
知乎搜索排序模型的演进,答主必看

大家好,我是你们的跃哥。熟悉的朋友都知道,跃哥在知乎也有一段时间了,无论是问答分享,还是知乎好物,都是玩转开了。加上盐选里还能白嫖各类优秀的书籍,以及一些优秀的课程,知乎已经成为跃哥每天必须打开N次的App。
那很多人就会纳闷,知乎是如何进行算法处理,让你的排名在搜索之后更靠前呢?今天开始,跃哥将连续分享几篇朋友圈里优秀的知乎类文章,请小伙伴们持续看过来吧。

分享嘉宾:王瑞欣 知乎 算法工程师
编辑整理:郭真继
出品平台:DataFunTalk
导读:搜索,是用户获取信息,找答案最方便快捷的方式。一次用户搜索会经历 Query 解析、召回、排序多个环节,排序作为最后整个过程一环,对用户的体验有最直接的影响。今天分享的内容是知乎搜索排序模型的演进。
主要内容包括:
知乎搜索发展历程
排序算法的迭代升级
一些未上线的尝试
未来方向
1. 知乎搜索
知乎作为一个大型的中文问答社区,有超过四千万的提问和超过两亿条回答,其中蕴含了丰富的知识、经验和见解,知乎搜索是帮助用户快速获取信息,找到答案的重要途径,随着媒介的升级,搜索结果的形式也不在局限于图文,视频解答也越来越多。
2. 知乎搜索算法发展历程
知乎的搜索算法团队成立于2017年底,于2018年8月上线了深度语义匹配模型。在2019年4月引入了BERT 模型,同年8月排序模型由 GBDT 升级为 DNN 模型,随后在DNN模型的基础上进行了一系列的迭代升级。

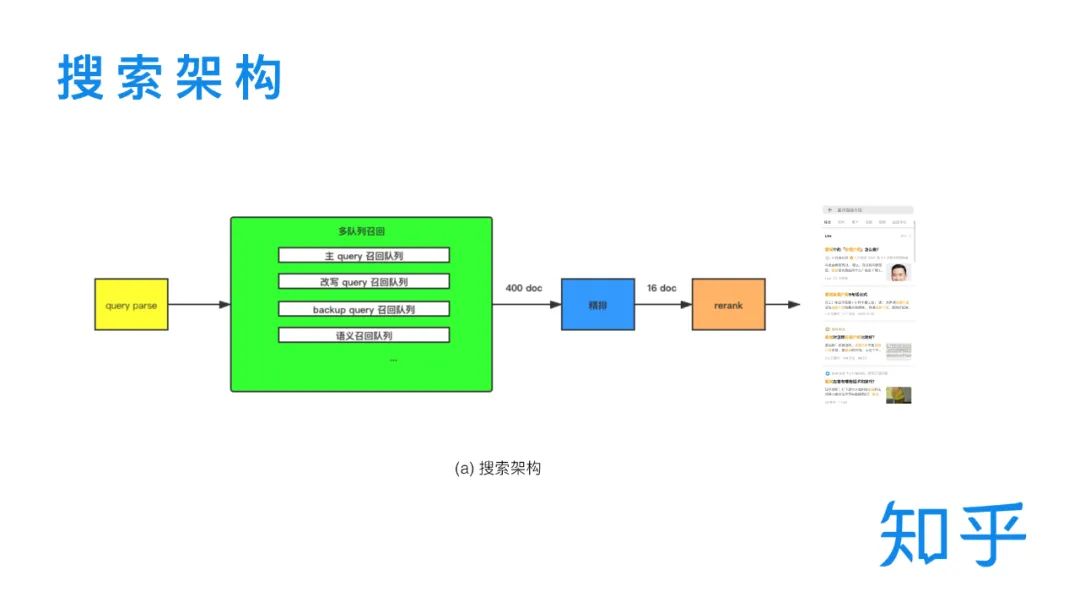
3. 知乎搜索架构
一次搜索流程主要包括 Query 解析、召回、排序几个阶段。用户输入 Query 之后,首先要进行 Query 解析,生成查询 Query Tree 和语义表示向量。之后进入多队列的召回模块,召回阶段从召回方式上说可以分为倒排召回和向量召回,在这一环节会筛选出前400的文档进入到排序阶段。排序阶段又分为精排和重排序两个环节,精排阶段通过模型对多召回源的文档进行统一打分,之后将 Top16的文档送入重排序模型进行位置的微调,最终呈现给用户。本次主要分享精排和重排序阶段两部分的模型演进。
1. 由GBDT模型升级到DNN模型
2019年8月份我们将排序模型由GBDT升级到DNN模型,这么做主要是考虑到两点:
数据量变大之后,DNN能够实现更复杂的模型,而GBDT的模型容量比较有限。
新的研究成果都是基于深度学习的研究,采用深度神经网络之后可以更好的应用新的研究成果,比如后面介绍的多目标排序。
升级到DNN模型之后,线上效果有一定的提高。

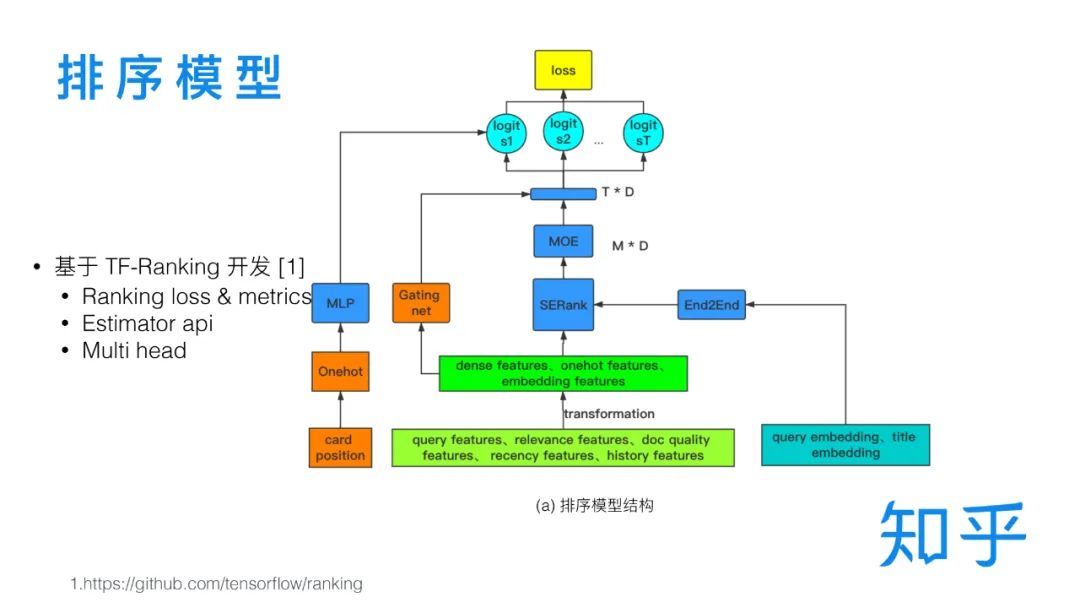
2. DNN排序模型结构
我们的DNN排序模型整体是在谷歌开源的TF-Ranking[1] 框架的基础上开发的,TF-Ranking 使用了 Estimator API,提供了排序任务常见的损失函数和指标计算实现,比如 Pairwise Loss 和 NDCG指标,以及通过Multi-head支持了多目标训练。整体的代码结构根据训练流程可以拆分成特征输入、特征转化、模型打分和损失计算等几个独立的模块。清晰合理的模块划分为后续的快速迭代提供了很大的方便和灵活性。下面简单介绍下各个模块:
特征输入模块,将 Query特征、相关性特征、文档质量特征和历史点击特征等输入模型。
特征转化模块,做一些常见的特征处理工作,比如取 log、归一化、onehot 和类别特征转 Embeding 等。
模型主体结构部分包括主网络部分、 End2End 部分,SeRank[5] 部分,Unbias tower 部分和 MOE 方式实现的多目标排序部分,后面会做详细介绍。
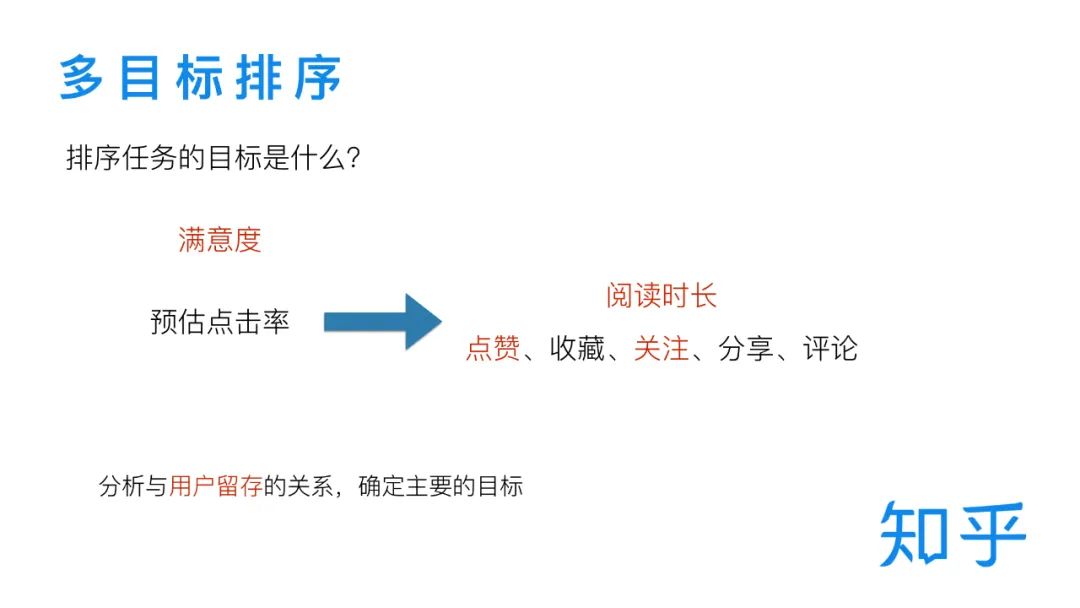
3. 多目标排序
搜索排序任务的学习目标首先能想到的就是预测用户点击,我们最初的排序模型也是这样做的。但是用户点击只是第一步,单纯的点击行为并不能代表用户对搜索结果的满意,我们需要同时考虑用户在点击之后的一系列行为,比如阅读时长、点赞、收藏、关注、分享、评论等等。这些行为都可以作为排序任务的训练目标,由于可选的目标比较多,我们通过分析这些指标与用户留存的关系进行了筛选,与点击率一起构成了排序模型的目标,开启了我们在多目标排序方面的探索。
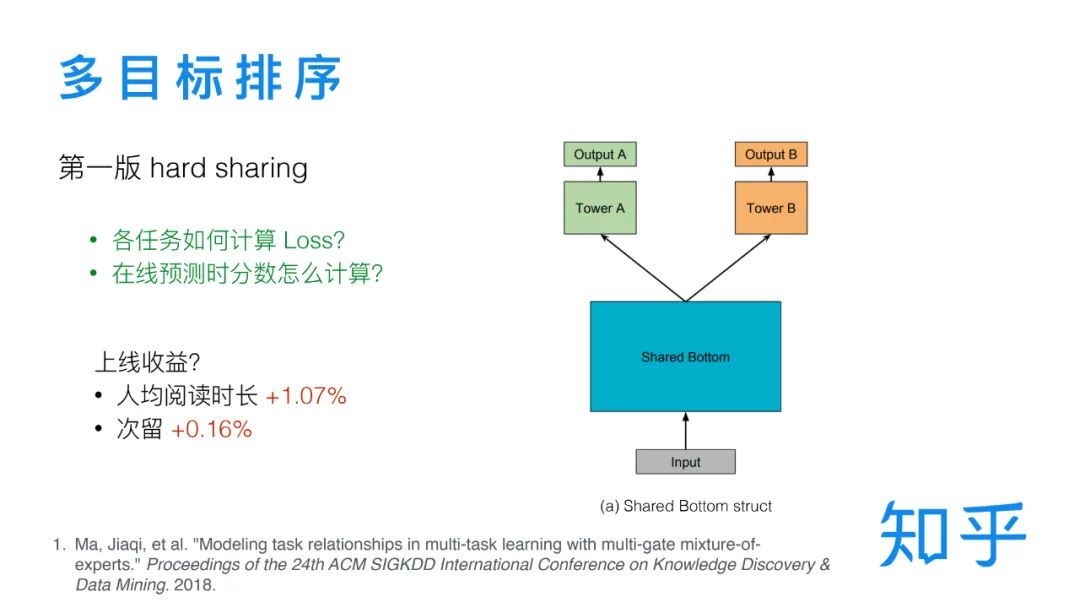
① 基于 hard sharing 的第一版多目标排序模型
第一版的多目标排序采用的是共享参数层+任务独立参数层的结构。共同学习的多个目标是有内在联系的,对一个目标的训练会帮助到其他目标,通过共享底层参数可以实现这个目的。在共享参数层之上又加了任务独立的参数层,使各个训练任务之间可以独立更新参数,保证互不影响。需要注意的是,不同目标的训练数据是不一样的,转化类的目标比如阅读时长、点赞、收藏,这些要用户点击之后才能发生,所以只在有点击的数据上计算 Loss。另外由于阅读时长呈长尾分布,需要用对数时长作为训练目标。在多目标模型中每个目标都会对应一个模型打分,在线上预测是需要多多个分数进行加权融合。至于不同的目标对应的具体权重我们是通过 AB 实验确定的。
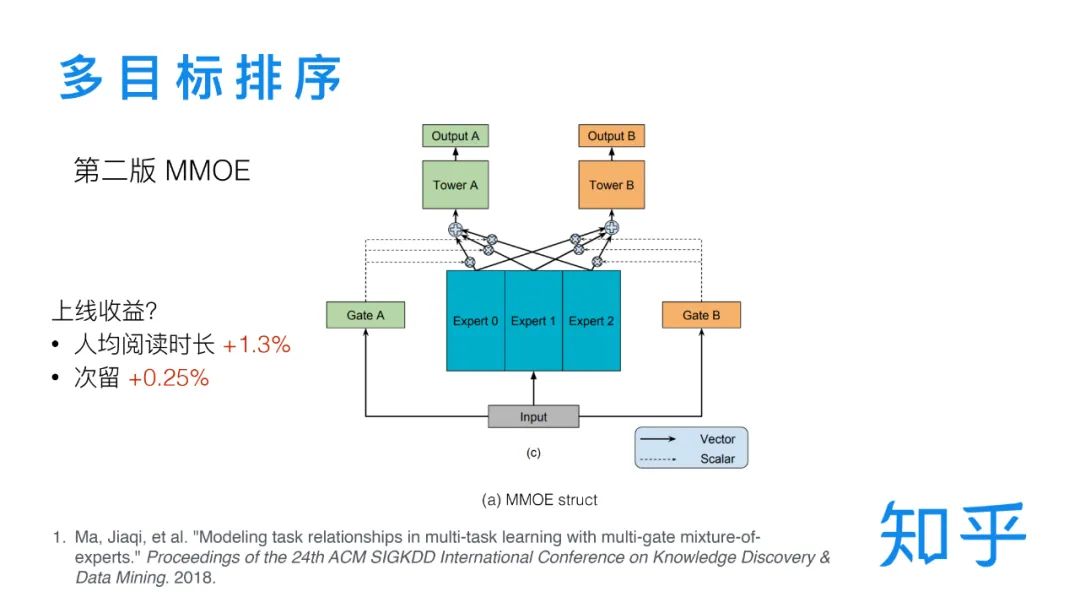
② 基于 MMOE 的第二版多目标排序
在去年年初的时候,我们采用 MMOE[2] 结构对多目标排序模型进行了升级。与 hard sharing 结构不同,MMOE 引入了 Expert,将共享参数层替换为多个 Experts 加权相加的方式,这些参数既是各个任务共享的,又通过独立权重的方式给了各个任务一定的独立性。这一版的更新在上线之后也是取得了一定的收益。
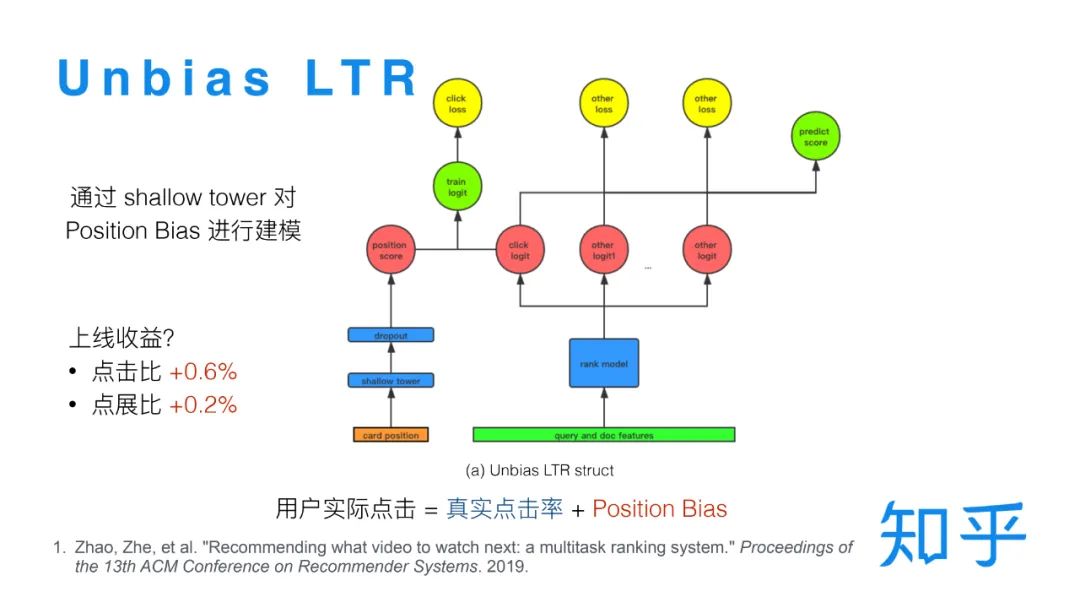
4. Unbias LTR
在使用用户点击日志作为训练数据时,点击日志中的一些噪声会对训练带来一定的负面影响。其中最常见的噪声就是Position bias,由于用户的浏览行为是从上到下的,所以同样的内容出现的位置越靠前越容易获得点击。以用户搜索小儿感冒为例,比如同时给用户展示了五条结果,用户在点击第一条之后获得了满足退出了这次搜索,这时就会生成一条训练数据,第一条作为正样本,其他的作为负样本,但是其实后面几条结果质量也比较好,如果后面的结果出现在第一条的位置也会发生点击,所以点击是受到位置影响的。在这种情况下训练数据是有偏的。

对于这个问题,有两种解决思路:
① 降低Top位置的样本权重
既然Top位置更容易受到位置偏差的影响,那么我们就降低头部样本的权重。
至于样本权重的确定,我们尝试过两种方案:
根据点击模型预估每个位置的权重,预估出来的结果可能是第一位0.7然后一直增加,到第五位是0.9
通过模型在训练的过程中自动学习权重
但是这两种方案上线之后都没有正向效果。
② 对Position bias建模
用户实际点击 = 真实点击率+ Position Bias
另一种思路就是考虑 Position Bias 的情况下,重新对用户点击进行建模。既然用户点击是由文档的真实点击率和文档的展示位置共同决定的,那就将这两部分分开预测,用文档的展示位置作为特征通过一个独立的 shallow tower 对 Position Bias 进行建模[3],将其他的 Query 和 Doc 本身的特征输入主模型结构建模文档的真实点击率,将两部分分数相加来预测用户点击。在线预测时,只需考虑真实点击率的部分。另外在训练的时候有两点需要注意,一个是最好在 shallow tower 的部分加一些 dropout 防止模型对 Position Bias 的过度依赖,另一个是只有点击目标会受到位置偏差的影响,所以只需要在点击目标上应用这个策略,在转化类目标上则无需这种处理。这一版的策略上线对点击比带来了显著的提升。
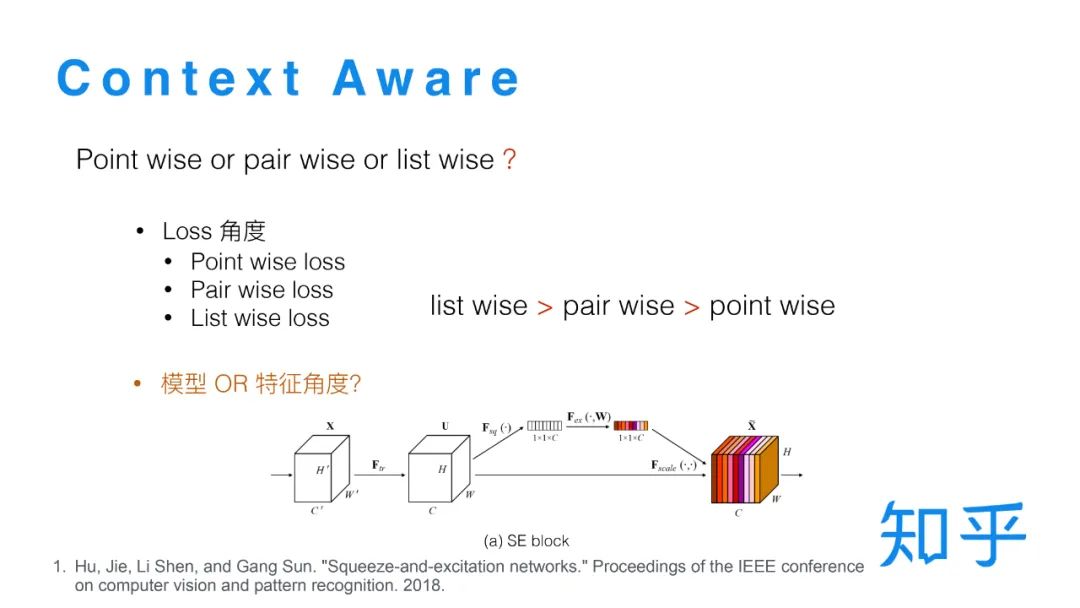
5. Context Aware LTR
对于排序任务可以有几种理解:
Point wise:确定每个文档独立打分,最终根据分数排序
Pair wise:确定两两文档对的相对顺序,推导出最终排序
List wise:直接优化待排序的文档的整体顺序
三种不同的方式都有对应损失函数,实践证明,对排序任务而言 List wise loss 优于 Pair wise loss 优于 Point wise loss。
从特征角度我们也可以通过构造一些 context 特征来实现 List wise,比如对待排序文档的特征取平均值或者中位数作为模型排序特征,实现起来比较简单,当然也是有效的。
常规的模型对不同文档的打分是相互独立的,我们希望可以实现一个模型在对单条文档打分时,同时可以考虑到其他的文档。在实践中我们借鉴了CV 中的 SE Block[4] 结构,具体到排序的场景就是:以全连接层输出 X 作为 SE Block 的输入,全连接层的输出维度是 L*C(L代表list size,C代表特征维度),然后先在 List维度上做Pooling,然后经过两层的全连接层之后将输出做Sigmoid 转换,映射到0到1之间,再跟乘回 X。通过List wise 的 Pooling操作就可以把一整个list信息融合到每个样本的打分里面,实现 List wise 打分。每一层全连接层后都可以接一个 SE Block 结构。在训练时有一个需要注意的点是,由于训练日志只是有展现的一小部分文档,但是在精排线上打分时候选集是比较大的,所以存在线上线下不一致的问题,而这种不一致对于 SE Block 的计算影响很大。为了解决这种的不一致的问题,我们在精排之后加了一个重排序阶段,把精排Top16的结果送到重排序模型中。保证Top16文档可以完整的加入到训练数据中,在离线训练时只有重排序模型应用 SE Block 结构,这样就保证了线上线下的一致性。这一版的策略更新对于头部位置的点击比提升比较明显。
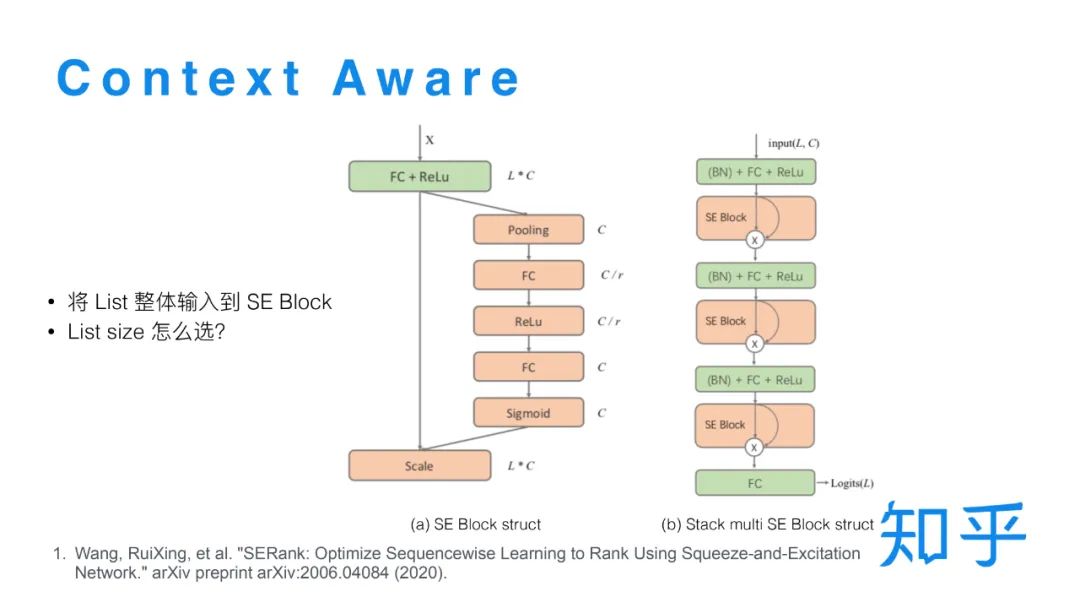
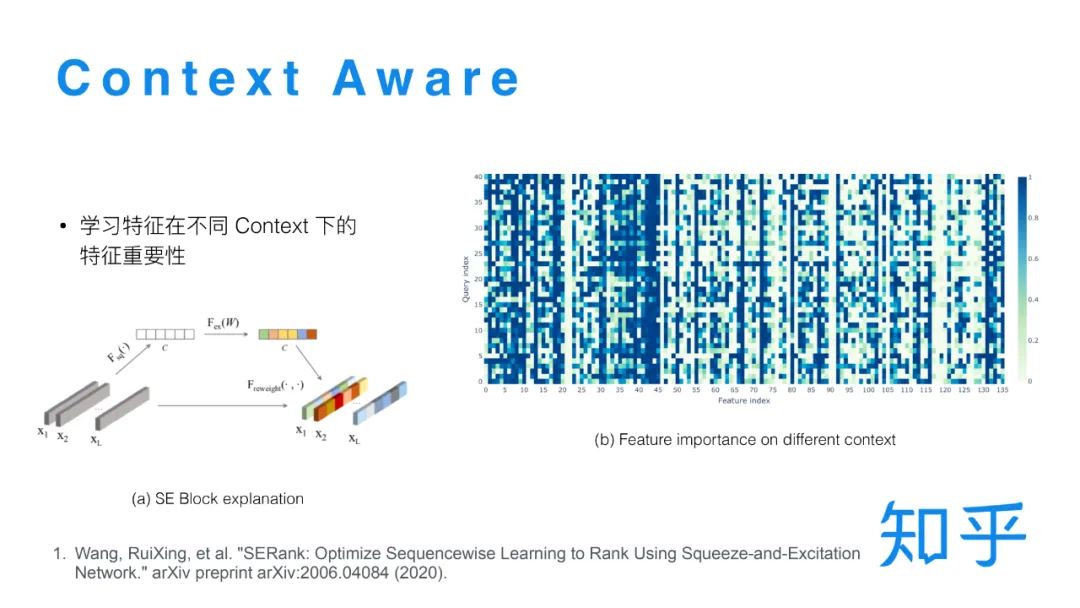
Se Block结构之所以能发挥作用,本质上是因为在单条样本打分过程中融合了所有候选集的信息。另外有一种可能的解释是 SE Block结构实现了某种注意力机制,输出的 0 - 1 的打分可以看做是某个特征在当前 Query context 下的特征重要性,而同一个特征在不同 Query 下的特征重要性是一样的,所以通过这种结构模型可能可以学到这样的信息,来帮助模型更好的打分。
6. End2End 学习
之前我们的排序模型并没有直接使用 Query 和文档的原文作为排序特征,而是将其输入相关性模型将计算得到的相关分数做为上层排序模型的特征,所以我们进行了一些 End2End 学习的尝试。
由于我们是使用 BERT 模型计算文本相关性,所以我们尝试了将 BERT 也加入到 LTR 的模型中进行训练。由于 BERT 的计算量过大,我们实际只加载的前三层的 Transformer。但是训练时长依然过长,且离线指标无提升。之后我们进行了第二次尝试,只是将 BERT 编码之后的 Query 和标题的 Embedding 向量加入到 LTR 模型中,在其上加入 Dense 层进行微调,这种方式最终获得了一定的线上收益。
7. 个性化 LTR
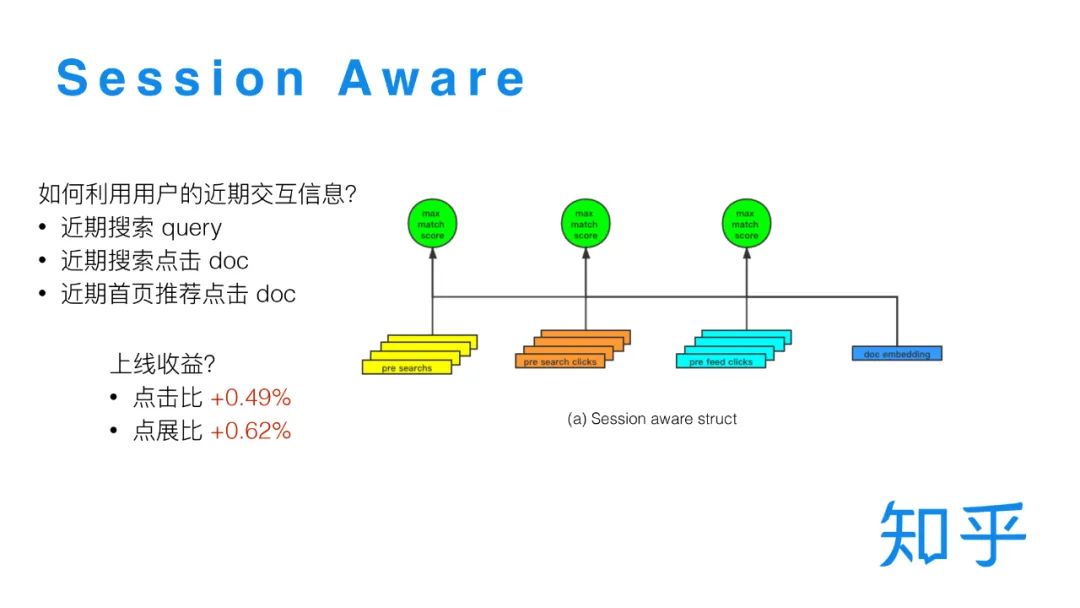
用户在发生点击行为之前,可能已经产生了很多的行为,比如有过搜索,或者点击过首页推荐的内容,这些交互行为都可以提供一些用户额外的信息用于排序。我们将用户近 30min 的搜索 Query 和点击的文档标题用 BERT 模型生成句向量输入到模型里,跟当前 Query 的Embedding做内积,计算最大匹配分数作为特征,这样操作虽然比较简单,但是拿到了很好的线上收益。除此之外我们还尝试了一些更为复杂特征交互结构,但是上线之后发现效果都不如这个简单的策略好。
1. GBDT特征编码模型
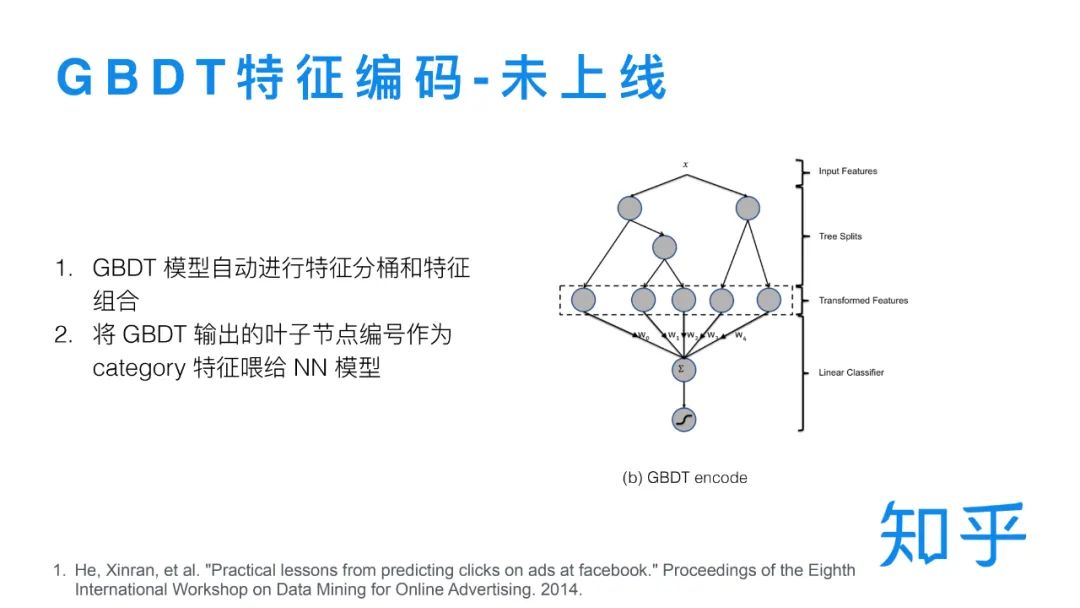
这个思路是Facebook 提出的[6],首先用点击数据训练一个 GBDT模型,利用模型进行特征分桶和特征组合,将GBDT输出的叶子节点编号作为排序模型的特征,但是这个方案没有线上收益。
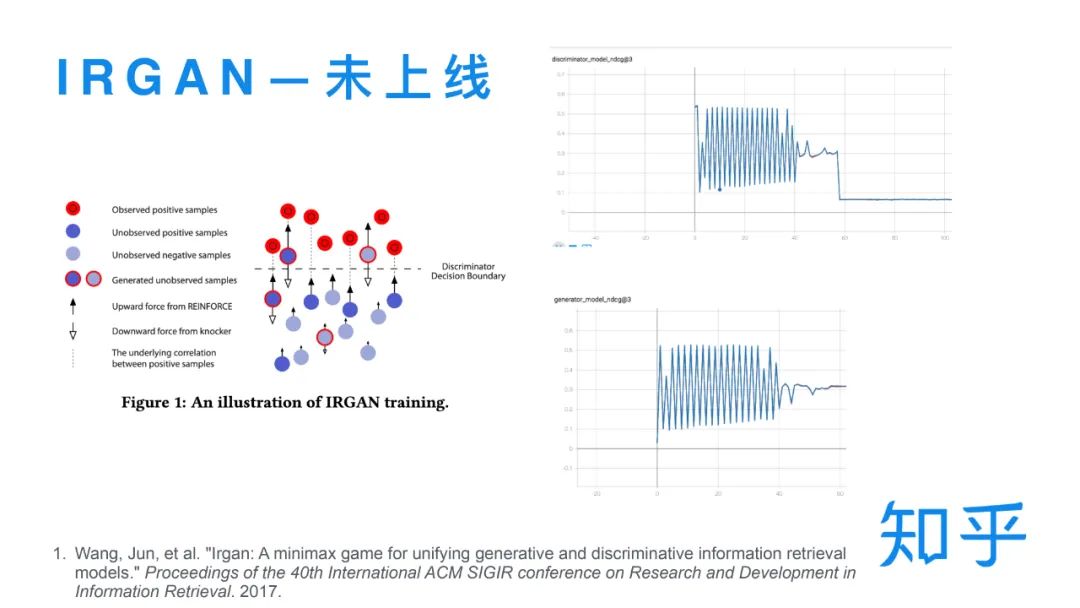
2. IRGAN,生成对抗网络模型
利用生成对抗网络训练排序任务[7],具体实现:实现一个生成网络一个判别网络,把展示未点击的样本喂给生成器,采样出疑似的正样本(作为判别器的负样本)和用户真实点击的样本一起喂给判别器。判别器的错误率作为生成器的 reward。核心思想是希望通过生成器生成的难负样本提高判别器的分类性能。但是实际训练时发现在一定步数之后模型会训练发散,并不能达到比较好的性能。
1. Online learning
我们之前发现模型在上线一段时间后指标有逐渐下降的趋势,之后尝试了模型日更,结果表明日更模型表现较好。提高模型更新频率可以让模型更快的适应新的数据分布,如果可以实时更新模型预计效果会进一步提高。
2. Graph embedding
用户的搜索 Query 和点击的文档可以构建一个图,用图挖掘的算法有可能从其中挖掘出更多的信息,提高排序模型的性能。
3. 个性化
我们目前关于个性化的尝试只是通过用户的近期交互行为挖掘了一些用户的短期兴趣,利用用户的长期兴趣画像,可以在 Query 意图宽泛时对结果做一些个性化的排序,更好的满足用户的个性化需求。
4. 边缘计算
与云计算方式不同,边缘计算可以利用用户更细粒度的交互信息,通过端上计算即时的对排序结果进行调整,进一步提升排序质量,是一个非常有潜力的发展方向。
参考资料:
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~

王瑞欣
知乎 | 搜索算法工程师
王瑞欣,知乎搜索算法工程师,在文本相关性判断和排序任务方面经验丰富。

