
Mysql的binlog和relay-log到底长啥样?
上一篇mysql面试的文章之后收到不少朋友的意见,希望深入讲讲复制、日志的格式这些,今天,我们就来深挖一下mysql的复制机制到底有哪一些,以及binlog和relay-log的结构到底是什么样子的。
binlog作用
binlog的主要作用是记录数据库中表的更改,它只记录改变数据的sql,不改变数据的sql不会写入,比如select语句一般不会被记录,因为他们不会对数据产生任何改动。
用一个实际的场景看下binlog产生的过程,准备sql:
create table test(text varchar(20));
insert into test values ('test_text');
select * from test;
flush logs;
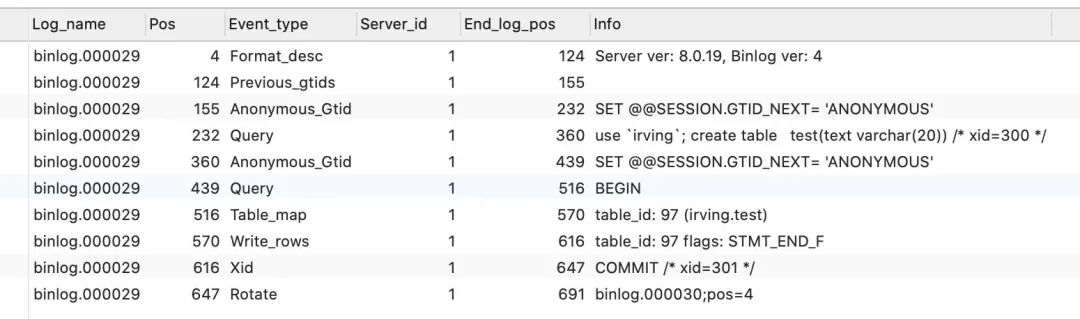
查看binlog
show binlog events in 'binlog.000029';
显示的结果如下:
另外,也可以使用mysqlbinlog工具来查看binlog的内容:
show variables like 'log_%'; #查看日志目录
mysqlbinlog --short-form --force-if-open --base64-output=never /usr/local/var/mysql/binlog.000029
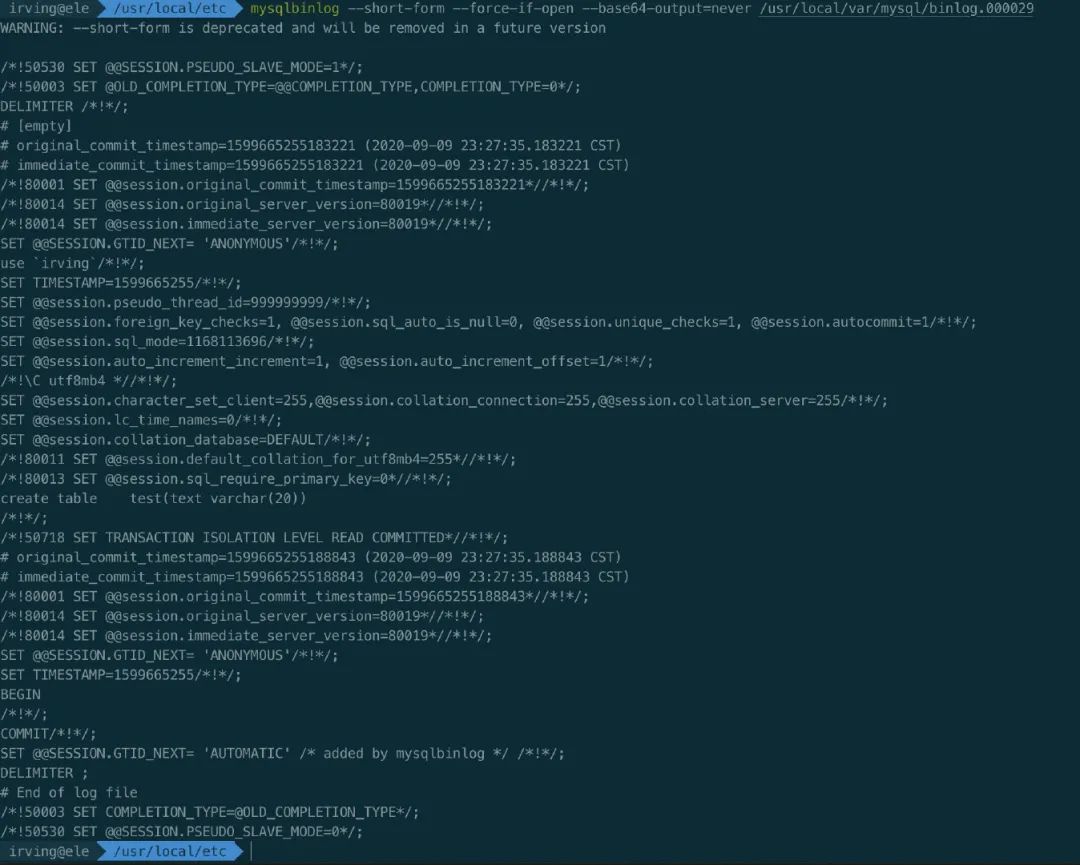
从日志我们可以看到执行了创建表的语句以及一个Format_desc头和Ratate轮换事件,这个我们会在后面讲到,先看几个字段代表的含义。
Log_name代表日志文件的名称,比如我这里的查询是直接查询binlog.000029,默认的写法是show binlog events,但是这样只会查询到第一个binlog,并不是当前激活状态的binlog,如果你不知道binlog有哪些,可以用命令:
show binary logs; #查看binlog列表
show master status; #查看最新的binlog
Pos代表文件开始的位置。
Event_type代表事件的类型。
Server_id是创建事件的服务器ID。
End_log_pos代表事件在文件中的结束位置,以上面为例,第一次查询的结束位置是723,第二次insert之后文件的开始位置就是从723开始。
Info代表事件信息,是一段可读的文本内容。
binlog日志结构
binlog日志的结构大概是长这样的,它由索引文件和binlog文件组成,其中binlog事件又包含通用头、提交头和事件体3个部分组成。
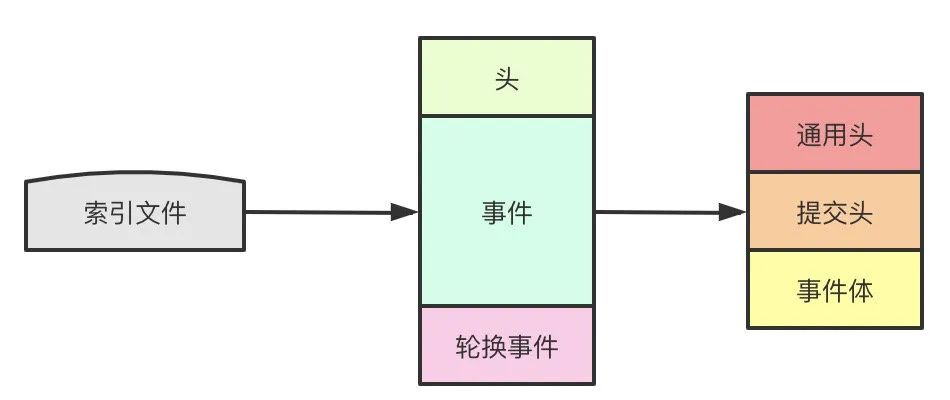
首先说说索引文件,索引文件的每一行都包含了一个binlog文件的完整文件名(类似host-bin.001),一些命令比如flush logs将所有日志写入磁盘会影响到索引文件。
每个binlog文件以若干个binlog事件组成,以格式描述事件(Format_description)作为文件头(上面的binlog图片Format_desc事件),以日志轮换事件(rotate)作为文件尾。
Format_description包含binlog文件的服务器信息、文件状态的关键信息等。如果服务器关闭或者重启,则会创建一个新的binlog文件,同时写入一个新的format_description。他的格式大致如下。
2 binlog-version
string[50] mysql-server version
4 create timestamp
1 event header length
string[p] event type header lengths
日志轮换事件则包含下一个binlog的文件名以及开始读取的位置,它由服务器写完binlog后添加到文件尾,轮换事件并不会每次都存在,格式如下。
if binlog-version > 1 {
8 position
}
string[p] name of the next binlog
binlog事件包含若干个事务组成的组(group),每个组对应一个事务,如果是create alter语句不属于事务语句的话,则他们本身就是一个组,每个组要么全部执行,要么都不执行。
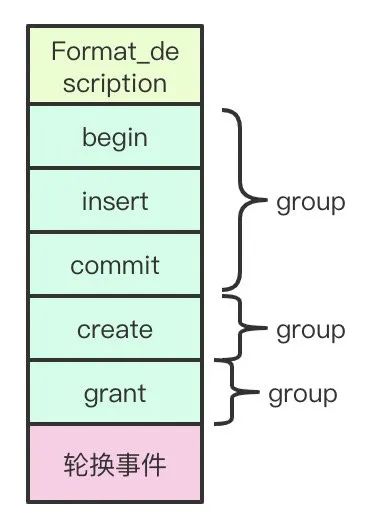
binlog事件结构
每个binlog事件由3个部分组成:
通用头,包含binlog中所有事件具备的基本信息。 提交头,对于不同类型的事件来说,提交头的内容也不尽相同 事件体,存储事件的主要数据,同样对于不同类型事件也不同。
binlog轮换和清理
从上面的例子我们也可以看出来,binlog并非只有一个,而基于真实的场景来说,始终写一个binlog文件肯定也是不可取的,而binlog轮换主要有3个场景:
服务器启动,每次服务器启动都会生成一个新的binlog文件。 达到最大大小,可以通过binlog-cache-size控制大小,达到最大大小后将更换。 显示刷新,flush logs将所有日志写入磁盘,这时候会创建一个新的文件写入,从第一个例子也能看出来执行完之后生成了一个新的日志binlog.000030的文件并且开始的位置是4。

随着时间的推移,我们的binlog文件会越来越多,这时候有两种方式可以清除binlog:
通过设置expire-logs-days控制想保留的binlog日志文件天数,系统将会自动清理。 通过PURGE BINARY LOGS手动清理
relay-log结构
relay-log中继日志是连接master和slave的核心,我们来深入了解一下它的结构和使用。
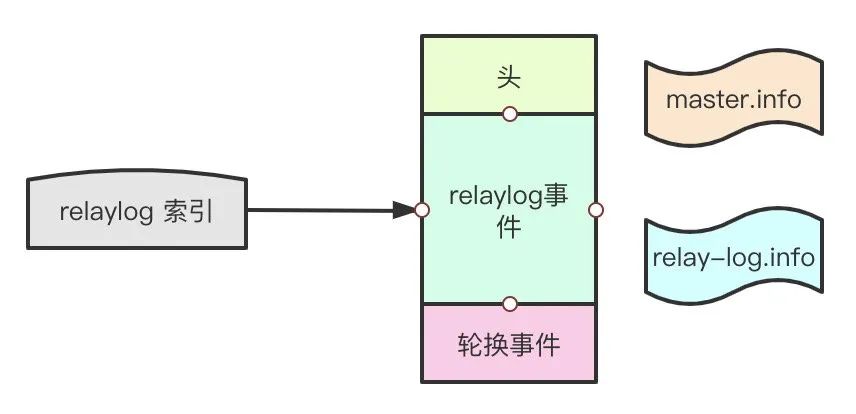
relay-log的结构和binlog非常相似,只不过他多了一个master.info和relay-log.info的文件。
master.info记录了上一次读取到master同步过来的binlog的位置,以及连接master和启动复制必须的所有信息。
relay-log.info记录了文件复制的进度,下一个事件从什么位置开始,由sql线程负责更新。
上一篇文章我们提到了整个复制流程的过程大概是这个样子:
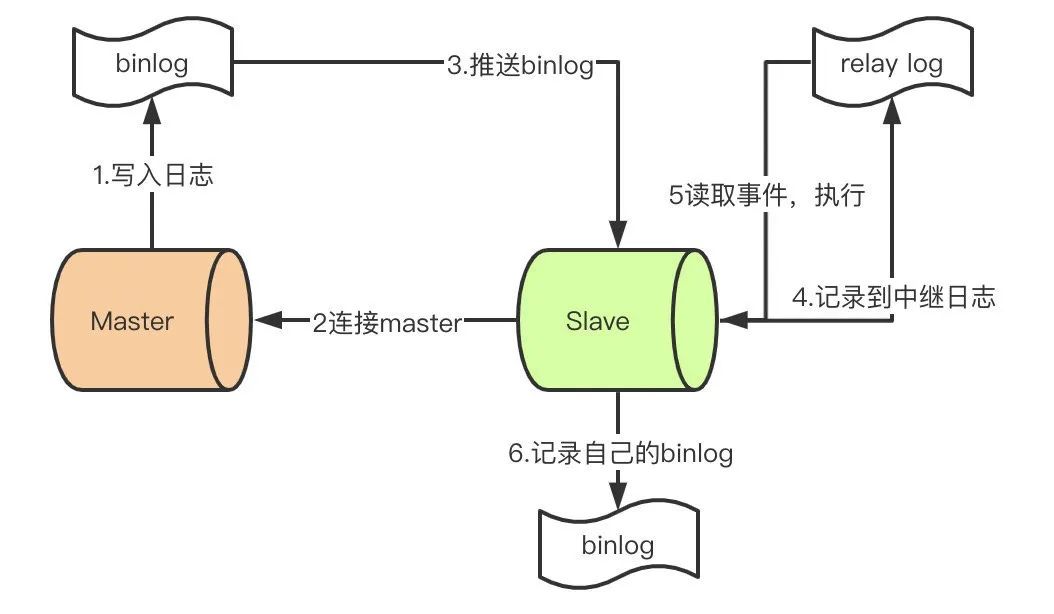
知道binlog和relay-log的结构之后,我们重新梳理一下整个链路的流程,这里我们假定master.info和relay-log.info都是存在的情况:
Master收到客户端请求语句,在语句结束之前向二进制日志写入一条记录,可能包含多个事件。 此时,一个Slave连接到Master,Master的dump线程从binlog读取日志并发送到Slave的IO线程。 IO线程从master.info读取到上一次写入的最后的位置。 IO线程写入日志到relay-log中继日志,如果超过指定的relay-log大小,写入轮换事件,创建一个新的relay-log。 更新master.info的最后位置 SQL线程从relay-log.info读取进上一次读取的位置 SQL线程读取日志事件 在数据库中执行sql 更新relay-log.info的最后位置 Slave记录自己的binlog日志
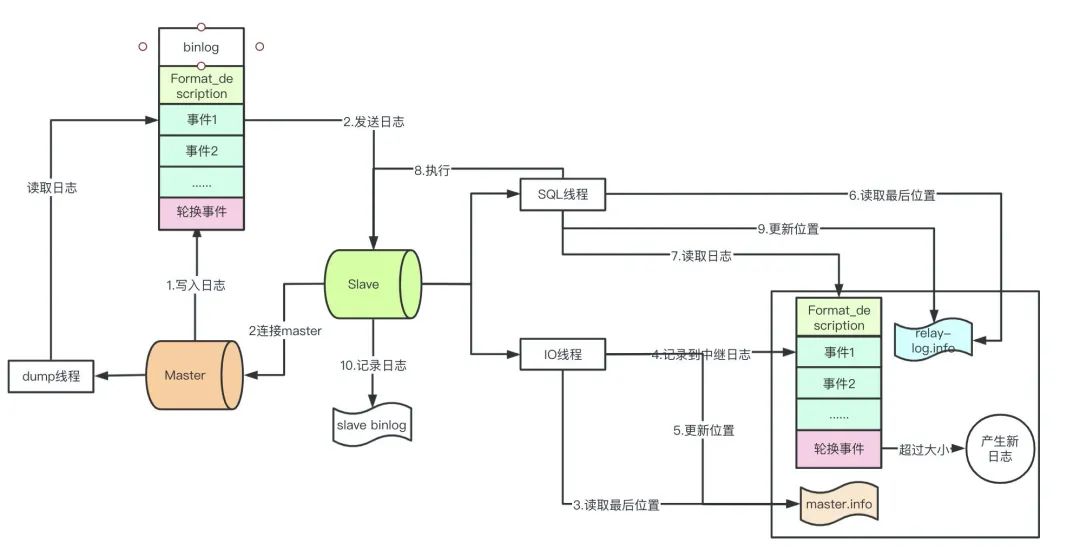
但是在这里IO和SQL线程有会产生重复事件的问题,举一个场景:
先记录中继日志,然后更新master.info位置 此时服务器崩溃,写入master.info失败 服务器恢复,再次同步从master.info获取到的是上一次的位置,会导致事件重复执行
既然会有这个问题还为什么要这样做呢?假设反过来,先更新master.info再记录中继日志,这样带来的问题就是丢失数据了。而mysql认为丢失比重复更严重,所以要先刷新日志,保大还是保小mysql帮你做了决定。
推荐阅读