
抓取微博 10w 余转发信息,构建 N 层转发关系网络图谱
点击上方 月小水长 并 设为星标,第一时间接收干货推送
https://weibo.com/1139098205/Is9M7taaYhttps://m.weibo.cn/detail/4467107636950632from NewSuperWeiboForwardSpider import NewSuperWeiboForwardif __name__ == '__main__':# cookie 要换的,参考B站视频 BV1F44y1i7dqforwardSpider = NewSuperWeiboForward(mid='Is9M7taaY',start_page=1,limit=1000000,cookie='eat cookie')forwardSpider.crawl()
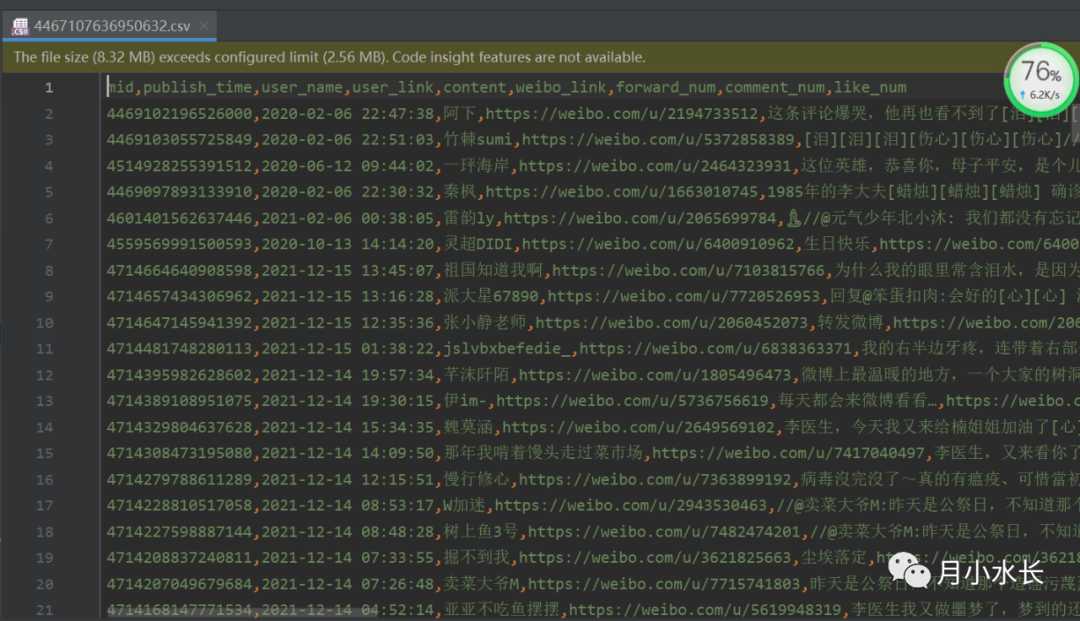
结果文件
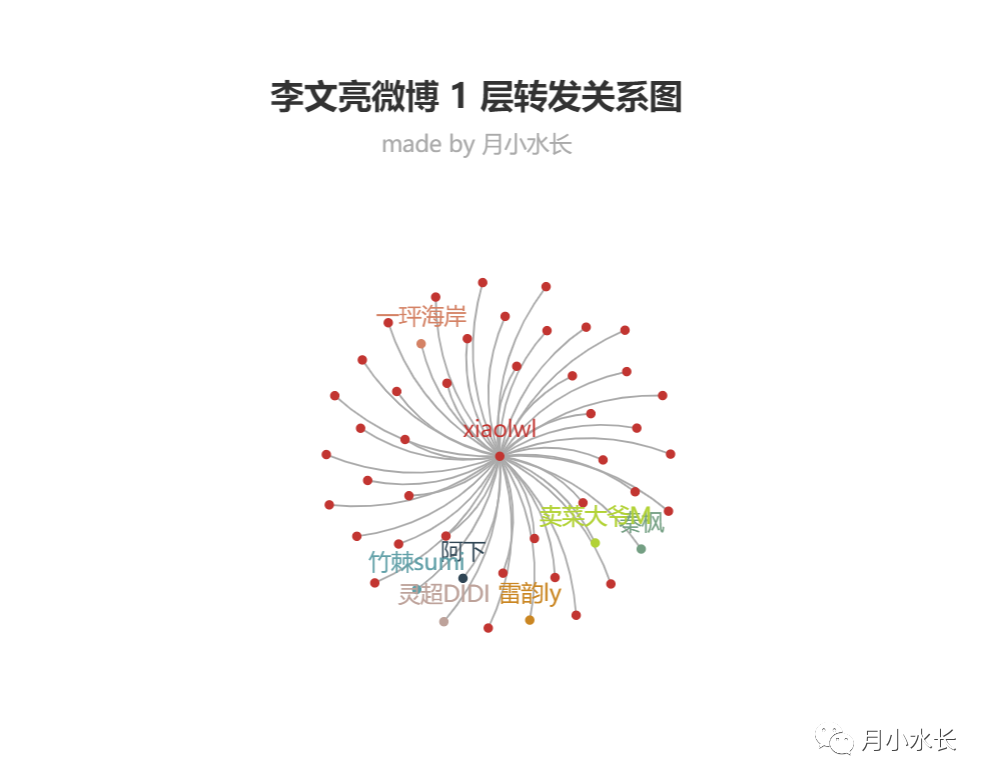
1 层转发网络
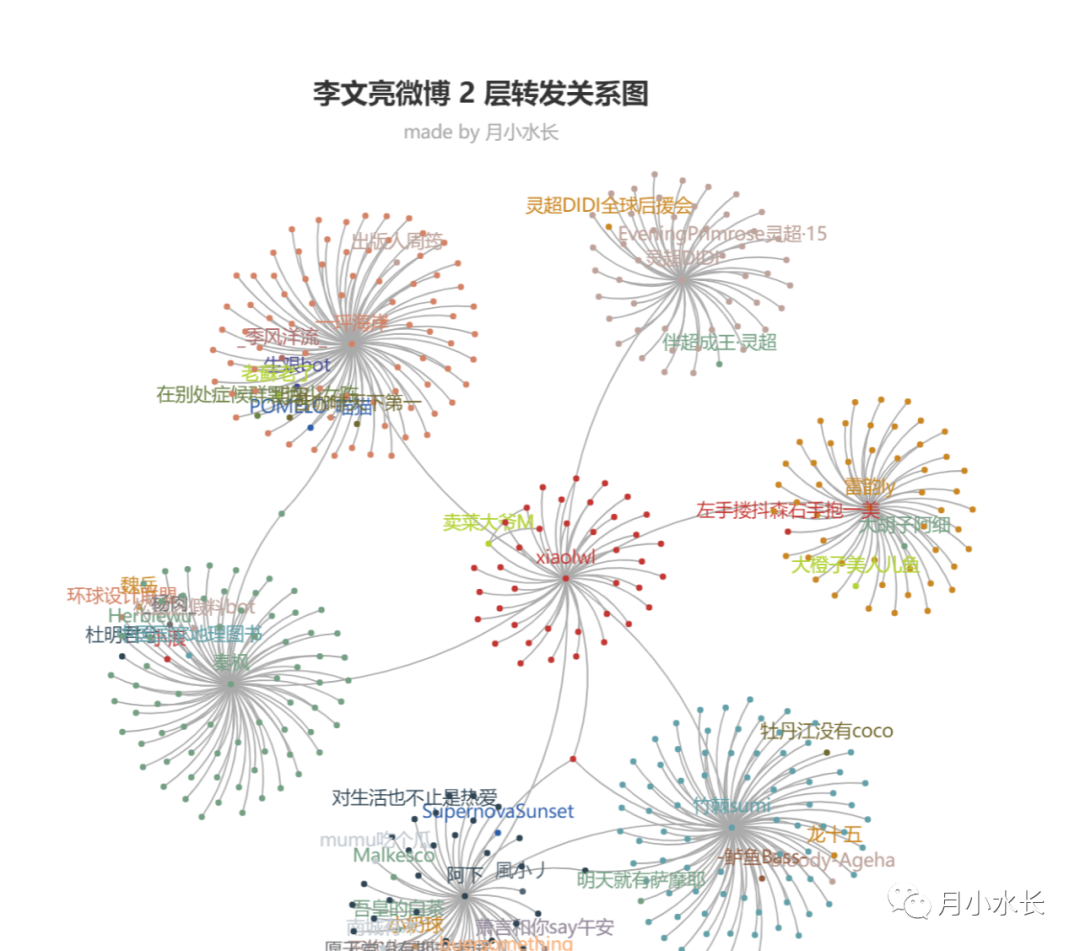
2 层转发网络
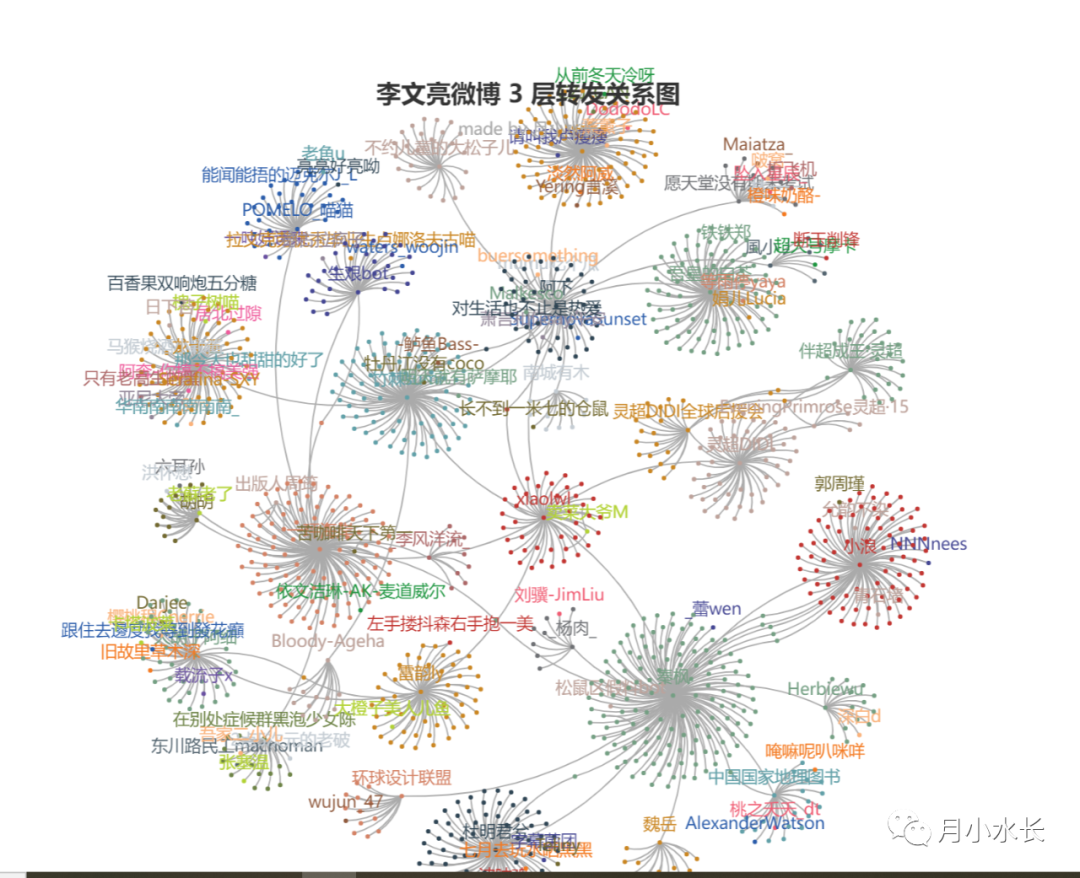
3 层转发网络
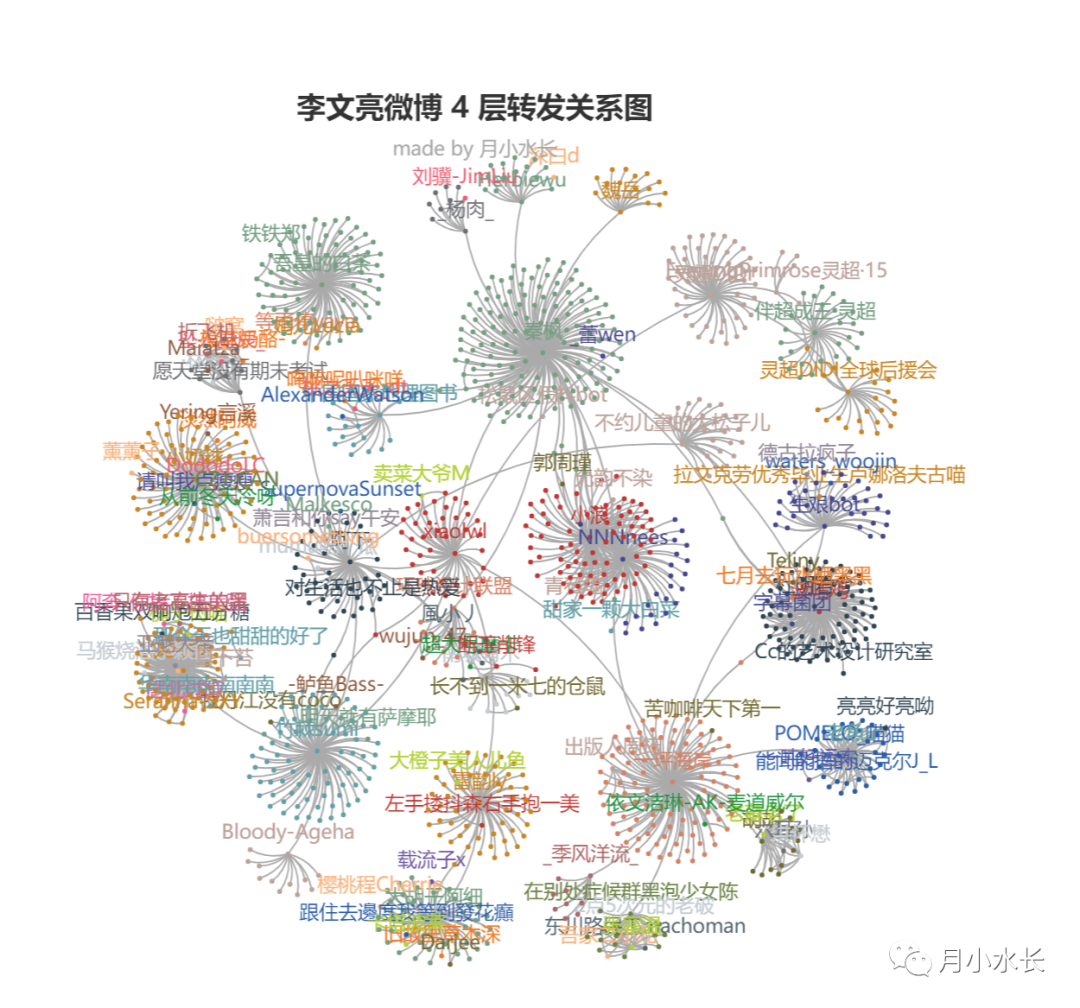
4 层转发网络
需要指定微博的指定层数的转发网络的读者,下文留言即可,转评赞此文者优先。
转发构建的教程呢?等阅读过万,下次一定!
评论