
如何做到史上最快的基于CPU的通用强化学习环境并行模拟器?
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


导读
一个基于C++的、高效的、通用的RL并行环境模拟器EnvPool,并且能兼容已有的gym/dm_env API。根据现有测试结果,能在正常的笔记本上比python subprocess快个3倍,在256核的CPU上能全吃满,跑出一百万FPS。
这不是标题党谢谢,这是我暑假做的项目)
TL; DR: EnvPool是一个基于C++的、高效的、通用的RL并行环境(俗称vector env)模拟器,并且能兼容已有的gym/dm_env API。根据现有测试结果,能在正常的笔记本上比python subprocess快个3倍,并且在服务器上加速比也很高(核越多越高),在256核的CPU上能全吃满,跑出一百万FPS,比subprocess快十几倍,比之前最快的异步模拟器 Sample Factory(https://github.com/alex-petrenko/sample-factory/)还快个一倍多两倍(有的时候甚至同步版EnvPool跑的都比Sample Factory快)!
现在已经在GitHub开源了!欢迎批评以及各种评测(虽然还有很多东西没从内部版checkout出来……在做了在做了……咕咕咕)
https://github.com/sail-sg/envpool
使用的话……原来SubprocVecEnv怎么用,EnvPool也可以一样用,当然还有一些高端用法后面会慢慢说
为啥要做这个项目
首先玩过RL的人应该都知道,如果把1个env和1个agent交互的过程变成n个env和1个agent交互,那么训练速度会大大提高(如果调参调的好的话),计算资源利用率也会提高,这样就可以几分钟train出来一个不错的AI而不是原来的几小时甚至几天。(其实这也是 tianshou (https://github.com/thu-ml/tianshou)立项原因之一)
其次是目前主流的环境并行解决方案是python for-loop和python subprocess+share memory。虽然很方便写,但是……太慢了。for-loop慢是很正常的,subprocess慢是因为几个原因,一个是process的切换需要context switching,导致overhead比较大,第二个是python有GIL,三是数据传输也有额外开销,四是python有点慢(所以正常的环境为了确保性能都是C++写的)
那么我们为啥不能直接在C++这一层把并行给做了呢?对外只暴露batch的接口
然后有人要说了,为啥不分布式呢?ray其实也做了这个而且看起来挺灵活。但是根据测试,ray的计算资源利用率不太行,通常加速比是负数(,这样会花很多冤枉钱在训练上面
然后有人要说了,为啥不GPU用CUDA做呢?其实有项目已经做这个方面的优化了比如 Brax / Isaac-gym,但是GPU的话其实不够通用,要重写整个env代码,意味着不能很好兼容生态以及不能用一些受商业保护的代码。所以现在他们只重写了几个类似mujoco的env,虽然能达到几千万FPS但毕竟不能适用于所有RL环境。
Brax:https://github.com/google/brax
Isaac-gym:https://developer.nvidia.com/isaac-gym
然后有人要说了,为啥之前没人做这个C++层面并行的idea?其实是有的,只不过没做好。举几个例子是openai的 gym3 和 procgen 也是这么做的,但是我当时顺便测了下速发现他们 实 在 不 行。看这里有个讨论:https://github.com/thu-ml/tianshou/issues/409
gym3 :https://github.com/openai/gym3
procgen:https://github.com/openai/procgen
(一个小插曲:我还在写EnvPool的时候,678月连着放了Brax/Isaac-gym/WarpDrive,虽然都是通过GPU进行加速,但是感觉非常慌,害怕连这种代码量巨大的项目也要卷……不过看起来是我多虑了)
(还有一个小插曲:某天看到票圈里面有个人说,花了三个月时间做Atari实验一共用了60万RMB,说应该把Atari剔除出RL benchmark。那我负责喊666然后顺便可以推销一波EnvPool,能省40万的话我要的也不多,就40万吧(雾
那么EnvPool性能究竟如何?
首先先解释一下EnvPool是如何区分同步step和异步step的。实际上在内部实现的时候这两种直接被看做是同一种方法,简单来讲举个例子,有8个env(num_envs=8)但是我每次设置只返回其中4个的结果(batch_size=4),每次step的时候把剩下的env放在background继续跑,这就是异步step;同步step就是num_envs == batch_size,每次等全部step好再返回。理论上这种异步step能够有效提高CPU利用率(事实确实如此)
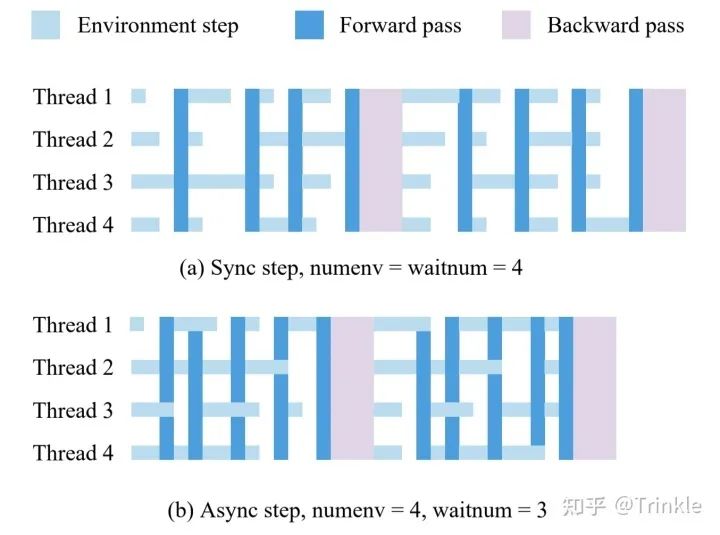
然后直接上图
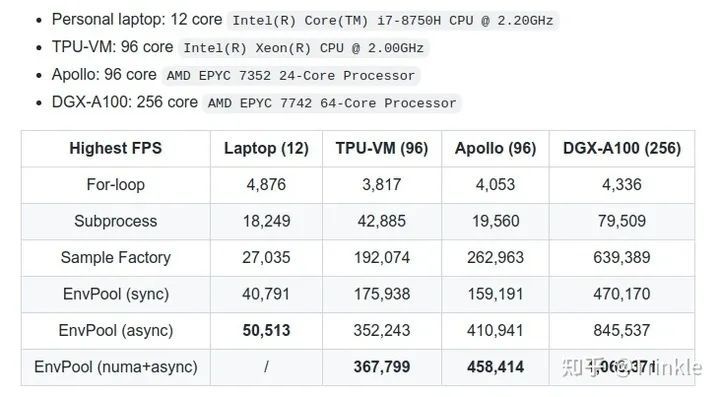
昨天和今天刚跑出来的。
首先EnvPool可以很方便的定义是同步版(每次step所有env,和vector_env一样)还是异步版(每次异步step指定env),这里面可以认为Sample Factory和EnvPool (async/numa) 是一组都是异步step,剩下的都是同步step。公平起见这里来算下每一组的倍数:
| Highest FPS | Laptop (12) | TPU-VM (96) | Apollo (96) | DGX-A100 (256) |
|---|---|---|---|---|
| For-loop | 8.37x | 46.09x | 39.28x | 108.43x |
| Subprocess | 2.24x | 4.10x | 8.14x | 5.91x |
| EnvPool (sync) | 1x | 1x | 1x | 1x |
| Sample Factory | 1.87x | 1.83x | 1.56x | 1.32x |
| EnvPool (async) | 1x | 1x | 1x | 1x |
为了不伤害Subprocess的自尊心,我这里就不拿async EnvPool和它比了。NUMA太优秀了就先一边站着。
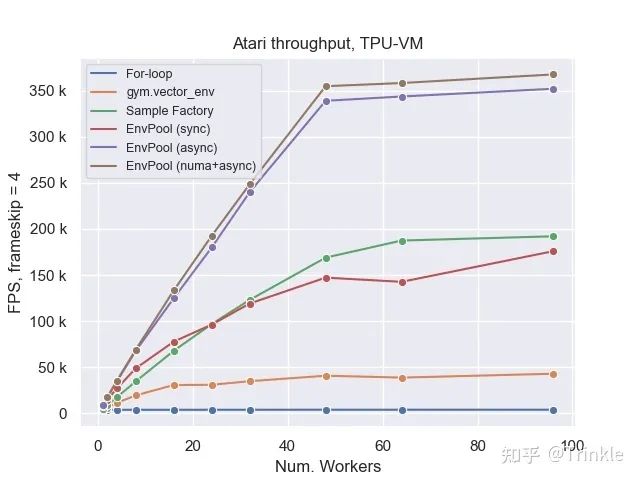
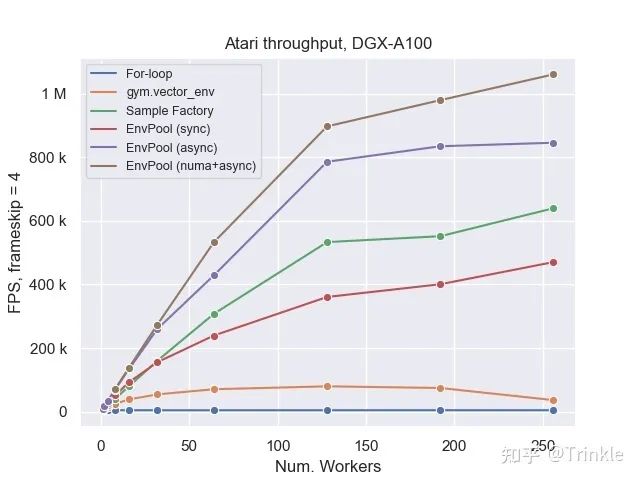
值得一提的是Sample Factory是异步实现的env.step,但是和EnvPool同步版的性能却差不多,更加证明了python-level parallalization是多么不行)
其实还有vizdoom的benchmark结果的,但是还没从内部版checkout到开源版本上面,到时候会更的!
那么……生态呢?
开源项目必须得在生态营造的地方下功夫才不至于会死。
首先是安装,使用 pip install envpool 就能在linux机子上安装成功(需要python版本3.7以上)(时间太赶还要上课做作业暂时先没考虑别的操作系统了……)
其次是用法,使用
env_gym = envpool.make_gym("Pong-v5", ...)
env_dm = envpool.make_dm("Pong-v5", ...)
# obs/act shape
observation_space = env_gym.observation_space
action_space = env_gym.action_space
就能轻松得到一个gym.Env或者dm_env,在同步模式下API是和已有的标准API完全一致,当然也可以只step/reset部分env,只需要多传一个参数就行:
while True:
act = policy(obs)
obs, rew, done, info = env.step(act, env_id)
env_id = info["env_id"]
(这其实已经是异步step了,如果每次env_id都只有一部分的话)
以及在设计新版EnvPool的时候,我们还考虑了结构化数据(比如nested observation/action)、multi-player env、以及二者融合的情况,接口都预留好了;
以及对于潜在的contributor而言,只需要在C++一侧按照envpool/core/env.h的API把环境接好,然后实例化注册一下就能成功用上EnvPool的加速。
对于开源项目最重要的测试和文档,现在已经搭了一套比较成熟的CI pipeline进行C++和Python两方面的测试,并且文档已经就位了:
里面有各种API解释和各种可配置参数。以及顺带提供了一些examples在envpool/examples at master · sail-sg/envpool(https://github.com/sail-sg/envpool/tree/master/examples),理论上可以直接跑的(虽然确实还比较少但是……我不想掉头发,会做的会做的 咕咕咕咕)
最后日常不要脸求star,再放一遍链接
https://github.com/sail-sg/envpool
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!