
GitHub 上有哪些优秀的 Python 爬虫项目?
大家好,我是一行
爬虫这种项目,只要博主不去维护,那过段时间也都会失效
毕竟是作为一门被动技术,只要网站守方更新防御机制,那爬虫攻方也得更新策略
所以就经常会有小伙伴来问我,怎么爬不了呢?就是规则改了没人维护了呗
这里一行推荐几个最受大家欢迎的Python项目,毕竟热度越高,博主维护的积极性也是越高
1最简单的爬虫不用代码
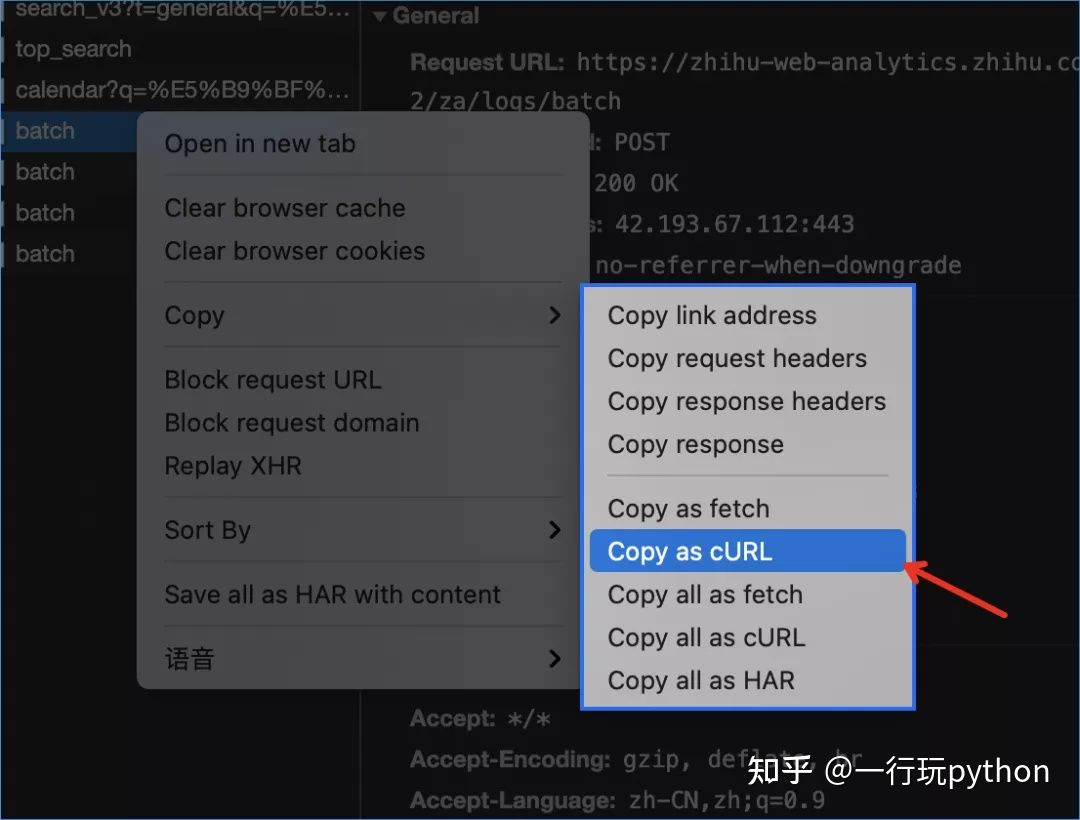
首先是简单的爬虫脚本生成器,那些低难度的爬虫脚本全都可以使用生成器生成
只要复制对应网站的cURl数据,复制粘贴到生成器里,3秒就能生成对应语言的爬虫脚本,而且12种语言任意选择转换(Python,Ansible URI,MATLAB,Node.js,R,PHP,Strest,Go,Dart,JSON,Elixir,Rust)
2一些非常有趣的python爬虫例子
一些常见的网站爬虫例子,代码通用性较高,时效性较久。项目代码对新手比较友好,尽量用简单的python代码,并配有大量注释。
毕竟下面这些爬虫小例子弄懂之后,你才能说爬虫入了门:
淘宝模拟登录
天猫商品数据爬虫(已模拟登录)
淘宝已买到的宝贝数据爬虫(已模拟登录)
每天不同时间段通过微信发消息提醒女友
爬取5K分辨率超清唯美壁纸
爬取豆瓣排行榜电影数据(含GUI界面版)
爬取天天基金网所有基金数据
一键生成微信个人专属数据报告(了解你的微信社交历史)
一键生成QQ个人历史报告
一键生成个人微信朋友圈数据电子书
一键分析你的上网行为(web页面可视化)
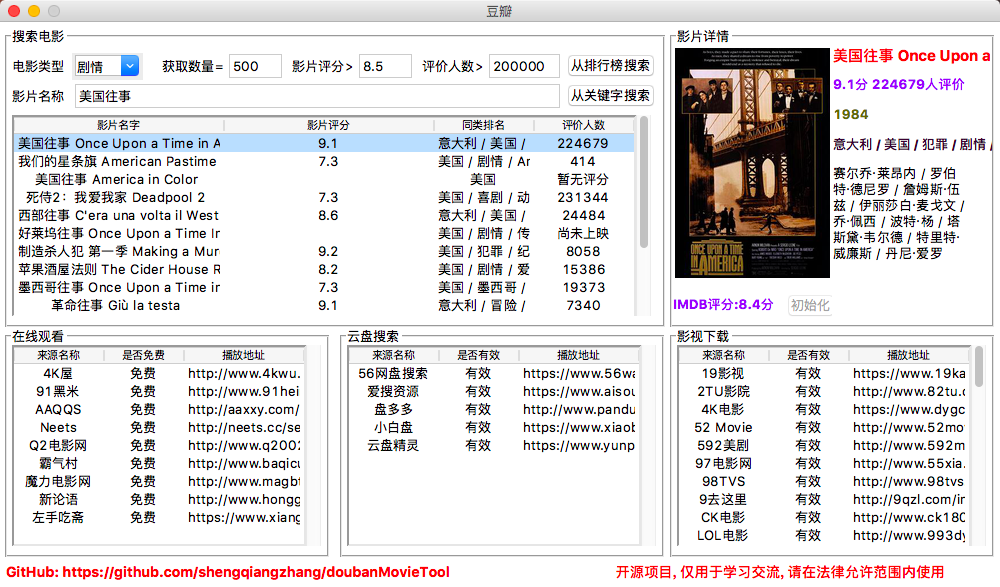
项目地址:https://github.com/shengqiangzhang/examples-of-web-crawlers
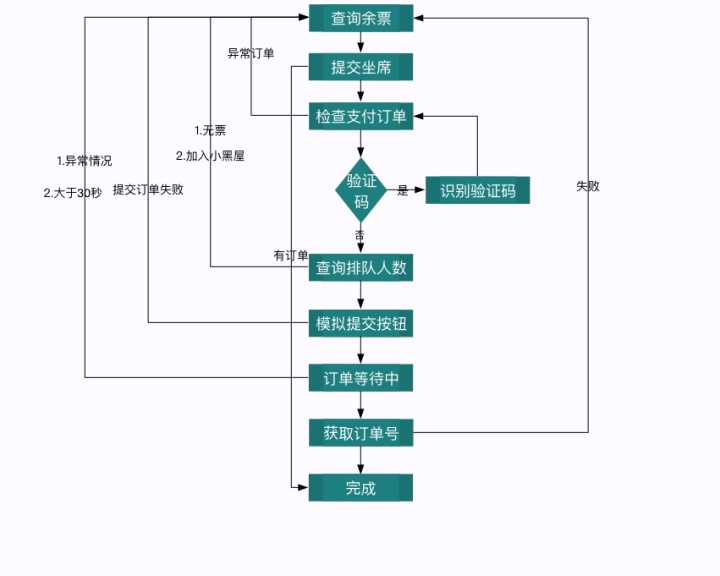
312306智能订票
这个项目实现12306 自动打码、自动登录、准点预售和捡漏、智能候补、邮件通知、server通知
可以说什么转发凑加速包再也用不上了
4ProxyPool 爬虫代理IP池
没有代理的爬虫,永远成不了规模的爬虫
这个爬虫代理IP池项目,主要功能为定时采集网上发布的免费代理验证入库,定时验证入库的代理保证代理的可用性,提供API和CLI两种使用方式。
同时你也可以扩展代理源以增加代理池IP的质量和数量。
你知道的越多,你不知道也就越多
今天的分享就先到这,技术永不眠,我们下期见
当然Python相关的电子书我也给整理好了在下面👇
