
从零实现深度学习框架(五)实现Tensor的反向传播

横屏观看,效果更佳!更多文章请关注公众号!
引言
本着“凡我不能创造的,我就不能理解”的思想,本系列文章会基于纯Python以及NumPy从零创建自己的深度学习框架,该框架类似PyTorch能实现自动求导。
要深入理解深度学习,从零开始创建的经验非常重要,从自己可以理解的角度出发,尽量不适用外部完备的框架前提下,实现我们想要的模型。本系列文章的宗旨就是通过这样的过程,让大家切实掌握深度学习底层实现,而不是仅做一个调包侠。
在常见运算的计算图中,我们了解了加减乘除等运算的计算图。本文通过代码实现加法和乘法的计算图来了解我们的Tensor自动反向传播计算梯度的模式。
实现运算基类
我们是一个仿PyTorch的自动求导深度学习框架,为什么要仿PyTorch呢?因为它真的非常好用。而且在这个过程会参考一些PyTorch的实现,这也会有利于我们对PyTorch的理解。
在文章EXTENDING PYTORCH(https://pytorch.org/docs/stable/notes/extending.html)中,介绍了如何在PyTorch中增加新的操作(operation),(1)首先要做的便是创建一个新的Function的子类并实现forward()及backward()方法;(2)然后,调用ctx参数上的合适方法;
forward()是进行真正运算的代码,它可以接收任意多的参数。backward()定义了梯度公式,通常有多少个输入,就得返回多少个相应的梯度。但是,有时并不是所有的参数都需要计算梯度,比如切片(Slice)参数。那么我们可以在相应的位置返回None,或者设置needs_input_grad对应位置为False。
实现者需要正确使用forward()的ctx中的函数,以确保新函数的自动求导能正确工作:
当需要保存 forward()中输入或输出Tensor以在backward()中使用时需要调用save_for_backward()方法。在前向传播时,建议调用apply()方法而不是forward()方法。mark_non_differentiable()用于表明某个输出不需要计算梯度。默认所有的输出Tensor只要是可导类型都设置为需要计算梯度。
以上节选自PyTorch官方文档的内容,虽然看起来好像并不复杂,但是完全照抄的话还是有些麻烦。我们的实现当然没有这么复杂,我们也有forward()和backward()静态方法,不需要计算梯度的参数,我们暂且返回None就好了。
class _Function:
def __init__(self, *tensors: "Tensor") -> None:
# 该操作所依赖的所有输入
self.depends_on = [t for t in tensors]
# 保存需要在backward()中使用的Tensor或其他对象(如Shape)
self.saved_tensors = []
def __new__(cls, *args, **kwargs):
'''__new__是静态方法,当该类被实例化时调用'''
# 把这两个方法转换为静态方法,我们可以通过类名直接调用
cls.forward = staticmethod(cls.forward)
cls.backward = staticmethod(cls.backward)
return super().__new__(cls)
def save_for_backward(ctx, *x: Any) -> None:
ctx.saved_tensors.extend(x)
def forward(ctx, *args: Any, **kwargs: Any) -> np.ndarray:
'''前向传播,进行真正运算的地方'''
raise NotImplementedError("You must implement the forward function for custom Function.")
def backward(ctx, grad: Any) -> Any:
'''实现反向传播,计算梯度'''
raise NotImplementedError("You must implement the backward method for your custom Function "
"to use it with backward mode AD.")
def apply(self, ctx, *xs: "Tensor", **kwargs) -> "Tensor":
'''与PyTorch一样,我们也不直接调用forward,而是调用此方法'''
# [t.data for t in xs]遍历Tensor中的data(np.ndarray)值,参与实际计算的都是NumPy的数组。
ret = Tensor(self.forward(ctx, *[t.data for t in xs], **kwargs),
requires_grad=any([t.requires_grad for t in xs]))
if ret.requires_grad:
ret._ctx = ctx
return ret
我们先定义好自己的_Function。然后根据常见运算的计算图先实现简单的加减乘除。
实现加法运算
class Add(_Function):
def forward(ctx, x: np.ndarray, y: np.ndarray) -> np.ndarray:
'''
实现 z = x + y ,我们这里的x和y都是Numpy数组,因此可能发生广播,
在实现反向传播是需要注意
'''
# 进行真正的运算
return x + y
def backward(ctx, grad: Any) -> Any:
# 输入有两个,都是需要计算梯度的,因此输出也是两个
return grad, grad
加法运算,流到的梯度为,就是上面代码中的grad。
实现乘法运算
class Mul(_Function):
def forward(ctx, x: np.ndarray, y: np.ndarray) -> np.ndarray:
'''
实现 z = x * y
'''
# 乘法需要保存输入x和y,用于反向传播
ctx.save_for_backward(x, y)
return x * y
def backward(ctx, grad: Any) -> Any:
x, y = ctx.saved_tensors
# 分别返回∂L/∂x 和 ∂L/∂y
return grad * y, grad * x
根据乘法的计算图,实现起来也比较简单。
加法和乘法实现好了,我们下面看如何结合计算图的知识通过代码实现它们的反向传播。
实现反向传播
使用过PyTorch的童鞋知道,只需要在Tensor上调用backward()就能计算梯度。
本小节,我们也来实现这样的功能。
在自动求导神器计算图中,我们其实已经看到了如何实现了。下面通过代码来描述它们。
和之前介绍的例子一样,我们也以e = ( a + b ) ∗ ( b + 1 )为例,期望调用e.backward()就能得到 a和b的梯度grad。
在自动求导神器计算图中,我们了解了反向模式。我们这里实现的当然就是这种高效的方式。
在Tensor中添加以下方法:
"""
backward函数现在应该从当前节点(Tensor)回溯到所有依赖节点(depends_on),计算路径上的偏导
# 我们分为两部分
# a) 遍历计算图
# 如果c是a经过某个函数的结果( c=f(a) ),我们无法知道a的梯度,直到我们得到了c的梯度(链式法则)
# 所以我们需要逆序计算图中的拓扑结构(reverse mode),相当沿着有向图的←方向(从指向节点到起始节点)进行计算
# b) 应用梯度
# 现在我们能访问到每个node,我们用它的backward函数将梯度传递给它们的depends_on
"""
def _rev_topo_sort(self):
'''
a) 遍历计算图,逆序计算图中的拓扑结构
Returns:
'''
def visit(node, visited, nodes):
# 标记为已访问
visited.add(node)
if node._ctx:
# 遍历所有依赖节点,递归调用visit
[visit(nd, visited, nodes) for nd in node._ctx.depends_on if nd not in visited]
# 递归调用结束后将node入nodes
nodes.append(node)
# 返回遍历结果
return nodes
return reversed(visit(self, set(), []))
反向模式的计算顺序相当于逆序计算图中的拓扑结构。我们以e = ( a + b ) ∗ ( b + 1 )为例,打印该函数的输出看。
if __name__ == '__main__':
a, b = Tensor(2, requires_grad=True), Tensor(1, requires_grad=True)
e = (a + b) * (b + 1)
print(list(e._rev_topo_sort()))
[Tensor(6.0, requires_grad=True), Tensor(2.0, requires_grad=True), Tensor(3.0, requires_grad=True)]
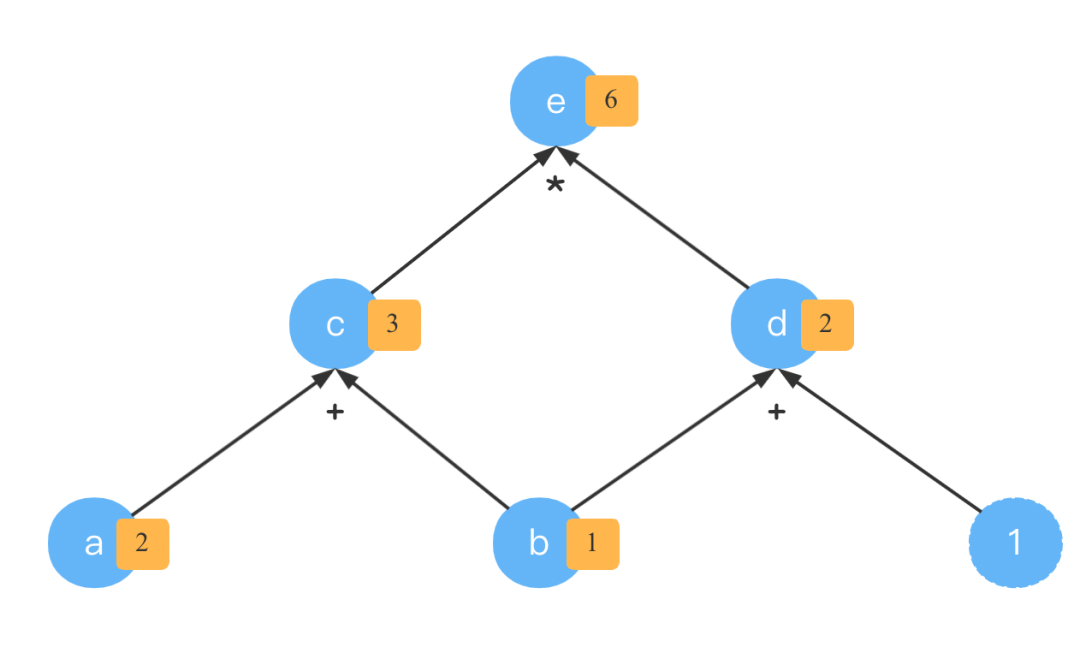
从上面的输出结合这张计算图来看,梯度由分别流向了和。
我们基于这种反向模式,来实现backward()方法。
def backward(self, grad: "Tensor" = None) -> None:
'''
实现Tensor的反向传播
Args:
grad: 如果该Tensor不是标量,则需要传递梯度进来
Returns:
'''
# 只能在requires_grad=True的Tensor上调用此方法
assert self.requires_grad, "called backward on tensor do not require grad"
self._grad = grad
# 如果传递过来的grad为空
if grad is None:
if self.shape == ():
# 设置梯度值为1,grad本身不需要计算梯度
self._grad = Tensor(1)
for t in self._rev_topo_sort():
assert t.grad is not None
# 以逆序计算梯度,调用t相关运算操作的backward静态方法
# 计算流向其依赖节点上的梯度(流向其下游)
grads = t._ctx.backward(t._ctx, t.grad.data)
# 如果只依赖一个输入,我们也通过列表来封装,防止zip将其继续拆分
if len(t._ctx.depends_on) == 1:
grads = [grads]
for t, g in zip(t._ctx.depends_on, grads):
# 计算其下游节点上的累积梯度,因为可能有多条边
if t.requires_grad and g is not None:
# t.shape要和grad.shape保持一致
assert t.shape == g.shape, f"grad shape must match tensor shape in {self._ctx!r}, {g.shape!r} != {t.shape!r}"
# grad Tensor
gt = Tensor(g)
t._grad = gt if t.grad is None else t.grad + gt
下面我们先写出计算式子,然后像PyTorch一样直接调用backward,看能否计算出对应节点上的梯度。
if __name__ == '__main__':
a, b = Tensor(2, requires_grad=True), Tensor(1, requires_grad=True)
e = (a + b) * (b + 1)
e.backward()
print(f'grad of a:{a.grad}')
print(f'grad of b:{b.grad}')
grad of a:Tensor(2.0, requires_grad=False)
grad of b:Tensor(5.0, requires_grad=False)
完整代码
完整代码笔者上传到了程序员最大交友网站上去了,地址: 👉 https://github.com/nlp-greyfoss/metagrad
总结
本文我们实现了Tensor的反向传播框架,并实现了加法和乘法的计算图。
最后一句:BUG,走你!


Markdown笔记神器Typora配置Gitee图床
不会真有人觉得聊天机器人难吧(一)
Spring Cloud学习笔记(一)
没有人比我更懂Spring Boot(一)
入门人工智能必备的线性代数基础
1.看到这里了就点个在看支持下吧,你的在看是我创作的动力。
2.关注公众号,每天为您分享原创或精选文章!
3.特殊阶段,带好口罩,做好个人防护。