
学不会去当产品吧?Flink实战任务调优
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多惊喜




背景
一些简单的原则
在Flink的后台任务管理中,我们可以看到Flink的哪个算子和task出现了反压。最主要的手段是资源调优和算子调优。资源调优即是对作业中的Operator的并发数(parallelism)、CPU(core)、堆内存(heap_memory)等参数进行调优。作业参数调优包括:并行度的设置,State的设置,checkpoint的设置。
轮着来,学不会转产品吧
先看指标,定位问题
再看资源,是否足够
Operator的并发数(parallelism)不合理
CPU(core)不合理
堆内存(heap_memory)等参数设置不合理
并行度的设置不合理
State的设置不合理
checkpoint的设置不合理
并行度(parallelism):保证足够的并行度,并行度也不是越大越好,太多会加重数据在多个solt/task manager之间数据传输压力,包括序列化和反序列化带来的压力。
CPU:CPU资源是task manager上的solt共享的,注意监控CPU的使用。
内存:内存是分solt隔离使用的,注意存储大state的时候,内存要足够。
网络:大数据处理,flink节点之间数据传输会很多,服务器网卡尽量使用万兆网卡。
三看吞吐,是否反压
四看JVM,是否OOM?
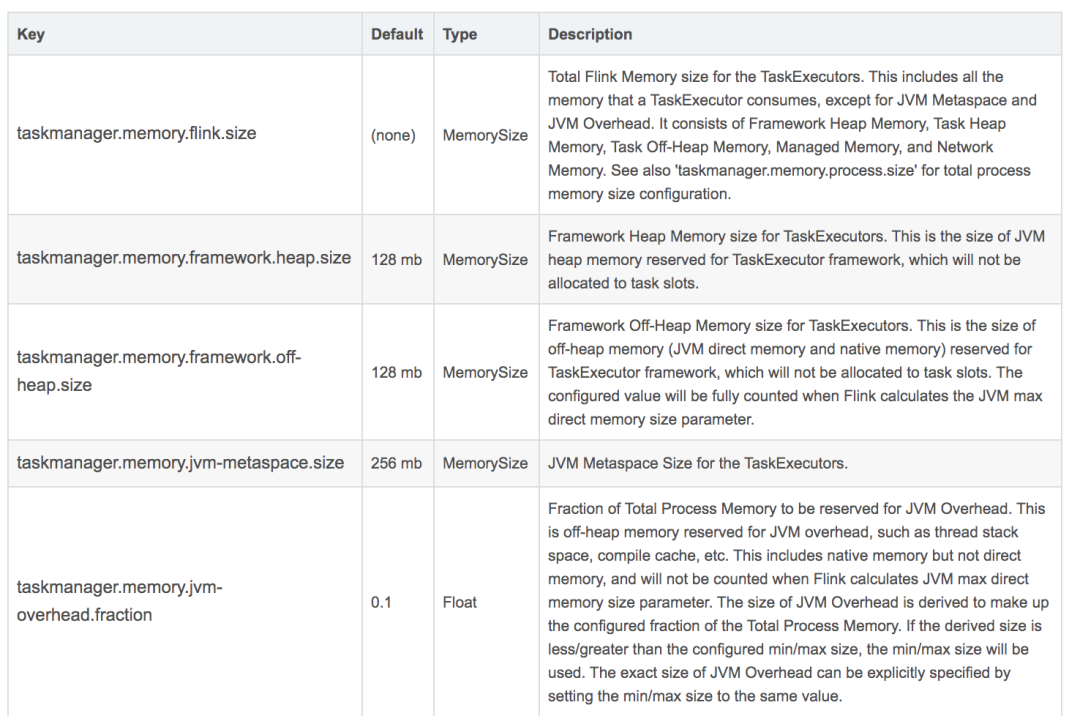
taskmanager.memory.process.size: 512m
taskmanager.memory.framework.heap.size: 64m
taskmanager.memory.framework.off-heap.size: 64m
taskmanager.memory.jvm-metaspace.size: 64m
taskmanager.memory.jvm-overhead.fraction: 0.2
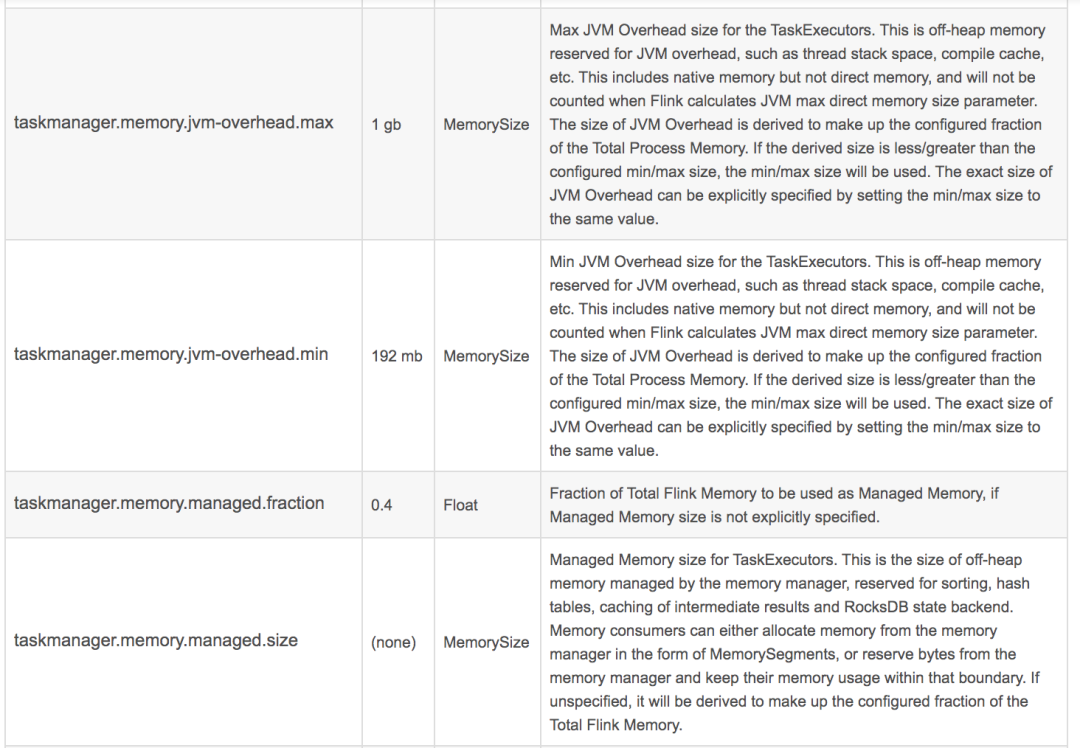
taskmanager.memory.jvm-overhead.min: 16m
taskmanager.memory.jvm-overhead.max: 64m
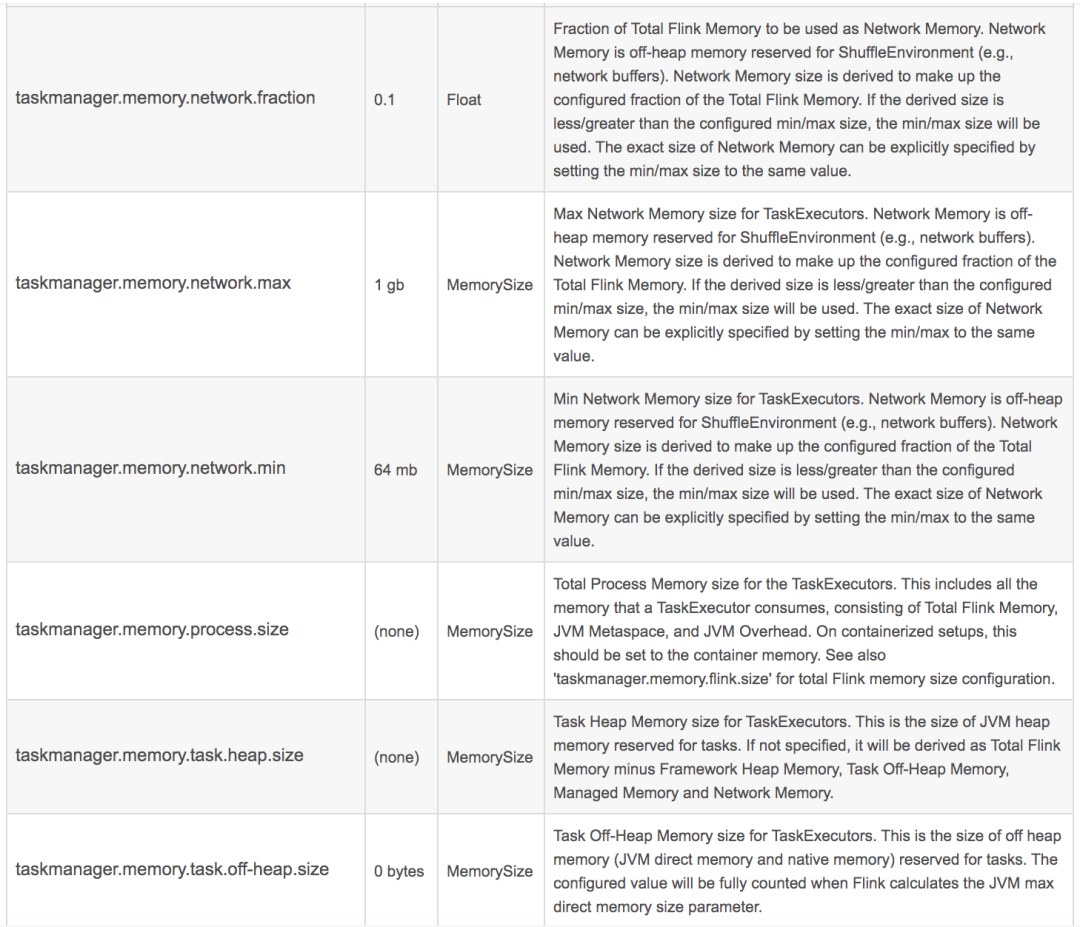
taskmanager.memory.network.fraction: 0.1
taskmanager.memory.network.min: 1mb
taskmanager.memory.network.max: 256mb
堆设置
-Xms :初始堆大小
-Xmx :最大堆大小
-XX:NewSize=n :设置年轻代大小
-XX:NewRatio=n: 设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
-XX:SurvivorRatio=n :年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
-XX:MaxPermSize=n :设置持久代大小
收集器设置
-XX:+UseSerialGC :设置串行收集器
-XX:+UseParallelGC :设置并行收集器
-XX:+UseParalledlOldGC :设置并行年老代收集器
-XX:+UseConcMarkSweepGC :设置并发收集器
垃圾回收统计信息
-XX:+PrintHeapAtGC GC的heap详情
-XX:+PrintGCDetails GC详情
-XX:+PrintGCTimeStamps 打印GC时间信息
-XX:+PrintTenuringDistribution 打印年龄信息等
-XX:+HandlePromotionFailure 老年代分配担保(true or false)
并行收集器设置
-XX:ParallelGCThreads=n :设置并行收集器收集时使用的CPU数。并行收集线程数。
-XX:MaxGCPauseMillis=n :设置并行收集最大暂停时间
-XX:GCTimeRatio=n :设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
并发收集器设置
-XX:+CMSIncrementalMode :设置为增量模式。适用于单CPU情况。
-XX:ParallelGCThreads=n :设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数
总结

Flink面试通关手册
Flink流量控制与反压机制完全总结
Flink源码阅读之Checkpoint


版权声明:
责编 | 大数据真好玩
插画 | 大数据真好玩
微信公众号 | 大数据真好玩
文章不错?点个【在看】吧! 👇
评论