
如何使用Python提取PDF表格及文本,并保存到Excel

导读:介绍一个开源Python工具库——pdfplumber。

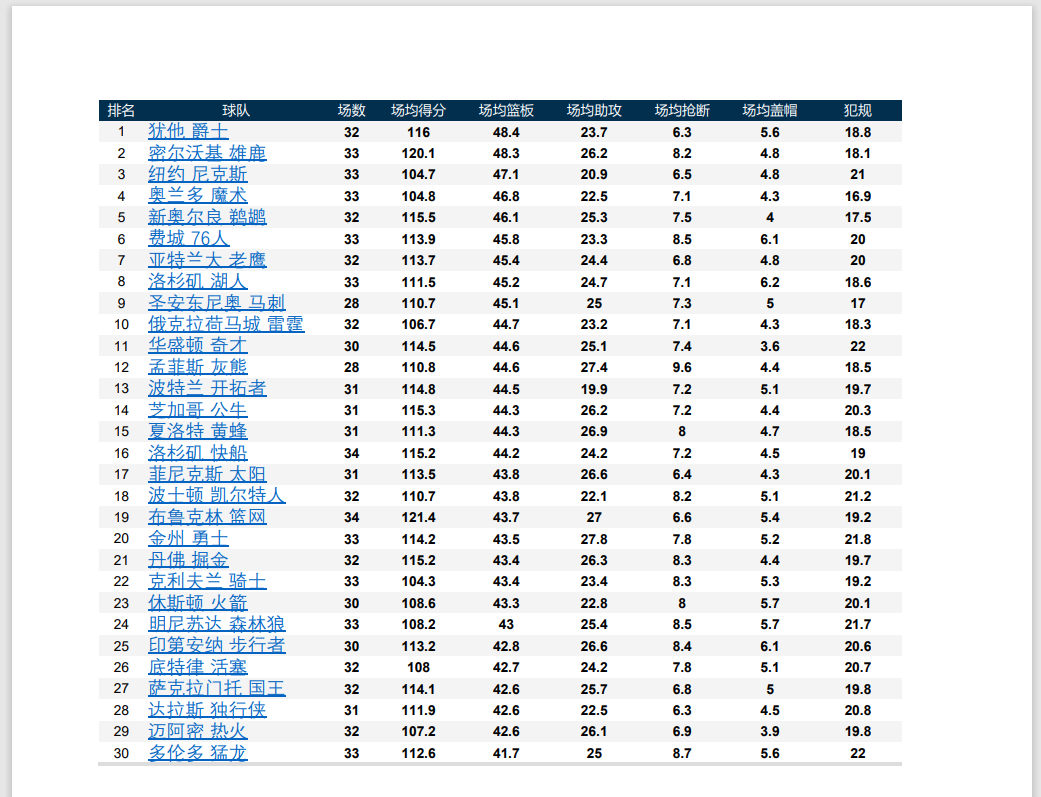
第一步:使用pdfplumber提取表格文本
# 导入pdfplumber
import pdfplumber
# 读取pdf文件,保存为pdf实例
pdf = pdfplumber.open("E:\\nba.pdf")
# 访问第二页
first_page = pdf.pages[1]
# 自动读取表格信息,返回列表
table = first_page.extract_table()
table
第二步:整理成dataframe格式,保存为excel
import pandas as pd
# 将列表转为df
table_df = pd.DataFrame(table_2[1:],columns=table_2[0])
# 保存excel
table_df.to_excel('test.xlsx')
table_df
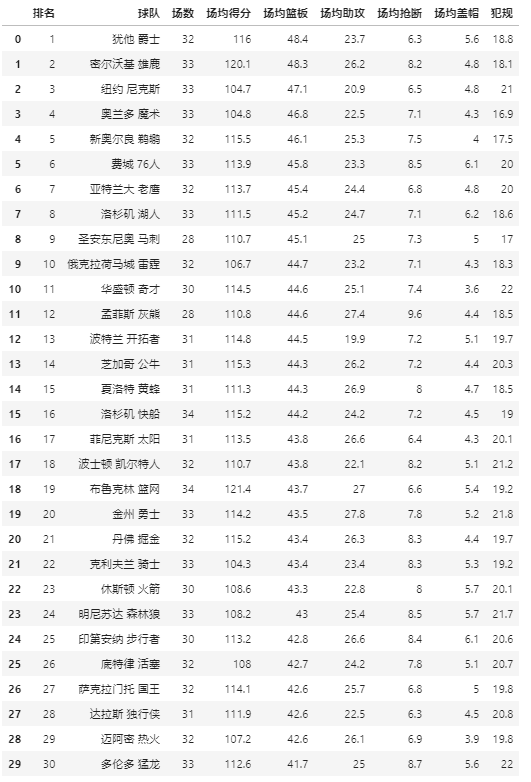
01 pdfplumber简介
它是一个纯Python第三方库,适合Python 3.x版本 它用来查看PDF各类信息,能有效提取文本、表格 它不支持修改或生成PDF,也不支持对pdf扫描件的处理
02 pdfplumber安装和导入
pip install pdfplumberimport pdfplumber
....03 pdfplumber简单使用
pdfplumber.PDF类
.metadata:获取PDF基础信息,返回字典 .pages:一个包含pdfplumber.Page实例的列表,每一个实例代表PDF每一页的信息。
pdfplumber.Page类

# 导入pdfplumber
import pdfplumber
# 读取pdf文件,返回pdfplumber.PDF类的实例
pdf = pdfplumber.open("e:\\nba2.pdf")
# 通过pdfplumber.PDF类的metadata属性获取pdf信息
pdf.metadata
# 通过pdfplumber.PDF类的metadata属性获取pdf页数
len(pdf.pages)# 第一页pdfplumber.Page实例
first_page = pdf.pages[0]
# 查看页码
print('页码:',first_page.page_number)
# 查看页宽
print('页宽:'first_page.width)
# 查看页高
print('页高:'first_page.height)
# 读取文本
text = first_page.extract_text()
print(text)
import pandas as pd
# 第二页pdfplumber.Page实例
first_page = pdf.pages[1]
# 自动读取表格信息,返回列表
table = first_page.extract_tables()
# 将列表转为df
table_df = pd.DataFrame(table_2[1:],columns=table_2[0])
table_df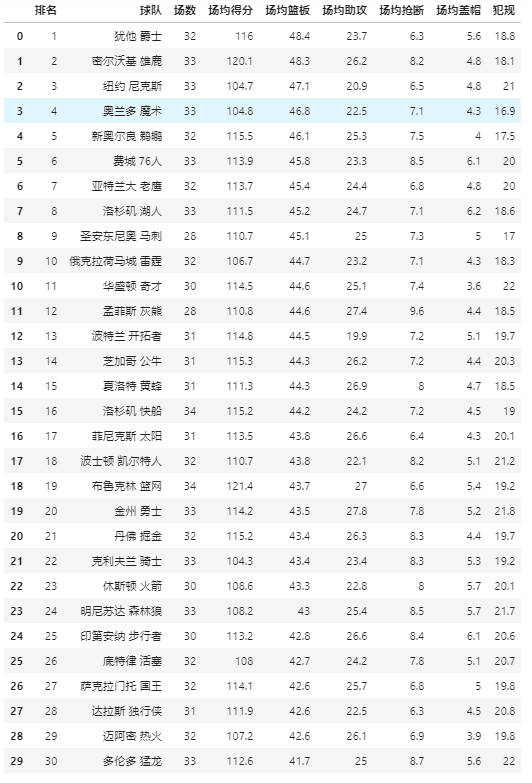
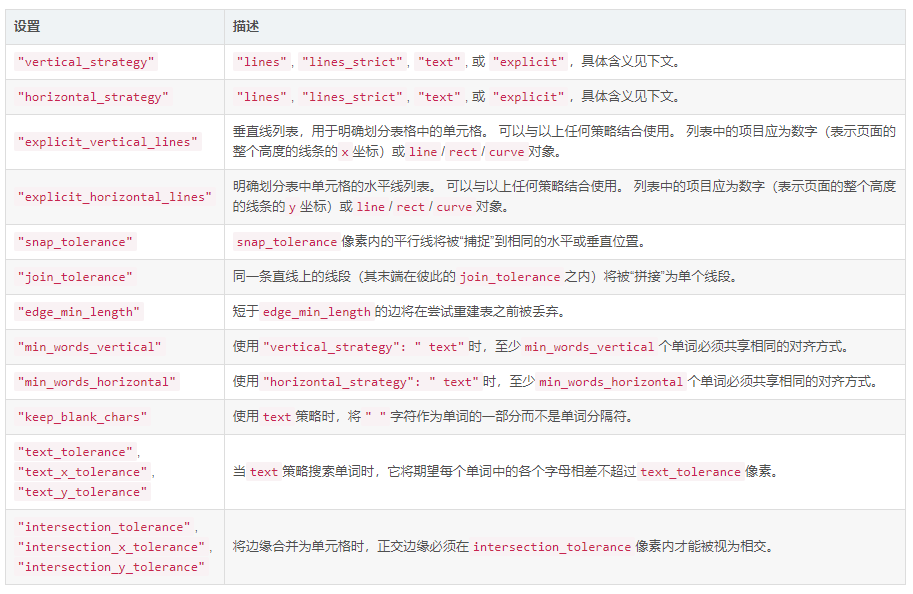
表格抽取参数设置
{
"vertical_strategy": "lines",
"horizontal_strategy": "lines",
"explicit_vertical_lines": [],
"explicit_horizontal_lines": [],
"snap_tolerance": 3,
"join_tolerance": 3,
"edge_min_length": 3,
"min_words_vertical": 3,
"min_words_horizontal": 1,
"keep_blank_chars": False,
"text_tolerance": 3,
"text_x_tolerance": None,
"text_y_tolerance": None,
"intersection_tolerance": 3,
"intersection_x_tolerance": None,
"intersection_y_tolerance": None,
}
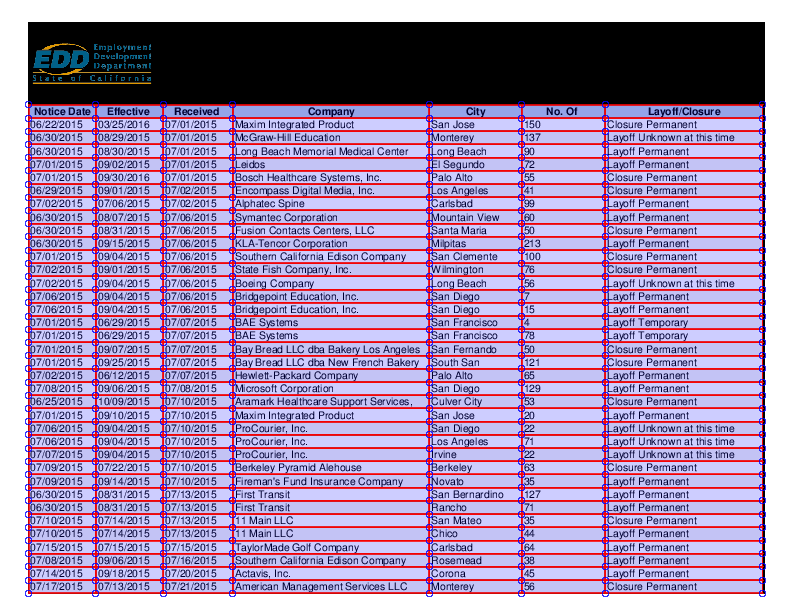
04 pdfplumber的独特之处


评论