
超级轻量级: KV存储引擎实现
Hi (๑╹◡╹)ノ”,各位
Gopher本人最近又用Go造了一个轮子,一个超级轻量级KV存储引擎,欢迎👏🏻各位Gopher进行评测。
主页介绍:https://bottle.ibyte.me (PC效果更佳😋)
项目地址:https://github.com/auula/bottle
特 性
嵌入的存储引擎 数据可以加密存储 可以自定义实现存储加密器 即使数据文件被拷贝,也保证存储数据的安全 未来索引数据结构也可以支持自定义实现
简 介
首先要说明的是Bottle是一款KV嵌入式存储引擎,并非是一款KV数据库,我知道很多人看到了KV认为是数据库,当然不是了,很多人会把这些搞混淆掉,KV存储可以用来存储很多东西,而并非是数据库这一领域。可以这么理解数据库是一台汽车,那么Bottle是一台车的发动机。可以简单理解Bottle是一个对操作系统文件系统的KV抽象化封装,可以基于Bottle做为存储层,在Bottle层之上封装一些数据结构和对外服务的协议就可以实现一个数据库。
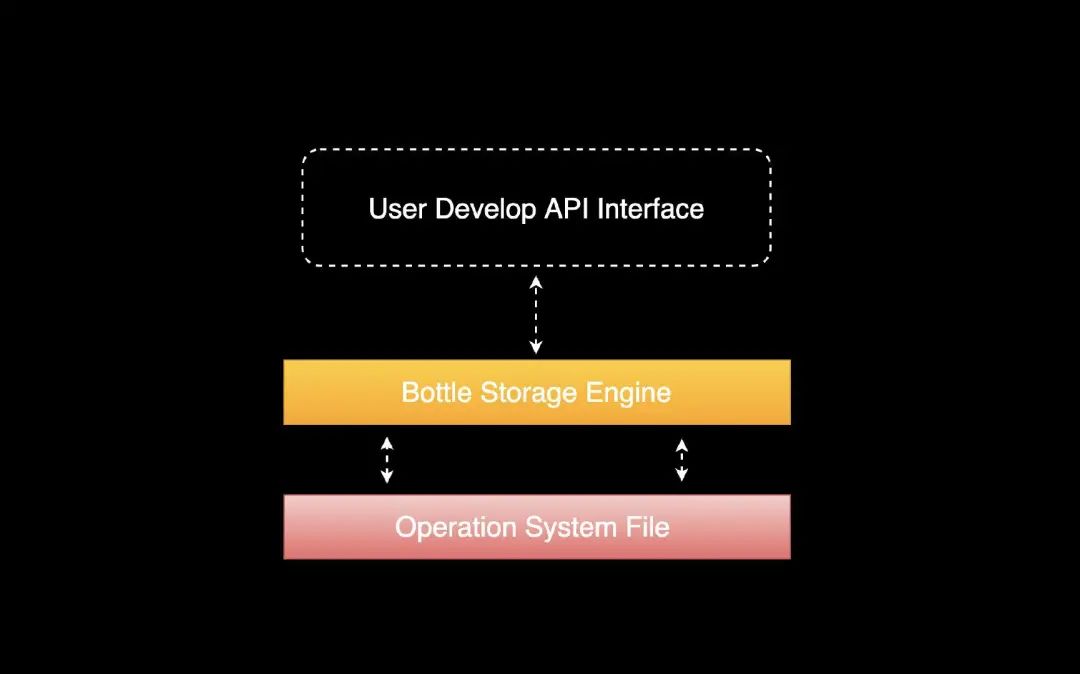
本项目功能实现完全基于 bitcask 论文所实现,另外本项目所用到一些知识和卡内基梅隆大学的CMU 15-445: Database Systems课程内容很接近,这门课由数据库领域的大牛Andy Pavlo讲授,有感兴趣的朋友可以去看看这套课,如果觉得不错你可以给我按一颗小星⭐谢谢。
安装Bottle
你只需要在你的项目中安装Bottle模块即可使用:
go get -u github.com/auula/bottle
基本API
如何操作一个Bottle实例代码:
package main
import (
"fmt"
"github.com/auula/bottle"
)
func init() {
// 通过默认配置打开一个存储实例
err := bottle.Open(bottle.DefaultOption)
// 并且处理一下可能发生的错误
if err != nil {
panic(err)
}
}
// Userinfo 测试数据结构
type Userinfo struct {
Name string
Age uint8
Skill []string
}
func main() {
// PUT Data
bottle.Put([]byte("foo"), []byte("66.6"))
// 如果转成string那么就是字符串
fmt.Println(bottle.Get([]byte("foo")).String())
// 如果不存在默认值就是0
fmt.Println(bottle.Get([]byte("foo")).Int())
// 如果不成功就是false
fmt.Println(bottle.Get([]byte("foo")).Bool())
// 如果不成功就是0.0
fmt.Println(bottle.Get([]byte("foo")).Float())
user := Userinfo{
Name: "Leon Ding",
Age: 22,
Skill: []string{"Java", "Go", "Rust"},
}
var u Userinfo
// 通过Bson保存数据对象,并且设置超时时间为5秒,TTL超时可以不设置看需求
bottle.Put([]byte("user"), bottle.Bson(&user), bottle.TTL(5))
// 通过Unwrap解析出结构体
bottle.Get([]byte("user")).Unwrap(&u)
// 打印取值
fmt.Println(u)
// 删除一个key
bottle.Remove([]byte("foo"))
// 关闭处理一下可能发生的错误
if err := bottle.Close(); err != nil {
fmt.Println(err)
}
}
加密器
数据加密器是针对数据的value记录的,也就是针对字段级别的区块加密,并非是把整个文件加密一遍,那样设计会带来性能消耗,所以采用区块数据段方式加密的方式。
下面例子是通过bottle.SetEncryptor(Encryptor,[]byte)函数去设置数据加密器并且配置16位的数据加密秘钥。
func init() {
bottle.SetEncryptor(bottle.AES(), []byte("1234567890123456"))
}
你也可以自定义去实现数据加密器的接口:
// SourceData for encryption and decryption
type SourceData struct {
Data []byte
Secret []byte
}
// Encryptor used for data encryption and decryption operation
type Encryptor interface {
Encode(sd *SourceData) error
Decode(sd *SourceData) error
}
下面代码就是内置AES加密器的实现代码,实现bottle.Encryptor接口即可,数据源为bottle.SourceData 结构体字段:
// AESEncryptor Implement the Encryptor interface
type AESEncryptor struct{}
// Encode source data encode
func (AESEncryptor) Encode(sd *SourceData) error {
sd.Data = aesEncrypt(sd.Data, sd.Secret)
return nil
}
// Decode source data decode
func (AESEncryptor) Decode(sd *SourceData) error {
sd.Data = aesDecrypt(sd.Data, sd.Secret)
return nil
}
具体的加密器实现代码可以查看encrypted.go
散列函数
如果你需要自定义实现散列函数,实现bottle.Hashed 接口即可:
type Hashed interface {
Sum64([]byte) uint64
}
然后通过内置的bottle.SetHashFunc(hash Hashed) 设置即可完成你的散列函数配置。
索引大小
索引预设置的大小很大程度上会影响你的程序存取和读取数据的速度,如果在初始化的时候能够预计出程序运行时需要的索引大小,并且在初始化的时候配置好,可以减小程序在运行过程中带来的运行数据迁移和扩容带来的性能问题。
func init() {
// 设置索引大小
bottle.SetIndexSize(1000)
}
配置信息
你也可以不使用默认配置,你可以使用内置的bottle.Option 的结构体初始化你存储引擎,配置实例如下:
func init() {
// 自定义配置信息
option := bottle.Option{
// 工作目录
Directory: "./data",
// 算法开启加密
Enable: true,
// 自定义秘钥,可以使用内置的秘钥
Secret: bottle.Secret,
// 自定义数据大小,存储单位是kb
DataFileMaxSize: 1048576,
}
// 通过自定义配置信息
bottle.Open(option)
}
当然也可以使用内置的bottle.Load(path string) 函数加载配置文件启动Bottle,配置文件格式为yaml,可配置项如下:
# Bottle config options
Enable: TRUE
Secret: "1234567890123456"
Directory: "./testdata"
DataFileMaxSize: 536870912
需要注意的是内置的加密器实现的秘钥必须是16位,如果你是自定义实现的加密器可通过bottle.SetEncryptor(Encryptor,[]byte)设置你自定义的加密器,那这个秘钥位数将不受限制。
数据目录
由于bottle设计就是基于但进程的程序,所以每个存储实例对应是一个数据目录,data为日志合并结构数据目录,index为索引数据版本。
日志合并结构数据目前版本是每次数据启动时候进行合并,默认是data数据文件夹下的所有数据文件占用总和超过1GB就会触发一次合并,合并之后没有用的数据被丢弃。
当然如果未达到脏数据合并要求,数据文件会以启动时候配置的大小进行归档,每个数据有版本号,并且被设置为只读挂载,进程工作目录结构如下:
./testdata
├── data
│ └── 1.data
└── index
├── 1646378326.index
└── 1646378328.index
2 directories, 3 files
当存储引擎开始工作的时候,这个目录下的所以文件夹和文件只能被这个进程操作,保证数据安全。
后续维护
Bottle目前不支持多数据存储分区,后续版本会引入一个Bucket概念,未来可以把指定的数据存储到指定的分区中,来降低并发的时候索引锁的颗粒度。后续将引入 零拷贝技术,当前文件操作很大程度上依赖于操作系统,当前文件必须sync才能保证数据一致性。脏数据合并可以在运行中进行合并整理,基于 信号量的方式通知垃圾回收工作线程。
其他信息
如果你发现了bug欢迎提issue或者发起pull request,我收到了消息会尽快回复你,另外欢迎各位Gopher提出自己意见,或者贡献自己的代码也是可以的,另外我们也非常欢迎大家进行存储相关技术交流,不错的话别忘去Github点一个⭐Thanks♪(・ω・)ノ。
更详细的问题可以查看:https://github.com/auula/bottle
想要了解更多与Go语言相关的内容,欢迎入群和我们进行交流~