
【论文解读】传统图像处理与深度学习又一结合:时空多尺度非局部自相似集成视频超分
导读
本文将传统图像处理中的自相似性、金字塔等思路与深度学习相结合进行视频超分,得到了SOTA指标,并为传统图像处理思路与深度学习提供了一个新的结合点。>>

Abstract
视频超分旨在采用多个连续低分辨率图像重建高分辨率图像,在这个过程中,帧间与帧内信息是探索时序与空域信息的关键源。现有视频超分方案往往存在这样几个局限性:(1) 采用光流进行时序相关估计,然而光流估计本身是存在误差,进而影响重建质量;(2) 图像中存在的相似模式在视频超分中鲜少有所应用。
受此启发,作者提出了一种时序相关集成策略以更好的利用帧间的相似块,提出一种跨尺度非局部相关集成策略以更好探索图像不同尺度见的自相似性。基于上述两个新提出的模块,作者构建了一种有效的MuCAN(Multi-Correspondense Aggregation Network)用于视频超分,所提方法在多个公开数据集上取得了SOTA性能。
该文主要贡献包含以下几点:
提出一种新的MuCAN用于视频超分,它在多个公开数据集取得了SOTA性能; 提出两种有效的模块:TM-CAM与CN-CAM以更好的探索时序和多尺度的相似性; 提出一种 Edge-aware损失以促使网络生成更好的边缘。
Method
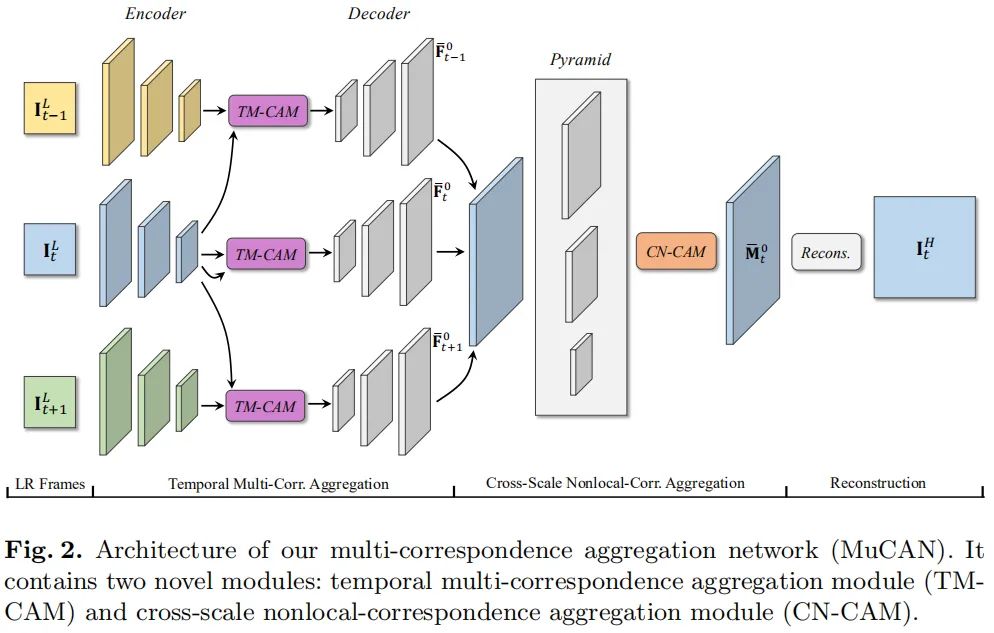
上图给出了本文所提出的MuCAN网络结构示意图。它以个连续低分辨率图像作为输入,输出中间帧的高分辨率图像。它包含三个关键模块:TM-CAM、CN-CAM以及重建模块。接下来,我们将分别针对三个模块进行详细介绍。
Temporal Multi-Correspondence Aggregation Module
相邻帧见的运动具有正反两方面性:一方面,大的运动需要进行消除以构建相似内容的相关性;另一方面,小运动的精确估计非常重要,它是细节的增强的根源。受FlowNet与PWCNet启发,作者设计了一种分层相关集成策略以更好的同时处理大运动和小运动,见下图。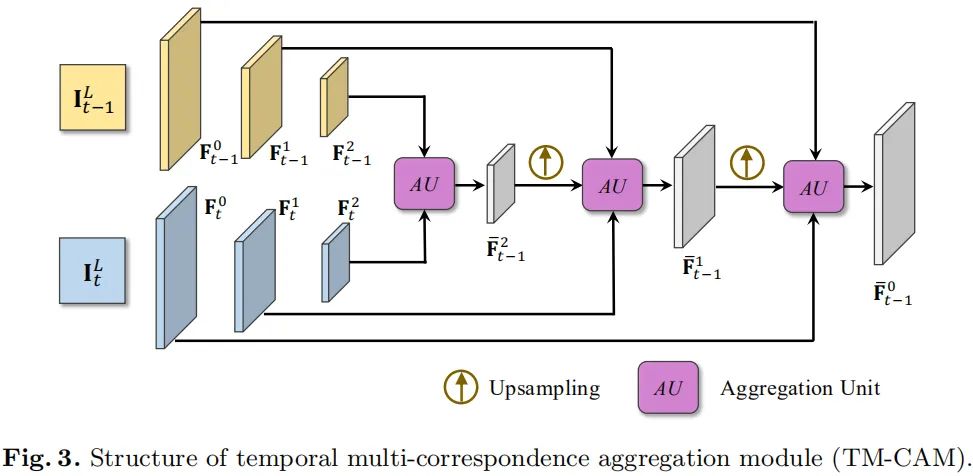
给定两个相邻低分辨率图像和, 首先将其编码到更低分辨率,然后在低分辨率阶段开始集成补偿大运动,并渐进式向高分辨率阶段补偿小运动(亚像素运动)。不同于FRVSR、DRVSR在图像空间直接回归光流,所提模块在特征空间进行处理,进而使得所提模块更为稳定与鲁棒。
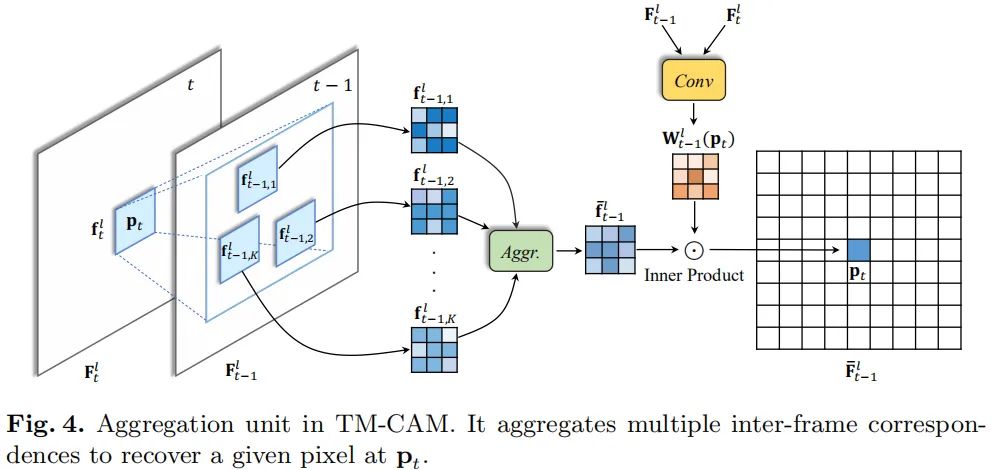
上图给出了TM-CAM中的集成单元示意图,很明显,它采用块匹配策略。由于1对1的映射难以捕获真正的帧间相关性,故而作者提出采用多对1的方式集成融合,类似于非局部均值的方式。
首先,我们定位并选择Top-K最相似块,然后采用相似自适应集成方式进行融合。以 到 为例进行说明,给定图像块,我们首先在上寻找与之最相近的块(为简单起见,这里采用进行度量,在实现过程中,作者采用FlowNet中的相关性作为度量方式)。特征块之间的相关性可以同时如下方式进行计算:
在完成相关性计算后,我们选择Top-K最相关的块进行降序排列并进行Concat与集成:
注:Aggr表示卷积操作。不同于非局部均值中的赋予不同块相同的权值,在这里作者设计了一种像素自适应的集成策略,融合权值通过如下方式计算得到:
正如Fig4所示,位置p出的输出将通过如下方式得到:
通过重复上述过程2N次,我们将得到一组对齐特征 。为处理统一特征层面的所有帧特征,我们采用了一个额外的TM-CAM用于自集成并输出。最后,所有特征通过卷积和PixelShuffle进行融合得到高分辨率特征。
Cross-Scale Nonlocal-Correspondence Aggregation Module
自然图像中存在大量的自相似性,这种自相似有助于图像的细节重建(在深度学习之前,这种自相似性曾被广泛应用与各种low-level图像处理中)。在这里,作者设计了一种跨尺度集成策略以更好的捕获跨尺度非局部相关性,见下图。
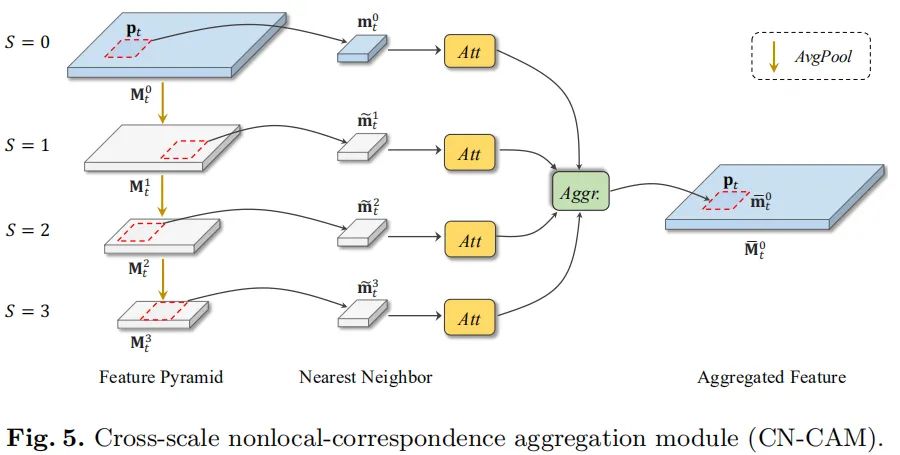
在这里我们采用表示t时刻s尺度的特征,我们首先对输入特征进行下采样并得到特征金字塔:
给定中位置q处的query块,我们需要在其他三个尺度进行相似块的非局部搜索:
在进行集成合并之前,先对所搜到的相似块通过自注意力模块判别是否真正有用。最后通过如下方式进行特征集成融合:
Edge-Aware Loss
已有视频超分方案在重建的高分辨率图像中边缘往往存在锯齿问题,为缓解该问题,作者提出了一种edge-aware损失以更好的调整边缘。首先,采用边缘检测器提取GT图像的边缘信息;然后,对于边缘区域赋予更多的损失权重以迫使网络在这些区域赋予更多的注意力。
在这里,作者采用Laplacian滤波器进行边缘提取得到边缘图,然后得到二值Mask图:
注:表示预订的阈值。在训练过程中,损失函数为CharbonnierLoss,总体损失定义如下:
其中L表示CharbonnierLoss。
Experiments
训练数据:(1)REDS,参考EDVR中的数据重组方式进行了处理;(2) Vimeo90K。度量指标:PSNR、SSIM。
关于网络架构,作者采用连续5(7)帧作为输入,特征提取与重建模块数量分别为5和40(当输入为7帧时设置为20)个残差模块,通道数为128。
关于训练超参信息,硬件信息:8卡1080Ti,每个GPUbatch=3,优化为为Adam,初始学习率为,学习调整机制为Consine,输入块大小为,数据增广为随机裁剪、随机镜像、随机旋转。训练600K次迭代。
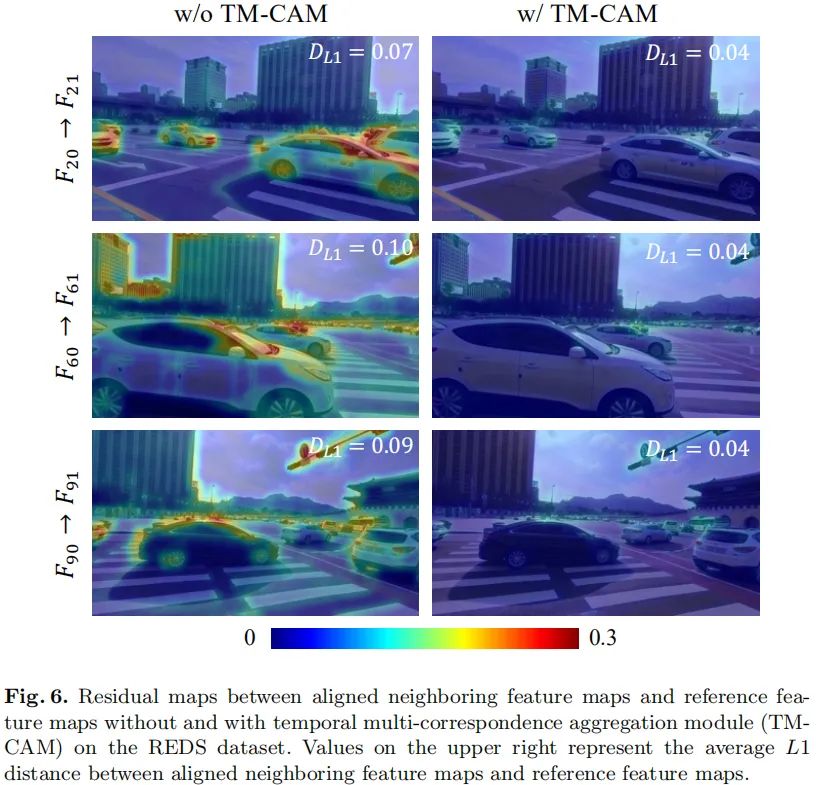
我们先来看一下消融实验效果对比以更好的说明所提模块的有效性,见下图。可以看到TM-CAM对齐模块取得了1.15dB的性能提升;CN-CAM在此基础上取得了额外的0.12dB提升;EAL在此基础上取得了0.06dB的性能提升。
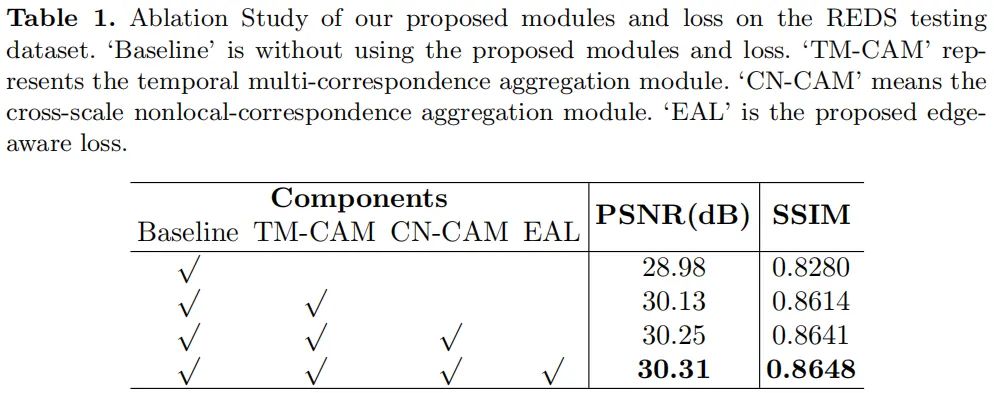
与此同时,作者还对比了添加TM-CAM与否两种情况下的重建差异对比热图,见下图。可以看到:添加TM-CAM后,重建图像与GT之间的误差更小,且误差分布更均匀,即更平滑。
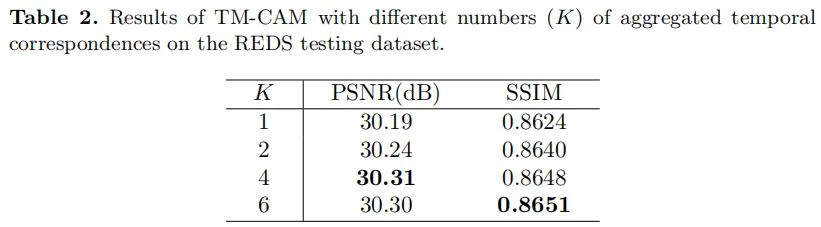
下表还给出了不同数量的相似块的性能对比,可以看到:采用4个相似块集成时效果更佳。
下图给出了CN-CAM模块的有效性示意图,CN-CAM可以在TM-CAM的基础上取得0.12dB的性能提升。下图同样说明了CN-CAM对于重建图像的结构信息有更好的保持性。

下图给出了添加EAL前后重建图像视觉效果,可以看到:添加EAL后重建图像的锐利度更优。

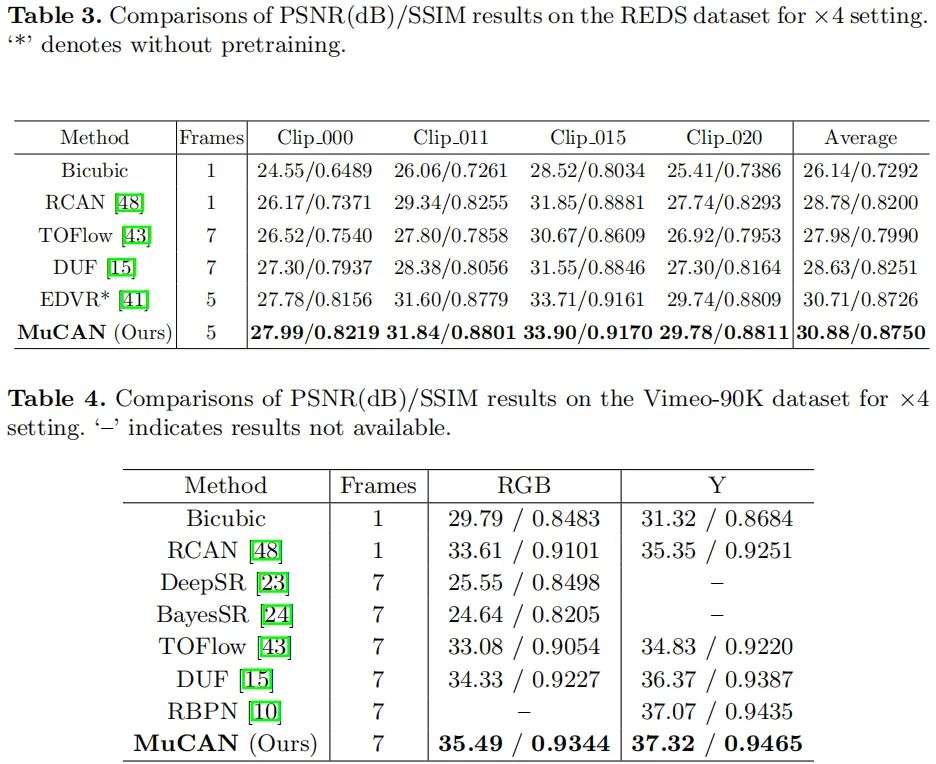
最后,我们再来看一下所提方法与其他SOTA方法的性能对比。从表中结果可以看到:(1)在REDS数据集上,MuCAN以至少0.17dB指标优于其他方法;(2) 在Vimeo90K-Test数据集上,MuCAN以1.2dB(RGB空间)指标优于DUF。
最后的最后,作者对比MuCAN与EDVR的重建效果,见下图。可以看到:EDVR生成的图像在某些情况下会存在伪影问题,而MuCAN则不存在该问题。

往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/y7uvZF6
本站qq群704220115。
加入微信群请扫码: