缓存之王 | Redis最佳实践&开发规范&FAQ

Redis–从问题说起
(一)Run-to-Completion in a solo thread–Redis最大的问题
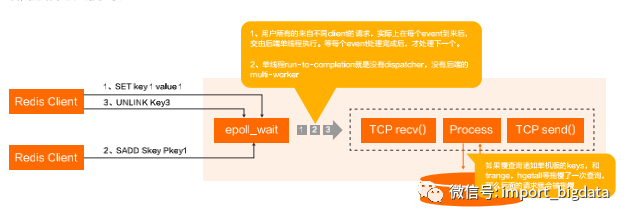
Ping命令判活:ping命令同样受到慢查询影响,如果引擎被卡住,则ping失败;
Duplex Failure:sentinel由于慢查询切备(备变主)再遇到慢查询,Redis将出现OOS。
(二)扩展为集群版,问题可解?
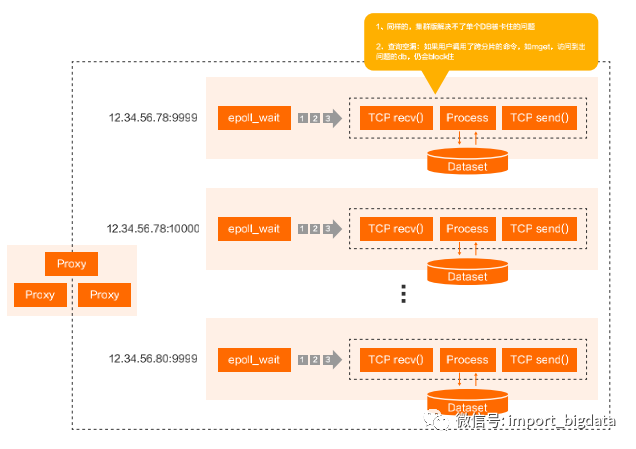
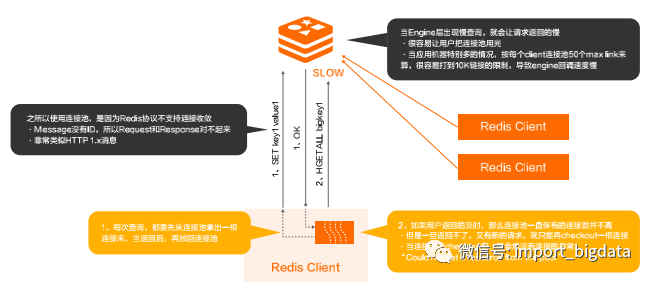
(三)Protocol问题–大量客户端与引擎Fully-Meshed问题
扩展性太差:基于Question-Answer模式,由于在Question/Answer里面没有对应的Sequence的存在,(如果不做复杂的转换wrapper层)存储引擎端没法match请求和响应,只能采用Run-To-Completion来挂住链接;

C10K的问题:当引擎挂住太多active链接的时候,性能下降太多。测试结果是当有10k active连接时,性能下降30-35%,由于引擎端挂住的链接不能被返回,用户大量报错。
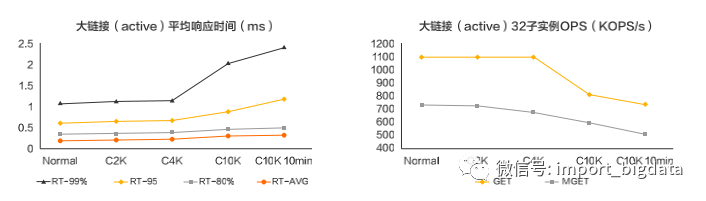
(四)“Could not get a resource from the pool”
Redis–不要触碰边界
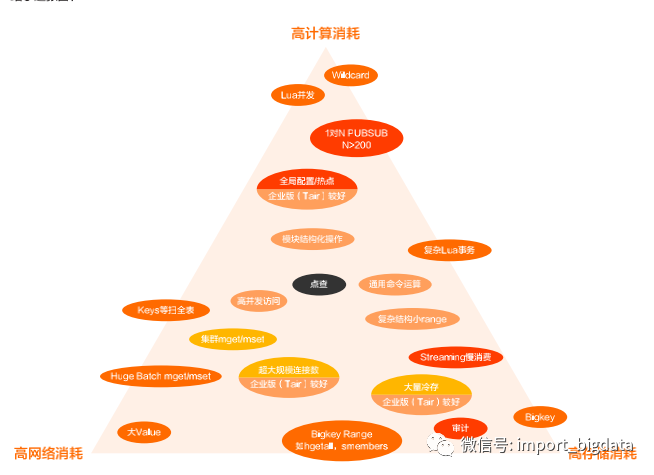
高并发不等于高吞吐 大 Value 的问题:高速存储并不会有特别大的高吞吐收益,相反会很危险;
数据倾斜和算力倾斜 bigKey 的问题:break掉存储的分配律;热点的问题,本质上是cpu上的分配律不满足;大 Range 的问题:对NoSQL的慢查询和导致的危害没有足够的重视。
存储边界 Lua使用不当造成的成本直线上升;数据倾斜带来的成本飙升,无法有效利用;
对于 Latency 的理解问题(RT高) 存储引擎的 Latency 都是P99 Latency,如:99.99%在1ms以内,99.5%在3ms以内,等;偶发性时延高是必然的。这个根因在于存储引擎内部的复杂性和熵。
Redis–阿里内部开发规约
确定场景,是缓存(cache)还是存储型;
Cache的使用原则是:“无它也可,有它更强”;
永远不要强依赖Cache,它会丢,也会被淘汰;
优先设计合理的数据结构和逻辑;
设计避免bigKey,就避免了80%的问题;
Keyspace能分开,就多申请几个Redis实例;
pubsub不适合做消息分发;
尽量避免用lua做事务。
我的服务对RT很敏感。>> 低RT能让我的服务运行的更好;
我把存储都公用在一个redis里。>> 区分cache和内存数据库用法,区分应用;
我有一个大排行榜/大集合/大链表/消息队列;我觉得服务能力足够了。>> 尽量拆散,服务能力不够可通过分布式集群版可以打散;
我有一个特别大的Value,存在redis里,访问能好些。>> redis吞吐量有瓶颈。
(一)BigKey–洪水猛兽
(二)Redis LUA JIT
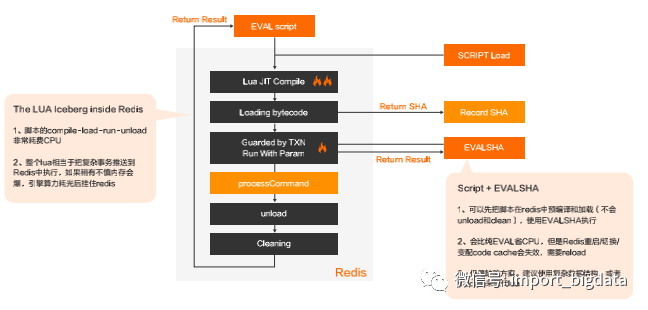
对于JIT技术在存储引擎中而言,“EVAL is evil”,尽量避免使用lua耗费内存和计算资源(省事不省心);
某些SDK(如Redisson)很多高级实现都内置使用lua,开发者可能莫名走入CPU运算风暴中,须谨慎。
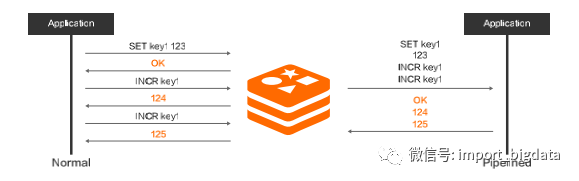
(三)Pubsub/Transaction/Pipeline
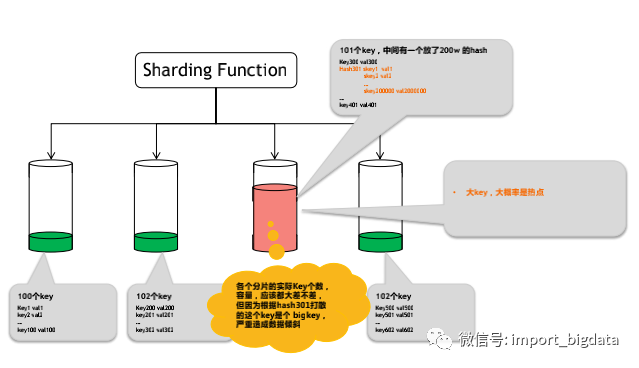
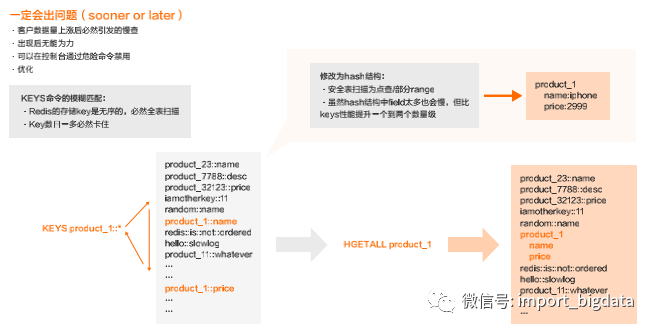
(四)KEYS 命令
Redis存储key是无序的,匹配时必然全表扫描, key数目一多必然卡住,所以一定要去优化。如下图所例子中所示,修改为hash结构:
可以从全表扫描变为点查/部分range, 虽然hash结构中field太多也会慢,但比keys性能提升一个到两个数量级。
(五)除去KEYS,下面命令依然危险
hgetall,smembers,lrange,zrange,exhgetall 直接与数据结构的subkey(field)多少相关,O(n),携带value爆网卡。建议使用scan来替代。
bitop,bitset 设置过远的bit会直接导致OOM。
flushall,flushdb 数据丢失。
配置中和ziplist相关的参数 Redis在存储相关数据结构时,数据量比较小,底层使用了ziplist结构,达到一定的量级,比如key/field变多了,会转换数据结构。当结构在ziplist结构体下时,算力开销变大,部分查询变O(n)级别,匹配变O(m*n),极端情况容易打满CPU,不过占用的内存确实变少了(需要评估带来的收益是否匹配付出的代价?)。
Cache场景,关闭AOF;内存数据库选择双副本
如果keyspace能够分开,就申请不同的实例来隔离
set/hash/zset/list/tairhash/bloom/gis等大key(内部叫做godkey)不要超过3000,会记录sillylog
避免使用keys,hgetall,lrange0-1等大range(使用scan替代)
避免使用大value(10k以上就算大value,50k会记录)
严禁设置低读超时和紧密重试(建议设置200ms以下read timeout)
需要接受P99时延,对超时和慢做容错处理
尽量使用扩展数据结构,避免使用lua
尽量避免pubsub和blocking的API
在阿里云上,如果机器宕机,或者是机器后面有风险,我们会做主动运维保证服务的稳定性。
Redis–常见问题处理
(一)Tair/Redis内存模型
链路内存(动态):主要包括Input buff、Output buff等,Input buff与Output buff跟每个客户端的连接有关系,正常情况下比较小,但是当Range操作的时候,或者有大key收发比较慢的时候,这两个区的内存会增大,影响数据区,甚至会造成OOM。还包括JIT Overhead、Fake Lua Link,包含了Code cache执行缓存等等。
数据内存:用户数据区,就是用户实际存储的value。
管理内存(静态):是静态buff,启动的时候比较小,比较恒定。这个区域主要管理data的hash开销,当key非常多的时候,比如几千万、几个亿,会占用非常大的内存。还包括Repl-buff、aof-buff(32M~64M)通常来说比较小。

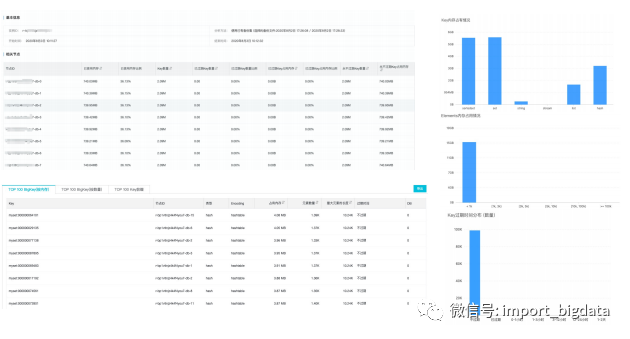
(二)缓存分析–内存分布统计、bigKey,key pattern
“实例管理”-->“CloudDBA”-->“缓存分析”-->“立即分析”;热Key分析无需主动触发。
支持已有备份集;
支持自动新建备份集。
社区版(2.8~6.0);
企业版(Tair)。
标准版;
读写分离版;
集群版。
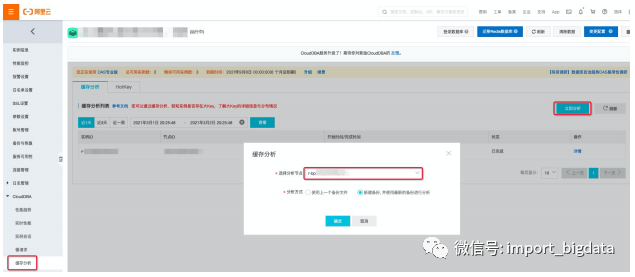
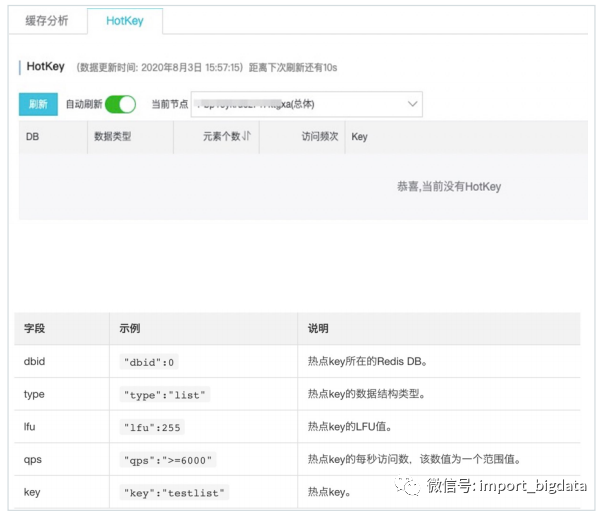
(三)热Key分析
使用入口:“实例管理” --> “CloudDBA” --> “缓存分析” -->“HotKey”;
使用须知:Tair版,或Redis版本>=redis4.0;
精确统计(非采样),能抓出当前所有 Per Key QPS > 3000的记录;
方法1:缓存分析也可以分析出相对较热的key,通过工具实现;
方法2:最佳实践,imonitor命令 + redis-faina 分析出热点Key;
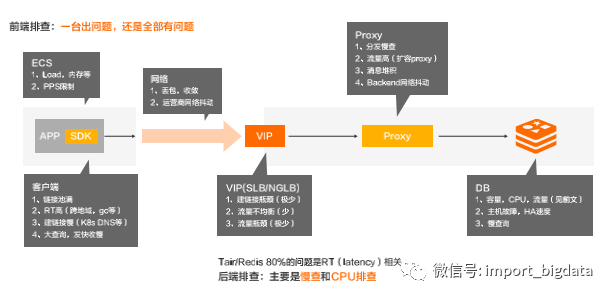
(四)Tair/Redis全链路诊断
ECS
Load,内存等;
PPS限制。
客户端
链接池满;
RT高(跨地域,gc等);
建链接慢(K8s DNS等);
大查询,发快收慢。
网络
丢包,收敛;
运营商网络抖动。
VIP(SLB/NGLB)
建链接瓶颈(极少);
流量不均衡(少);
流量瓶颈(极少)。
Proxy
分发慢查;
流量高(扩容proxy);
消息堆积;
Backend网络抖动。
DB
容量,CPU,流量(见前文);
主机故障,HA速度;
慢查询。
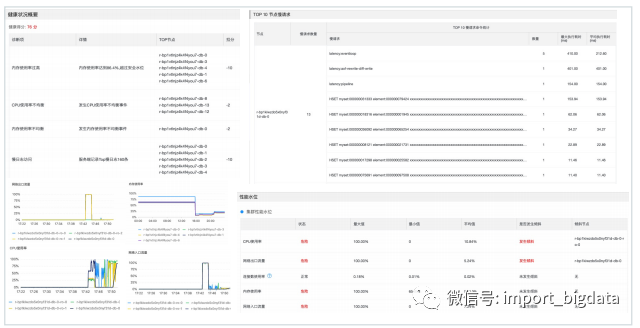
(五)Tair/Redis诊断报告
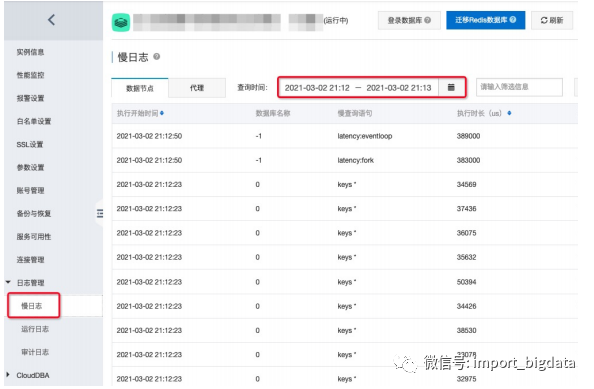
(六)Tair/Redis慢日志
slowlog-log-slower-than:DB分片上慢日志阈值,不可设置过低!;
slowlog-max-len:DB分片slowlog链表最大保持长度;
rt_threshold_ms:Proxy上慢日志阈值,不可设置过低!。

使用入口:“实例管理” --> “日志管理” --> “慢日志”;
使用须知:Tair版,或Redis版本>=redis4.0,具体查看帮助文档;
可获取近72小时内的慢日志。
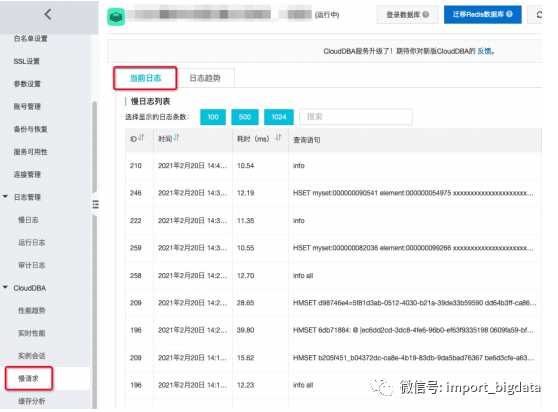
使用入口:“实例管理” --> “CloudDBA” --> “慢请求”;
实时获取,能抓出当前所有分片slowlog。