
CUDA随笔之Stream的使用
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
来看看如何使用stream进行数据传输和计算并行,让数据处理快人一步。
出于个人兴趣和工作需要,最近接触了GPU编程。于是想写篇文章(或一系列文章),总结一下学习所得,防止自己以后忘了。
这篇短文主要介绍CUDA里面Stream的概念。用到CUDA的程序一般需要处理海量的数据,内存带宽经常会成为主要的瓶颈。在Stream的帮助下,CUDA程序可以有效地将内存读取和数值运算并行,从而提升数据的吞吐量。
本文使用了一个非常naive的图像处理例子:像素色彩空间转换,将一张7680x4320的8-bit BRGA图像转成同样尺寸的8-bit YUV。计算非常简单,就是数据量非常大。转换公式直接照抄维基百科(https://en.wikipedia.org/wiki/YUV#Conversion_to/from_RGB)

由于GPU和CPU不能直接读取对方的内存,CUDA程序一般会有一下三个步骤:1)将数据从CPU内存转移到GPU内存,2)GPU进行运算并将结果保存在GPU内存,3)将结果从GPU内存拷贝到CPU内存。
如果不做特别处理,那么CUDA会默认只使用一个Stream(Default Stream)。在这种情况下,刚刚提到的三个步骤就如菊花链般蛋疼地串联,必须等一步完成了才能进行下一步。是不是很别扭?(短文末尾附有完整代码)

uint8_t* bgraBuffer;
uint8_t* yuvBuffer;
uint8_t* deviceBgraBuffer;
uint8_t* deviceYuvBuffer;
const int dataSizeBgra = 7680 * 4320 * 4;
const int dataSizeYuv = 7680 * 4320 * 3;
cudaMallocHost(&bgraBuffer, dataSizeBgra);
cudaMallocHost(&yuvBuffer, dataSizeYuv);
cudaMalloc(&deviceBgraBuffer, dataSizeBgra);
cudaMalloc(&deviceYuvBuffer, dataSizeYuv);
//随机生成8K的BGRA图像
GenerateBgra8K(bgraBuffer, dataSizeBgra);
//将图像拷贝到GPU内存
cudaMemcpy(deviceBgraBuffer, bgraBuffer, dataSizeBgra, cudaMemcpyHostToDevice);
//CUDA kernel将 BGRA 转换为 YUV
convertPixelFormat<<<4096, 1024>>>(deviceBgraBuffer, deviceYuvBuffer, 7680*4320);
//等待数值计算完成
cudaDeviceSynchronize()
//将转换完的图像拷贝回CPU内存
cudaMemcpy(yuvBuffer, deviceYuvBuffer, dataSizeYuv, cudaMemcpyDeviceToHost);
cudaFreeHost(bgraBuffer);
cudaFreeHost(yuvBuffer);
cudaFree(deviceBgraBuffer);
cudaFree(deviceYuvBuffer);
NVIDIA家的GPU有一下很不错的技能(不知道是不是独有):
数据拷贝和数值计算可以同时进行。 两个方向的拷贝可以同时进行(GPU到CPU,和CPU到GPU),数据如同行驶在双向快车道。
但同时,这数据和计算的并行也有一点合乎逻辑的限制:进行数值计算的kernel不能读写正在被拷贝的数据。
Stream正是帮助我们实现以上两个并行的重要工具。基本的概念是:
将数据拆分称许多块,每一块交给一个Stream来处理。 每一个Stream包含了三个步骤:1)将属于该Stream的数据从CPU内存转移到GPU内存,2)GPU进行运算并将结果保存在GPU内存,3)将该Stream的结果从GPU内存拷贝到CPU内存。 所有的Stream被同时启动,由GPU的scheduler决定如何并行。
在这样的骚操作下,假设我们把数据分成A,B两块,各由一个Stream来处理。A的数值计算可以和B的数据传输同时进行,而A与B的数据传输也可以同时进行。由于第一个Stream只用到了数据A,而第二个Stream只用到了数据B,“进行数值计算的kernel不能读写正在被拷贝的数据”这一限制并没有被违反。效果如下:

实际上在NSight Profiler里面看上去是这样(这里用了8个Stream):
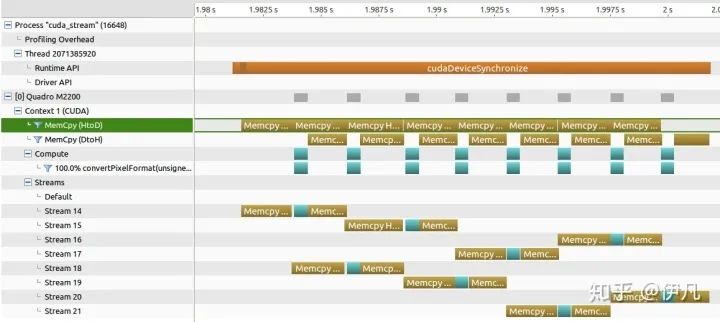
代码(省略版):
uint8_t* bgraBuffer;
uint8_t* yuvBuffer;
uint8_t* deviceBgraBuffer;
uint8_t* deviceYuvBuffer;
const int dataSizeBgra = 7680 * 4320 * 4;
const int dataSizeYuv = 7680 * 4320 * 3;
cudaMallocHost(&bgraBuffer, dataSizeBgra);
cudaMallocHost(&yuvBuffer, dataSizeYuv);
cudaMalloc(&deviceBgraBuffer, dataSizeBgra);
cudaMalloc(&deviceYuvBuffer, dataSizeYuv);
//随机生成8K的BGRA图像
GenerateBgra8K(bgraBuffer, dataSizeBgra);
//Stream的数量,这里用8个
const int nStreams = 8;
//Stream的初始化
cudaStream_t streams[nStreams];
for (int i = 0; i < nStreams; i++) {
cudaStreamCreate(&streams[i]);
}
//计算每个Stream处理的数据量。这里只是简单将数据分成8等分
//这里不会出现不能整除的情况,但实际中要小心
int brgaOffset = 0;
int yuvOffset = 0;
const int brgaChunkSize = dataSizeBgra / nStreams;
const int yuvChunkSize = dataSizeYuv / nStreams;
//这个循环依次启动 nStreams 个 Stream
for(int i=0; i<nStreams; i++)
{
brgaOffset = brgaChunkSize*i;
yuvOffset = yuvChunkSize*i;
//CPU到GPU的数据拷贝(原始数据),Stream i
cudaMemcpyAsync( deviceBgraBuffer+brgaOffset,
bgraBuffer+brgaOffset,
brgaChunkSize,
cudaMemcpyHostToDevice,
streams[i] );
//数值计算,Stream i
convertPixelFormat<<<4096, 1024, 0, streams[i]>>>(
deviceBgraBuffer+brgaOffset,
deviceYuvBuffer+yuvOffset,
brgaChunkSize/4 );
//GPU到CPU的数据拷贝(计算结果),Stream i
cudaMemcpyAsync( yuvBuffer+yuvOffset,
deviceYuvBuffer+yuvOffset,
yuvChunkSize,
cudaMemcpyDeviceToHost,
streams[i] );
}
//等待所有操作完成
cudaDeviceSynchronize();
cudaFreeHost(bgraBuffer);
cudaFreeHost(yuvBuffer);
cudaFree(deviceBgraBuffer);
cudaFree(deviceYuvBuffer);
在我的电脑上测试得出的性能对比(GPU型号 Quadro M2200):
CPU:300 ms
GPU 不用 Stream:34.6 ms
GPU 用8个Stream:20.2 ms
GPU 用18个Stream:19.3 ms
总结
使用多个Stream令数据传输和计算并行,可比只用Default Stream增加相当多的吞吐量。在需要处理海量数据,Stream是一个十分重要的工具。
完整代码(需要NVidia GPU,本文中的测试使用CUDA 10.0):
#include <vector>
#include <random>
#include <iostream>
#include <cuda.h>
#include <cuda_runtime.h>
#ifdef DEBUG
#define CUDA_CALL(F) if( (F) != cudaSuccess ) \
{printf("Error %s at %s:%d\n", cudaGetErrorString(cudaGetLastError()), \
__FILE__,__LINE__); exit(-1);}
#define CUDA_CHECK() if( (cudaPeekAtLastError()) != cudaSuccess ) \
{printf("Error %s at %s:%d\n", cudaGetErrorString(cudaGetLastError()), \
__FILE__,__LINE__-1); exit(-1);}
#else
#define CUDA_CALL(F) (F)
#define CUDA_CHECK()
#endif
void PrintDeviceInfo();
void GenerateBgra8K(uint8_t* buffer, int dataSize);
void convertPixelFormatCpu(uint8_t* inputBgra, uint8_t* outputYuv, int numPixels);
__global__ void convertPixelFormat(uint8_t* inputBgra, uint8_t* outputYuv, int numPixels);
int main()
{
PrintDeviceInfo();
uint8_t* bgraBuffer;
uint8_t* yuvBuffer;
uint8_t* deviceBgraBuffer;
uint8_t* deviceYuvBuffer;
const int dataSizeBgra = 7680 * 4320 * 4;
const int dataSizeYuv = 7680 * 4320 * 3;
CUDA_CALL(cudaMallocHost(&bgraBuffer, dataSizeBgra));
CUDA_CALL(cudaMallocHost(&yuvBuffer, dataSizeYuv));
CUDA_CALL(cudaMalloc(&deviceBgraBuffer, dataSizeBgra));
CUDA_CALL(cudaMalloc(&deviceYuvBuffer, dataSizeYuv));
std::vector<uint8_t> yuvCpuBuffer(dataSizeYuv);
cudaEvent_t start, stop;
float elapsedTime;
float elapsedTimeTotal;
float dataRate;
CUDA_CALL(cudaEventCreate(&start));
CUDA_CALL(cudaEventCreate(&stop));
std::cout << " " << std::endl;
std::cout << "Generating 7680 x 4320 BRGA8888 image, data size: " << dataSizeBgra << std::endl;
GenerateBgra8K(bgraBuffer, dataSizeBgra);
std::cout << " " << std::endl;
std::cout << "Computing results using CPU." << std::endl;
std::cout << " " << std::endl;
CUDA_CALL(cudaEventRecord(start, 0));
convertPixelFormatCpu(bgraBuffer, yuvCpuBuffer.data(), 7680*4320);
CUDA_CALL(cudaEventRecord(stop, 0));
CUDA_CALL(cudaEventSynchronize(stop));
CUDA_CALL(cudaEventElapsedTime(&elapsedTime, start, stop));
std::cout << " Whole process took " << elapsedTime << "ms." << std::endl;
std::cout << " " << std::endl;
std::cout << "Computing results using GPU, default stream." << std::endl;
std::cout << " " << std::endl;
std::cout << " Move data to GPU." << std::endl;
CUDA_CALL(cudaEventRecord(start, 0));
CUDA_CALL(cudaMemcpy(deviceBgraBuffer, bgraBuffer, dataSizeBgra, cudaMemcpyHostToDevice));
CUDA_CALL(cudaEventRecord(stop, 0));
CUDA_CALL(cudaEventSynchronize(stop));
CUDA_CALL(cudaEventElapsedTime(&elapsedTime, start, stop));
dataRate = dataSizeBgra/(elapsedTime/1000.0)/1.0e9;
elapsedTimeTotal = elapsedTime;
std::cout << " Data transfer took " << elapsedTime << "ms." << std::endl;
std::cout << " Performance is " << dataRate << "GB/s." << std::endl;
std::cout << " Convert 8-bit BGRA to 8-bit YUV." << std::endl;
CUDA_CALL(cudaEventRecord(start, 0));
convertPixelFormat<<<32400, 1024>>>(deviceBgraBuffer, deviceYuvBuffer, 7680*4320);
CUDA_CHECK();
CUDA_CALL(cudaDeviceSynchronize());
CUDA_CALL(cudaEventRecord(stop, 0));
CUDA_CALL(cudaEventSynchronize(stop));
CUDA_CALL(cudaEventElapsedTime(&elapsedTime, start, stop));
dataRate = dataSizeBgra/(elapsedTime/1000.0)/1.0e9;
elapsedTimeTotal += elapsedTime;
std::cout << " Processing of 8K image took " << elapsedTime << "ms." << std::endl;
std::cout << " Performance is " << dataRate << "GB/s." << std::endl;
std::cout << " Move data to CPU." << std::endl;
CUDA_CALL(cudaEventRecord(start, 0));
CUDA_CALL(cudaMemcpy(yuvBuffer, deviceYuvBuffer, dataSizeYuv, cudaMemcpyDeviceToHost));
CUDA_CALL(cudaEventRecord(stop, 0));
CUDA_CALL(cudaEventSynchronize(stop));
CUDA_CALL(cudaEventElapsedTime(&elapsedTime, start, stop));
dataRate = dataSizeYuv/(elapsedTime/1000.0)/1.0e9;
elapsedTimeTotal += elapsedTime;
std::cout << " Data transfer took " << elapsedTime << "ms." << std::endl;
std::cout << " Performance is " << dataRate << "GB/s." << std::endl;
std::cout << " Whole process took " << elapsedTimeTotal << "ms." <<std::endl;
std::cout << " Compare CPU and GPU results ..." << std::endl;
bool foundMistake = false;
for(int i=0; i<dataSizeYuv; i++){
if(yuvCpuBuffer[i]!=yuvBuffer[i]){
foundMistake = true;
break;
}
}
if(foundMistake){
std::cout << " Results are NOT the same." << std::endl;
} else {
std::cout << " Results are the same." << std::endl;
}
const int nStreams = 16;
std::cout << " " << std::endl;
std::cout << "Computing results using GPU, using "<< nStreams <<" streams." << std::endl;
std::cout << " " << std::endl;
cudaStream_t streams[nStreams];
std::cout << " Creating " << nStreams << " CUDA streams." << std::endl;
for (int i = 0; i < nStreams; i++) {
CUDA_CALL(cudaStreamCreate(&streams[i]));
}
int brgaOffset = 0;
int yuvOffset = 0;
const int brgaChunkSize = dataSizeBgra / nStreams;
const int yuvChunkSize = dataSizeYuv / nStreams;
CUDA_CALL(cudaEventRecord(start, 0));
for(int i=0; i<nStreams; i++)
{
std::cout << " Launching stream " << i << "." << std::endl;
brgaOffset = brgaChunkSize*i;
yuvOffset = yuvChunkSize*i;
CUDA_CALL(cudaMemcpyAsync( deviceBgraBuffer+brgaOffset,
bgraBuffer+brgaOffset,
brgaChunkSize,
cudaMemcpyHostToDevice,
streams[i] ));
convertPixelFormat<<<4096, 1024, 0, streams[i]>>>(deviceBgraBuffer+brgaOffset, deviceYuvBuffer+yuvOffset, brgaChunkSize/4);
CUDA_CALL(cudaMemcpyAsync( yuvBuffer+yuvOffset,
deviceYuvBuffer+yuvOffset,
yuvChunkSize,
cudaMemcpyDeviceToHost,
streams[i] ));
}
CUDA_CHECK();
CUDA_CALL(cudaDeviceSynchronize());
CUDA_CALL(cudaEventRecord(stop, 0));
CUDA_CALL(cudaEventSynchronize(stop));
CUDA_CALL(cudaEventElapsedTime(&elapsedTime, start, stop));
std::cout << " Whole process took " << elapsedTime << "ms." << std::endl;
std::cout << " Compare CPU and GPU results ..." << std::endl;
for(int i=0; i<dataSizeYuv; i++){
if(yuvCpuBuffer[i]!=yuvBuffer[i]){
foundMistake = true;
break;
}
}
if(foundMistake){
std::cout << " Results are NOT the same." << std::endl;
} else {
std::cout << " Results are the same." << std::endl;
}
CUDA_CALL(cudaFreeHost(bgraBuffer));
CUDA_CALL(cudaFreeHost(yuvBuffer));
CUDA_CALL(cudaFree(deviceBgraBuffer));
CUDA_CALL(cudaFree(deviceYuvBuffer));
return 0;
}
void PrintDeviceInfo(){
int deviceCount = 0;
cudaGetDeviceCount(&deviceCount);
std::cout << "Number of device(s): " << deviceCount << std::endl;
if (deviceCount == 0) {
std::cout << "There is no device supporting CUDA" << std::endl;
return;
}
cudaDeviceProp info;
for(int i=0; i<deviceCount; i++){
cudaGetDeviceProperties(&info, i);
std::cout << "Device " << i << std::endl;
std::cout << " Name: " << std::string(info.name) << std::endl;
std::cout << " Glocbal memory: " << info.totalGlobalMem/1024.0/1024.0 << " MB"<< std::endl;
std::cout << " Shared memory per block: " << info.sharedMemPerBlock/1024.0 << " KB"<< std::endl;
std::cout << " Warp size: " << info.warpSize<< std::endl;
std::cout << " Max thread per block: " << info.maxThreadsPerBlock<< std::endl;
std::cout << " Thread dimension limits: " << info.maxThreadsDim[0]<< " x "
<< info.maxThreadsDim[1]<< " x "
<< info.maxThreadsDim[2]<< std::endl;
std::cout << " Max grid size: " << info.maxGridSize[0]<< " x "
<< info.maxGridSize[1]<< " x "
<< info.maxGridSize[2]<< std::endl;
std::cout << " Compute capability: " << info.major << "." << info.minor << std::endl;
}
}
void GenerateBgra8K(uint8_t* buffer, int dataSize){
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> sampler(0, 255);
for(int i=0; i<dataSize/4; i++){
buffer[i*4] = sampler(gen);
buffer[i*4+1] = sampler(gen);
buffer[i*4+2] = sampler(gen);
buffer[i*4+3] = 255;
}
}
void convertPixelFormatCpu(uint8_t* inputBgra, uint8_t* outputYuv, int numPixels){
short3 yuv16;
char3 yuv8;
for(int idx=0; idx<numPixels; idx++){
yuv16.x = 66*inputBgra[idx*4+2] + 129*inputBgra[idx*4+1] + 25*inputBgra[idx*4];
yuv16.y = -38*inputBgra[idx*4+2] + -74*inputBgra[idx*4+1] + 112*inputBgra[idx*4];
yuv16.z = 112*inputBgra[idx*4+2] + -94*inputBgra[idx*4+1] + -18*inputBgra[idx*4];
yuv8.x = (yuv16.x>>8)+16;
yuv8.y = (yuv16.y>>8)+128;
yuv8.z = (yuv16.z>>8)+128;
*(reinterpret_cast<char3*>(&outputYuv[idx*3])) = yuv8;
}
}
__global__ void convertPixelFormat(uint8_t* inputBgra, uint8_t* outputYuv, int numPixels){
int stride = gridDim.x * blockDim.x;
int idx = threadIdx.x + blockIdx.x * blockDim.x;
short3 yuv16;
char3 yuv8;
while(idx<=numPixels){
if(idx<numPixels){
yuv16.x = 66*inputBgra[idx*4+2] + 129*inputBgra[idx*4+1] + 25*inputBgra[idx*4];
yuv16.y = -38*inputBgra[idx*4+2] + -74*inputBgra[idx*4+1] + 112*inputBgra[idx*4];
yuv16.z = 112*inputBgra[idx*4+2] + -94*inputBgra[idx*4+1] + -18*inputBgra[idx*4];
yuv8.x = (yuv16.x>>8)+16;
yuv8.y = (yuv16.y>>8)+128;
yuv8.z = (yuv16.z>>8)+128;
*(reinterpret_cast<char3*>(&outputYuv[idx*3])) = yuv8;
}
idx += stride;
}
}
点个在看 paper不断!