还没期末考试,算法却说我的物理一定挂科

大数据文摘授权转载自HyperAI超神经
不得不说,算法的预测能力越来越强,小到预测夫妻是否会吵架,大到预测地震洪水等何时发生。
现在,算法甚至连你的物理课会不会挂科,都能预测出来。
这是最近西弗吉尼亚大学和加州理工大学的学者们,在 arxiv.org 上发表的一项最新研究。

他们发表了一篇有趣的论文:《Using Machine Learning to Identify the Most At-Risk Students in Physics Classes》(《使用机器学习来识别物理课上,最有挂科风险的学生》)。

论文中表示,通过机器学习算法,可以评估物理基础课中学生的毕业成绩,该预测模型将学生分类为成绩A、B、C、D、F 和 W(退选)。
注:美国大部分院校采用的评分等级与百分制分数对应规则大约为:A:90+;B:80+;C:70+;D:60+;F:不及格;W:退选课程(Withdrawal的简写)。
预测成绩:敲响警钟,你还可以抢救一下
还记得被大学物理支配的恐慌吗?
对很多理工科学生来说,大学物理的难度系数与高数相当,是最让人头秃的科目之一。
国外一项研究显示:曾主修工程和科学(统称为 STEM)但最后转专业,或者没能拿到学位的学生中,其中一小半的人就是因为物理和数学等主修课程,实在是太难。

STEM学生,尤其是基础学科的流失率逐年提高,而与此同时,社会对他们的需求却依旧很高,出现了不小的人才缺口。
因此,西弗吉尼亚大学和加州理工大学的研究人员提出,用AI算法来拯救这些学生吧。
他们认为,用机器学习算法,来识别哪些学生有挂科风险。这样教师就可以根据预测结果,有针对性地进行指导,从而提高学生的通过率,也能及时了解他们的掌握情况。
算法:参考过往表现,预测未来成绩
样本抽取
研究人员从来两所大学的抽取了三个样本,来训练预测学生表现的人工智能算法。
这些样本数据包括了:学生的ACT(美国高考)成绩、大学GPA 、物理课上收集的数据(比如课后作业成绩和考试成绩)。
其中,样本一和样本二来自于美国东部一所大学的物理科学和工程专业的学生。
样本一:包括2000年至2018年,完成大学物理1课程的所有学生,样本量为7184人。
样本二:2016年秋季至2019年春季学期的数据,样本量为1683人。样本包括了课堂表现数据,比如平均答题次数、课后作业平均成绩、学期考试分数等。
样本三:数据来自于2017年整个学年的力学入门课。样本三收集于另一所大学,该大学位于美国西部。
变量
本研究中所使用的变量,都是来自大学和班级内部。同时,也将一些人口统计信息如性别、族裔等信息纳入其中。
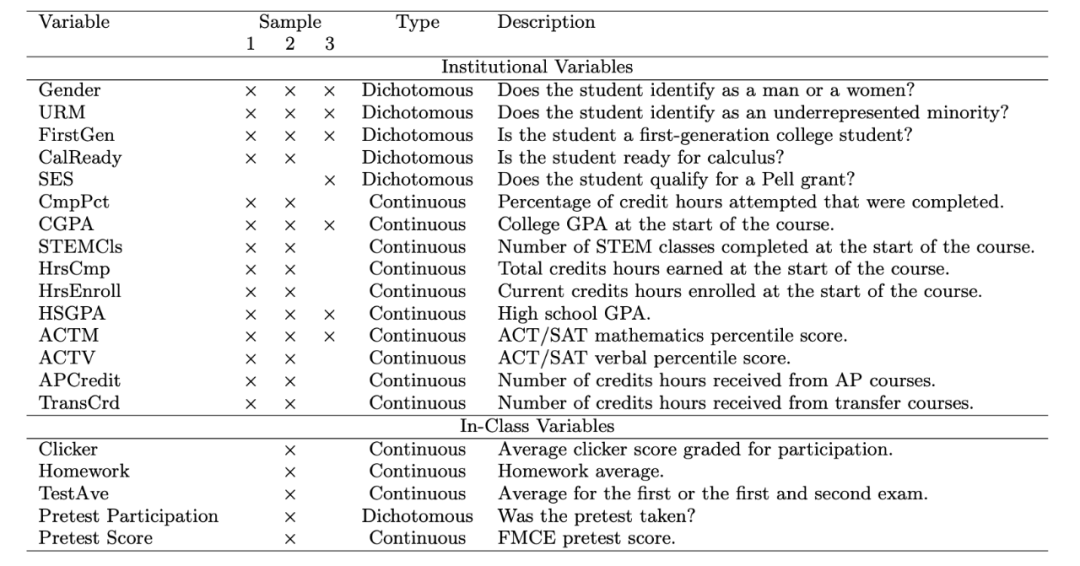
随机森林算法预测
研究中,采用随机森林机器学习算法,来预测学生的入门物理学课程最终成绩。算法最后会将学生分为获得A、B 或 C的学生(归为ABC类学生)和获得D、F或W的学生(归为DFW类潜在挂科学生)。
为了了解算法的性能,他们将数据集分为测试和训练数据集。训练数据集用于开发分类模型,以训练分类器。
测试数据集则用于表征模型性能。
分类模型预测测试数据集中每个学生的测试结果后,会将预测结果与实际结果进行比较。
结果:尴尬了,准确度57%
经过模型调整与验证,研究者得出了预测结果,但准确率实在不太乐观……
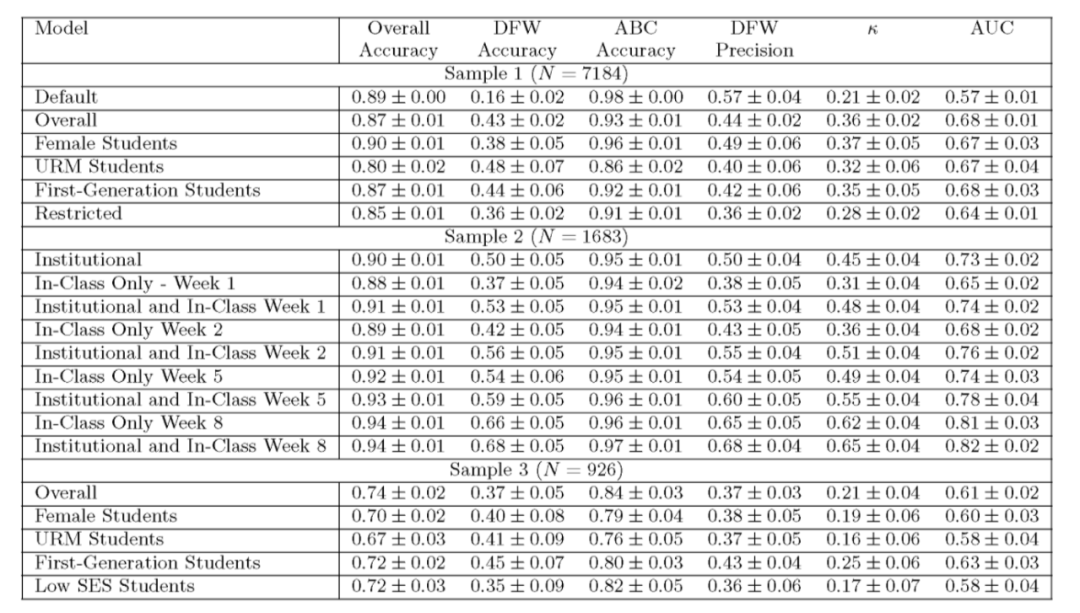
他们指出,在对整个样本预测结果中,女性和少数民族学生较多的样本,DFW准确性较低,他们指出,这需要对人口统计学进行模型调整。
在第一个样本上训练的算法,预测「DFW 类学生」的准确性仅为16%,研究人员分析,这可能是因为训练集中,成绩为DFW的学生比例很低(12%)所致。
样本一中,模型的最佳表现准确度仅仅达到57%,也就是仅比随机概率好一点点而已。
结果准确率低,模型引争议
面对这个结果,他们认为:对于教育工作者和正在努力学习的学生来说,此类机器学习分类模型,可能是一个强大的工具,可以更好指导教育干预和教育资源的分配。

但是,也有批评者认为,像这样的技术,可能会带有偏见或误导性的预测,给学生造成伤害。
一直研究表明,即使接受了大型语料库的训练,人工智能在预测复杂结果方面,仍会存在偏差问题。
此前,亚马逊的内部AI招聘工具,就因为表现出对女性的偏见,而被停用。
因此,人们也担心,这种成绩预测算法,不仅不能起到提高STEM学生保留率,反而会加剧不平等现象。
当然一切的结果都只是预测,考试嘛,三分天注定,七分靠打拼,剩下的九十分靠老师的心情。

实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn