
InsightFace: 用OneFlow轻松实现超大规模人脸识别模型

| Framework | African | Caucasian | Indian | Asian | All |
仓库地址: https://github.com/deepinsight/insightface/tree/master/recognition/oneflow_face[4]
1.大规模人脸识别背景介绍 2.OneFlow如何实现大规模人脸识别 3.MXNet的大规模人脸识别方案 4.数据并行、模型并行解决方案的通信量对比 5.Partail FC采样技术 6.OneFlow和MXNet实现的性能对比 7.总结
《OneFlow 的并行特色》[5] 《如何评价 7 月 31 日一流科技开源的深度学习框架 OneFlow?》[6] 《仅此一文让您掌握OneFlow框架的系统设计(上篇)》[7]
1.大规模人脸识别背景介绍
1.1 面临的问题
简单的网络
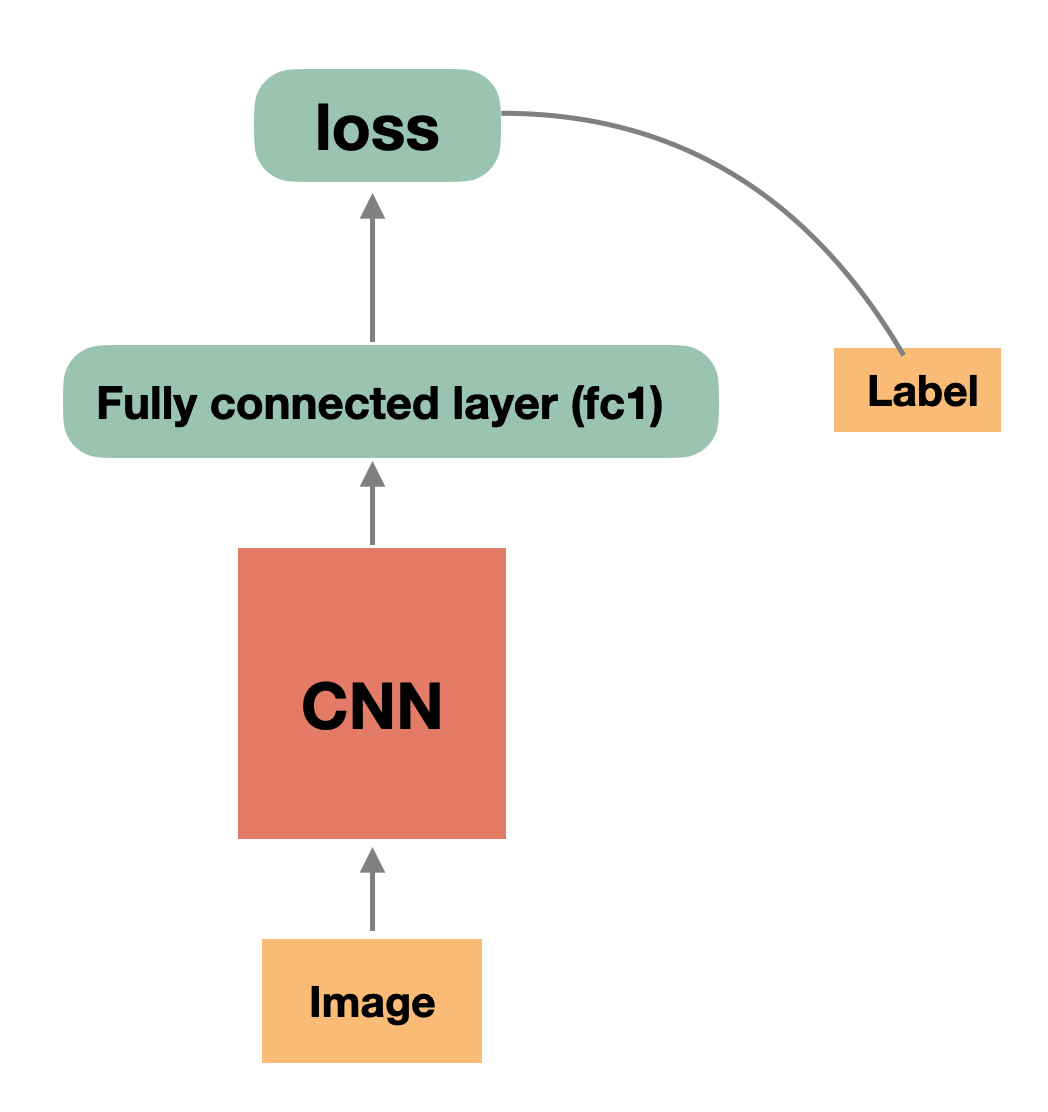
复杂的MarginLoss
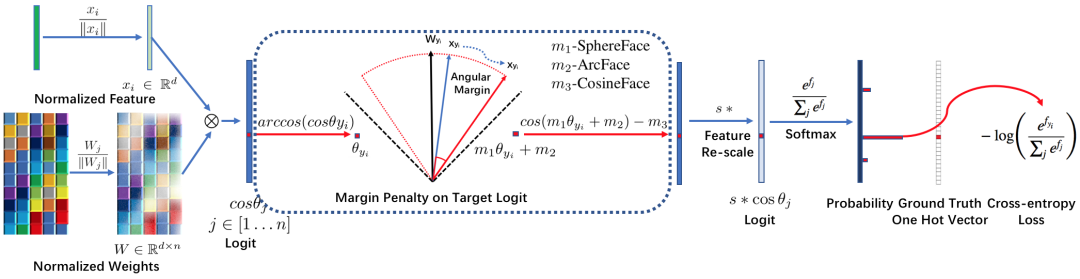
class MarginLoss(object):
""" Default is Arcface loss
"""
def __init__(self, margins=(1.0, 0.5, 0.0), loss_s=64, embedding_size=512):
"""
"""
# margins
self.loss_m1 = margins[0]
self.loss_m2 = margins[1]
self.loss_m3 = margins[2]
self.loss_s = loss_s
self.embedding_size = embedding_size
def forward(self, data, weight, mapping_label, depth):
"""
"""
with autograd.record():
norm_data = nd.L2Normalization(data)
norm_weight = nd.L2Normalization(weight)
#
fc7 = nd.dot(norm_data, norm_weight, transpose_b=True)
#
mapping_label_onehot = mx.nd.one_hot(indices=mapping_label,
depth=depth,
on_value=1.0,
off_value=0.0)
# cosface
if self.loss_m1 == 1.0 and self.loss_m2 == 0.0:
_one_hot = mapping_label_onehot * self.loss_m3
fc7 = fc7 - _one_hot
else:
fc7_onehot = fc7 * mapping_label_onehot
cos_t = fc7_onehot
t = nd.arccos(cos_t)
if self.loss_m1 != 1.0:
t = t * self.loss_m1
if self.loss_m2 != 0.0:
t = t + self.loss_m2
margin_cos = nd.cos(t)
if self.loss_m3 != 0.0:
margin_cos = margin_cos - self.loss_m3
margin_fc7 = margin_cos
margin_fc7_onehot = margin_fc7 * mapping_label_onehot
diff = margin_fc7_onehot - fc7_onehot
fc7 = fc7 + diff
fc7 = fc7 * self.loss_s
return fc7, mapping_label_onehot
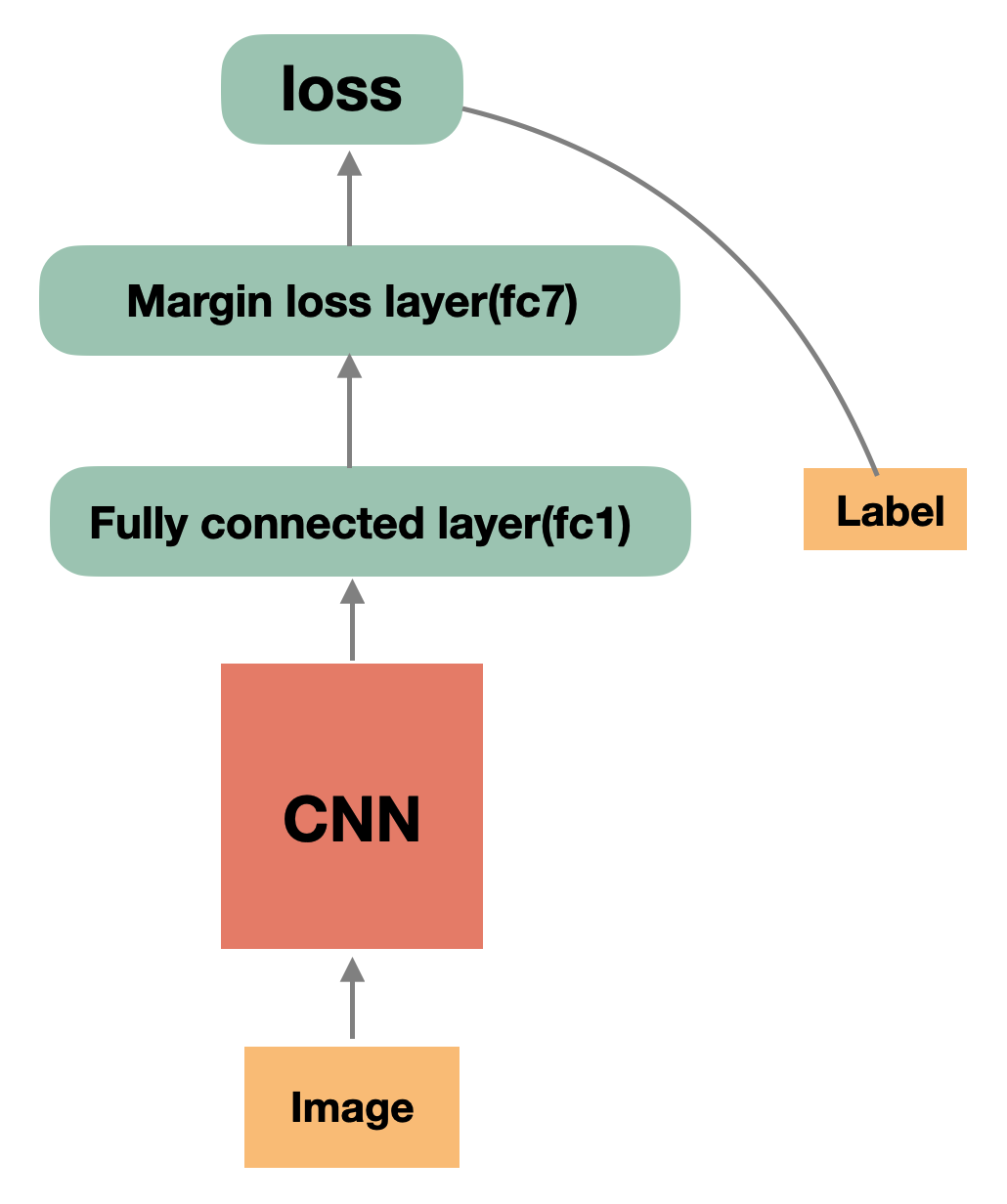
巨大的人脸ID数导致显存爆炸
1.2 解决方案
数据并行 or 模型并行
2.OneFlow 如何实现大规模人脸识别
2.1 整体结构
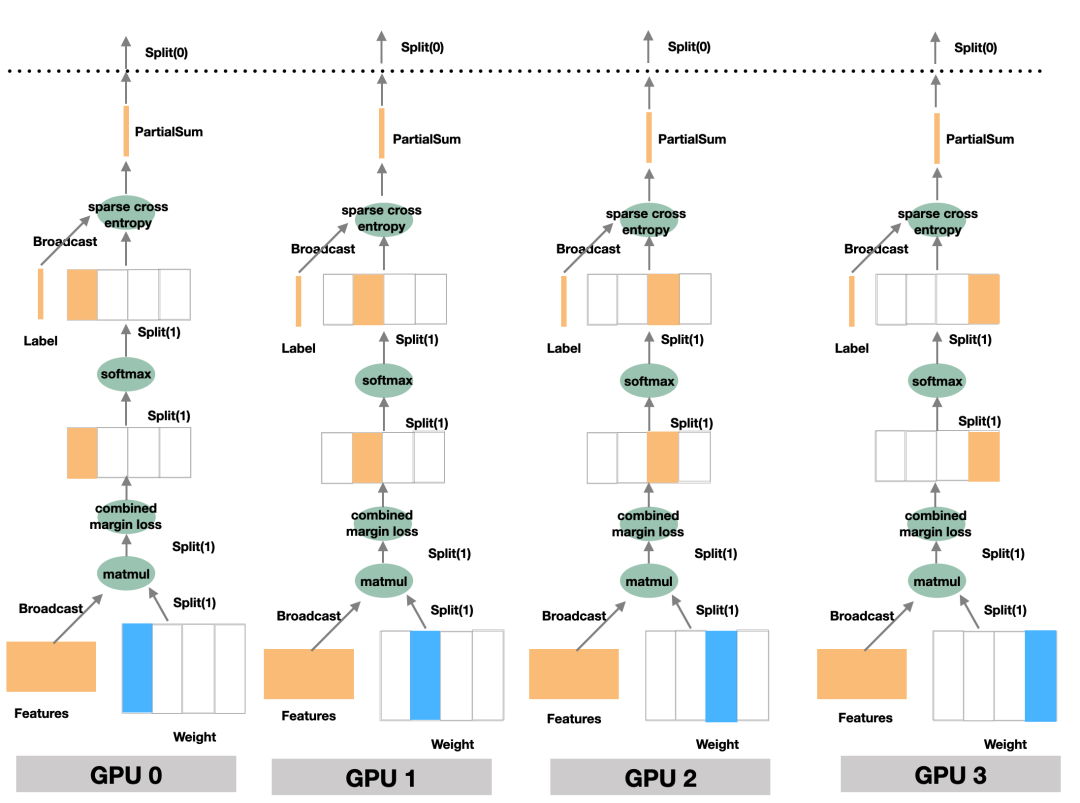
softmax 的输入进行计算,因为 softmax 的运算特性,可以使得输出的 SBP 属性依然是 Split(1)。类似的,softmax 的输出(按 Split(1) 切分)继续作为 sparse_cross_entropy 的输入进行计算,由于算子本身的特性和 OneFlow 的机制,sparse_cross_entropy 的输出的 SBP 属性依然可以保持 Split(1)。sparse_cross_entropy 处理后的输出,逻辑上获得最终的 loss 结果。此时,数据块的形状为 (batch_size, 1),已经很小,这时候再将模型并行的Split(1)模式转为按 Split(0) 切分的数据并行。softmax和sparse_cross_entropy实现细节相关的内容以及Split(1)切分是如果做到数学上的等价。2.2 Oneflow实现代码解析
elif config.loss_name == "margin_softmax":
if args.model_parallel:
print("Training is using model parallelism now.")
labels = labels.with_distribute(flow.distribute.broadcast())
fc1_distribute = flow.distribute.broadcast()
fc7_data_distribute = flow.distribute.split(1)
fc7_model_distribute = flow.distribute.split(0)
else:
fc1_distribute = flow.distribute.split(0)
fc7_data_distribute = flow.distribute.split(0)
fc7_model_distribute = flow.distribute.broadcast()
fc7_weight = flow.get_variable(
name="fc7-weight",
shape=(config.num_classes, embedding.shape[1]),
dtype=embedding.dtype,
initializer=_get_initializer(),
regularizer=None,
trainable=trainable,
model_name="weight",
distribute=fc7_model_distribute,
)
if args.partial_fc and args.model_parallel:
print(
"Training is using model parallelism and optimized by partial_fc now."
)
(
mapped_label,
sampled_label,
sampled_weight,
) = flow.distributed_partial_fc_sample(
weight=fc7_weight, label=labels, num_sample=args.total_num_sample,
)
labels = mapped_label
fc7_weight = sampled_weight
fc7_weight = flow.math.l2_normalize(
input=fc7_weight, axis=1, epsilon=1e-10)
fc1 = flow.math.l2_normalize(
input=embedding, axis=1, epsilon=1e-10)
fc7 = flow.matmul(
a=fc1.with_distribute(fc1_distribute), b=fc7_weight, transpose_b=True
)
fc7 = fc7.with_distribute(fc7_data_distribute)
fc7 = (
flow.combined_margin_loss(
fc7, labels, m1=config.loss_m1, m2=config.loss_m2, m3=config.loss_m3
)
* config.loss_s
)
fc7 = fc7.with_distribute(fc7_data_distribute)
else:
raise NotImplementedError
loss = flow.nn.sparse_softmax_cross_entropy_with_logits(
labels, fc7, name="softmax_loss"
)
lr_scheduler = flow.optimizer.PiecewiseScalingScheduler(
base_lr=args.lr,
boundaries=args.lr_steps,
scale=args.scales,
warmup=None
)
flow.optimizer.SGDW(lr_scheduler,
momentum=args.momentum if args.momentum > 0 else None,
weight_decay=args.weight_decay
).minimize(loss)
return loss
fc1_distribute = flow.distribute.broadcast() # 表示SBP为B,广播,用于全量数据的同步
fc7_model_distribute = flow.distribute.split(0) # 表示SBP为S0,表示模型并行且按第0维切割
# (FC层为dense层,在框架实现上会对dense层模型做转置,model_distribute设Split(0)代表模型在第1维分割,SBP属性相当于Split(1)
fc7_data_distribute = flow.distribute.split(1) # 表示SBP为S1,表示数据并行且按第1维切割(和模型并行保持一致)
1.首先,通过flow.matmul()进行矩阵乘法(fc1层->fc7层的前向传播),并设置其结果的SBP属性为fc7_data_distribute。 2.然后,通过flow.combined_margin_loss()完成fc7层的前向传播,由于其SBP属性并没有改变,故继续设置其SBP属性为fc7_data_distribute。 3.最后,直接调用flow.nn.sparse_softmax_cross_entropy_with_logits()即可完成求softmax交叉墒损失,至此完成了整个过程前向+loss计算,之后的反向过程、梯度更新、学习率更新等将由后面的flow.optimizer自动完成。
2.3 模型并行的技术细节
matmul 运算,其原理示意可参考 Consistent 与 Mirrored[13] 一文中的相关部分,之后对matmul的结果进行 softmax+求交叉熵损失函数,即调用flow.nn.sparse_softmax_cross_entropy_with_logits()完成整个计算过程。问题产生的原因
matmul 运算,然后直接在各卡本地计算 softmax,最终通过 sparse cross entropy 算子计算得到 SBP 属性为 Split(1) 的 loss,最终将 loss 的 SBP 属性转为 Split(0), 即转为和普通数据并行方案等价的loss。因此,看起来和普通的softmax方案会存在差异,那么这就带来了这两种方案下的softmax计算在数学上是否等价的问题!flow.nn.parse_softmax_cross_entropy_with_logits 算子,是如何在模型并行的情况下做到数学上softmax计算等价的。模型并行下的softmax
公式中涉及到的求 max 和求 sum 的运算均需要全局的信息 但是每个 GPU 设备上只有部分的模型
flow.nn.parse_softmax_cross_entropy_with_logits 的内部实现原理和细节,可以看到它利用 OneFlow 框架 SBP 机制,是如何巧妙地解决以上问题。sparse_softmax_cross_entropy_with_logits 的实现细节
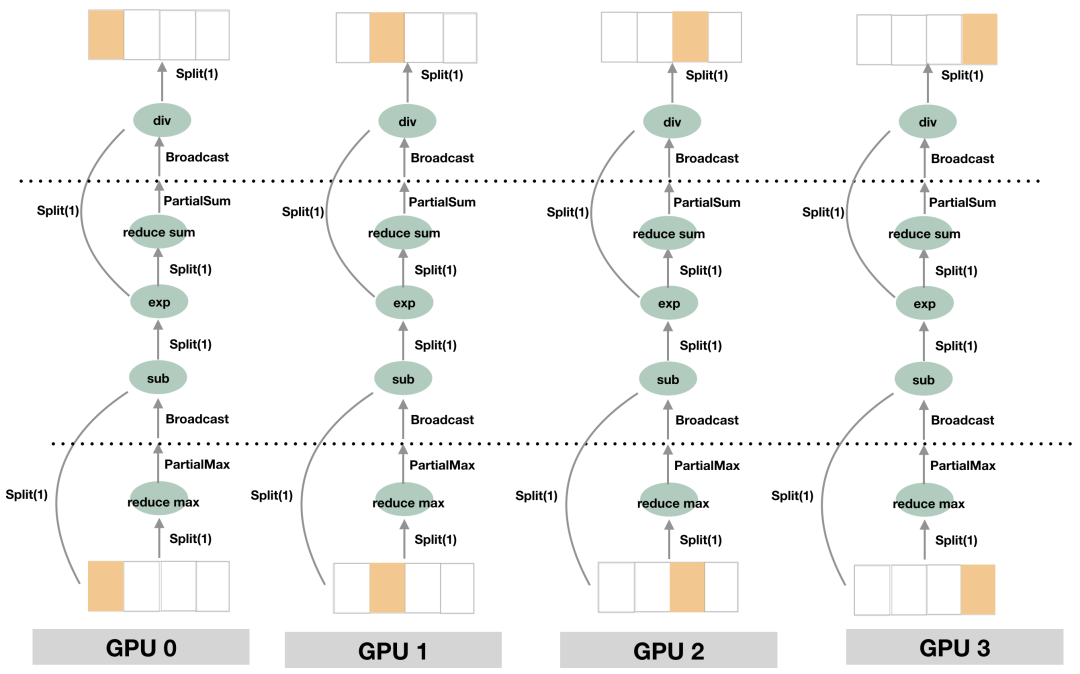
[5, 4, 2] [5]
[4, 3, 3] -reduce max-> [4]
[1, 9, 8] [9]
前一层 softmax 的输出,SBP 属性为 Split(1) labels,SBP 属性为 Broadcast
OneFlow 中的代码实现
labels = flow.parallel_cast(labels, distribute = flow.distribute.broadcast())
embedding = flow.parallel_cast(embedding, distribute = flow.distribute.broadcast())
fc7 = flow.layers.dense(
inputs=embedding,
units=args.class_num,
model_distribute=flow.distribute.split(0),
) #dense中模型会做转置,model_distribute设Split(0)代表模型在第1维分割,SBP属性为Split(1)
loss = flow.nn.sparse_softmax_cross_entropy_with_logits(
labels, fc7.with_distribute(flow.distribute.split(1)), name="softmax_loss"
)
flow.parallel_cast 方法将 labels 和 embedding 的 SBP 属性设置为 Broadcast。然后,在flow.layers.dense内通过设置其 model_distribute 参数为 flow.distribute.split(0) 将模型的 SBP 属性设置为 Split(1),从而创建了模型并行方式的全连接层。flow.nn.sparse_softmax_cross_entropy_with_logits 获取 loss。上文讨论原理中所涉及的 SBP 类型推导、SBP 属性转换等工作,都由 OneFlow 框架自行完成。3.MXNet的大规模人脸识别方案
数据+模型的混合并行下网络、梯度、数据的处理; 混合并行模式下常规的算子如gloss.SoftmaxCrossEntropyLoss 无法正常工作的问题。
3.1 MXNet实现代码解析
train_module.fit(train_data_iter,
optimizer_params=backbone_kwargs,
initializer=mx.init.Normal(0.1),
batch_end_callback=call_back_fn)
通过 forward_backward()[16]来进行前向、反向的过程,并计算出待更新的梯度; 通过 update()[17] 调用 optimizer 完成对模型、学习率等参数的更新。
def forward_backward(self, data_batch):
"""A convenient function that calls both ``forward`` and ``backward``.
"""
total_feature, total_label = self.forward(data_batch, is_train=True)
self.backward_all(total_feature, total_label)
前向
def forward(self, data_batch, is_train=None):
self.backbone_module.forward(data_batch, is_train=is_train)
if is_train:
self.num_update += 1
fc1 = self.backbone_module.get_outputs()[0]
label = data_batch.label[0]
total_features = self.allgather(tensor=fc1,
name='total_feature',
shape=(self.batch_size * self.size,
self.embedding_size),
dtype='float32',
context=self.gpu)
total_labels = self.allgather(tensor=label,
name='total_label',
shape=(self.batch_size *
self.size, ),
dtype='int32',
context=self.cpu)
return total_features, total_labels
else:
return None
反向
2.普通CNN网络的反向
下面,我们看一下backward_all()方法:
def backward_all(
self,
total_feature,
total_label,
):
# get memory bank learning rate
self.memory_lr = self.memory_optimizer.lr_scheduler(self.num_update)
self.grad_cache = self.get_ndarray(self.gpu, 'grad_cache',
total_feature.shape)
self.loss_cache = self.get_ndarray(self.gpu, 'loss_cache', [1])
self.grad_cache[:] = 0
self.loss_cache[:] = 0
if not bool(config.sample_ratio - 1):
grad, loss = self.backward(total_feature, total_label)
else:
grad, loss = self.backward_sample(total_feature, total_label)
self.loss_cache[0] = loss
total_feature_grad = grad
total_feature_grad = hvd.allreduce(total_feature_grad, average=False)
fc1_grad = total_feature_grad[self.batch_size *
self.rank:self.batch_size * self.rank +
self.batch_size]
self.backbone_module.backward(out_grads=[fc1_grad / self.size])
第1部分,对Marginloss层的处理集中放在了backward()和backward_sample()部分,二者区别在于backward()对应的是sample_ratio=1.0时的反向(不使用Partial fc进行采样);backward_sample()对应使用Partial fc进行采样时的反向过程。 第2部分,实现CNN网络的反向,即:self.backbone_module.backward
Marginloss
def backward(self, total_feature, label):
memory_bank = self.memory_bank
assert memory_bank.num_local == memory_bank.num_sample, "pass"
_data = self.get_ndarray2(self.gpu, "data_%d" % self.rank,
total_feature)
# Attach grad
_data.attach_grad()
memory_bank.weight.attach_grad()
# Convert label
_label = self.get_ndarray2(self.gpu, 'label_%d' % self.rank, label)
_label = _label - int(self.rank * memory_bank.num_local)
_fc7, _one_hot = self.fc7_model.forward(_data,
memory_bank.weight,
mapping_label=_label,
depth=memory_bank.num_local)
# Sync max
max_fc7 = nd.max(_fc7, axis=1, keepdims=True)
max_fc7 = nd.reshape(max_fc7, -1)
total_max_fc7 = self.get_ndarray(context=self.gpu,
name='total_max_fc7',
shape=(max_fc7.shape[0], self.size),
dtype='float32')
total_max_fc7[:] = 0
total_max_fc7[:, self.rank] = max_fc7
hvd.allreduce_(total_max_fc7, average=False)
global_max_fc7 = self.get_ndarray(context=self.gpu,
name='global_max_fc7',
shape=(max_fc7.shape[0], 1),
dtype='float32')
nd.max(total_max_fc7, axis=1, keepdims=True, out=global_max_fc7)
# Calculate exp(logits)
_fc7_grad = nd.broadcast_sub(_fc7, global_max_fc7)
_fc7_grad = nd.exp(_fc7_grad)
# Calculate sum
sum_fc7 = nd.sum(_fc7_grad, axis=1, keepdims=True)
global_sum_fc7 = hvd.allreduce(sum_fc7, average=False)
# Calculate prob
_fc7_grad = nd.broadcast_div(_fc7_grad, global_sum_fc7)
# Calculate loss
tmp = _fc7_grad * _one_hot
tmp = nd.sum(tmp, axis=1, keepdims=True)
tmp = self.get_ndarray2(self.gpu, 'ctx_loss', tmp)
tmp = hvd.allreduce(tmp, average=False)
global_loss = -nd.mean(nd.log(tmp + 1e-30))
# Calculate fc7 grad
_fc7_grad = _fc7_grad - _one_hot
# Backward
_fc7.backward(out_grad=_fc7_grad)
# Update center
_weight_grad = memory_bank.weight.grad
self.memory_optimizer.update(weight=memory_bank.weight,
grad=_weight_grad,
state=memory_bank.weight_mom,
learning_rate=self.memory_lr)
return _data.grad, global_loss
_fc7, _one_hot = self.fc7_model.forward(_data,
memory_bank.weight,
mapping_label=_label,
depth=memory_bank.num_local)
4.数据并行、模型并行解决方案的通信量对比
4.1 数据并行通信量
2 * emb_size * 10000000 * (P - 1)4.2 混合并行通信量
1.CNN 网络得到的人脸特征由 Split(0)->Broadcast 的传输,数据块大小为 (batch_size, emb_size) 2.label 由 Split(0)->Broadcast 的传输,数据块大小为 (batch_size, 1) 3.Softmax 计算过程中,每卡 Split(1) 切分数据的 max 值由 Partial max->Broadcast 的传输,数据块大小为(batch_size, 1);每卡 Split(1) 切分数据的 sum 值由 Partial sum->Broadcast 的传输,数据块大小为(batch_size, 1) 4.最终算出 loss 后的通信,数据块大小为 (batch_size, 1)
(batch_size * emb_size + 6 * batch_size) * (P - 1)4.3 对比总结
batch_size大小及显卡数P一定、且人脸类别 ID 数巨大时(譬如1000万),纯数据并行和基于本方案的混合并行,二者通信量存在数量级的差异:2 * emb_size * 10000000 * (P - 1)VSbatch_size * (emb_size + 6) * (P - 1)5.Partial FC采样技术
fc7 = flow.matmul(
a=fc1.with_distribute(fc1_distribute), b=fc7_weight, transpose_b=True
)
(batch_size_per_device * P, num_classes/P)
当num_classes逐渐增加时,需要增加设备数量P以支持训练,但同时logits矩阵的第一维也会逐渐增加导致更高的显存占用,从而实际支持的最大人脸ID类别数也有上限,即不能通过无限拓展设备数P来支持更大规模的ID类别数。为了解决此问题,格灵深瞳在论文《Partial FC: Training 10 Million Identities on a Single Machine》[20]提出了Partial FC的采样技术,简单来说,Partial fc即对权重和logits矩阵的一种采样,通过设置相应的采样率(sample ratial)来达到节省内存,能支持更大类别数的效果。
根据论文中的描述,softmax函数中的负类在人脸表征学习中的重要性并没有那么高,即无需用每个输出特征和完整的模型权重矩阵相乘(全采样),可以通过sample ratial设置采样率,譬如sample ratial=0.1则表示只采样10%的权重矩阵,而经过采样后不损失精度,通过此方式可以轻松支持更大类别数。insightface相关的代码在官方仓库:insightface/partial_fc[21]。
flow.distributed_partial_fc_sample算子即可对权重矩阵、标签label进行采样。使用Partial FC采样的主要代码如下:(mapped_label, sampled_label, sampled_weight) = flow.distributed_partial_fc_sample(
weight=fc7_weight, label=labels, num_sample= num_sample)
6.OneFlow和MXNet实现的性能对比
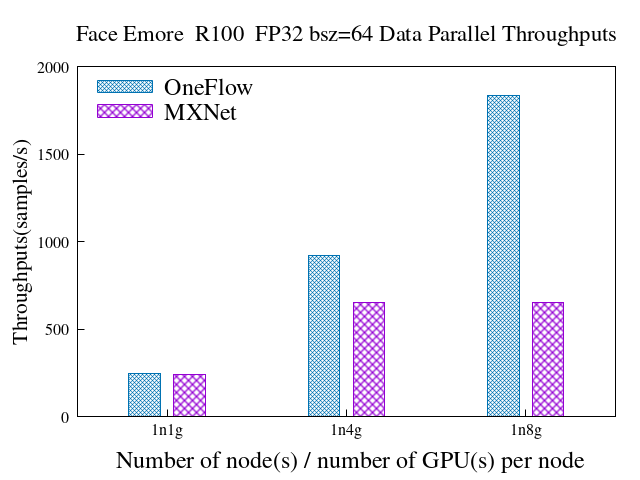
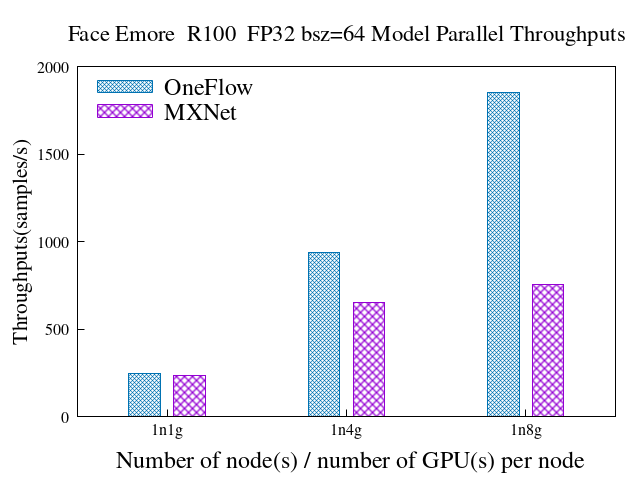
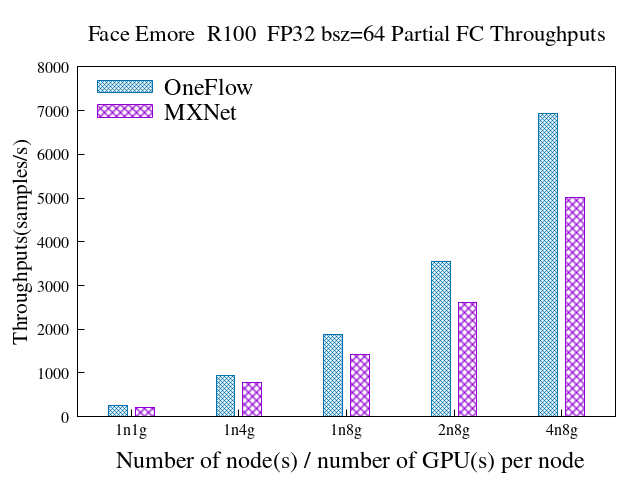
数据并行时,1836.8 vs 650.8(samples/s),速度是MXNet的2.82倍 模型并行时,1854.15 vs 756.96(samples/s),速度是MXNet的2.45倍 混合并行+Partial fc时(4机32GPU),6931.6 vs 5008.7(samples/s),速度是MXNet的1.38倍,且加速比28.1 vs 22.8
模型并行时,115 vs 96,较MXNet提升20% 混合并行+Partial fc时,115 vs 96,较基于MXNet实现的Partial fc提升20%
混合并行+Partial fc时,单机支持的最大人脸ID数(num classes):1350万 vs 1200万,较基于MXNet的Partial fc提升12.5%
6.1 数据并行
dataset: emore backbone:resnet100
| OneFlow | MXNet | ||||
6.2 模型并行
dataset: emore backbone:resnet100
| OneFlow | MXNet | ||||
6.3 混合并行 + Partial FC(sample ratio = 0.1)
emore数据集
dataset: emore backbone:resnet100
| OneFlow | MXNet | ||||
glint360k数据集
dataset: glint360k backbone:resnet100
| OneFlow | MXNet | ||||
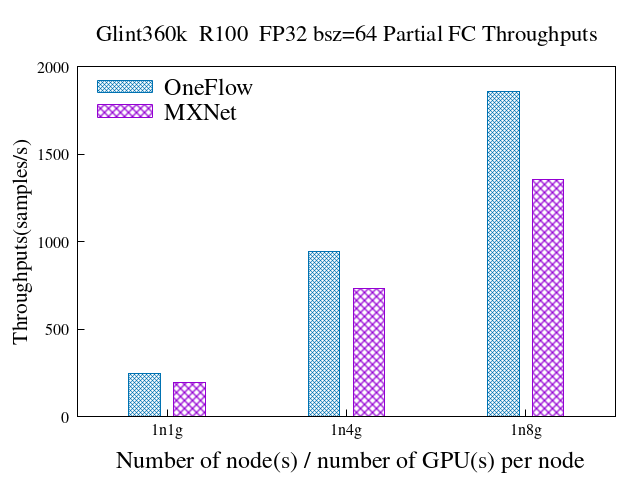
6.4 Max batch size per device
| OneFlow | MXNet | |
6.5 Max num classes
| mode | node_num | gpu_num_per_node | max num classes(OneFlow) | max num classes(MXNet) |
所有数据、测试报告及代码见DLPerf仓库:https://github.com/Oneflow-Inc/DLPerf#insightface[22]
7.总结
扩展性强、可以轻松支持千万、最大支持亿级别的类别 ID 数的人脸识别模型。
不增加额外通信,在 FC 层甚至大大降低了通信量,训练速度更快,更近线性加速比。
速度和灵活性上的优势得益于SBP的抽象以及以分布式易用性为出发点的系统设计,OneFlow实现数据并行/模型并行方案只需要很少量的代码,无需对dataset、optimizer、model等做额外包装、无需使用horovod等第三方工具,对算法开发工程师来说更为友好。
OneFlow复现、调试Insightface的过程中,需要特别感谢Insightface项目的发起人过佳以及Partial fc的作者格灵深瞳的安翔。首先感谢两位提供了如此高效的大规模人脸识别方案,其次,在OneFlow方案实现过程中,他们给出了耐心细致的指导,在数据集、测试方面也给予了大力支持,衷心感谢!
InsightFace : https://github.com/deepinsight/insightface
[2]insightface的官方仓库: https://github.com/deepinsight/insightface/tree/master/recognition/oneflow_face
[3]预训练模型: https://github.com/Oneflow-Inc/oneflow_face#Pretrained-model
[4]https://github.com/deepinsight/insightface/tree/master/recognition/oneflow_face: https://github.com/deepinsight/insightface/tree/master/recognition/oneflow_face
[5]《OneFlow 的并行特色》: https://docs.oneflow.org/extended_topics/model_mixed_parallel.html
[6]《如何评价 7 月 31 日一流科技开源的深度学习框架 OneFlow?》: https://www.zhihu.com/question/409036335/answer/1373468192
[7]《仅此一文让您掌握OneFlow框架的系统设计(上篇)》: https://zhuanlan.zhihu.com/p/337851255
[8]《ArcFace: Additive Angular Margin Loss for Deep Face Recognition》: https://arxiv.org/pdf/1801.07698.pdf
[9]MarginLoss: https://github.com/deepinsight/insightface/blob/79aacd2bb3323fa50a125b828bb1656166604487/recognition/partial_fc/mxnet/memory_softmax.py
[10]flow.combined_margin_loss: https://github.com/Oneflow-Inc/oneflow_face/blob/master/insightface_train.py#L358
[11]insightface官方的partail_fc: https://github.com/Oneflow-Inc/DLPerf/tree/master/MxNet/InsightFace/PartailFC
[12]oneflow_face: https://github.com/deepinsight/insightface/tree/master/recognition/oneflow_face
[13]Consistent 与 Mirrored: https://docs.oneflow.org/extended_topics/consistent_mirrored.html#_3
[14]train_module.fit(): https://github.com/deepinsight/insightface/blob/863a7ea9ea0c0355d63c17e3c24e1373ed6bec55/recognition/partial_fc/mxnet/train_memory.py#L158
[15]SampleDistributeModule: https://github.com/deepinsight/insightface/blob/863a7ea9ea0c0355d63c17e3c24e1373ed6bec55/recognition/partial_fc/mxnet/memory_module.py#L14
[16]forward_backward(): https://github.com/deepinsight/insightface/blob/863a7ea9ea0c0355d63c17e3c24e1373ed6bec55/recognition/partial_fc/mxnet/memory_module.py#L118
[17]update(): https://github.com/deepinsight/insightface/blob/863a7ea9ea0c0355d63c17e3c24e1373ed6bec55/recognition/partial_fc/mxnet/memory_module.py#L119
[18]forward_backward(): https://github.com/deepinsight/insightface/blob/863a7ea9ea0c0355d63c17e3c24e1373ed6bec55/recognition/partial_fc/mxnet/memory_module.py#L118
[19]MarginLoss: https://github.com/deepinsight/insightface/blob/863a7ea9ea0c0355d63c17e3c24e1373ed6bec55/recognition/partial_fc/mxnet/memory_softmax.py#L6
[20]《Partial FC: Training 10 Million Identities on a Single Machine》: https://arxiv.org/abs/2010.05222
[21]官方仓库:insightface/partial_fc: https://github.com/deepinsight/insightface/tree/master/recognition/partial_fc
[22]https://github.com/Oneflow-Inc/DLPerf#insightface: https://github.com/Oneflow-Inc/DLPerf#insightface