
catch语句
and和or布尔操作
?:三元运算符
对于多分支的CASE结构或IF-ELSEIF-ELSE结构,统计判定节点的个数时需要特别注意一点,要求必须统计全部实际的判定节点数,也即每个ELSEIF语句,以及每个CASE语句,都应该算为一个判定节点。
判定节点在模块的控制流图中很容易被识别出来,所以,针对程序的控制流图计算圈复杂度V(G)时,一般采用点边计算法,也即V(G)=e-n+2;而针对模块的控制流图时,可以直接使用统计判定节点数,这样更为简单。
圈复杂度计算练习
练习1:
1void sort(int * A)
2{
3 int i=0;
4 int n=4;
5 int j = 0;
6 while(i < n-1)
7 {
8 j = i +1
9 while(j < n)
10 {
11 if (A[i] < A[j])
12 swap(A[i], A[j]);
13 }
14 i = i + 1
15 }
16}
使用点边计算法绘出控制流图:
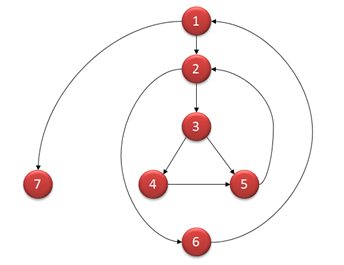
其圈复杂度为:V(G) = 9 - 7 + 2 = 4
练习2:
1U32 find (string match){
2 for(auto var : list)
3 {
4 if(var == match && from != INVALID_U32) return INVALID_U32;
5 }
6 //match step1
7 if(session == getName() && key == getKey())
8 {
9 for (auto& kv : Map)
10 {
11 if (kv.second == last && match == kv.first)
12 {
13 return last;
14 }
15 }
16
17 }
18 //match step2
19 auto var = Map.find(match);
20 if(var != Map.end()&& (from != var->second)) return var->second;
21
22 //match step3
23 for(auto var: Map)
24 {
25 if((var.first, match) && from != var.second)
26 {
27 return var.second;
28 }
29 }
30 return INVALID_U32;
31 };
其圈复杂度为:V(G) = 1(for) + 2(if) + 2(if) + 1(for) + 2(if) + 2(if) + 1(for) + 2(if) + 1= 14
圈复杂度的意义
在缺陷成为缺陷之前捕获它们。
圈复杂度与缺陷
一般来说圈复杂度大于10的方法存在很大的出错风险。圈复杂度和缺陷个数有高度的正相关:圈复杂度最高的模块和方法,其缺陷个数也可能最多。
圈复杂度与结构化测试
此外,它还为测试设计提供很好的参考。一个好的用例设计经验是:创建数量与被测代码圈复杂度值相等的测试用例,以此提升用例对代码的分支覆盖率。
圈复杂度与TDD
TDD(测试驱动的开发,test-driven development)和低CC值之间存在着紧密联系。在编写测试时,开发人员会考虑代码的可测试性,倾向于编写简单的代码,因为复杂的代码难以测试。因此TDD的“代码、测试、代码、测试” 循环将导致频繁重构,驱使非复杂代码的开发。
圈复杂度与遗留代码
对于遗留代码的维护或重构,测量圈复杂度特别有价值。一般使用圈复杂度作为提升代码质量的切入点。
圈复杂度与CI
在持续集成环境中,可以基于时间变化维度来评估模块或函数的复杂度和增长值。如果CC值在不断增长,那么应该开展两项活动:
确保相关测试的有效性,减少故障风险。
评估重构必要性和具体方式,以降低出现代码维护问题的可能性。
圈复杂度和软件质量
| 圈复杂度 | 代码状况 | 可测性 | 维护成本 |
|---|---|---|---|
| 1-10 | 清晰、结构化 | 高 | 低 |
| 10-20 | 复杂 | 中 | 中 |
| 20-30 | 非常复杂 | 低 | 高 |
| >30 | 不可读 | 不可测 | 非常高 |
降低圈复杂度的方法
重新组织你的函数
技巧1 提炼函数
有一段代码可以被组织在一起并独立出来:
1void Example(int val)
2{
3 if( val > MAX_VAL)
4 {
5 val = MAX_VAL;
6 }
7
8 for( int i = 0; i < val; i++)
9 {
10 doSomething(i);
11 }
12}将这段代码放进一个独立函数中,并让函数名称解释该函数的用途:
1int getValidVal(int val)
2{
3 if( val > MAX_VAL)
4 {
5 return MAX_VAL;
6 }
7 return val;
8}
9
10void doSomethings(int val)
11{
12 for( int i = 0; i < val; i++)
13 {
14 doSomething(i);
15 }
16}
17
18void Example(int val)
19{
20 doSomethings(getValidVal(val));
21}最后还要重新审视函数内容是否在统一层次上。
技巧2 替换算法
把某个算法替换为另一个更清晰的算法:
1string foundPerson(const vector<string>& peoples){
2 for (auto& people : peoples)
3 {
4 if (people == "Don"){
5 return "Don";
6 }
7 if (people == "John"){
8 return "John";
9 }
10 if (people == "Kent"){
11 return "Kent";
12 }
13 }
14 return "";
15}将函数实现替换为另一个算法:
1string foundPerson(const vector<string>& people){
2 std::map<string,string>candidates{
3 { "Don", "Don"},
4 { "John", "John"},
5 { "Kent", "Kent"},
6 };
7 for (auto& people : peoples)
8 {
9 auto& it = candidates.find(people);
10 if(it != candidates.end())
11 return it->second;
12 }
13}所谓的表驱动。
简化条件表达式
技巧3 逆向表达
在代码中可能存在条件表达如下:
1if ((condition1() && condition2()) || !condition1())
2{
3 return true;
4}
5else
6{
7 return false;
8}
应用逆向表达调换表达顺序后效果如下:
1if(condition1() && !condition2())
2{
3 return false;
4}
5
6return true;技巧4 分解条件
在代码中存在复杂的条件表达:
1if(date.before (SUMMER_START) || date.after(SUMMER_END))
2 charge = quantity * _winterRate + _winterServiceCharge;
3else
4 charge = quantity * _summerRate;从if、then、else三个段落中分别提炼出独立函数:
1if(notSummer(date))
2 charge = winterCharge(quantity);
3else
4 charge = summerCharge (quantity);技巧5 合并条件
一系列条件判断,都得到相同结果:
1double disabilityAmount()
2{
3 if (_seniority < 2) return 0;
4 if (_monthsDisabled > 12) return 0;
5 if (_isPartTime) return 0;
6 // compute the disability amount
7 ......将这些判断合并为一个条件式,并将这个条件式提炼成为一个独立函数:
1double disabilityAmount()
2{
3 if (isNotEligableForDisability()) return 0;
4 // compute the disability amount
5 ......技巧6 移除控制标记
在代码逻辑中,有时候会使用bool类型作为逻辑控制标记:
1void checkSecurity(vector<string>& peoples) {
2 bool found = false;
3 for (auto& people : peoples)
4 {
5 if (! found) {
6 if (people == "Don"){
7 sendAlert();
8 found = true;
9 }
10 if (people == "John"){
11 sendAlert();
12 found = true;
13 }
14 }
15 }
16}使用break和return取代控制标记:
1void checkSecurity(vector<string>& peoples) {
2 for (auto& people : peoples)
3 {
4 if (people == "Don" || people == "John")
5 {
6 sendAlert();
7 break;
8 }
9 }
10}技巧7 以多态取代条件式
条件式根据对象类型的不同而选择不同的行为:
1double getSpeed()
2{
3 switch (_type) {
4 case EUROPEAN:
5 return getBaseSpeed();
6 case AFRICAN:
7 return getBaseSpeed() - getLoadFactor() *_numberOfCoconuts;
8 case NORWEGIAN_BLUE:
9 return (_isNailed) ? 0 : getBaseSpeed(_voltage);
10 }
11 throw new RuntimeException ("Should be unreachable");
12}
将整个条件式的每个分支放进一个子类的重载方法中,然后将原始函数声明为抽象方法:
1class Bird
2{
3public:
4 virtual double getSpeed() = 0;
5
6protected:
7 double getBaseSpeed();
8}
9
10class EuropeanBird
11{
12public:
13 double getSpeed()
14 {
15 return getBaseSpeed();
16 }
17}
18
19class AfricanBird
20{
21public:
22 double getSpeed()
23 {
24 return getBaseSpeed() - getLoadFactor() *_numberOfCoconuts;
25 }
26
27private:
28 double getLoadFactor();
29
30 double _numberOfCoconuts;
31}
32
33class NorwegianBlueBird
34{
35public:
36 double getSpeed()
37 {
38 return (_isNailed) ? 0 : getBaseSpeed(_voltage);
39 };
40
41private:
42 bool _isNailed;
43}简化函数调用
技巧8 读写分离
某个函数既返回对象状态值,又修改对象状态:
1class Customer
2{
3 int getTotalOutstandingAndSetReadyForSummaries(int number);
4}建立两个不同的函数,其中一个负责查询,另一个负责修改:
1class Customer
2{
3 int getTotalOutstanding();
4 void SetReadyForSummaries(int number);
5}技巧9 参数化方法
若干函数做了类似的工作,但在函数本体中却 包含了不同的值:
1Dollars baseCharge()
2 {
3 double result = Math.min(lastUsage(),100) * 0.03;
4 if (lastUsage() > 100)
5 {
6 result += (Math.min (lastUsage(),200) - 100) * 0.05;
7 }
8 if (lastUsage() > 200)
9 {
10 result += (lastUsage() - 200) * 0.07;
11 }
12 return new Dollars (result);
13}
14
建立单一函数,以参数表达那些不同的值:
1Dollars baseCharge()
2{
3 double result = usageInRange(0, 100) * 0.03;
4 result += usageInRange (100,200) * 0.05;
5 result += usageInRange (200, Integer.MAX_VALUE) * 0.07;
6 return new Dollars (result);
7}
8
9int usageInRange(int start, int end)
10{
11 if (lastUsage() > start)
12 return Math.min(lastUsage(),end) -start;
13
14 return 0;
15}技巧10 以明确函数取代参数
函数实现完全取决于参数值而采取不同反应:
1void setValue (string name, int value)
2{
3 if (name == "height")
4 _height = value;
5 else if (name == "width")
6 _width = value;
7 Assert.shouldNeverReachHere();
8}
针对该参数的每一个可能值,建立一个独立函数:
1void setHeight(int arg)
2{
3 _height = arg;
4}
5void setWidth (int arg)
6{
7 _width = arg;
8}实战练习
还是以之前统计CC值的例子:
1 U32 find (string match){
2 for(auto var : List)
3 {
4 if(var == match && from != INVALID_U32)
5 return INVALID_U32;
6 }
7 //match step1
8 if(session == getName() && key == getKey())
9 {
10 for (auto& kv : Map)
11 {
12 if (kv.second == last && match == kv.first)
13 {
14 return last;
15 }
16 }
17
18 }
19 //match step2
20 auto var = Map.find(match);
21 if(var != Map.end()&& (from != var->second)) return var->second;
22
23 //match step3
24 for(auto var: Map)
25 {
26 if((var.first, match) && from != var.second)
27 {
28 return var.second;
29 }
30 }
31 return INVALID_U32;
32 };综合运用降低CC值的技巧后:
1namespace
2{
3 struct Matcher
4 {
5 Matcher(string name, string key);
6 U32 find();
7
8 private:
9 bool except();
10 U32 matchStep1();
11 U32 matchStep2();
12 U32 matchStep3();
13
14 bool isTheSameMatch();
15
16 string match;
17 U32 from;
18 };
19
20 Matcher::Matcher(string name, string key):
21 match(name + key)
22 {
23 from = GetFrom();
24 }
25
26 U32 Matcher::find()
27 {
28 if (except())
29 return INVALID_U32;
30
31 auto result = matchStep1();
32 if (result != INVALID_U32)
33 return result;
34
35 result = matchStep2();
36 if (result != INVALID_U32)
37 return result;
38
39 return matchStep3();
40 }
41
42 bool Matcher::except()
43 {
44 for(auto var : List)
45 {
46 if(var == match && from != INVALID_U32)
47 return true;
48 }
49
50 return false;
51 }
52
53 U32 Matcher::matchStep1()
54 {
55 if(!isTheSameMatch())
56 {
57 return INVALID_U32;
58 }
59
60 for (auto& kv : Map)
61 {
62 if ( last == kv.second && match == kv.first)
63 {
64 return last;
65 }
66 }
67
68 return INVALID_U32;
69 }
70
71 bool Matcher::isTheSameMatch()
72 {
73 return match == getName() + getKey();
74 }
75
76 U32 Matcher::matchStep2()
77 {
78 auto var = Map.find(match);
79 if(var != Map.end()&& (from != var->second))
80 {
81 return var->second;
82 }
83
84 return INVALID_U32;
85 }
86
87 U32 Matcher::matchStep3()
88 {
89 for(auto var: Map)
90 {
91 if(keyMatch(var.first, match) && from != var.second)
92 {
93 return var.second;
94 }
95 }
96
97 return INVALID_U32;
98 }
99}
100
101U32 find (string match)
102{
103 Matcher matcher;
104
105 return matcher.find(match);
106}
107
该例子将匹配算法都封装到Matcher类中,并将原有逻辑通过提炼函数(技巧1)和合并条件(技巧6)将匹配逻辑抽象成能力查询、粘滞、精确匹配及模糊匹配四个步骤,这样将循环和条件分支封入小函数中,从而降低接口函数(findPno)的圈复杂度,函数职责也更加单一和清晰。整体圈复杂度从单个函数的14降到多个函数最高的5。
圈复杂度思辨
思辨1 高复杂度的代码是否可维护性差
在实际项目中为了调试方便,经常会把消息号对应的名称打印出来:
1string getMessageName(Message msg)
2{
3 switch(msg)
4 {
5 case MSG_1:
6 return "MSG_1";
7 case MSG_2:
8 return "MSG_2";
9 case MSG_3:
10 return "MSG_3";
11 case MSG_4:
12 return "MSG_4";
13 case MSG_5:
14 return "MSG_5";
15 case MSG_6:
16 return "MSG_6";
17 case MSG_7:
18 return "MSG_7";
19 case MSG_8:
20 return "MSG_8";
21 default:
22 return "MSG_UNKNOWN"
23 }
24}这段代码无论从可读性来说,还是从可维护性来说都是可以接收的。因此,当因为”高”复杂度就进行重构的话(例如:技巧2或技巧6),在降低圈复杂度的同时会带来不必要的逻辑复杂度。
当然,如果出现下面的情况的话,还是有必要进一步降低圈复杂度的:
消息数过多。
switch…case…多处重复。对于消息过多的情况,可以考虑将消息进行分类,然后采用技巧1进行重构。对于出现多处重复的情况,可以通过技巧6将同样case的内容内聚到一个具体的类的方法中,然后通过多态的方式来使用。
思辨2 复杂度相同的代码是否是一致的
例如下面两个代码片段的圈复杂度都是6。代码片段1:
1string getWeight(int i) {
2 if (i <= 0)
3 {
4 return "no weight";
5 }
6 if (i < 10)
7 {
8 return "light";
9 }
10 if (i < 20)
11 {
12 return "medium";
13 }
14 if (i < 30)
15 {
16 return "heavy";
17 }
18 if (i < 40)
19 {
20 return "very heavy";
21 }
22
23 return "super heavy"
24}
代码片段2
1int sumOfNonPrimes(int limit) {
2 bool bAdd = false;
3 int sum = 0;
4 for (int i = 0; i < limit; ++i) {
5 if (i <= 2)
6 continue;
7
8 for (int j = 2; j < i; ++j)
9 {
10 if (i % j == 0)
11 {
12 bAdd = false;
13 break;
14 }
15 bAdd = true;
16 }
17 if (bAdd)
18 sum += i;
19 }
20 return sum;
21}
但是它们的代码无论从可读性上来说,还是从可维护性来说,代码片段1应该都优于代码片段2,代码片段2的坏味道更加浓郁。因此,圈复杂度还需要具体情况具体分析,其只能作为重构的一个度量指标,作为决策的一个参考依据。
圈复杂度工具
圈复杂度的工具有很多,大致有三类:
| 类型 | 名称 | 说明 |
|---|---|---|
| 专用工具(单语言) | OCLint | C语言相关 |
| GMetrics | Java | |
| PyMetrics | python | |
| JSComplexity | js | |
| 通用工具(多语言) | lizard | 支持多种语言:C/C++ (works with C++14)、Java、C#、JavaScript、Objective C、Swift、Python、Ruby、PHP、Scala等。 |
| sourcemonitor | 免费、Windows平台。支持语言包括C、C++、C#、Java、VB、Delphi和HTML。 | |
| 通用平台 | sonarqube | 一个用于代码质量管理的开源平台,支持20多种语言。通过插件机制可集成不同的测试工具,代码分析工具及持续集成工具 |
source: //kaelzhang81.github.io/2017/06/18/详解圈复杂度

喜欢,在看