
一篇文章助力大家理解Python 代码中的垃圾回收机制
回复“书籍”即可获赠Python从入门到进阶共10本电子书

GNE: 新闻网页正文通用抽取器[1]更新了0.2.1版本,大幅度提高了正文的提取速度。在开发这个版本的时候,我遇到了一个非常奇怪的 Bug,最终发现是由于垃圾回收机制和内存重用机制导致的。今天我们来看看这个问题。
问题背景
先来看一段代码:
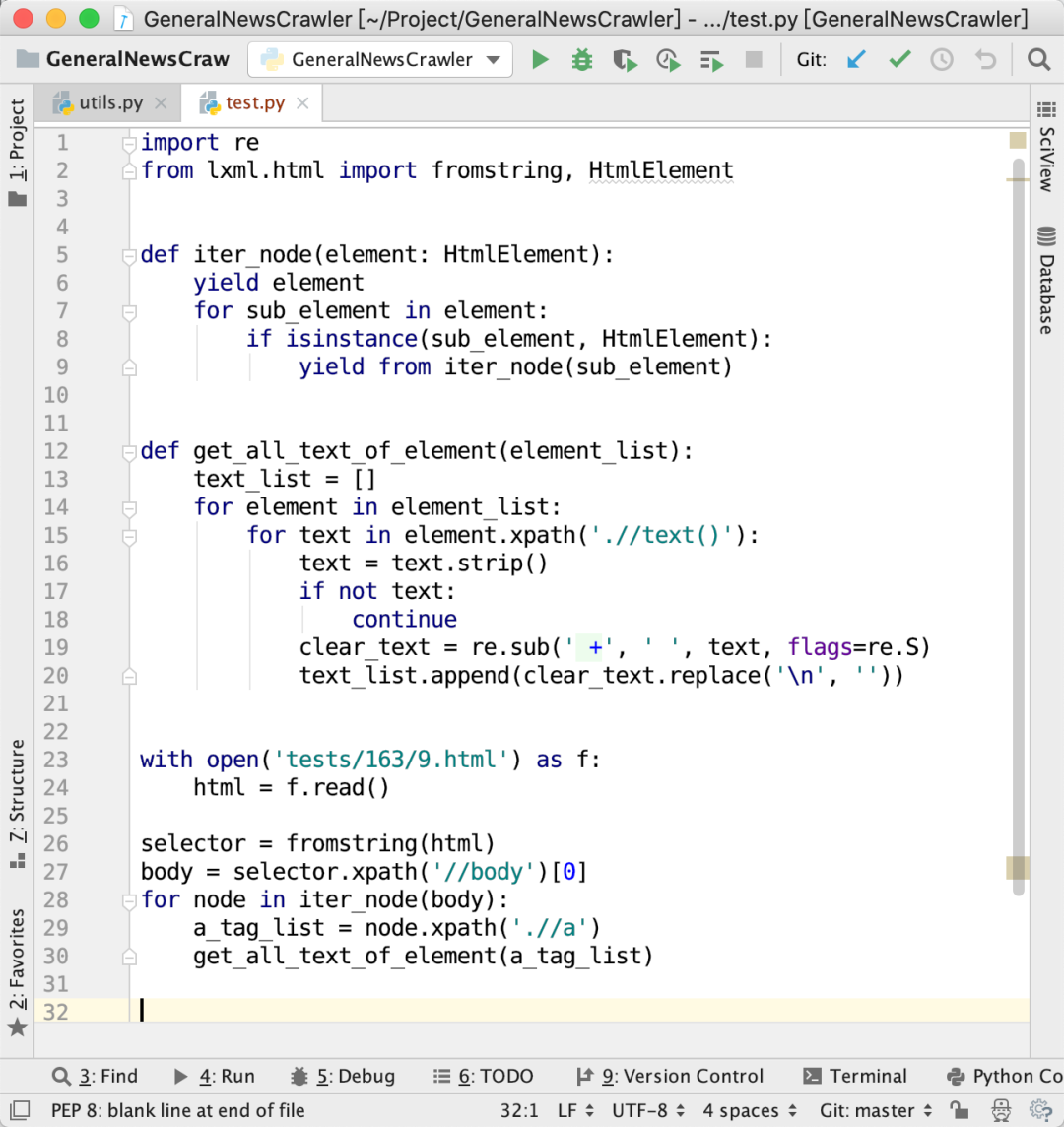
这段代码读取tests/163/9.html这个文件里面的 HTML 代码,分别获取 下面的所有标签内部的所有标签中的文本。说起来可能有点绕口,我举个例子。
世界
分别获取 但这段代码有个问题,就是对于嵌套结构的标签,会重复提取。例如: 首先,获取 这样一来,在上图代码里面第15-20行就会重复执行两次。 为了提高代码的运行效率,我们引入缓存,记录每一个 于是,代码修改成下面这样: 代码第18行的 这段代码看起来似乎没有什么问题,但在实际提取数据的时候,发现提取的结果不太正常。 为了调试这个问题,我对代码做了一下修改: 可以看到,同一个 HTML 标签,之前缓存的结果竟然跟新提取的不一样。 于是,我想看看每次提取的时候,对应的 element 是哪个,但却发生了更诡异的事情,我们做一个看起来对代码不会有任何影响的改动: 图4里面,我们直接把 但奇怪的事情就这样发生了,问题消失了!在图4大量打印的 但为什么会发生这种事情呢?难道说跟缓存的结果有关系?那么我们把列表里面的 仅仅是把 它似乎知道我在试图去观察它,当我尝试用代码去观察 遇事不决,量子力学。这个问题跟量子力学实际上没有关系。导致这个诡异情况发生的原因,是一个一直运行在 Python 里面,但是你常常忽略的机制——垃圾回收。 Python 会把不再使用的对象清理掉,从而释放内存。当我们执行一个 for 循环时: 循环第一次执行的时候,生成第一个 但如果换一种写法: 由于列表 在示例代码里面,大家注意 一开始,我有一个不正确的假设,我以为 但实际上这是不正确的。因为如果前一个节点的内存区域被垃圾回收了,那么这个区域会被重新分配,新来的节点可能碰巧会放到这个地方,这就导致两个不同的 而当我使用 所以,bug 的根本原因在于,我不应该使用 于是,修改代码,把 问题得以解决。 GNE: 新闻网页正文通用抽取器: https://github.com/kingname/GeneralNewsExtractor ------------------- End ------------------- 往期精彩文章推荐: 欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持 想加入Python学习群请在后台回复【入群】 万水千山总是情,点个【在看】行不行 /今日留言主题/ 随便说一两句吧~~标签下面的标签中的文本,也就是你好和世界。 标签,获取到的是你好所在的标签。但是,获取标签下面的标签时,获取的仍然是同一个标签。标签的分析结果,如果发现一个标签已经被分析了,就直接使用缓存的结果,避免重复分析。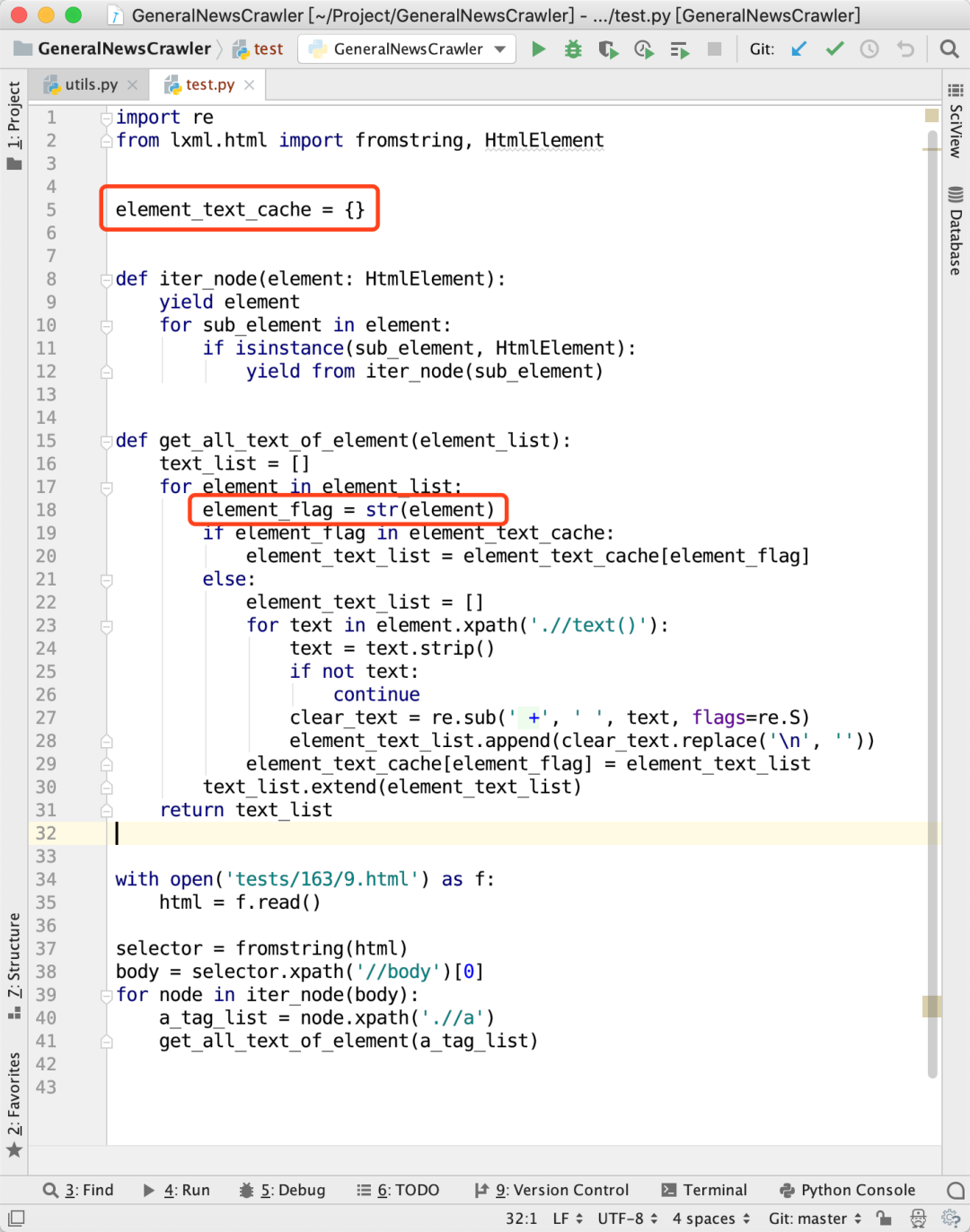
str(element)对应了这个节点的内存地址,如下图所示: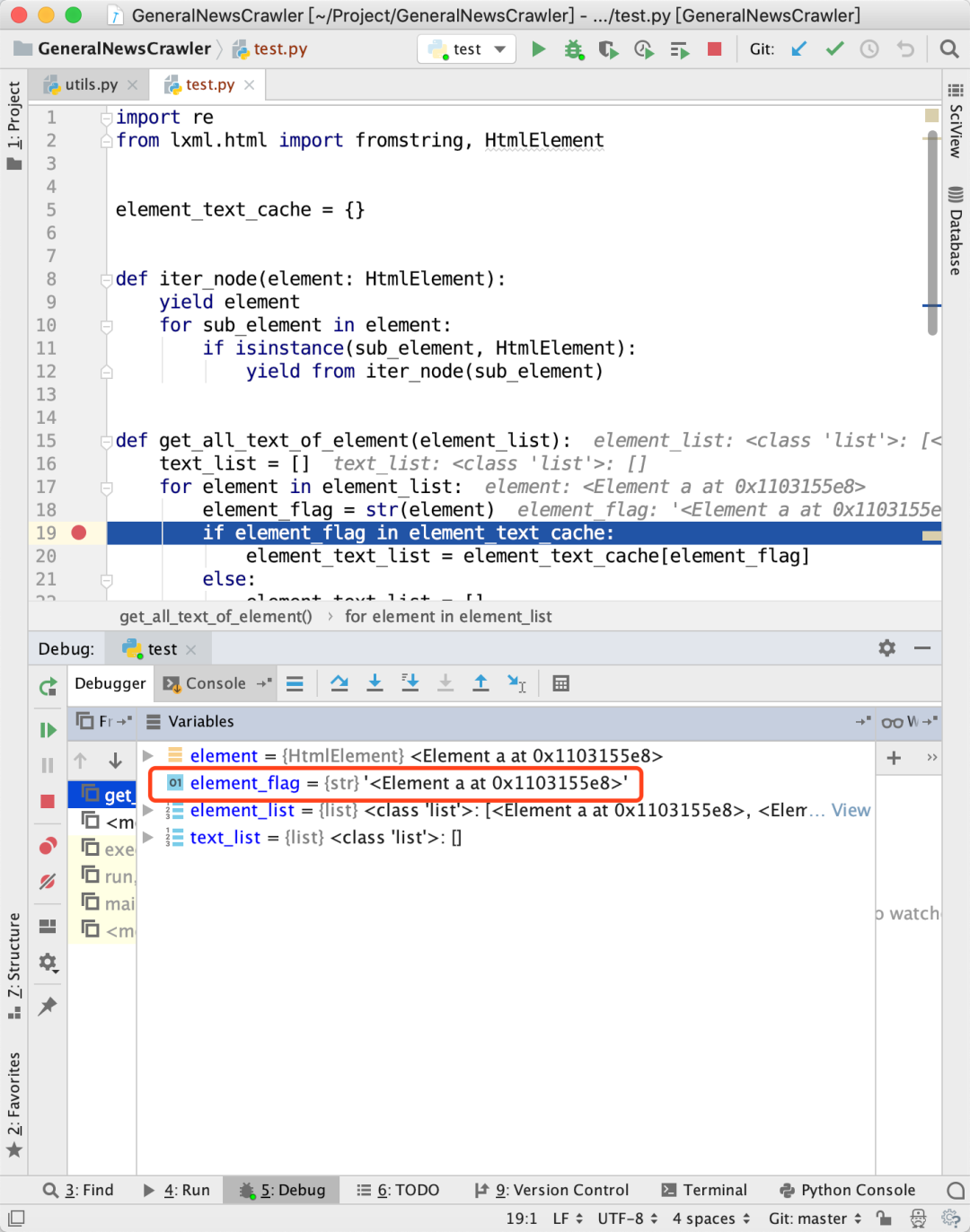
薛定谔的 Element
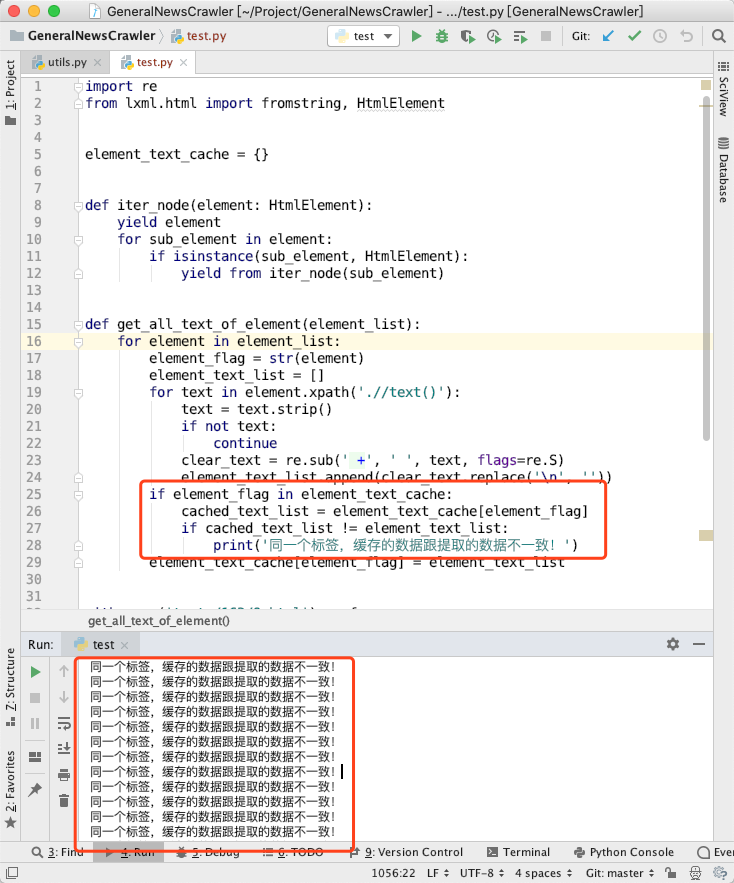
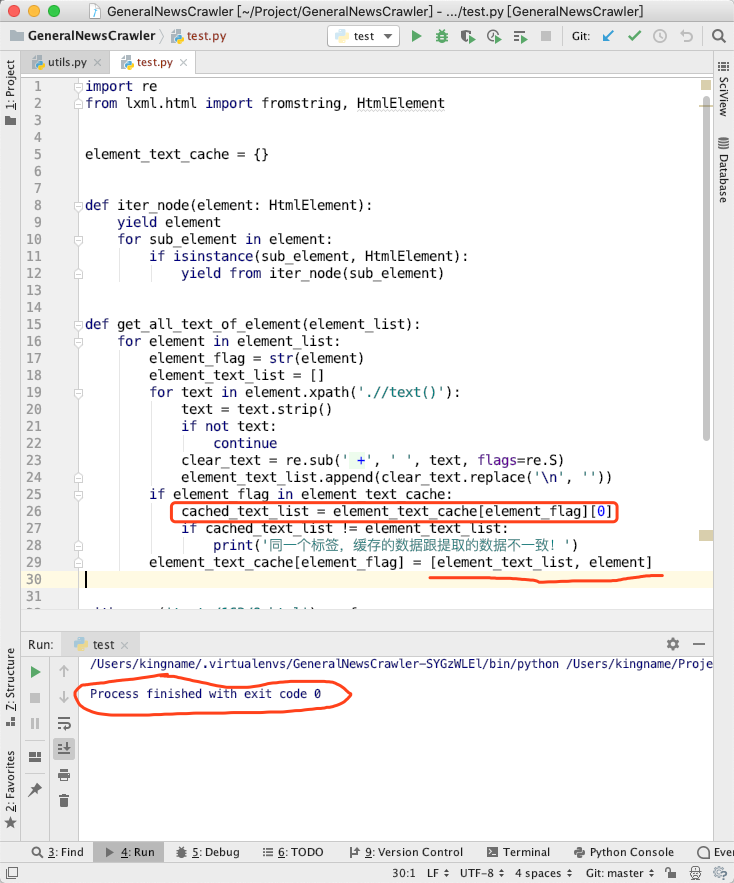
element_text_list缓存起来。图5里面,我们把[element_text_list, element]缓存起来,读取的时候,读取这个列表的下标为0的元素。也就是说,这个缓存的element我们根本不使用。同一个标签,缓存的数据跟提取的数据不一致!,在图5里面却一条都没有打印。这样修改以后,GNE 的提取的结果就正确了。element改成其他数据看看: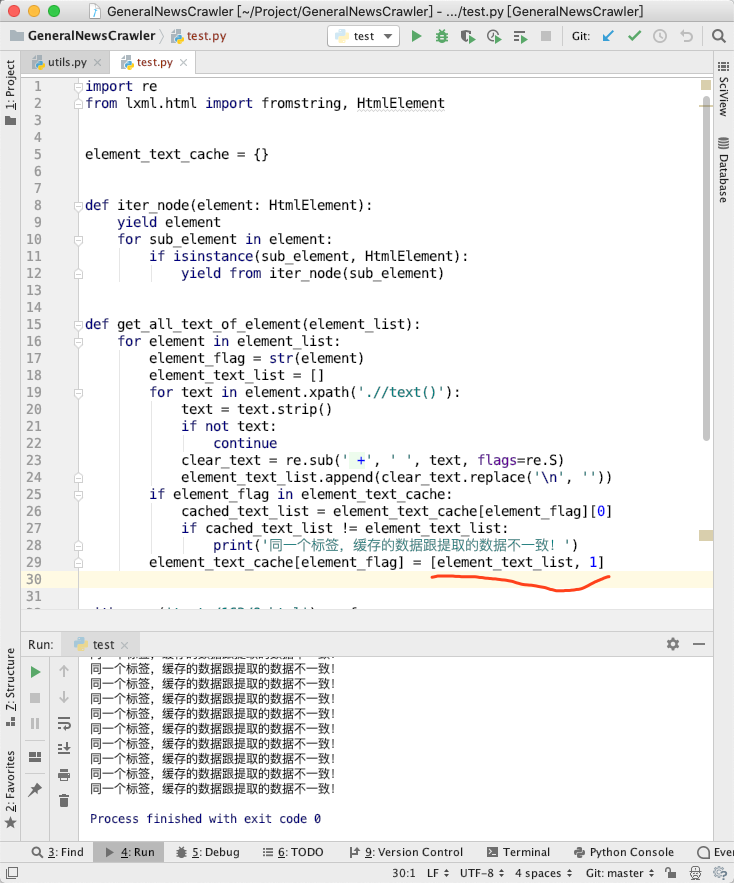
element改成了数字1,Bug 又出现了。element时,它就一切正常。当我不观察它时,它就会出问题。薛定谔的 element。看不见的手
for element in element_list: a = element.xpath('//xxx') b = element.xpath('.//text()') c = 1 + 1element对象,但是这个对象在循环第二次执行的时候就被新的element对象覆盖了。因为没有其他地方继续使用第一个 element 对象,它的引用计数归零,Python 的垃圾回收机制就会把它清理掉。它占用的内存空间也会被释放出来。cache = []for element in element_list: a = element.xpath('//xxx') b = element.xpath('.//text()') c = 1 + 1 cache.append(element)cache中包含了对每个 element 对象的引用,导致第一次循环生成的element对象的引用计数不为0,垃圾回收机制不会回收它,它始终占用了一块内存区域。这块区域不会被其他数据使用。那么每次循环,新的element对象都会新申请一块内存区域来存放数据,于是就等价于每一个不同的 element 节点对应了不同的内存地址。element_flag = str(element)这一行,它的值类似于0x1087ba638对应了这个对象在内存里面的地址。str(element)的值,对应的 HTML 里面的每个节点。同一个节点,多次执行,结果都一样,不同的节点,多次执行,结果都不一样。 标签,当你执行str(element)时,他们打印出来的结果都是相同的。但是实际上他们的正文不一样。element_text_cache[element_flag] = [element_text_list, element]时,由于每个element对象不会被回收,于是就不会出现不同的节点互相覆盖的问题,所以它的工作就符合了预期。解决问题
str(element)作为缓存的 Key,应该找一个跟 HTML 节点一一对应的东西来作为 Key。显然,使用 XPath 更好。element_flag改成 XPath: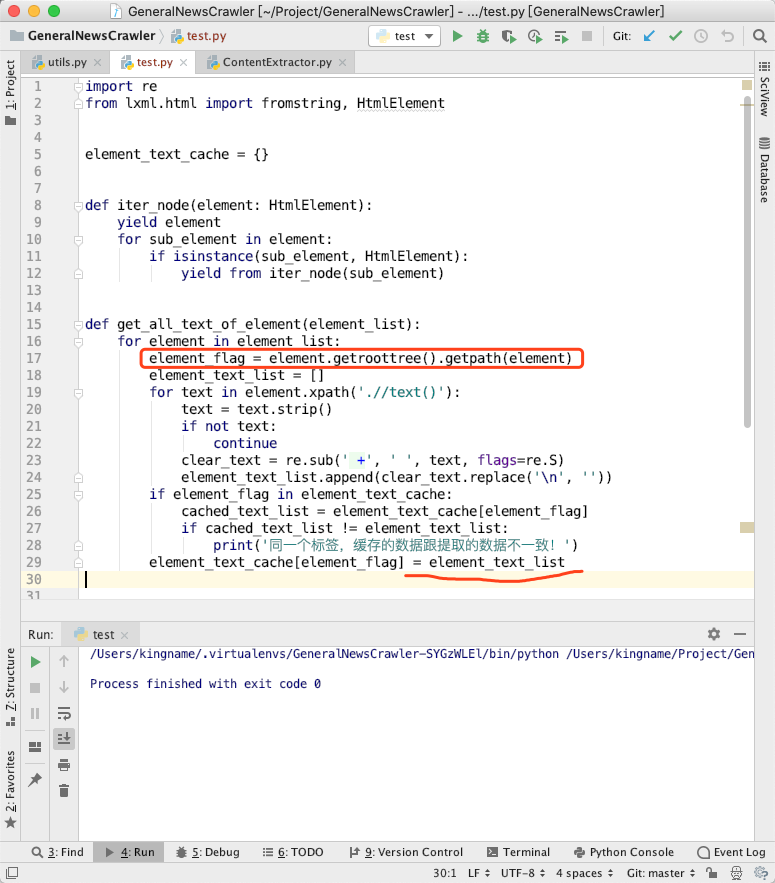
参考资料
