
【Python】太6了!用Python快速开发数据库入库系统
本文示例代码已上传至我的
❞Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
这是我的系列教程「Python+Dash快速web应用开发」的第十二期,在以前撰写过的静态部件篇(中)那期教程中,我们介绍过在Dash中创建静态表格的方法。
而在实际的使用中,我们很多时候在网页中渲染的表格不仅仅是为了对数据进行展示,还需要更多交互能力,譬如「按列排序」、「动态修改表中数值」等特性,以及对「大型数据表」的「快速渲染查看」能力,诸如此类众多的交互功能在Dash自带的dash_table中已经实现。
而接下来的几期,我们就将针对如何利用dash_table创建具有丰富交互功能的表格进行介绍,今天介绍的是dash_table的基础使用方法。

2 dash_table基础使用
作为Dash自带的拓展库,我们通过下列语句导入dash_table:
import dash_table
接着像之前使用其他的Dash部件一样,在定义layout时将dash_table.DataTable()对象置于我们定义的合适位置即可,可参考下面的例子配合pandas的DataFrame来完成最简单的表格的渲染。
其中参数columns用于设置每一列对应的名称与id属性,data接受由数据框转化而成的特殊格式数据,virtualization设置为True代表使用了「虚拟化」技术来加速网页中大量表格行数据的渲染:
❝app1.py
❞
import dash
import dash_html_components as html
import dash_bootstrap_components as dbc
import dash_table
import seaborn as sns
app = dash.Dash(__name__)
# 载入演示数据集
df = sns.load_dataset('iris')
# 创建行下标列
df.insert(loc=0, column='#', value=df.index)
app.layout = html.Div(
dbc.Container(
dash_table.DataTable(
columns=[{'name': column, 'id': column} for column in df.columns],
data=df.to_dict('records'),
virtualization=True
),
style={
'margin-top': '100px'
}
)
)
if __name__ == '__main__':
app.run_server(debug=True)
如果你对数据的展示完全没要求,看个数就行,那上述的这套基础的参数设置你就可以当成万金油来使用,而如果你觉得dash_table.DataTable「默认」太丑了(大实话),那么请继续阅读今天的教程。
2.1 自定义表格基础样式
针对DataTable所渲染出的表格的几个基础构成部分,我们可以使用到的用于修改表格样式的参数有style_table、style_cell、style_header、style_data等:
「使用style_table来自定义表格外层容器样式」
参数style_table用于对整个表格最外层的容器样式传入css键值对进行修改,一般用来设定表格的高度、宽度、周围留白或对齐等属性:
❝app2.py
❞
import dash
import dash_html_components as html
import dash_bootstrap_components as dbc
import dash_table
import seaborn as sns
app = dash.Dash(__name__)
# 载入演示数据集
df = sns.load_dataset('iris')
# 创建行下标列
df.insert(loc=0, column='#', value=df.index)
app.layout = html.Div(
dbc.Container(
[
dash_table.DataTable(
columns=[{'name': column, 'id': column} for column in df.columns],
data=df.to_dict('records'),
virtualization=True,
style_table={
'height': '200px',
'margin-top': '100px'
}
),
html.Hr(),
dash_table.DataTable(
columns=[{'name': column, 'id': column} for column in df.columns],
data=df.to_dict('records'),
virtualization=True,
style_table={
'height': '200px',
'margin-left': '80px',
'width': '300px'
}
),
html.Hr(),
dash_table.DataTable(
columns=[{'name': column, 'id': column} for column in df.columns],
data=df.to_dict('records'),
virtualization=True,
style_table={
'height': '150px',
'width': '50%',
'margin-left': '50%'
}
)
],
style={
'background-color': '#bbdefb'
}
)
)
if __name__ == '__main__':
app.run_server(debug=True)

「使用style_cell、style_header与style_data定义单元格样式」
不同于style_table,使用style_cell可以传入css将样式应用到所有「单元格」,而style_header与style_data则更加有针对性,可分别对标题单元格、数据单元格进行设置:
❝app3.py
❞
import dash
import dash_html_components as html
import dash_bootstrap_components as dbc
import dash_table
import seaborn as sns
app = dash.Dash(__name__)
# 载入演示数据集
df = sns.load_dataset('iris')
# 创建行下标列
df.insert(loc=0, column='#', value=df.index)
app.layout = html.Div(
dbc.Container(
[
dash_table.DataTable(
columns=[{'name': column, 'id': column} for column in df.columns],
data=df.to_dict('records'),
virtualization=True,
style_table={
'height': '300px'
},
style_cell={
'background-color': '#fff9c4',
'font-family': 'Times New Romer',
'text-align': 'center'
}
),
html.Hr(),
dash_table.DataTable(
columns=[{'name': column, 'id': column} for column in df.columns],
data=df.to_dict('records'),
virtualization=True,
style_table={
'height': '300px'
},
style_header={
'background-color': '#b3e5fc',
'font-family': 'Times New Romer',
'font-weight': 'bold',
'font-size': '17px',
'text-align': 'left'
},
style_data={
'font-family': 'Times New Romer',
'text-align': 'left'
}
)
],
style={
'margin-top': '100px'
}
)
)
if __name__ == '__main__':
app.run_server(debug=True)
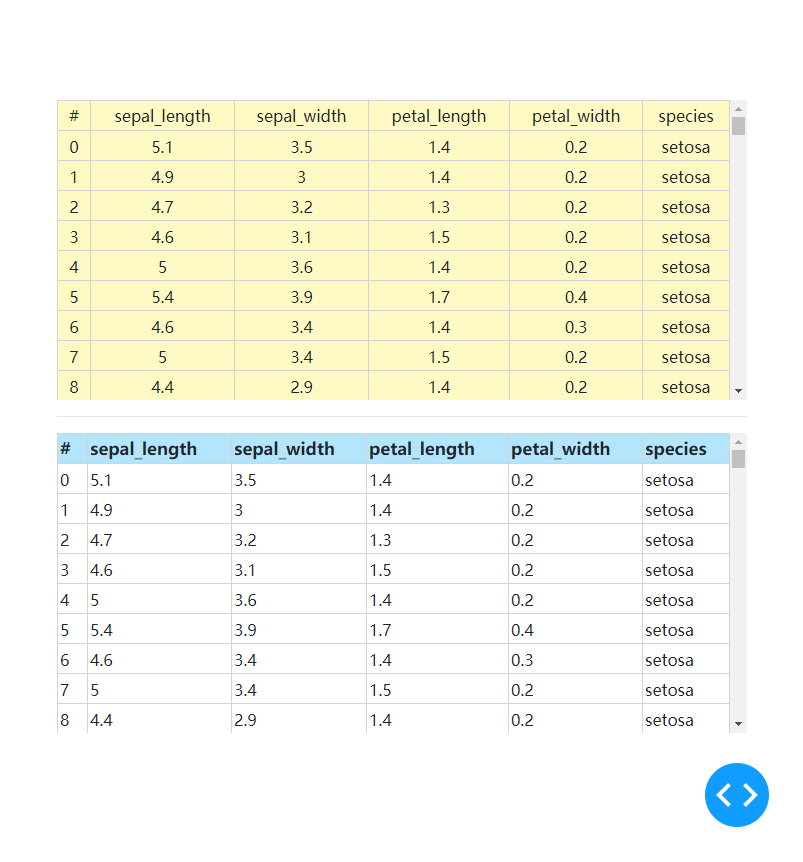
「条件样式设置」
除了像上文所演示的那样针对某一类表格构成元素进行整体样式设置外,DataTable还为我们提供了条件样式设置,比如我们想为特殊的几列单独设置样式,或者为奇数下标与偶数下标行设置不同的样式,就可以使用到这一特性。
这在DataTable中我们可以利用style_header_conditional与style_data_conditional来传入列表,列表中每个元素都可看做是带有额外if键值对的css参数字典,而这个if键值对的值亦为一个字典,其接受的键值对种类丰富,我们今天先来介绍column_id与row_index,它们分别用来指定对应「id」的header与整行单元格。
参考下面这个例子,我们分别特殊设置#列的表头与奇数行的样式:
❝app4.py
❞
import dash
import dash_html_components as html
import dash_bootstrap_components as dbc
import dash_table
import seaborn as sns
app = dash.Dash(__name__)
# 载入演示数据集
df = sns.load_dataset('iris')
# 创建行下标列
df.insert(loc=0, column='#', value=df.index)
app.layout = html.Div(
dbc.Container(
[
dash_table.DataTable(
columns=[{'name': column, 'id': column} for column in df.columns],
data=df.to_dict('records'),
virtualization=True,
style_table={
'height': '500px'
},
style_cell={
'font-family': 'Times New Romer',
'text-align': 'center'
},
style_header_conditional=[
{
'if': {
# 选定列id为#的列
'column_id': '#'
},
'font-weight': 'bold',
'font-size': '24px'
}
],
style_data_conditional=[
{
'if': {
# 选中行下标为奇数的行
'row_index': 'odd'
},
'background-color': '#cfd8dc'
}
]
)
],
style={
'margin-top': '100px'
}
)
)
if __name__ == '__main__':
app.run_server(debug=True)
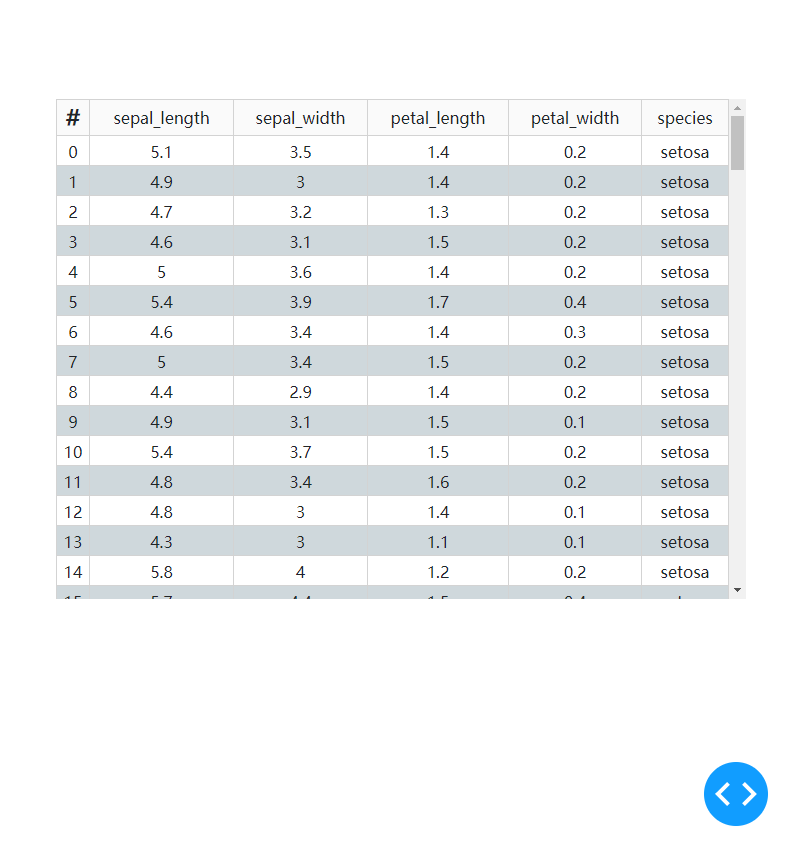
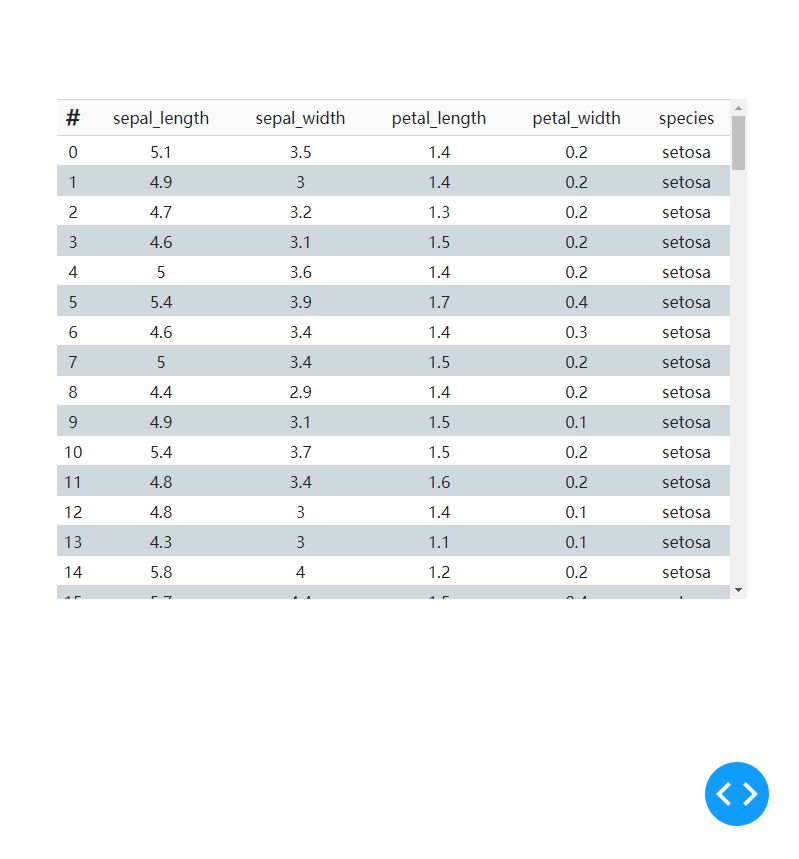
「隐藏所有竖直框线」
设置参数style_as_list_view为True可以隐藏所有竖向的框线,app4设置之后的效果如下:
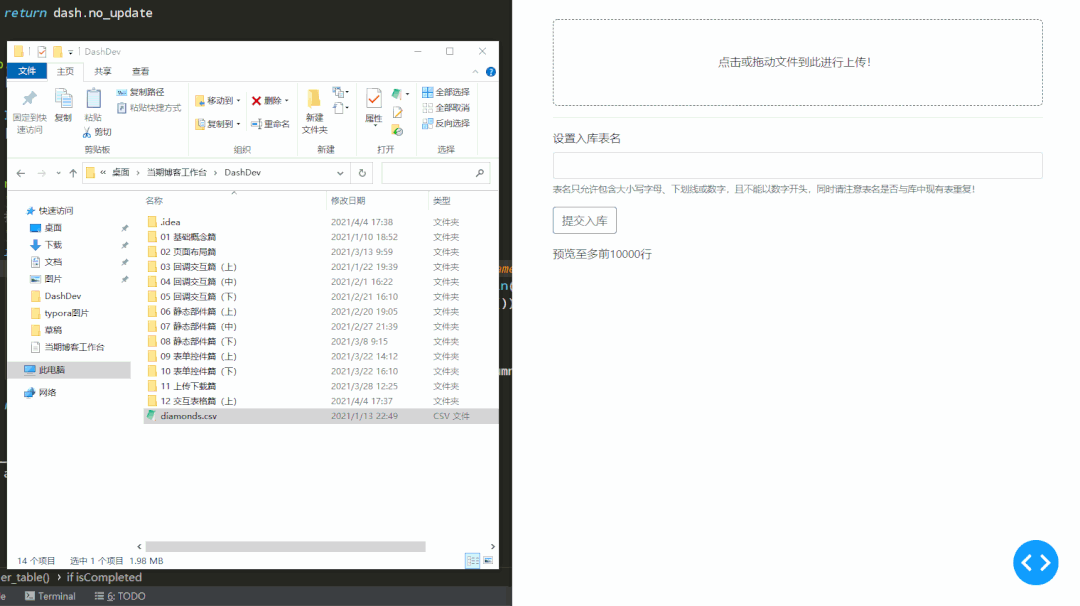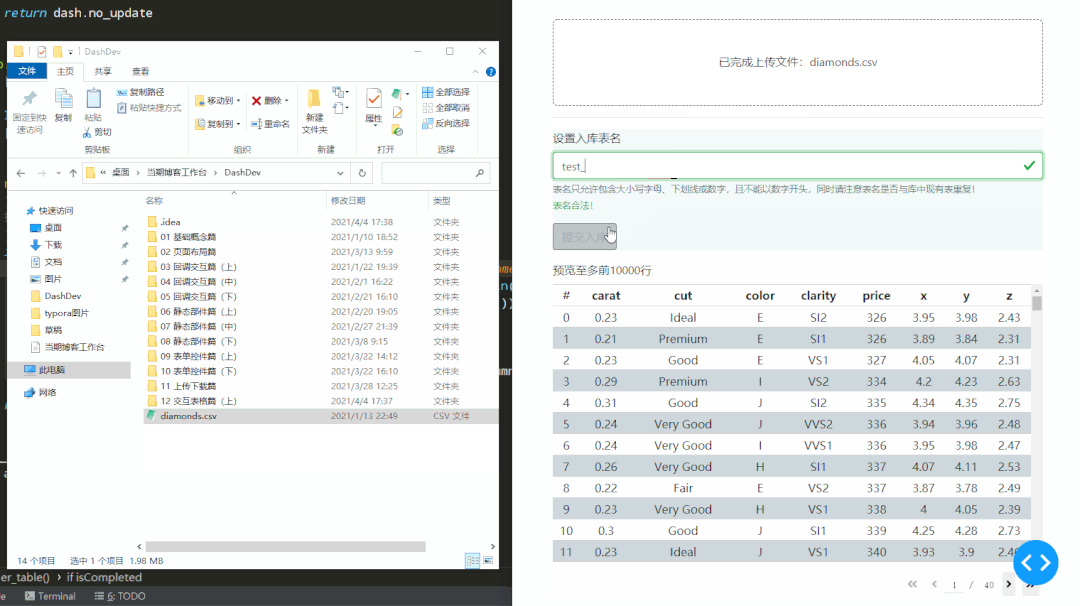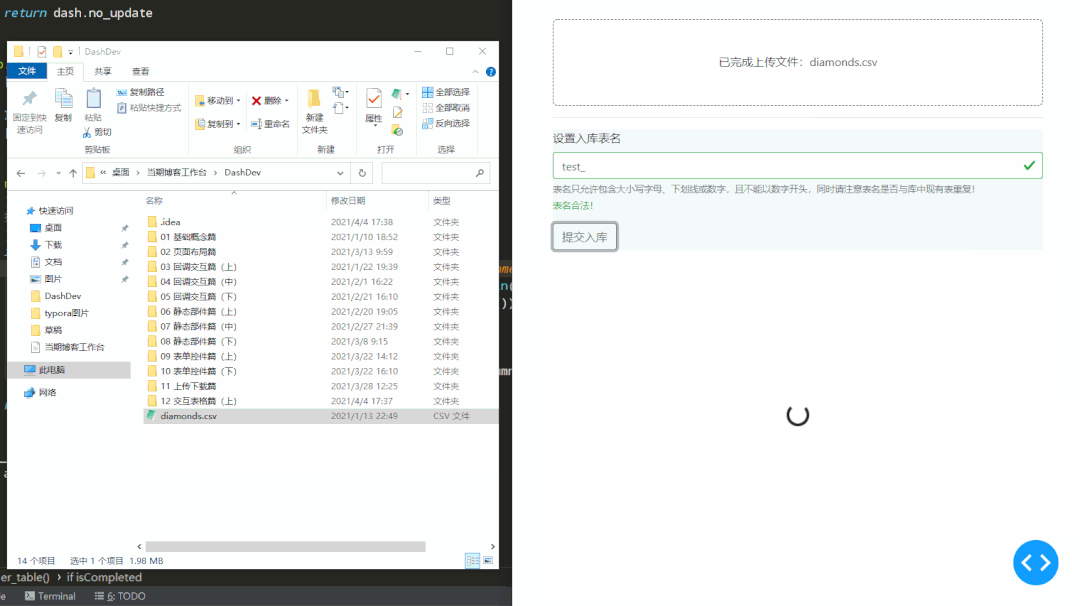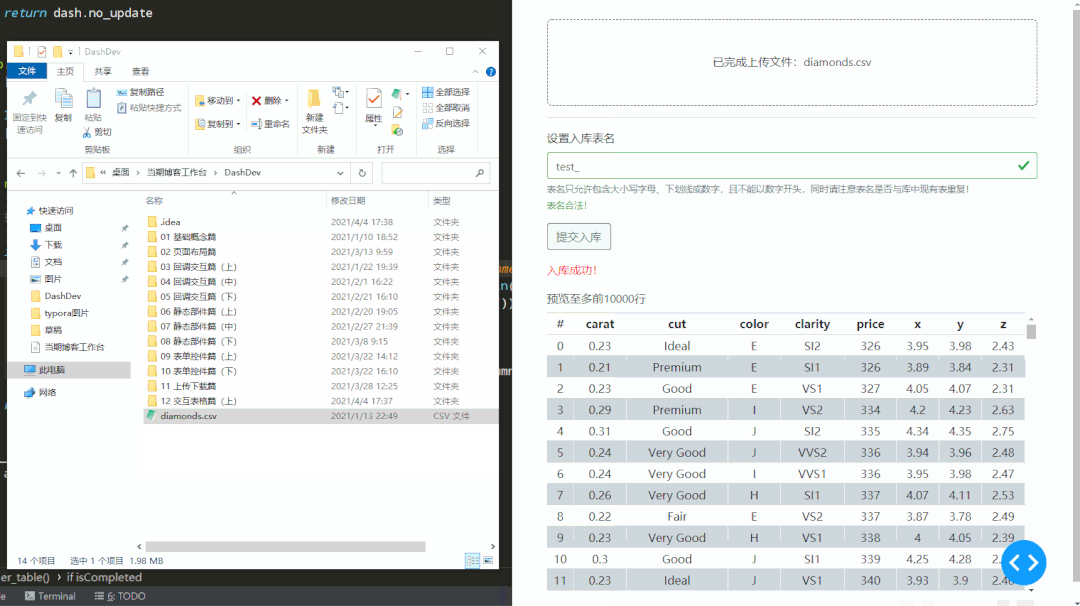
3 动手制作一个数据入库应用
学习完今天的内容之后,我们来动手写一个简单的数据入库应用,通过拖入本地csv文件以及填写入库表名,来实现对上传数据的预览与数据库导入,后端会自动检查用户输入的数据表名称是否合法,并自动检测上传csv文件的文件编码。
下面就是该应用工作时的情景,其中因为test表在库中已存在,所以会被检测出不合法:
而当上传的数据表行数较多时,右下角会自动出现分页部件,我们将在下一期中进行讨论,完整代码如下:
❝app5.py
❞
import dash
import dash_html_components as html
import dash_bootstrap_components as dbc
from dash.dependencies import Input, Output, State
import dash_table
import dash_uploader as du
import re
import os
import pandas as pd
from sqlalchemy import create_engine
import cchardet as chardet # 用于自动识别文件编码
postgres_url = 'postgresql://postgres:CUDLCUDL@localhost:5432/Dash'
engine = create_engine(postgres_url)
app = dash.Dash(__name__)
du.configure_upload(app, 'upload')
app.layout = html.Div(
dbc.Container(
[
du.Upload(
id='upload',
filetypes=['csv'],
text='点击或拖动文件到此进行上传!',
text_completed='已完成上传文件:',
cancel_button=True,
pause_button=True),
html.Hr(),
dbc.Form(
[
dbc.FormGroup(
[
dbc.Label("设置入库表名", html_for="table-name"),
dbc.Input(
id='table-name',
autoComplete='off'
),
dbc.FormText(
"表名只允许包含大小写字母、下划线或数字,且不能以数字开头,同时请注意表名是否与库中现有表重复!", color="secondary"
),
dbc.FormFeedback(
"表名合法!", valid=True
),
dbc.FormFeedback(
"表名不合法!",
valid=False,
),
]
),
dbc.FormGroup(
[
dbc.Button('提交入库', id='commit', outline=True)
]
)
],
style={
'background-color': 'rgba(224, 242, 241, 0.4)'
}
),
dbc.Spinner(
[
html.P(id='commit-status-message', style={'color': 'red'}),
dbc.Label('预览至多前10000行', html_for='uploaded-table'),
dash_table.DataTable(
id='uploaded-table',
style_table={
'height': '400px'
},
virtualization=True,
style_as_list_view=True,
style_cell={
'font-family': 'Times New Romer',
'text-align': 'center'
},
style_header={
'font-weight': 'bold'
},
style_data_conditional=[
{
'if': {
# 选中行下标为奇数的行
'row_index': 'odd'
},
'background-color': '#cfd8dc'
}
]
)
]
)
],
style={
'margin-top': '30px'
}
)
)
@app.callback(
[Output('table-name', 'invalid'),
Output('table-name', 'valid')],
Input('table-name', 'value')
)
def check_table_name(value):
''''
检查表名是否合法
'''
if value:
# 查询库中已存在非系统表名
exists_table_names = (
pd
.read_sql('''SELECT tablename FROM pg_tables''', con=engine)
.query('~(tablename.str.startswith("pg") or tablename.str.startswith("sql_"))')
)
if (re.findall('^[A-Za-z0-9_]+$', value)[0].__len__() == value.__len__()) \
and not re.findall('^\d', value) \
and value not in exists_table_names['tablename'].tolist():
return False, True
return True, False
return dash.no_update
@app.callback(
Output('commit-status-message', 'children'),
Input('commit', 'n_clicks'),
[State('table-name', 'valid'),
State('table-name', 'value'),
State('upload', 'isCompleted'),
State('upload', 'fileNames'),
State('upload', 'upload_id')]
)
def control_table_commit(n_clicks,
table_name_valid,
table_name,
isCompleted,
fileNames,
upload_id):
'''
控制已上传表格的入库
'''
if all([n_clicks, table_name_valid, table_name, isCompleted, fileNames, upload_id]):
uploaded_df = pd.read_csv(os.path.join('upload', upload_id, fileNames[0]),
encoding=chardet.detect(open(os.path.join('upload', upload_id, fileNames[0]),
'rb').read())['encoding'])
uploaded_df.to_sql(table_name, con=engine)
return '入库成功!'
return dash.no_update
@app.callback(
[Output('uploaded-table', 'data'),
Output('uploaded-table', 'columns')],
Input('upload', 'isCompleted'),
[State('upload', 'fileNames'),
State('upload', 'upload_id')]
)
def render_table(isCompleted, fileNames, upload_id):
'''
控制预览表格的渲染
'''
if isCompleted:
uploaded_df = pd.read_csv(os.path.join('upload', upload_id, fileNames[0]),
encoding=chardet.detect(open(os.path.join('upload', upload_id, fileNames[0]),
'rb').read())['encoding']).head(10000)
uploaded_df.insert(0, '#', range(uploaded_df.shape[0]))
return uploaded_df.to_dict('record'), [{'name': column, 'id': column} for column in uploaded_df.columns]
return dash.no_update
if __name__ == '__main__':
app.run_server(debug=True)
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
往期精彩回顾
本站qq群851320808,加入微信群请扫码: