借助TensorFlow.js,手把手教你把会动的蒙娜丽莎带回家!

大数据文摘出品
来源:tensorflowblog
编译:Fisher、coolboy
据说,当你在卢浮宫博物馆踱步游览的时候,你会感到油画中的蒙娜丽莎视线随你而动。这就是《蒙娜丽莎》这幅画的神奇之处。出于好玩,TensorFlow软件工程师Emily Xie最近开发了一个互动数字肖像,只需要浏览器和摄像头,你就能把会动的蒙娜丽莎带回家了!
这个项目的核心利用了TensorFlow.js,深度学习,还有一些图像处理技术。大体想法如下:首先,要生成一系列蒙娜丽莎的头像,这些头像注视的方向由左到右。有了这个头像集,我们就可以在其中连续选取图像,从而根据观看者的位置产生一幅实时画面。
在这个帖子里,作者详细介绍了项目设计和实现的细节。
用深度学习让蒙娜丽莎动起来
图片动画化技术可以让一张静态图片参考一个“驱动视频”的运动模式而活动起来。使用基于深度学习的方法,作者得以生成一段非常逼真的动画——“蒙娜丽莎的注视”。
具体来说,Emily使用了Aliaksandr Siarohin等人在2019年发布的First Order Motion Model(FOMM)这一模型。总的来说,这个方法由两个模块组成,分别负责运动抽取和图像生成。运动抽取模块会检测“驱动视频”中的关键点和局部仿射变换。这些值在相邻帧间的差将输入神经网络以预测一个稠密运动场(dense motion field)以及一个闭合遮罩(mask),该遮罩指定了需要修饰或者需要做上下文推断的图像区域。负责图像生成的神经网络会继而检测人脸特征点,并根据运动抽取模块的结果对源图像进行变形和着色,最后输出处理后的图像。
Emily选择FOMM是因为它特别易用。作为对比,图片动画化领域的先验模型都是“依赖于对象”的,要求获取所要动画化的对象的详尽数据。相反,FOMM不依赖先验知识。更重要的是,FOMM的作者们发布了一个开源的人脸动画化方案——自带预训练权重,拿来就能用。这使得把FOMM模型应用在蒙娜丽莎上变得相当简单:只要把代码仓库克隆到Colab notebook上,再拿自己做模特生成一小段眼部来回移动的“驱动视频”提供给模型,同时提供一张蒙娜丽莎的头部截图就可以了。模型生成的视频效果很好,Emily从中选取了33帧用于构成最终的动画。

FOMM生成的视频和图像动画预测示例

图像拼接
尽管可以针对自己的项目重新训练模型,Emily还是决定就用Siarohin等作者给出的神经网络权重。这样可以节省时间,也节省计算资源。不过,这意味着输出的图像分辨率低于期望,而且只包含人物的头部区域。Emily想要的最终视觉效果是蒙娜丽莎的整体,包括头部、躯干和背景。因此,他打算把得到的头部图像简单地叠放在完整的肖像画上。
这又带来了一系列挑战。如果你仔细看上面的例图,你会注意到头部区域的分辨率比较低,而且有一些变形,看起来像是浮在背景图之上。换句话说,这打补丁的痕迹也太明显了!为了解决这个问题,作者用Python做了一些处理来把头部区域和背景“拼接”起来。

首先,他调整了头部图像的分辨率,通过像素的模糊化,让分辨率增加到跟背景图一致。然后,通过头部图像和背景图像的像素加权平均来做一张新图,思路也很简单,头部图像的像素权重在它的中点位置取得最大,远离中点逐渐变小。
权重分布由一个二维的S形函数决定,表达式为:
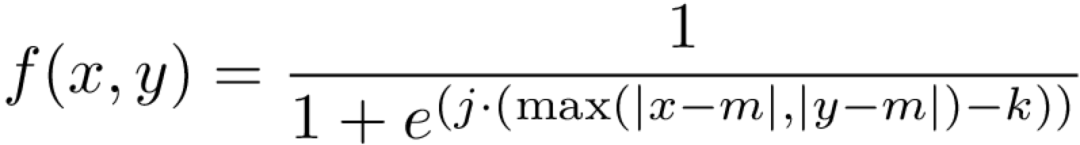
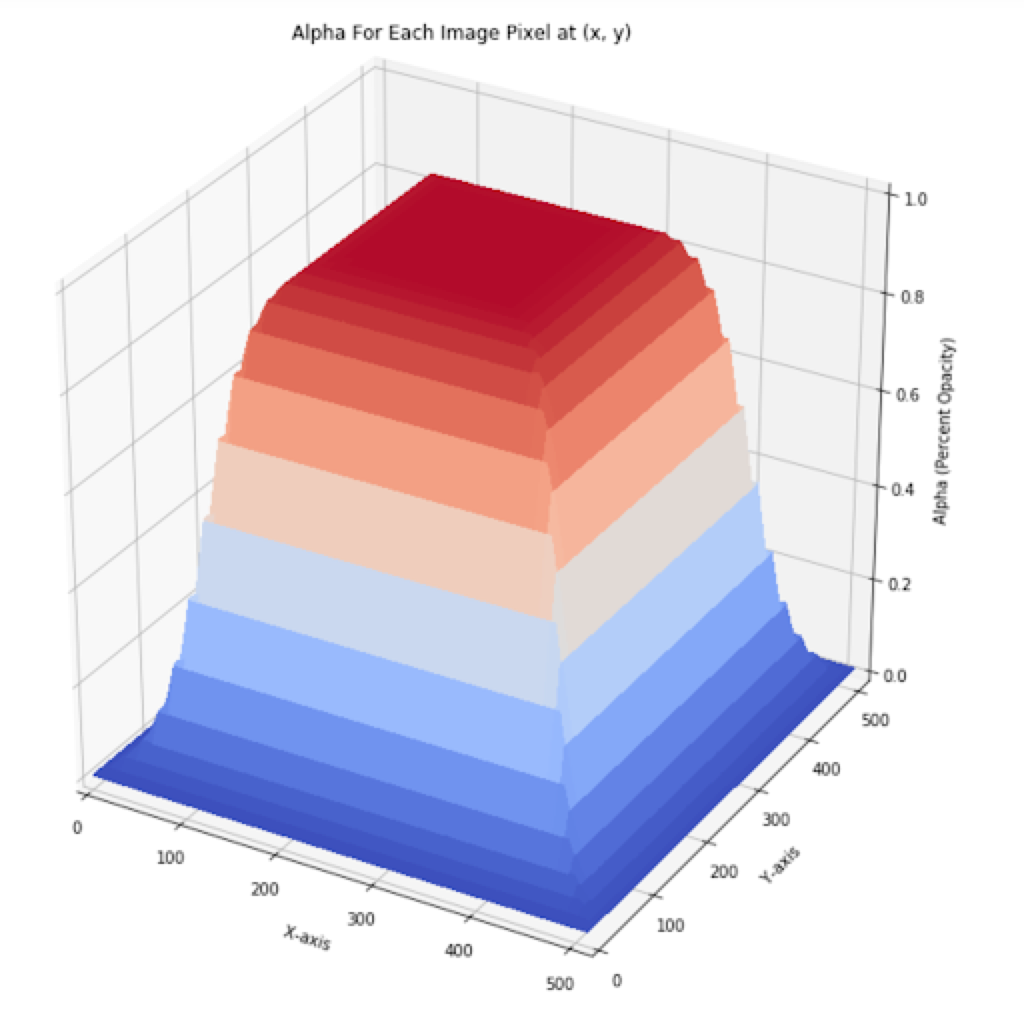
这里j决定了S形函数的陡度,k是拐点,m是坐标中点值。函数画出来如下:
Emily把动画集中的33帧图像都做了如上处理,结果每一张看起来都浑然一体:

用BlazeFace跟踪观看者的头部
到此,剩下的任务就是决定如何通过摄像头跟踪用户,以显示相应的画面。
自然,他用TensorFlow.js来处理这项任务。TensorFlow库提供了一系列相当健壮的模型用于检测视频中的人像。经过调研,他选择了BlazeFace。
BlazeFace是一个基于深度学习的目标识别模型,能够检测人脸和脸部特征点。该模型经过专门训练,以适应移动摄像头作为输入源。这非常适合他的情况,因为作者预期大部分使用者用类似的方式使用他们的摄像头——头部入镜,正面朝向摄像头,距离较近——不管是用移动设备还是笔记本电脑。
不过,他选择BlazeFace的最主要考量是它出色的检测速度。这个项目要成功,就得把整个动画实时跑起来,这包括了人脸识别的时间开销。BlazeFace改编了single-shot detection (SSD)模型——一种基于深度学习的目标检测算法,能够在一次网络前向传递中同时定位边框和发现目标。BlazeFace的轻量级检测器能够达到每秒200帧的人脸识别速度。

给定输入图像,BlazeFace可以捕获的内容的演示:人头的边界框以及面部标志。
选定模型之后,Emily又写了一些代码用于把用户的摄像头数据对接到BlazeFace。程序每跑一次,模型会输出一个包含人脸特征点的数组,以及特征点对应的2维坐标。用这些数据可以计算用户两眼的中点位置,这样就近似得到了脸部中心的X坐标。
最后,Emily把结果离散映射到整数0到32,每一个数字对应动画序列中的一帧(如果你还记得的话,动画集里有33帧)——0代表蒙娜丽莎的视线转向最左,32则在最右。接下来,只要在屏幕上显示相应的画面就可以了。
来试一下吧!
相关报道:
https://blog.tensorflow.org/2020/09/bringing-mona-lisa-effect-to-life-tensorflow-js.html
实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn