
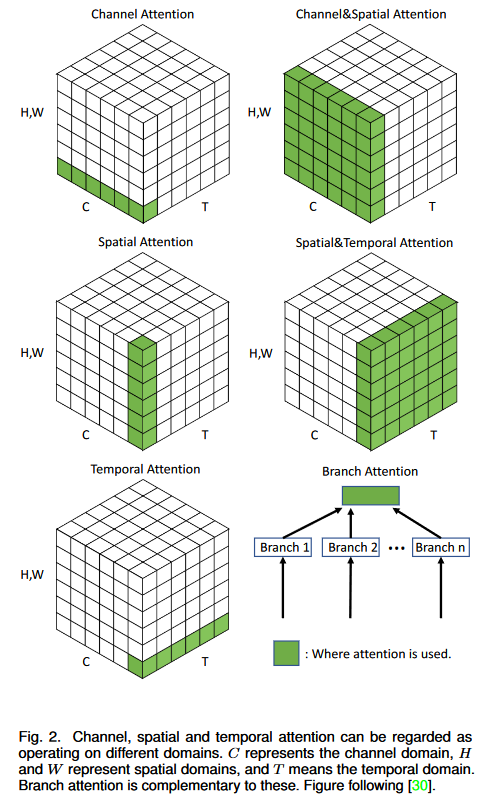
Attention Mechanism in Computer Vision
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
前言 本文系统全面地介绍了Attention机制的不同类别,介绍了每个类别的原理、优缺点。
其中表示生成的attention vector,表示基于对输入进行处理。不同种类的attention机制都可以用这个统一的公式进行表述。
Channel Attention
在神经网络中,我们可以认为不同feature map中的不同channel表示不同的object,channel attention就是要调节不同channel之间的权重,这个过程也可以视为在不同object中挑选的过程,因此channel attention也被称为what to pay attention to。Channel attention的核心目的就是找到重要的channel并捕捉全局信息。
Channel attention的代表作是发表在CVPR2018的SENet。在经典的卷积操作中,卷积的输出会将空间和通道的信息混杂在一起,无法展现通道间的关系,SENet提出了SE模块(squeeze and excitation)用于捕捉全局信息和通道间的关系。
如下图所示,SE模块分为两个阶段,squeeze阶段和excitation阶段。
Squeeze阶段(下图的)利用global average pooling将大小的feature压缩成大小,从而获得全局信息。
Excitation阶段通过MLP学习到不同channel之间的联系,MLP为两个线性层,中间夹着非线性激活函数,最后经过sigmoid函数输出attention vector。最终将原始的feature与attention vector进行对应通道的乘法。
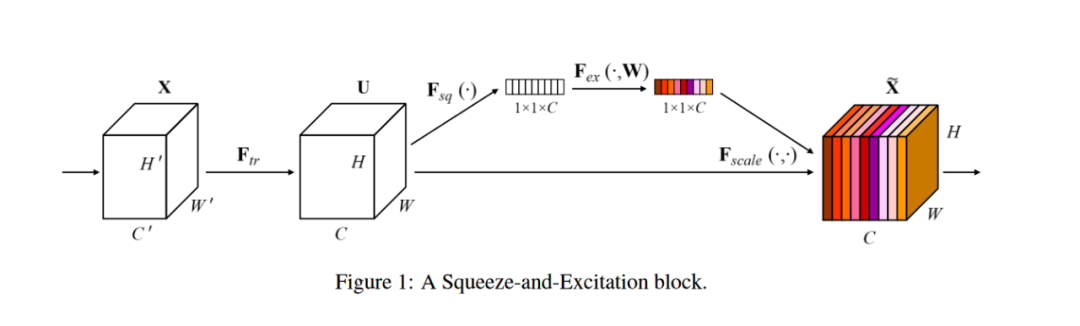
因此,SE模块可以表示为:
SE模块中的global average pooling和MLP或许太过简单,后续大量工作都是在改进squeeze阶段或excitation阶段,这些工作组成了channel attention这一大类。
Spatial Attention
Spatial attention能寻找重要的空间区域,也称为where to pay attention。Spatial attention目前许多工作都利用了self-attention机制,这部分以self-attention机制和相关的spatial attention工作为代表。
Non-local是self-attention在视觉领域的推广,其论文中的公式如下,该公式中的相当于上方通用公式的,来计算attention vector。但必须强调,self-attention不是spatial attention,self-attention可以用在空间,也可以用在时间,或者其他角度。
Self-attention是上方通用公式的特例,即
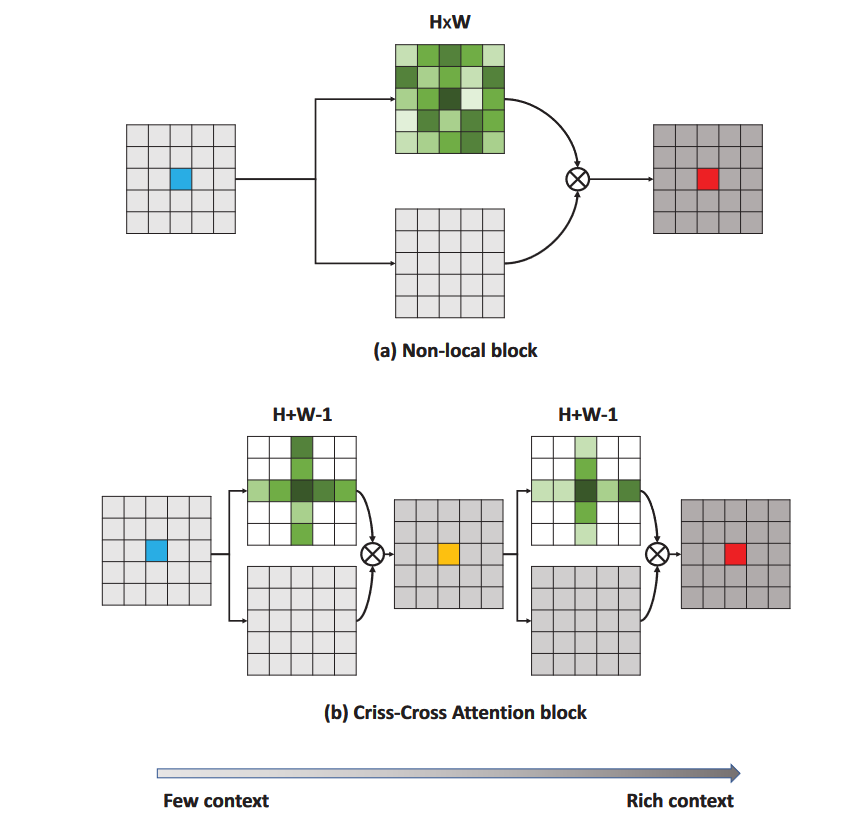
Self-attention能有效提取全局信息,这有利于解决卷积操作固有的局部性的缺点。但它也有缺点,尤其是计算量大,时间复杂度为平方复杂度。后续有许多工作来改进这一点,下面以CCNet为例。
CCNet的结构如下图所示,经典的attention是每一个像素点要对其他所有的点计算向量点积,而Criss-Cross(十字架)的结构让每一个点只与同一行和同一列的点进行计算。但这样又会无法获得整张图的信息,于是加入了recurrent的结构,将上一步得到的feature再进行一次Criss-Cross,由于十字架上的每个点对应上一次十字架的一行一列,因此第二次的Criss-Cross能覆盖整张图。注意两次计算attention时,参数是共享的,因为这是recurrent结构。这种attention的计算量为 ,由变成了。
另外像非常火热的ViT和Swin Transformer也都是利用spatial attention机制,它们将图像分成一些patch,然后在patch之间进行attention来传递信息。这两个模型非常火热,因此不赘述。
Temporal Attention and Branch Attention
假设输入图像,channel attention实际上就是在不同channel间计算attention来促进信息的流动,spatial attention就是在的像素点之间计算attention。
这两种attention机制构成了视觉attention的主要内容。Temporal attention的原理也是类似的,通常它用在视频的处理上,设输入为,temporal attention就是在这个维度上进行处理。Branch attention在此略过。
Channel & Spatial Attention
这里选择CVPR2017的分类模型Residual Attention Network和CVPR2019的分割模型Dual Attention Network作为代表。
Residual Attention Network对attention机制的使用体现在下图中,i遍历所有的像素,c遍历所有的channel。对像素和channel都进行sigmoid,这是同时使用了spatial和channel attention;进行了L2 normalization,去除了空间信息,是channel attention;类似地,去除掉了channel的信息,属于spatial attention。
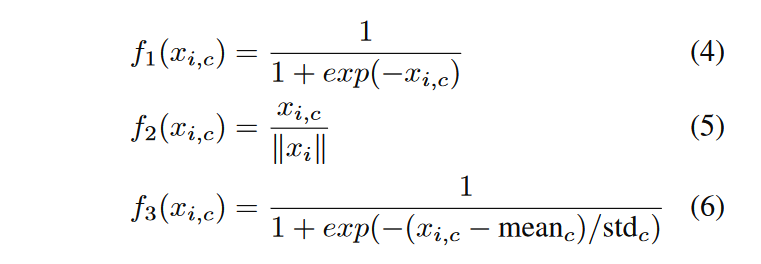
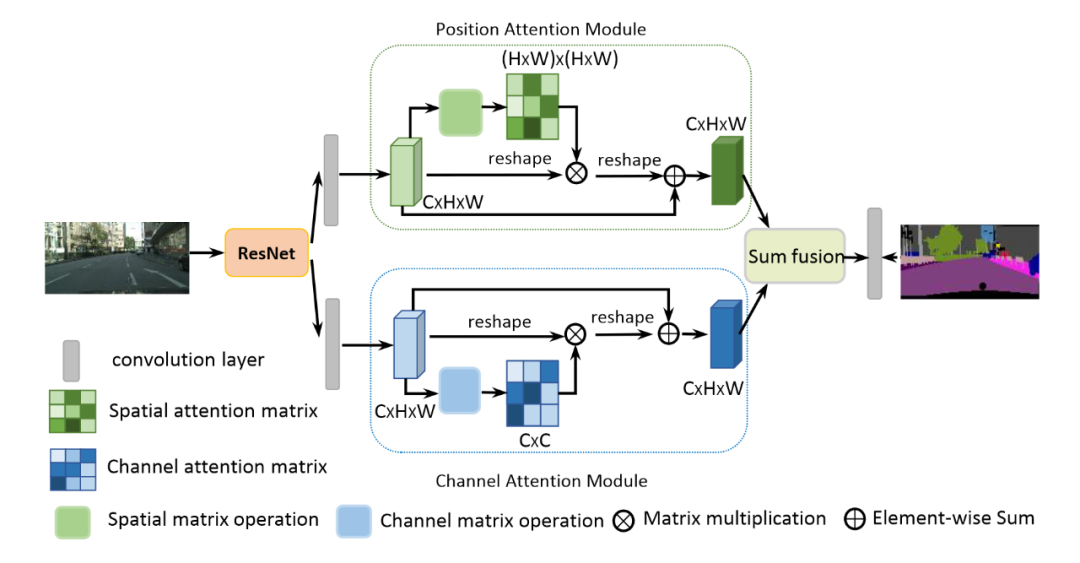
Dual Attention Network在经过卷积神经网络提取特征之后,将feature输入到两个不同的attention模块中,上方利用spatial attention机制,下方则是channel attention机制。
具体而言,假设输入position attention模块的feature为,先生成attention map,然后与X相乘得到attention,在类似residual进行加法,得到输出。
Channel attenion模块的做法基本一致,只是计算的维度在channel这一维,最终将两个attention模块的输出相加。
由上方两个例子可以看出,混合的attention机制无非是基本attention机制的一些组合,只要理解了基本的attention机制,万变不离其宗。
若觉得还不错的话,请点个 “赞” 或 “在看” 吧